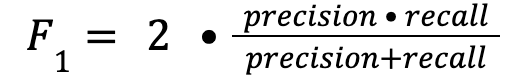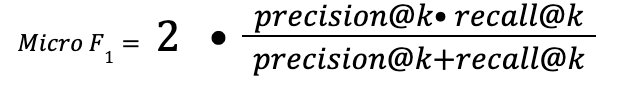topK and similarityCutoff parameters can be used to achieve behaviors where only the following are returned:
- The single most applicable label
- Labels with similarities that exceed a threshold
- A set number of items
- A set number if it exceeds the threshold
For detailed API specifications in Swagger/OpenAPI format, see Platform APIs.
Prerequisites
To use this API, you need:- The unique
APPLICATION_IDfor your Lucidworks AI application. For more information, see credentials to use APIs. - A bearer token generated with a scope value of
machinelearning.predict. For more information, see Authentication API. - The
USE_CASEandMODEL_IDfields for the use case request. The path is:/ai/prediction/USE_CASE/MODEL_ID. A list of supported models is returned in the Lucidworks AI Use Case API.
Unique values for the classification use case
Some parameter values available in theclassification use case are unique to this use case, including values for the useCaseConfig parameter.
Refer to the API spec for more information.
Classification use case example
Classification with 100 classes or less
If there are 100 or fewer classes and labels for the input, Lucidworks recommends you use the Classification use case. Whether you are using a pre-trained model, or a model you have trained, you can list all the possible labels in the requestlabels parameter along with the text to classify. The response returns all labels in descending order of the highest similarity score.
You can also use the topK and similarityCutoff parameters to limit the response and more easily utilize the output labels.
For more information about the parameters, see Unique values for the classification use case.
Classification with more than 100 classes
If there are more than 100 classes or labels, you must incorporate a side-car collection that contains all of the labels.Using the Lucidworks AI embeddings and side-car collection
If you use the Lucidworks AI embeddings models and a side-car collection, the general process flow is as follows:- Use a pre-trained or custom model to vectorize the labels when the side-car collection is indexed.
-
After the labels are indexed, create a query pipeline with a vectorized stage and a hybrid stage to search the labels.
- The query pipeline can also be used in a different query pipeline to check the labels.
- The hybrid stage can be used to replicate the
topKandsimilarityCutoffparameter settings to limit the response and more easily utilize the output labels.
Using the Fusion Smart Answers model and side-car collection
If you use the Fusion Smart Answers Coldstart training or the Smart Answers Supervised Training job, the general process is as follows:-
To format the input, set the
classfield and the field to be classified as a pair of documents in a collection. -
Input the collection into the Fusion job with the following information:
- Specify which field contains the documents to be used to learn about the vocabulary.
- Separate the fields by a comma. For example
class,query.
- Save and run the Fusion job.
- The subsequent model can be used as the model to both index and query the side-car classes’ collection.
Evaluating classification
To evaluate how well the classification is performed, use the F-score metric. This is also referred to as the F1 metric. The formula for the metric is: