Custom Models screen
To access the Custom Models screen, navigate to the megamenu and click Models > Custom Models.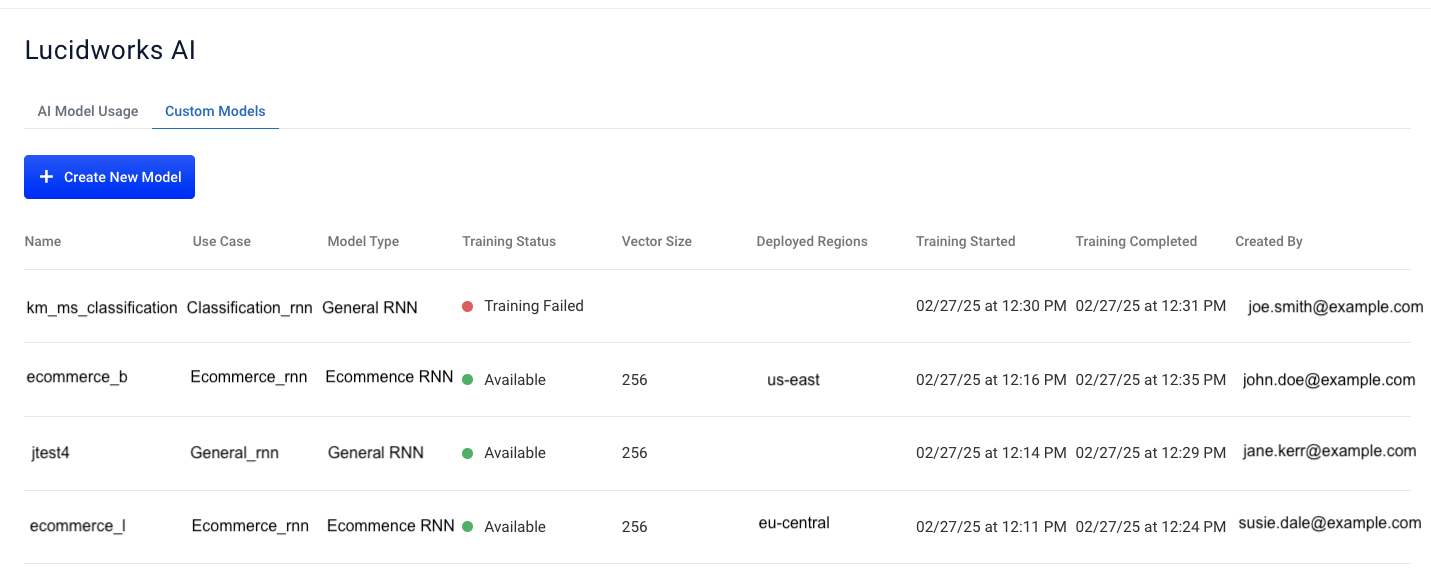
You can also create a new custom model. For more information, see Create a new model.
Model Details screen
If you hold the pointer over a model on the list and click the entry, the Model Details screen displays. You can view Training details that include Metadata, Summary, and Metrics information about the selected model. You can also:- Click Download Model Data to download the JSON file for the model. You can use the parameters from this model in a different model without rekeying the information.
- Click Delete if the model can be deleted. If the model cannot be deleted because it is associated with deployments, all the deployments must be deleted first. For example, if the model is associated with two deployments,
2 Active Deployments: Deleting Disableddisplays instead of the Delete button. This example indicates there are two current deployments for the model, and based on the status of those deployments, the option to delete the model is disabled.
Training Details
The Training Details screen provides metadata, summary, and metrics information.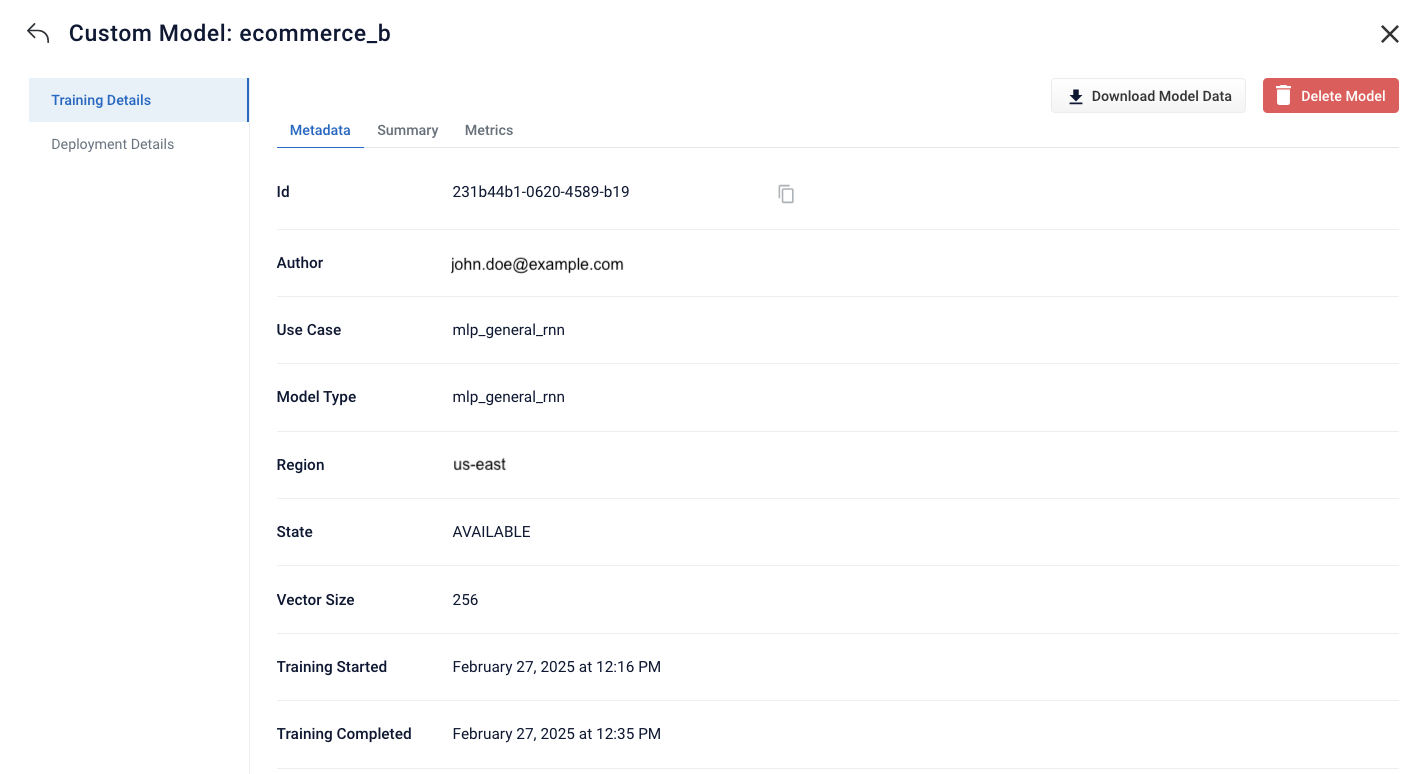
Metadata
This metadata provides the data supplied when the model was created.
An example of an error message when the training fails is:
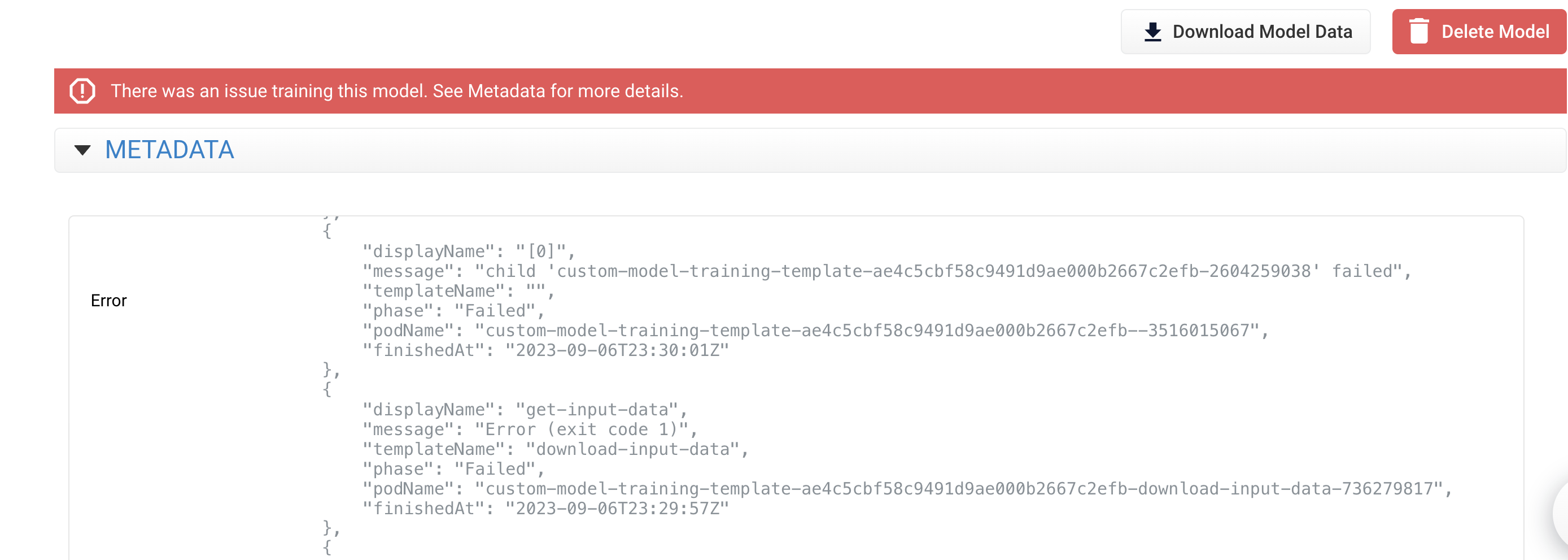
Summary
Click the Summary tab to view information about training metrics for the selected model.
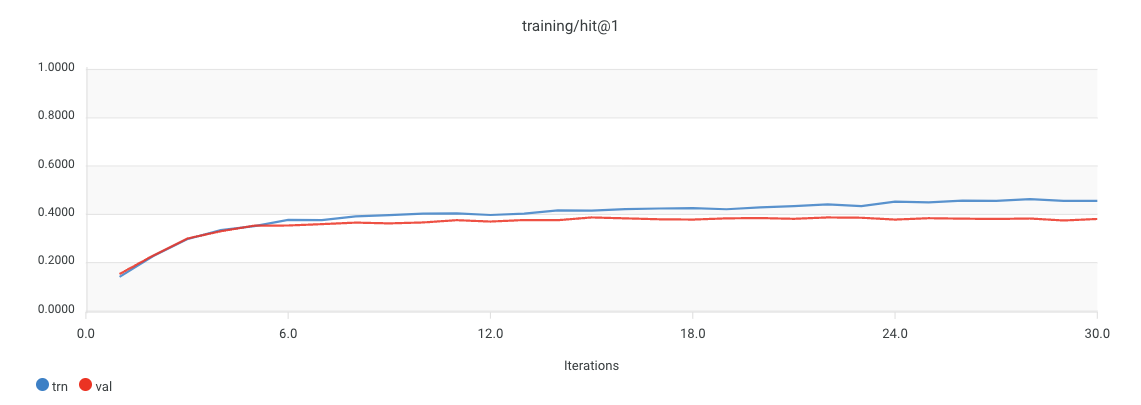
Metrics
Click the Metrics tab to view analytics about the trained model. This information provides insights that help you determine if parameters need to be changed or if more data is needed to improve the model for optimal results. The Custom configuration parameter that specifies metrics isdataset_config.metrics_config.monitor_metric. When you select one of the values, the k designates the numbers 1, 3, 5, and 10.
hit@kwhich measures the probability that the prediction is in the first topkmodel predictions.map@kis the mean average precision metric that evaluates the system to return relevant items in the topkresults, and positions more relevant items at the top.mrr@kis the mean reciprocal rank that determines how quickly the system displays the first relevant item in the topkresults.ndcg@kis the normalized discounted cumulative gain metric that compares rankings to the optimal order where all relevant items display at the top.recall@kdisplays the number of relevant items returned in the topkrecommendations out of the number of relevant items in the dataset.
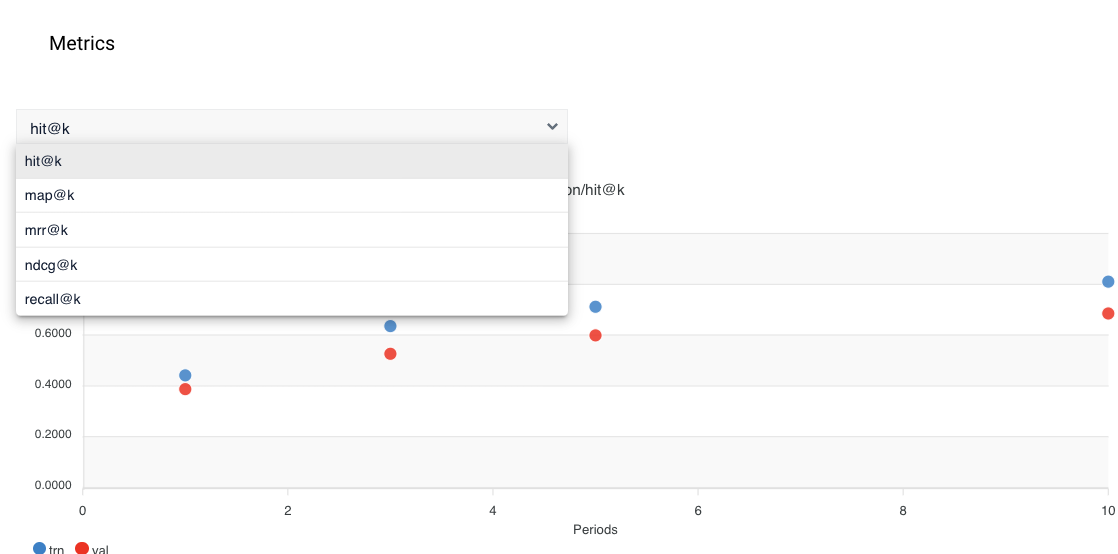
hit@k value is selected. Four graphs display on the screen: hit@1 (pictured), hit@3, hit@5, and hit@10.
Deployment Details
The deployments screen displays information about each time you deployed the selected model.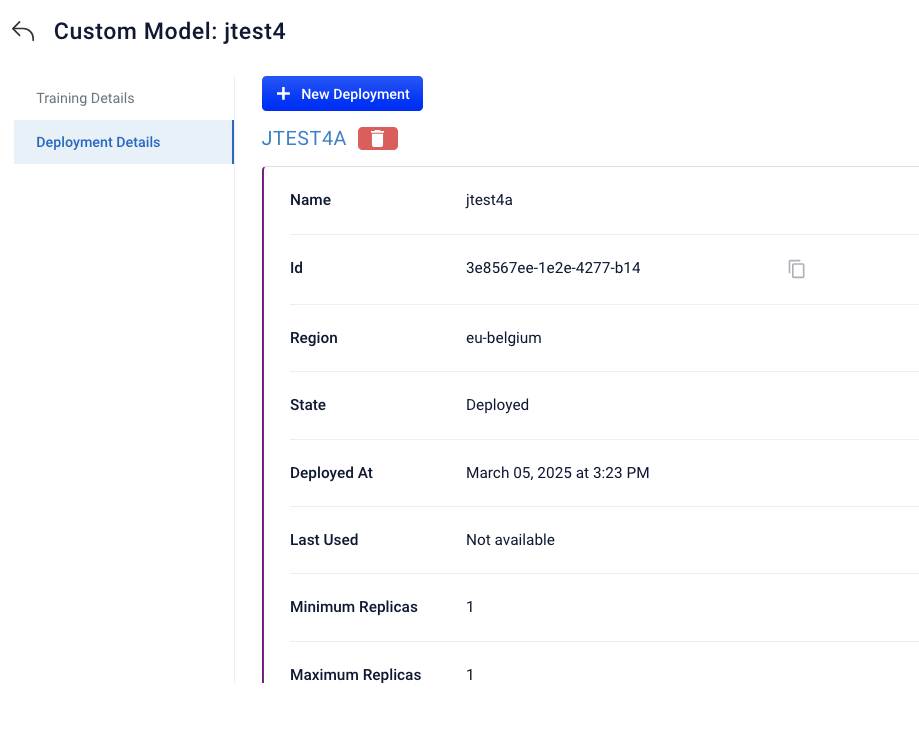
You can also:
- Click + New Deployment to deploy the model again. For more information, see Create a new deployment.
- Click the Trash icon to delete a deployment with a status of “Deployed”. You cannot delete a deployment with a status of “Deploying”.