- Business-to-Consumer
- Business-to-Business
- Knowledge Management
Using neural hybrid search, keyword matches and semantic similarities can be combined with RAG to generate answers from your site’s guidelines, procedures, and information. For example, if a customer requests information about return policies, NHS blends matches to “return” with semantically similar information, and then uses RAG to generate a comprehensive, contextual answer from existing site documents.
For self-hosted Fusion: Enable Lucidworks AI
Before you can begin using Lucidworks AI features with self-hosted Fusion, a couple of one-time setup steps are required. If you are using Lucidworks Search, these steps have already been performed for you by the Lucidworks team.Set up Lucidworks AI Gateway
Lucidworks AI Gateway provides secure, authenticated communication between your self-hosted Fusion instance and Lucidworks AI.
You must configure the integration between the two before you can begin using Lucidworks AI features in Fusion.
Configure A Lucidworks AI Gateway Integration
Configure A Lucidworks AI Gateway Integration
Before you can use Lucidworks AI with Lucidworks Platform, you must configure the Lucidworks AI Gateway to provide a secure, authenticated integration between self-hosted Fusion and your hosted models.
This configuration is done through a secret properties file that you can find in the Lucidworks Platform UI.Integrations are created for you by the Lucidworks team. But as a workspace owner, you can configure those integrations with Lucidworks AI Gateway.
Each account can have its own set of credentials and associated scopes, which define the operations it can perform.
If configuration properties are not provided at the account level, default settings are used instead.To configure the Lucidworks AI Gateway, navigate to the megamenu and click Models.For a configuration with multiple integrations, it should look like this:
This feature is available starting in Fusion 5.9.5 and in all subsequent Fusion 5.9 releases.
- On the Integrations tab, click your integration. If you don’t see your integration, contact your Lucidworks representative.
- Download or copy the YAML code and paste it into a file called
account.yaml.
- Apply the file to your Fusion configuration file. For example:
Set up Neural Hybrid Search and RAG
In just a few steps, you’ll have a functional pipeline you can test, tune, and use as a starting point for future implementations.Prepare your documents
As your documents are indexed, they need to be prepared for Lucidworks AI. This includes and .Both steps run in one stage called the LWAI Chunker Stage. Add it to your index pipeline anywhere before the Solr Partial Update Indexer stage.
<doc.embedding_t>.Index some documents and continue to the next step.Choose a chunking strategy
Choose a chunking strategy
Lucidworks AI supports several chunking strategies. Each one splits text differently and is suited to specific content types. The strategy you choose affects both performance and response quality. Lucidworks recommends starting with the Sentence strategy and experimenting from there.
- Sentence
- Dynamic sentence
- Dynamic newline
- Regex splitter
- Semantic
The sentence chunker splits text into fixed-size chunks based on a set number of sentences. This approach is simple and consistent, making it a good choice for most use cases where the structure of the text is clear.Best for:
- FAQs
- Help articles
- Structured documentation
Choose a model for indexing
Choose a model for indexing
The model you choose at indexing time controls how your documents are vectorized. These vectors are what Lucidworks AI uses to compare queries to document chunks. A good model captures the meaning of your content clearly and compactly. Model quality affects how accurately the system retrieves relevant chunks during search or generation. Model size affects indexing speed, storage cost, and system performance.Start with a clear goal for your retrieval use case. If you need fast responses and can tolerate a small drop in relevance, choose a smaller model. If you need precise chunk matching across large or complex content, use a higher-quality model—even if it’s slower.Common starting points
- e5-base-v2: Balanced quality and speed. Works well for general-purpose indexing in English.
- bge-base: Strong semantic performance.
- snowflake-arctic-embed-m-v2.0: High retrieval accuracy with optional dimension reduction for performance tuning.
- multilingual-e5-base: Recommended if your content includes multiple languages.
- Start with a base or small model to establish a performance and relevance baseline.
- Index a representative sample and test retrieval using real queries.
- Use Query Workbench to inspect which chunks are returned for each query.
- Measure indexing time and vector storage to catch early scalability issues.
- Use
dimReductionSizewith supported models to reduce vector size without retraining. - If chunk retrieval is weak, try a different model before adjusting chunking strategy.
Vectorize your queries
Just as you needed to vectorize documents, you need to vectorize queries so Lucidworks AI can find the best matching document chunks.Add the LWAI Vectorize Query stage before any stage that alters the query in your query pipeline. Use the same model you selected for the LWAI Chunker Stage in the index pipeline.
Configure NHS
Neural Hybrid Search combines and queries to create a flexible balance for any use case.Add the Chunking Neural Hybrid Query stage anywhere between the LWAI Vectorize Query and Solr Query stages. The default configuration is a good starting point, but you must set the Vector Query Field to match the value in the Destination Field Name & Context Output field from the LWAI Chunker Stage.
Configure RAG
Add the LWAI Prediction stage anywhere between the LWAI Vectorize Query and Solr Query stages. For this use case, select RAG.
Lucidworks AI supports many use cases. To explore more, see Lucidworks AI use cases.
body and source fields. You can include additional fields if they help improve the responses.If your model requires an API key, add it to the configuration. The key is stored securely.Embedding models for RAG
Embedding models for RAG
Choosing the right embedding model for RAG starts with understanding what you want retrieval to achieve. Embedding models offer different tradeoffs in quality, performance, and language support. The best option depends on your data, your users’ expectations, and your system constraints. Start with a clear goal: Are you trying to surface precise answers from a product catalog? Return relevant support content? Summarize technical documentation?Lucidworks provides a set of pre-trained models that support a wide range of domains. The guidance below focuses on common RAG retrieval needs in B2B commerce, B2C commerce, and knowledge management.Tips for evaluation
- B2B
- B2C
- Knowledge Management
RAG in B2B typically supports technical queries against complex product catalogs, configuration rules, and documentation. Accuracy and domain fit matter more than general language quality.
- snowflake-arctic-embed-m-v2.0: High retrieval quality with support for vector size reduction. Recommended starting point for B2B. Optimized for long, structured product content.
- multilingual-e5-base: Strong multilingual support with consistent performance across languages and formats. Good fallback when content spans languages or includes inconsistent structure.
- e5-base-v2: Balanced quality and speed if your data is mostly English and latency is a concern.
- Use real queries from actual users, including edge cases, to measure effectiveness.
- Start with a base or small model and scale up only if needed.
- Inspect retrieved chunks in Query Workbench to verify relevance.
- Reduce vector size using
dimReductionSizein supported models to improve performance. - Switch models easily in the LWAI Prediction stage as your use case evolves.
Fine-tune
Everything is set up. Now test your configuration in the Query Workbench. Switch to the JSON view to inspect Neural Hybrid Search results and RAG responses.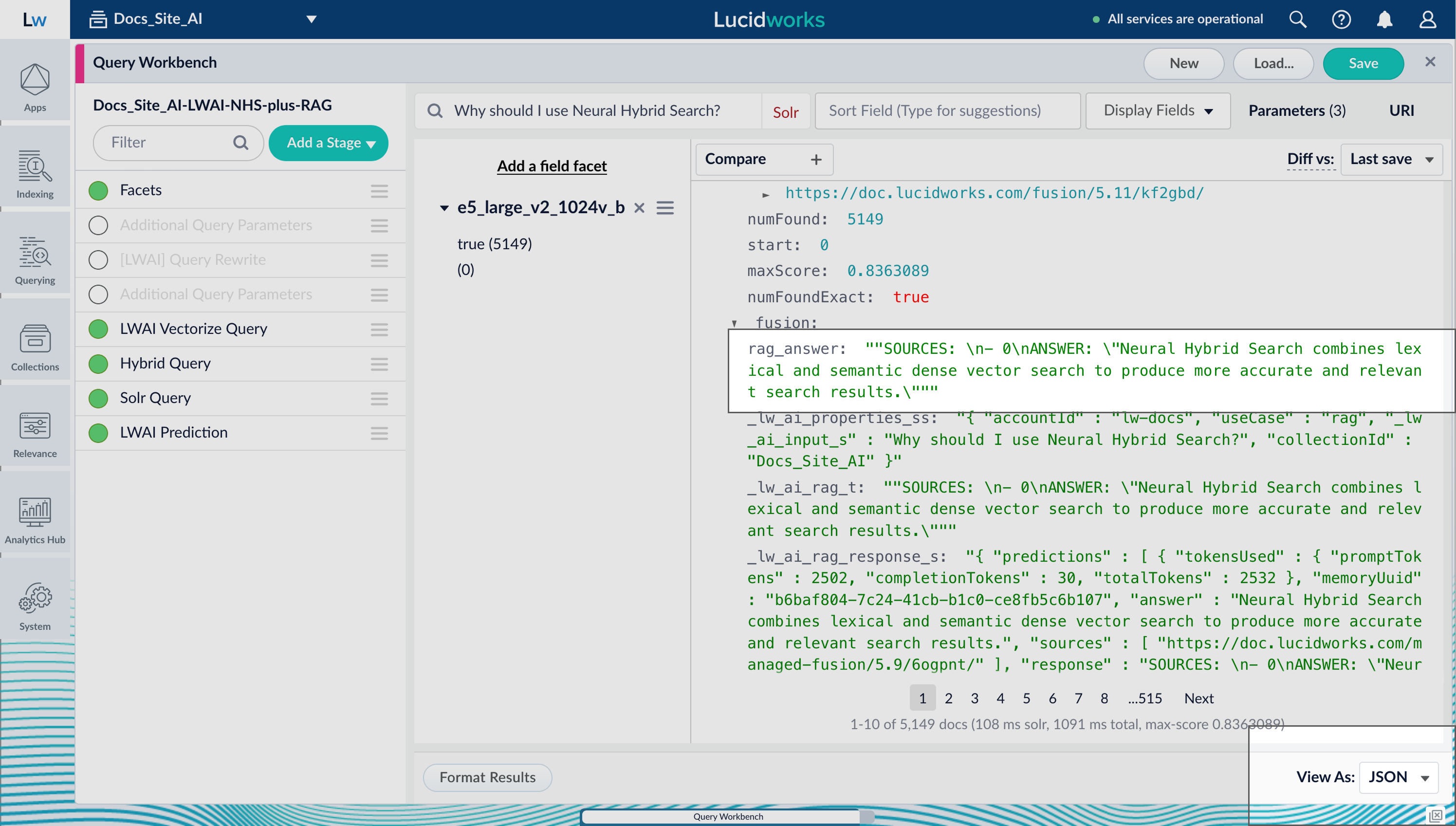
- Is the answer backed by retrieved content? The response should only include facts found in the retrieved documents.
- Do citations match the content? References must point to documents that support the answer.
- What happens if nothing useful is retrieved? The system should avoid generating unsupported content.
- Does the answer stay on topic? The response should directly address the query.
- Does the system handle edge cases well? Use ambiguous or off-topic queries to test its behavior.
Learn more
LWAI pipeline with NHS plus RAG
LWAI pipeline with NHS plus RAG
This pipeline uses the following stages:
- Additional Query Parameters
- LWAI Query Rewrite
- Additional Query Parameters
- LWAI Vectorize Query
- Hybrid Query
- Solr Query
- LWAI Prediction
Add the pipeline
- Navigate to Querying > Query Pipelines.
- Click Add+.
- Enter the Pipeline ID, for example
LWAI-NHS-plus-RAG. - Remove the default stages except for Solr Query:
- Remove the Text Tagger stage.
- Remove the Boost with Signals stage.
- Remove the Query Fields stage.
- Remove the Facets stage.
- Remove the Apply Rules stage.
- Remove the Modify Response with Rules stage.
Additional Query Parameters
Configure the Additional Query Parameters stage as follows.- Click Add a new pipeline stage > Additional Query Parameters.
- Enter names, values, and policies for the Parameters and Values:
orig_q-<request.q>-replace.rewritten_q-<request.q>-replace.
- Save the pipeline.
LWAI Query Rewrite
LWAI Query Rewrite is set up using the LWAI Prediction stage.- Click Add a new pipeline stage > LWAI Prediction.
- Enter a Label, such as
[LWAI] Query Rewrite. - In the Condition field, enter
request.getFirstFieldValue('q') != '**:**' && request.hasParam('memory_uuid'). - Select the Lucidworks AI integration Account Name as defined by your Fusion Administrator.
- Select the Use Case, such as
standalone-query-rewriter. - Select the Model to use.
- Enter the Input context variable as
<request.q>. - Enter the Destination Variable Name & Context Output as
standalone. - Enter the following under Use Case Configuration:
- Parameter Name:
memoryUuid. - Parameter Value:
<request.memory_uuid>.
- Parameter Name:
- Save the pipeline.
Additional Query Parameters
Configure another Additional Query Parameters stage as follows.- Click *Add a new pipeline stage > Additional Query Parameters.
- Enter the following under Parameters and Values:
- Parameter Name:
rewritten_q. - Parameter Value:
<ctx.standalone>. - Update Policy:
replace.
- Parameter Name:
- Save the pipeline.
LWAI Vectorize Query
Configure the LWAI Vectorize Query stage as follows.- Click Add a new pipeline stage > LWAI Vectorize Query.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
- Select Asynchronous Execution Config if you want to run this stage asynchronously. If this field is enabled, complete the following fields:
- Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
signalsoraccess_control. - Copy the Async ID value.
For detailed information, see Enable asynchronous query pipeline processing and Asynchronous query pipeline processing.
- Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
- Select the Account Name.
- Select the Model to use.
- Set the Query Input to
<request.rewritten_q>. - Enter the Output Context Variable as
vector. - Save the pipeline.
Hybrid Query
Configure the Hybrid Query stage as follows.- Click Add a new pipeline stage > Hybrid Query.
- Set the Lexical Query Input as
<request.rewritten_q>. - Enter a value for the Lexical Query Weight, for example,
0.3. - Set the Number of Lexical Results, such as
1000. - In the Vector Query Field, enter the name of the Solr field for KNN vector search.
- Set the Vector Input to
<ctx.vector>. - Enter a value for the Vector Query Weight, for example,
0.7. - Check the box for Use KNN Query.
- Under Use KNN Query, enter Number of Vector Results, such as
1000. - Save the pipeline.
Solr Query
Configure the Solr Query stage as follows.- Select the HTTP Method as POST.
- Make sure the Generate Response Signal is checked.
- Set the Preferred Replica Type to pull.
- Save the pipeline.
LWAI Prediction
Configure the LWAI Prediction stage as follows.- Click Add a new pipeline stage > LWAI Prediction.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
- Select Asynchronous Execution Config if you want to run this stage asynchronously. If this field is enabled, complete the following fields:
- Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
signalsoraccess_control. - Copy the Async ID value.
For detailed information, see Enable asynchronous query pipeline processing and Asynchronous query pipeline processing.
- Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
- Set the Account Name to the Lucidworks AI integration name as defined by your Fusion Administrator.
- Select the Use Case as
rag. - Select the Model to use.
- Set the Input context variable to
<request.rewritten_q>. - Make sure Include Response Documents? is checked.
- Enter values into the Use Case Configuration:
- Parameter Name:
answerNotFoundMessage. - Parameter Value:
Not possible to answer given this content.
- Parameter Name:
- Save the pipeline.
Order the stages
- Make sure the stages are in the following order:
- Additional Query Parameters
- LWAI Query Rewrite
- Additional Query Parameters
- LWAI Vectorize Query
- Hybrid Query
- Solr Query
- LWAI Prediction
- Save the pipeline.