Lucidworks Search supports several different query stages that implement Neural Hybrid Search. This topic provides guidance for choosing the right stage for your use case and developing your query pipeline for optimal results.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
Choose a stage
The stage you choose depends on the features you need and your version of Lucidworks Search:| Best for chunking | Best all-around | Deprecated | |
|---|---|---|---|
| Chunking Neural Hybrid Query stage | Neural Hybrid Query stage | Hybrid Query stage | |
| Lucidworks Search support | 5.9.12 and later | 5.9.10 and later | 5.9.5 – 5.9.9 |
| Support for nested/chunked data | |||
| Prefiltering support | |||
| Improved faceting | |||
| Support for collapse | |||
| Key bug fixes | |||
| New query parsers | |||
| Lexical search | |||
| Vector search | |||
| k-Nearest Neighbors (KNN) | |||
| VecSim |
Best practices for implementation
When building a query pipeline with Neural Hybrid Search, apply these best practices to achieve the most relevant results and minimize troubleshooting.Start with a simplified query pipeline
When developing your query pipeline, start with a very simple one containing only the essential stages below, in this order:- LWAI Vectorize Query or Ray/Seldon Vectorize Query
- Query Fields
- Your hybrid query stage (see above for guidance)
- Solr Query
Order your stages carefully
As you add stages to your query pipeline, the order of the stages matters. To get the best results, order the stages according to the guidelines below.Vectorize the query early
Place the LWAI Vectorize Query or Ray/Seldon Vectorize Query stage as early as possible in the query pipeline. This ensures that the query cannot be changed.Only before the NHS stage
If your pipeline includes the stages described below, they must appear before the NHS stages indicated here:| Stage | Chunking Neural Hybrid | Neural Hybrid Query | Hybrid Query |
|---|---|---|---|
| Query Fields | |||
Any stage that modifies disMax/eDisMax params (mm, qf, uf, pf, and so on) | |||
| Text Tagger |
Only after the NHS stage
If your pipeline includes the stages described below, they must appear after the NHS stages indicated here:| Stage | Chunking Neural Hybrid | Neural Hybrid Query | Hybrid Query |
|---|---|---|---|
| Apply Rules | |||
| Boosting stages (such as Boost with Signals, Document Boosting, and so on) | |||
| Security Trimming | |||
| Pre-filtering JavaScript stage (5.9.13) |
Use Solr explain
Lucidworks Search’s query responses include information returned by Solr’sexplain feature, which includes information about how a document’s score was calculated.
In an NHS app, Solr explain provides valuable insight into the variables you can adjust in your pipeline configuration or your model configuration to achieve the best results.
You can find Solr explain information in Lucidworks Search’s search results:
- In JSON results, the field is
debug.explain. - In Query Workbench’s debug view, the field is
explain.
explain field in Query Workbench:
The scoring calculations will vary depending on the query pipeline you’ve built.
In an NHS pipeline,
explain shows you the neural hybrid score, the original score, and the factors used to calculate each, as in this example:
Solr explain example output
Evaluate different configurations
Try creating multiple query pipelines, each configured with different values so you can test different approaches. Compare the results side by side and adjust your pipeline configurations until you get the level of relevance you need. These basic parameters are a good place to start experimenting with different values:- Adjust the value of Lexical Query Squash Factor to experiment with the weight of the lexical score relative to the vector score.
If the first lexical score in Solr
explainis 0.9999, you should lower the squash factor. - Try turning Compute Vector Similarity for Lexical-Only Matches on or off. It must be off if you are using byte vectors.
- See whether you can improve performance by enabling pre-filtering.
Advanced technical tips
This section provides advanced technical tips to help you optimize your Neural Hybrid Search app.Scaling equations and the squash factor
In hybrid search, a scaling equation is the mathematical formula used to combine scores from the two retrieval models (vector + lexical) into a single unified score that determines the final ranking of results. These differ slightly between the newer NHS stages and the deprecated Hybrid Query stage. Click below to compare the scaling equations of the different hybrid query stages:- Chunking Neural Hybrid Query stage + Neural Hybrid Query stage
- Hybrid Query stage (deprecated)
squash factor.
Because lexical scores range from zero to infinity and vector scores range between zero and one, their natural scores are not comparable; vector results would consistently be ranked beneath lexical results.
Squashing compensates for this by converting lexical scores into scores within the same (0–1) range as the vector scores so that they can be compared for ranking in a more balanced way.
In the scaling equations above, squash is tanh(alpha*lexical_score), where alpha is the Lexical Query Squash Factor that you configure in the stage and lexical_score is the lexical score.
Lucidworks recommends setting the Lexical Query Squash Factor to the inverse of the maximum lexical score observed across your queries. This helps balance the impact of lexical and vector scores, leading to more accurate and nuanced search results.
Chunking Neural Hybrid Query stage
-
Use this stage when your index pipeline includes the LWAI Chunker index stage, or when your data is chunked by some other means.
In that index stage:
-
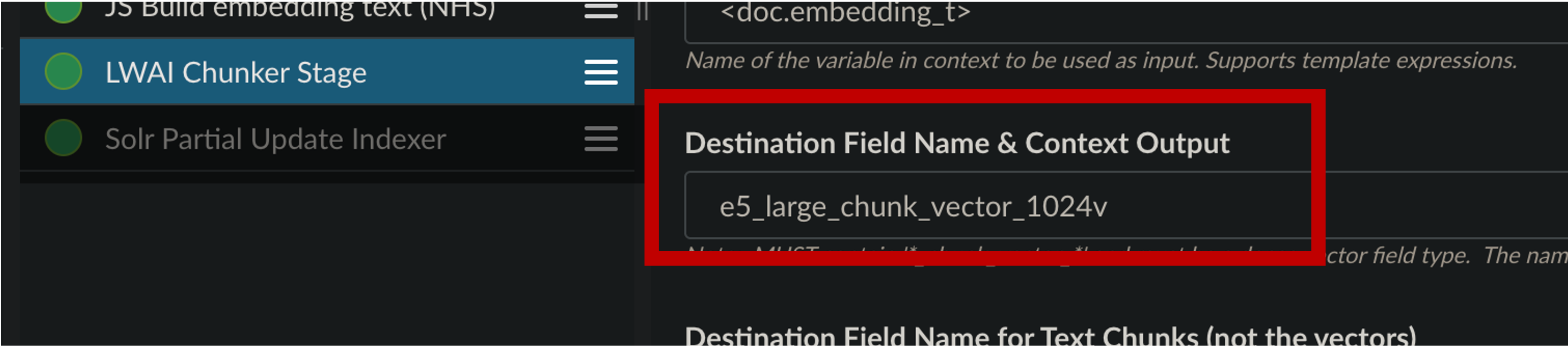
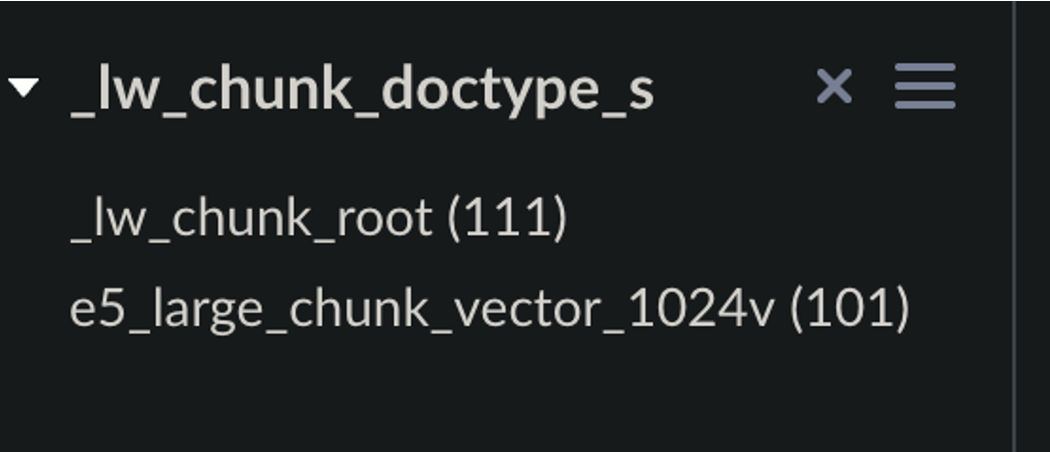
Make sure your indexed data includes a
field _lw_chunk_doctype_sfield whose value is either_lw_chunk_rootor the name of the vector field defined for the children. -
Include one of these values in the chunking index stage:
-
Make sure your indexed data includes a
-
We recommend starting with a new collection for your chunked data.
If not, you must add following to
solrconfig.xml: - To smooth results scores and catch any orphans, turn on Compute Vector Similarity for Lexical-Only Matches. This does impact performance but it also prevents relevant documents from being lost.
Neural Hybrid Query stage
-
We recommend starting with a new collection for your vectorized data.
If not, you must add following to
solrconfig.xml: -
Prefiltering varies in some Lucidworks Search releases:
- In 5.9.12 and later, facet counts are stable regardless of whether pre-filtering is enabled.
- In 5.9.10 and 5.9.11, facet counts are stable only when pre-filtering is blocked.
- When pre-filtering is enabled in 5.9.10 and 5.9.11, all filter queries are included, which can cause inconsistent facet counts.
- To smooth results scores and catch any orphans, turn on Compute Vector Similarity for Lexical-Only Matches. This does impact performance but it also prevents relevant documents from being lost.
-
Make sure the incoming
qparameter is a raw user query string and not a Solr query parser string (such asfield_t:foo). The resulting query is always written to<request.params.q>.
Hybrid Query stage
All documents should have a vector to avoid theno float vector value is indexed for field bug in Lucene.
NRT replicas and HNSW graph challenges
Lucidworks recommends using PULL and TLOG replicas. These replica types copy the index of the leader replica, which results in the same Hierarchical Navigable Small World (HNSW) graph on every replica. When querying, the HNSW approximation query will be consistent given a static index. In contrast, Near Real-Time (NRT) replicas have their own index, so they will also have their own HNWS graph. HNSW is an Approximate Nearest Neighbor (ANN) algorithm, so it will not return exactly the same results for differently constructed graphs. This means that queries performed can and will return different results per HNWS graph (number of NRT replicas in a shard) which can lead to noticeable result shifts. When using NRT replicas, the shifts can be made less noticeable by increasing thetopK parameter. Variation will still occur, but it should be lower in the documents. Another way to mitigate shifts is to use Neural Hybrid Search with a vector similarity cutoff.
For more information, refer to Solr Types of Replicas.
In the case of Neural Hybrid Search, lexical Best Matching 25 (BM25) & Term Frequency–Inverse Document Frequency (TF-IDF) score differences that can occur with NRT replicas because of index differences for deleted documents, can also affect combined Hybrid score.
If you choose to use NRT replicas then it is possible that any lexical and/or semantic vectors variations can and will be exacerbated.
Troubleshooting tips
If you aren’t getting the results you expect, these general troubleshooting tips can help you narrow down the cause of the issue:Check your indexed data.
Check your indexed data.
Inspect your indexed data to verify that vector fields are present.
If not, re-index your data using one of these index stages:
The Vector Query Field value configured in your query pipeline’s hybrid query stage must match the value of the destination field configured in the vector indexing stages above.
Verify that a query parser is present.
Verify that a query parser is present.
Check
Below is the configuration that’s automatically included in newly-created collections for compatibility with all hybrid query stages.
If your query parser is missing, you can paste this snippet into
solrconfig.xml to verify that it includes a queryParser whose name matches your hybrid query stage:| Chunking Neural Hybrid Query stage | Neural Hybrid Query stage | Hybrid Query stage |
|---|---|---|
_lw_chunk_wrap | neuralHybrid | xVecSim |
solrconfig.xml:Query parser configuration
Test a vector-only query.
Test a vector-only query.
Inspect the vector results without the lexical results by creating a special query pipeline that performs only a vector query.
Instead of a hybrid query stage, you can use a JavaScript query stage to create the query, as in this example:
Example JavaScript stage for vector-only queries
Turn query stages off and on.
Turn query stages off and on.
Try disabling and re-enabling different query pipeline stages one at a time, noting any differences in the results.
If results improve when one stage is disabled, the issue may be isolated to that stage.
Check Solr `explain`.
Check Solr `explain`.
Use Solr’s
explain feature to check the variables being used to calculate document scores.
You can use this information to adjust your query pipeline configuration for better results.See Use Solr explain above for details.Check for orphans.
Check for orphans.
Solr’s implementation of dense vector search depends on the Lucene implementation of HNSW ANN.
The Lucene implementation has a known issue where, in some collections, nodes in the HNSW graph become unreachable via graph traversal, essentially becoming disconnected or “orphaned.”Run the following command to identify orphaning:Construct a KNN exclusion query where topK is higher than the number of vectors in your collection.
If the number of vectors in your collection exceeds 999,999 then increase the value to be at least equal to that value.If any are documents returned, those documents are orphans.
If no documents are returned, there are likely no orphans.
You can test a few varying vectors to be certain.To resolve orphans, do the following:
If the collection doesn’t have a vector for every document, include a filter so only the documents that have vectors are included. Filter on the boolean vector, as in this example:
--form-string 'fq=VECTOR_FIELD_b:true' \- Increase the HNSW Solr schema parameters
hnswBeamWidthandhnswMaxConnectionsper the Suggested values below. - Save the schema.
- Clear the index.
- Re-index your collection.
| Orphaning rate | hnswBeamWidth | hnswMaxConnections |
|---|---|---|
| 5% or less | 300 | 64 |
| 5% - 25% | 500 | 100 |
| 25% or more | 3200 | 512 |
Reconfigure highlighting.
Reconfigure highlighting.
Highlighting can conflict with the hybrid stages.
If you have configured highlighting, you might see query failures with errors like
Index _ out of bounds for length _.To resolve this issue, set hl.q to the lexical-only query parameter <request.params.q> before the hybrid stage, or <request.params.raw_lex_q>.