The Ray/Seldon Vectorize Field stage invokes a machine learning model to encode a string field to a vector representation. In Lucidworks Search 5.9.11 and earlier, this stage is called Seldon Vectorize Field.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
Configure Ray/Seldon vector search
Configure Ray/Seldon vector search
You can use Seldon or Ray models to vectorize text for Neural Hybrid Search.To vectorize text with Ray, you first need to develop and deploy a machine learning model with Ray.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
Prerequisites
Seldon
To vectorize text with Seldon, you’ll first need to develop and deploy a machine learning model.Ray
This feature is available starting in Lucidworks Search 5.9.12 and in all subsequent Lucidworks Search 5.9 releases.
Configure index pipeline
- Sign into Lucidworks Search, go to Indexing > Index Pipelines, then select an existing pipeline or create a new one.
- Click Add a new pipeline stage, then select Ray/Seldon Vectorize Field. In Lucidworks Search 5.9.11 and earlier, this stage is called Seldon Vectorize Field.
- Fill in the required fields:
- Enter a Model ID. This is the name of the model you developed and deployed.
- Enter the Model Input Field. For example,
text. - Enter the Model Output Vector Field. For example,
vector. - Enter the Source Field. For example,
body_t. - Enter the Destination Field. For example,
body_512_v.
- Click Save.
- Make sure the Ray/Seldon Vectorize Field stage is ordered before the Solr Indexer stage.
Configure query pipeline
- Go to Querying > Query Pipelines, then select an existing pipeline.
- Click Add a new pipeline stage, then select Ray/Seldon Vectorize Query. In Lucidworks Search 5.9.11 and earlier, this stage is called Seldon Vectorize Query.
- Fill in the required fields, making sure to search against the field into which you indexed the vectors:
- Enter a Model ID. This is the name of the model you developed and deployed.
- Enter the Query Input.
- Enter the Model Input Field. For example,
text. - Enter the Model Output Vector Field. For example,
vector. - Enter the Vector Context Key. For example,
vector.
- Click Save.
- Make sure the Ray/Seldon Vectorize Query stage is ordered before the Solr Query stage.
Perform vector searches
After setting up the stages, you can perform vector searches via theknn query parser as you would with Solr. Specify the search vector and include it in the query. For example, change the q parameter to a knn query parser string.The Ray/Seldon Vectorize Query stage will encode user queries using the specified model and modify the q parameter to use the knn query parser, turning the query into a vector search.Develop and deploy a machine learning model with Ray
Develop and deploy a machine learning model with Ray
This tutorial walks you through deploying your own model to Fusion with Ray.A real instance of this class with the In the preceding code, logging has been added for debugging purposes.The preceding code example contains the following functions:In the preceding example, the Python file is named Any recent ray[serve] version should work, but the tested value and known supported version is 2.42.1.
In general, if an item was used in an Using the example model, the terminal commands would be as follows:This repository is public and you can visit it here: e5-small-v2-ray
This feature is only available in Fusion 5.9.x for versions 5.9.12 and later.
Prerequisites
- A Fusion instance with an app and indexed data.
- An understanding of Python and the ability to write Python code.
- Docker installed locally, plus a private or public Docker repository.
- Ray installed locally:
pip install ray[serve]using the version of ray[serve] found in the release notes for your version of Lucidworks Search. - Code editor; you can use any editor, but Visual Studio Code is used in this example.
- Model: intfloat/e5-small-v2
- Docker image: e5-small-v2-ray
Tips
- Always test your Python code locally before uploading to Docker and then Fusion. This simplifies troubleshooting significantly.
- Once you’ve created your Docker you can also test locally by doing
docker runwith a specified port, like 9000, which you can thencurlto confirm functionality in Fusion. See the testing example below. - If you previously deployed a model with Seldon, you can deploy the same model with Ray after making a few changes to your Docker image as explained in this topic. To avoid conflicts, deploy the model with a different name. When you have verified that the Ray model is working after deployment with Ray, you can delete the Seldon model using the Delete Seldon Core Model Deployment job.
- If you run into an issue with the model not deploying and you’re using the ‘real’ example, there is a very good chance you haven’t allocated enough memory or CPU in your job spec or in the Ray-Argo config.
It’s easy to increase the resources. To edit the ConfigMap, run
kubectl edit configmap argo-deploy-ray-model-workflow -n <namespace>and then find theray-headcontainer in the artisanal escaped YAML and change the memory limit. Exercise caution when editing because it can break the YAML. Just delete and replace a single character at a time without changing any formatting.- For additional guidance, see the testing locally e5-model example.
Intro to Machine Learning in Fusion
The course for Intro to Machine Learning in Fusion focuses on using machine learning to infer the goals of customers and users in order to deliver a more sophisticated search experience.
Local testing example
- Docker command:
- Curl to hit Docker:
- Curl model in Fusion:
- See all your deployed models:
- Check the Ray UI to see Replica State, Resources, and Logs.
If you are getting an internal model error, the best way to see what is going on is to query via port-forwarding the model.
TheMODEL_DEPLOYMENTin the command below can be found withkubectl get svc -n NAMESPACE. It will have the same name as set in the model name in the Create Ray Model Deployment job.Once port-forwarding is successful, you can use the below cURL command to see the issue. At that point your worker logs should show helpful error messages.
Download the model
This tutorial uses thee5-small-v2 model from Hugging Face, but any pre-trained model from https://huggingface.co will work with this tutorial.If you want to use your own model instead, you can do so, but your model must have been trained and then saved though a function similar to the PyTorch’s torch.save(model, PATH) function.
See Saving and Loading Models in the PyTorch documentation.Format a Python class
The next step is to format a Python class which will be invoked by Fusion to get the results from your model. The skeleton below represents the format that you should follow. See also Getting Started in the Ray Serve documentation.e5-small-v2 model is as follows:This code pulls from Hugging Face. To have the model load in the image without pulling from Hugging Face or other external sources, download the model weights into a folder name and change the model name to the folder name preceded by
./.__call__: This function is non-negotiable.init: Theinitfunction is where models, tokenizers, vectorizers, and the like should be set to self for invoking. It is recommended that you include your model’s trained parameters directly into the Docker container rather than reaching out to external storage insideinit.encode: Theencodefunction is where the field or query that is passed to the model from Fusion is processed. Alternatively, you can process it all in the__call__function, but it is cleaner not to. Theencodefunction can handle any text processing needed for the model to accept input invoked in itsmodel.predict()or equivalent function which gets the expected model result.
Use the exact name of the class when naming this file.
deployment.py and the class name is Deployment().Create a Dockerfile
The next step is to create a Dockerfile. The Dockerfile should follow this general outline; read the comments for additional details:Create a requirements file
Therequirements.txt file is a list of installs for the Dockerfile to run to ensure the Docker container has the right resources to run the model.
For the e5-small-v2 model, the requirements are as follows:import statement in your Python file, it should be included in the requirements file.To populate the requirements, use the following command in the terminal, inside the directory that contains your code:Build and push the Docker image
After creating theMODEL_NAME.py, Dockerfile, and requirements.txt files, you need to run a few Docker commands.
Run the following commands in order:Deploy the model in Fusion
Now you can go to Fusion to deploy your model.When deploying your Ray model, you have two options for handling traffic:- Use a single deployment. Deploy one model job that handles both indexing and query traffic. This is simpler to manage and requires only one deployment.
- Use separate deployments for indexing and querying. Deploy two separate model jobs: one dedicated to indexing and another for query traffic. This approach eliminates the risk of indexing workloads impacting query response times, providing better performance isolation and independent scaling control.
EXAMPLE_MODEL_INDEX and EXAMPLE_MODEL_QUERY). Use the index-specific model in your index pipeline stages and the query-specific model in your query pipeline stages. To keep both deployments in sync, ensure both jobs use the exact same model name, Ray deployment import path, Docker repository, and image name.- In Fusion, navigate to Collections > Jobs.
- Add a job by clicking the Add+ Button and selecting Create Ray Model Deployment.
-
Fill in each of the text fields:
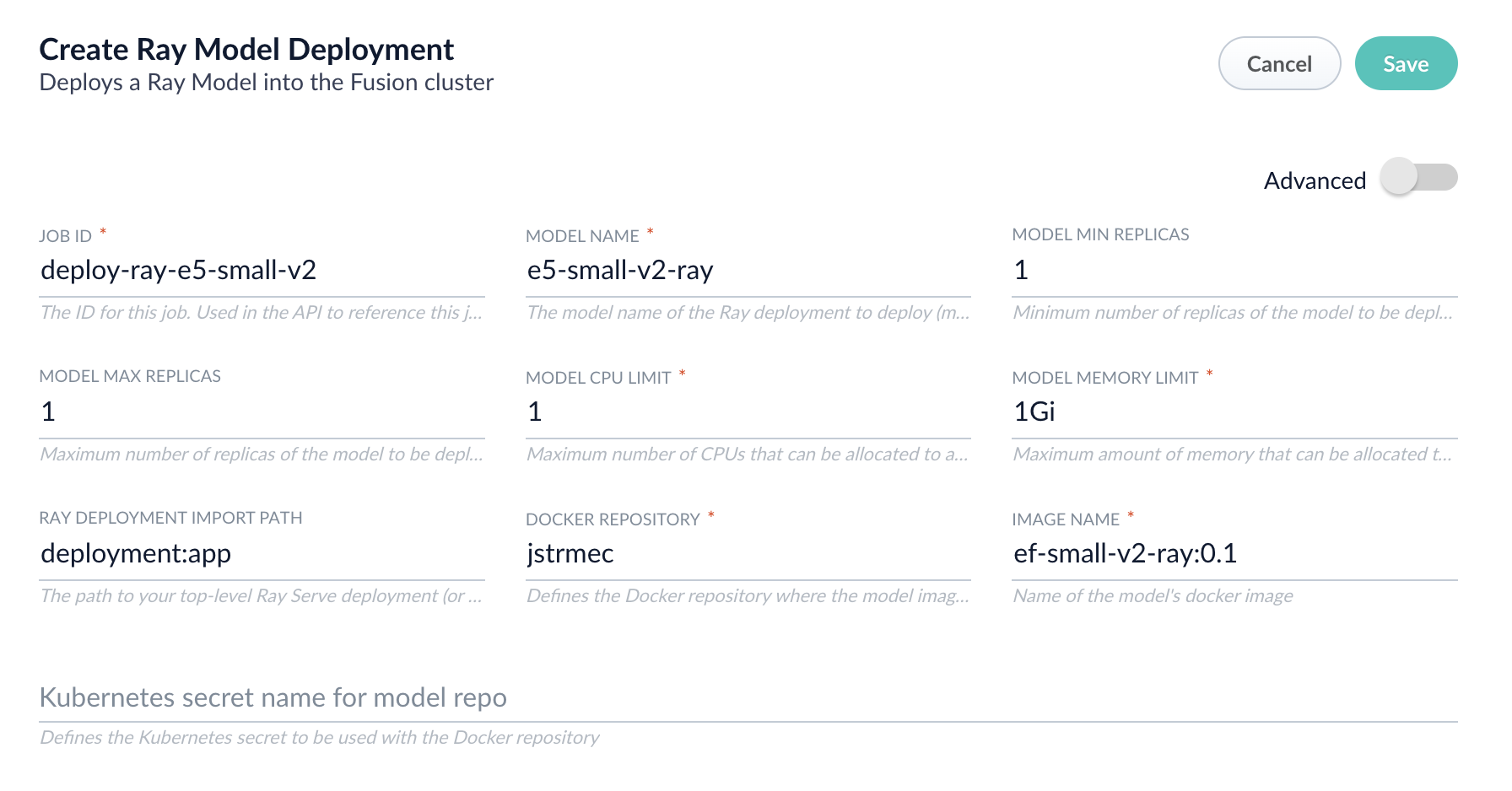
Parameter Description Job ID A string used by the Fusion API to reference the job after its creation. Model name A name for the deployed model. This is used to generate the deployment name in Ray. It is also the name that you reference as a model-idwhen making predictions with the ML Service.Model min replicas The minimum number of load-balanced replicas of the model to deploy. Model max replicas The maximum number of load-balanced replicas of the model to deploy. Specify multiple replicas for a higher-volume intake. Model CPU limit The number of CPUs to allocate to a single model replica. Model memory limit The maximum amount of memory to allocate to a single model replica. Ray Deployment Import Path The path to your top-level Ray Serve deployment (or the same path passed to serve run). For example,deployment:appDocker Repository The public or private repository where the Docker image is located. If you’re using Docker Hub, fill in the Docker Hub username here. Image name The name of the image. For example, e5-small-v2-ray:0.1.Kubernetes secret If you’re using a private repository, supply the name of the Kubernetes secret used for access. -
Click Advanced to view and configure advanced details:
Parameter Description Additional parameters. This section lets you enter parameter name:parametervalue options to be injected into the training JSON map at runtime. The values are inserted as they are entered, so you must surround string values with". This is the sparkConfig field in the configuration file.Write Options. This section lets you enter parameter name:parametervalue options to use when writing output to Solr or other sources. This is the writeOptions field in the configuration file.Read Options. This section lets you enter parameter name:parametervalue options to use when reading input from Solr or other sources. This is the readOptions field in the configuration file. -
Click Save, then Run and Start.
Configure the Fusion pipelines
Your real-world pipeline configuration depends on your use case and model, but for our example we will configure the index pipeline and then the query pipeline.Configure the index pipeline- Create a new index pipeline or load an existing one for editing.
- Click Add a Stage and then Machine Learning.
- In the new stage, fill in these fields:
- The model ID
- The model input
- The model output
- Save the stage in the pipeline and index your data with it.
- Create a new query pipeline or load an existing one for editing.
- Click Add a Stage and then Machine Learning
- In the new stage, fill in these fields:
- The model ID
- The model input
- The model output
- Save the stage and then run a query by typing a search term.
- To verify the Ray results are correct, use the Compare+ button to see another pipeline without the model implementation and compare the number of results.
ImportantThis index stage must be placed before the Solr Indexer stage.