Released on August 27, 2024, this maintenance release includes the new Neural Hybrid Search capability, as well as upgrades to Solr, Kubernetes, Zookeeper, and some bug fixes. To learn more, skip to the release notes.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
Platform Support and Component Versions
Kubernetes platform support
Lucidworks has tested and validated support for the following Kubernetes platform and versions:- Google Kubernetes Engine (GKE): 1.28, 1.29, 1.30
Component versions
The following table details the versions of key components that may be critical to deployments and upgrades.| Component | Version |
|---|---|
| Solr | fusion-solr 5.9.5 (based on Solr 9.6.1) |
| ZooKeeper | 3.9.1 |
| Spark | 3.2.2 |
| Ingress Controllers | Nginx, Ambassador (Envoy), GKE Ingress Controller Istio not supported. |
New Features
Neural Hybrid Search
Lucidworks Search 5.9.5 introduces Neural Hybrid Search, a capability that combines lexical and semantic vector search. This feature includes:- A new index pipeline to vectorize fields with Lucidworks AI. See Configure the LWAI Vectorize pipeline.
- A new query pipeline to set up Neural Hybrid Search with Lucidworks AI. See Configure the LWAI Neural Hybrid Search pipeline.
- Query and index stages for vectorizing text using Lucidworks AI. See LWAI Vectorize Query stage and LWAI Vectorize Field stage.
- Query and index stages for vectorizing text with Seldon. See Seldon Vectorize Query stage and Seldon Vectorize Field stage.
- A new query stage for hybrid search that works with Lucidworks AI or Seldon. See Hybrid Query stage.
- A new service,
lwai-gateway, provides a secure, authenticated connection between Lucidworks Search and your Lucidworks AI-hosted models.
See Lucidworks AI Gateway for details. - Solr config changes to support dense vector dynamic fields.
- A custom Solr plugin containing a new
vectorSimilarityQParser that will not be available in Apache Solr until 9.7.
Neural Hybrid Search
The course for Neural Hybrid Search focuses on how neural hybrid search combines lexical and semantic search to improve the relevance and accuracy of results.
Configure use case for embedding
In the LWAI Vectorize Field stage, you can specify the use case for your embedding model. To learn how to configure your embedding use case, see the following demonstration:Fine tune lexical and semantic settings
The Hybrid Query stage is highly customizable. You can lower the Min Return Vector Similarity threshold for vector results to include more semantic results. For example, a lower threshold would return “From Dusk Till Dawn” when queryingnight against a movie dataset. A higher threshold prioritizes high scoring results and in this case only returns movie names with night in the title.
To learn how to configure the Hybrid Query stage, see the following demonstration:
Vector dimension size
There is no limitation on vector dimension sizes. If you’re setting up vector search and Neural Hybrid Search with an embedding model with large dimensions, simply configure your managed-schema to support the appropriate dimension. See Configure Neural Hybrid Search.Configure Neural Hybrid Search
Configure Neural Hybrid Search
Neural Hybrid Search combines lexical-semantic search with semantic vector search.To use semantic vector search in Lucidworks Search, you need to configure Neural Hybrid Search.
Then you can choose the balance between lexical and semantic vector search that works best for your use case.Before you begin, see Neural Hybrid Search for conceptual information that can help you understand how to configure this feature.This query stage must be placed before the Solr Query stage.Construct a KNN exclusion query where topK is higher than the number of vectors in your collection
If the number of vectors in your collection exceeds 999,999 then increase the value to be at least equal to that value.If any are documents returned, there are orphans, and the
This feature is currently only available to clients who have contracted with Lucidworks for features related to Neural Hybrid Search and Lucidworks AI.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
Configure vector search
This section explains how to configure vector search using Lucidworks AI, but you can also configure it using Ray or Seldon.Before you set up the Lucidworks AI index and query stages, make sure you have set up your Lucidworks AI Gateway integration.Configure the LWAI Vectorize Field index stage
To vectorize the index pipeline fields:- Sign in to Lucidworks Search and click Indexing > Index Pipelines.
- Click the pipeline you want to use.
- Click Add a new pipeline stage.
- In the AI section, click LWAI Vectorize Field.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
- In the Account Name field, select the Lucidworks AI API account name defined in Lucidworks AI Gateway. If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
- In the Model field, select the Lucidworks AI model to use for encoding. If you do not see your model name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks. For more information about models, see:
- In the Source field, enter the name of the string field where the value should be submitted to the model for encoding. If the field is blank or does not exist, this stage is not processed. Template expressions are supported.
- In the Destination field, enter the name of the field where the vector value from the model response is saved.
{Destination Field}is the vector field.{Destination Field}_bis the boolean value if the vector has been indexed.
- In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. - Optionally, you can use the Model Configuration section for any additional parameters you want to send to Lucidworks AI.
Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs while generating a prediction for a document.
- Click Save.
- Index data using the new pipeline. Verify the vector field is indexed by confirming the field is present in documents.
Configure the LWAI Vectorize query stage
To vectorize the query in the query pipeline:- Sign in to Lucidworks Search and click Querying > Query Pipelines.
- Select the pipeline you want to use.
- Click Add a new pipeline stage.
- Click LWAI Vectorize Query.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
-
Select Asynchronous Execution Config if you want to run this stage asynchronously. If this field is enabled, complete the following fields:
-
Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
signalsoraccess_control. -
Copy the Async ID value.
For detailed information, see Asynchronous query pipeline processing.
-
Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
- In the Account Name field, select the name of the Lucidworks AI account. If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
-
In the Model field, select the Lucidworks AI model to use for encoding.
If you do not see any model names and you are a non-admin Fusion user, verify with a Fusion administrator that your user account has these permissions:
PUT,POST,GET:/LWAI-ACCOUNT-NAME/**For more information about models, see: - In the Query Input field, enter the location from which the query is retrieved.
- In the Output context variable field, enter the name of the variable where the vector value from the response is saved.
-
In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. -
Optionally, you can use the Model Configuration section for any additional parameters you want to send to Lucidworks AI.
Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs during this stage.
- Click Save.
The Top K setting is 100 by default, but a value as high as 1000 provides better recall if you have fewer than one million indexed documents.
You can raise it even higher, but keep in mind that higher recall also causes higher latency.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
Modify Solr managed-schema (5.9.4 and earlier)
This step is required if you’re migrating a collection from a version of Lucidworks Search that does not support Neural Hybrid Search. If creating a new collection in Lucidworks Search 5.9.5, you can continue to Configure Hybrid Query stage.- Go to System > Solr Config and then click managed-schema to edit it.
-
Comment out
<copyField dest="\_text_" source="*"/>and add<copyField dest="text" source="*_t"/>below it. This will concatenate and index all*_t fields. -
Add the following code block to the managed-schema file:
This example uses 512 vector dimension. If your model uses a different dimension, modify the code block to match your model. For example,
_1024v. There is no limitation on supported vector dimensions.
Configure neural hybrid queries
In Lucidworks Search 5.9.10 and later, you use the Neural Hybrid Query stage to configure neural hybrid queries. In Lucidworks Search 5.9.9 and earlier, you use the Hybrid Query stage.Configure the Neural Hybrid Query stage (5.9.10 and later)
Configure the Neural Hybrid Query stage in Lucidworks Search 5.9.10 and later.- In the same query pipeline where you configured vector search, click Add a new pipeline stage, then select Neural Hybrid Query.
- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example, <request.params.q>. Template expressions are supported.
- In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Lexical Query Squash Factor field, enter a value that will be used to squash the lexical query score. The squash factor controls how much difference there is between the top-scoring documents and the rest. It helps ensure that documents with slightly lower scores still have a chance to show up near the top. For this value, Lucidworks recommends entering the inverse of the lexical maximum score across all queries for the given collection.
- In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
-
In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
- In the Min Return Vector Similarity field, enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- In the Min Traversal Vector Similarity field, enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query.
- When enabled, the Compute Vector Similarity for Lexical-Only Matches setting computes vector similarity scores for documents in lexical search results but not in the initial vector search results. Select the checkbox to enable this setting.
-
If you want to use pre-filtering:
-
Uncheck Block pre-filtering.
In the Javascript context (
ctx), thepreFilterKeyobject becomes available. -
Add a Javascript stage after the Neural Hybrid Query stage and use it to configure your pre-filter.
The
preFilterobject adds both the top-levelfqandpreFilterto the parameters for the vector query. You do not need to manually add the top levelfqin the javascript stage. See the example below:
-
Uncheck Block pre-filtering.
In the Javascript context (
- Click Save.
solrconfig.xml within the <config> tag:Configure the Hybrid Query stage (5.9.9 and earlier)
If you’re setting up Neural Hybrid Search in Lucidworks Search 5.9.9 and earlier, use the Hybrid Query stage. If you’re using Lucidworks Search 5.9.10 or later, use the Neural Hybrid Query stage.- In the same query pipeline where you configured vector search, click Add a new pipeline stage, then select Hybrid Query.
- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example, <request.params.q>. Template expressions are supported.
- In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Number of Lexical Results field, enter the number of lexical search results to include in re-ranking. For example, 1000. A value is 0 is ignored.
- In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
- In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
- Select the Use KNN Query checkbox to use the knn query parser and configure its options. This option cannot be selected if Use VecSim Query checkbox is selected. In addition, Use KNN Query is used if neither Use KNN Query or Use VecSim Query is selected.
- If the Use KNN Query checkbox is selected, enter a value in the Number of Vector Results field. For example, 1000.
- Select the Use VecSim Query checkbox to use the vecSim query parser and configure its options. This option cannot be selected if Use KNN Query checkbox is selected.
If the Use VecSim Query checkbox is selected, enter values in the following fields:
- Min Return Vector Similarity. Enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- Min Traversal Vector Similarity. Enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query. The value must be lower than, or equal to, the value in the Min Return Vector Similarity field.
- In the Minimum Vector Similarity Filter, enter the value for a minimum similarity threshold for filtering documents. This option applies to all documents, regardless of other score boosting such as rules or signals.
- Click Save.
Perform hybrid searches
After setting up the stages, you can perform hybrid searches via theknn query parser as you would with Solr. Specify the search vector and include it in the query. For example, change the q parameter to a knn query parser string.You can also preview the results in the Query Workbench.
Try a few different queries, and adjust the weights and parameters in the Hybrid Query stage to find the best balance between lexical and semantic vector search for your use case.
You can also disable and re-enable the Neural Hybrid Query stage to compare results with and without it.XDenseVectorField is not supported in Lucidworks Search 5.9.5. Instead, use DenseVectorField.Troubleshoot inconsistent results
Neural Hybrid Search leverages Solr semantic vector search, which has known behaviors which can be inconsistent at query time. These behaviors include score fluctuations with re-querying, documents showing and disappearing on re-querying, and (when SVS is configured without Hybrid stages) completely unfindable documents. This section outlines possible reasons for inconsistent behavior and resolutions steps.NRT replicas and HNSW graph challenges
Lucidworks recommends using PULL and TLOG replicas. These replica types copy the index of the leader replica, which results in the same HNSW graph on every replica. When querying, the HNSW approximation query will be consistent given a static index.In contrast, NRT replicas have their own index, so they will also have their own HNWS graph. HNSW is an Approximate Nearest Neighbor (ANN) algorithm, so it will not return exactly the same results for differently constructed graphs. This means that queries performed can and will return different results per HNWS graph (# of NRT replicas in a shard) which can lead to noticeable result shifts. When using NRT replicas, the shifts can be made less noticeable by increasing thetopK parameter. Variation will still occur, but should be lower in the documents. Another way to mitigate shifts is to use Neural Hybrid Search with a vector similarity cutoff.For more information, refer to Solr Types of Replicas.In the case of Neural Hybrid Search, lexical BM25 and TF-IDF score differences that can occur with NRT replicas because of index differences for deleted documents can also affect combined Hybrid score.
If you choose to use NRT replicas, then it is possible that any lexical and semantic vectors variations can and will be made worse.Orphaning (Disconnected Nodes)
Solr’s implementation of dense vector search depends on the Lucene implementation of HNSW ANN. The Lucene implementation has a known issue where, in some collections, nodes in the HNSW graph become unreachable via graph traversal, essentially becoming disconnected or “orphaned.”Identify orphaning
Run the following command to identify orphaning:If the collection doesn’t have a vector for every document, include a filter so only the documents that have vectors are included. Filter on the boolean vector, as in this example:
--form-string 'fq=VECTOR_FIELD_b:true' \ids you see are the orphans.
Proceed to Resolving orphans.
If no documents are returned, there are likely no orphans.
You can try a few varying vectors to be certain.Resolving orphans
To resolve orphans, do the following:- Increase the HNSW Solr schema parameters
hnswBeamWidthandhnswMaxConnectionsper the Suggested values below. - Save the schema.
- Clear the index.
- Re-index your collection.
Suggested values
| Orphaning rate | hnswBeamWidth | hnswMaxConnections |
|---|---|---|
| 5% or less | 300 | 64 |
| 5% - 25% | 500 | 100 |
| 25% or more | 3200 | 512 |
Improvements
- Lucidworks Search now supports Kubernetes 1.30 for GKE. Refer to Kubernetes documentation at Kubernetes v1.30 for more information.
- Solr has been upgraded to 9.6.1.
- Zookeeper has been upgraded to 3.9.1.
-
The default value for
kafka.logRetentionBytesis increased to 5 GB. This improvement helps prevent failed datasource jobs due to full disk space. Refer to Troubleshoot failed datasource jobs.
Troubleshoot failed datasource jobs
Troubleshoot failed datasource jobs
When indexing large files, or large quantities of files, you may encounter issues such as datasource jobs failing or documents not making it into Fusion.
Overview
When data flows into Fusion, it passes through a Kafka topic first. When the number of documents being created by a connector is large, or when the connector is pulling data into the Kafka topic faster than it can be indexed, the topic fills up and the datasource job fails. For example, if your connector is inputting a large CSV file where every row is imported as a separate Solr document, the indexing processing can time out before the document is fully ingested.Identify the cause
If you experience failed datasource jobs or notice your connector isn’t grabbing all the documents it should, check the logs for the Kafka pod. Look for a message containing the phrasesresetting offset and is out of range, which indicate data has been dropped.Adjust indexing settings
If you determine that your datasource job is failing due to an issue in Kafka, there are a few options to try.Adjust retention parameters
One solution is to increase the Kafka data retention parameters to allow for larger documents. You can configure these settings in yourvalues.yaml file in the Helm chart.-
The default value for
kafka.logRetentionBytesis1073741824bytes (1 GB). Try increasing this value to2147483648bytes (2 GB) or3221225472(3 GB), or larger depending on the size of your documents.You can also set this toIn Fusion 5.9.5, the default value is increased to 5 GB.-1to remove the size limit. If you do this, be sure to set an appropriate limit forlogRetentionHoursinstead. -
The default value for
kafka.logRetentionHoursis168(7 days). If you increasekafka.logRetentionBytesby a significant amount (for example, 20 GB), you might need to decrease this setting to prevent running out of disk space. However, because older log entries are deleted when either limit is reached, you should set it high enough to ensure the data remains available until it’s no longer needed. - In Fusion, go to Indexing > Datasources and create a new datasource to trigger a new Kafka topic that incorporates these settings.
Adjust fetch settings
Another option is to decrease the values for number of fetch threads and request page size in your datasource settings.- In Fusion, go to Indexing > Datasources and click your datasource.
- Click the Advanced slider to show more settings.
-
Reduce the number of Fetch Threads.
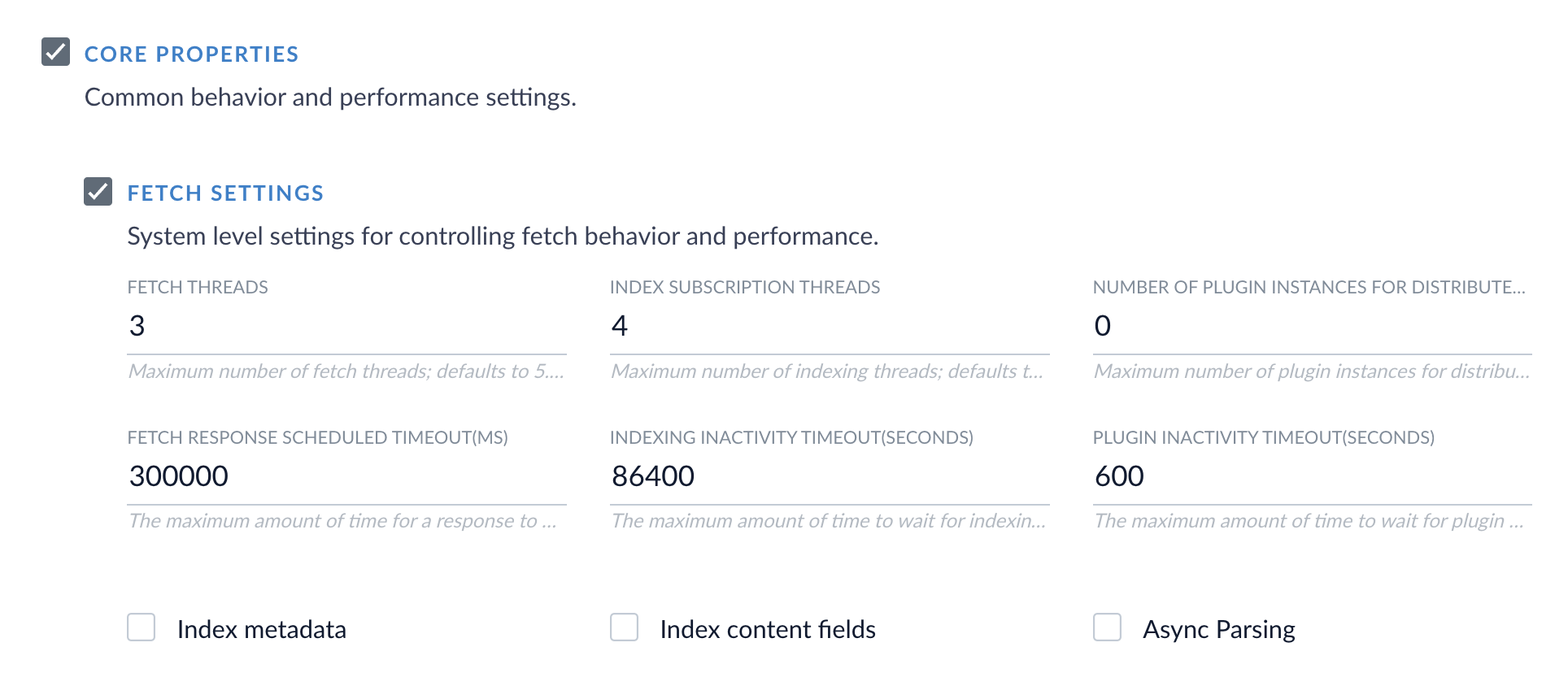
-
Reduce the Request Page Size.
 This setting might not be available in every connector.
This setting might not be available in every connector.
-
There is a new AI category in the Add a new pipeline stage dropdown for Query and Index Pipelines. This category contains the new stages for Neural Hybrid Search, as well as existing machine learning and AI stages.
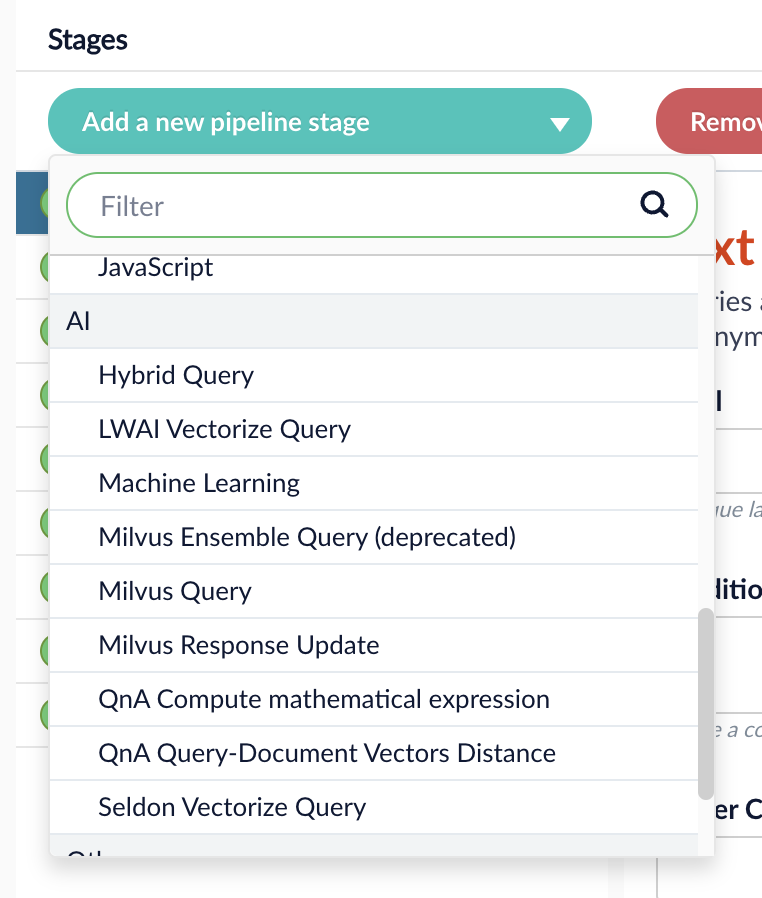
-
The Lucidworks Search migration script is updated to align with changes from the Solr upgrade. The migration script:
- Removes the unused configuration,
<circuitBreaker>, fromsolrconfig.xml. Solr no longer supports this configuration. - Removes the query response writer of class
solr.XSLTResponseWriter. - Comments out processors of type
solr.StatelessScriptUpdateProcessorFactory. - Removes
<bool name="preferLocalShards"/>element from request handler. - Changes cache class attribute of elements
"filterCache","cache","documentCache","queryResultCache"tosolr.search.CaffeineCache. - Removes
keepShortTermattribute from filter of classsolr.NGramFilterFactory.
- Removes the unused configuration,
-
Added the parameter
job-expiration-duration-secondsfor remote connectors that lets you configure the timeout value. Refer to Configure Remote V2 Connectors.
Configure Remote V2 Connectors
Configure Remote V2 Connectors
If you need to index data from behind a firewall, you can configure a V2 connector to run remotely on-premises using TLS-enabled gRPC.The
Remote V2 Connectors are not available by default. Contact your Lucidworks representative for more information about enabling them in your Lucidworks Search deployment.
Prerequisites
Before you can set up an on-prem V2 connector, you must configure the egress from your network to allow HTTP/2 communication into the Fusion cloud. You can use a forward proxy server to act as an intermediary between the connector and Fusion.The following is required to run V2 connectors remotely:- The plugin zip file and the connector-plugin-standalone JAR.
- A configured connector backend gRPC endpoint.
- Username and password of a user with a
remote-connectorsoradminrole. This step is performed by Lucidworks. - If the host where the remote connector is running is not configured to trust the server’s TLS certificate, Lucidworks must help configure the file path of the trust certificate collection.
If your version of Fusion doesn’t have the
remote-connectors role by default, Lucidworks can create one. No API or UI permissions are required for the role.Connector compatibility
Only V2 connectors are able to run remotely on-premises.The gRPC connector backend is not supported in Fusion environments deployed on AWS.System requirements
The following is required for the on-prem host of the remote connector:- (Lucidworks Search 5.9.0-5.9.10) JVM version 11
- (Lucidworks Search 5.9.11) JVM version 17
- Minimum of 2 CPUs
- 4GB Memory
Enable backend ingress
NOTE: Contact Lucidworks support to complete this step.In yourrpc-service/values.yaml file, configure this section as needed:-
Set
enabledtotrueto enable the backend ingress. -
Set
pathtypetoPrefixorExact. -
Set
pathto the path where the backend will be available. -
Set
hostto the host where the backend will be available. -
In Fusion 5.9.6 only, you can set
ingressClassNameto one of the following:nginxfor Nginx Ingress Controlleralbfor AWS Application Load Balancer (ALB)
-
Configure TLS and certificates according to your CA’s procedures and policies.
TLS must be enabled in order to use AWS ALB for ingress.
Connector configuration example
Minimal example
Logback XML configuration file example
Run the remote connector
logging.config property is optional. If not set, logging messages are sent to the console.Test communication
You can run the connector in communication testing mode. This mode tests the communication with the backend without running the plugin, reports the result, and exits.Encryption
In a deployment, communication to the connector’s backend server is encrypted using TLS. You should only run this configuration without TLS in a testing scenario. To disable TLS, setplain-text to true.Egress and proxy server configuration
One of the methods you can use to allow outbound communication from behind a firewall is a proxy server. You can configure a proxy server to allow certain communication traffic while blocking unauthorized communication. If you use a proxy server at the site where the connector is running, you must configure the following properties:- Host. The hosts where the proxy server is running.
- Port. The port the proxy server is listening to for communication requests.
- Credentials. Optional proxy server user and password.
Password encryption
If you use a login name and password in your configuration, run the following utility to encrypt the password:- Enter a user name and password in the connector configuration YAML.
-
Run the standalone JAR with this property:
- Retrieve the encrypted passwords from the log that is created.
- Replace the clear password in the configuration YAML with the encrypted password.
Connector restart (5.7 and earlier)
The connector will shut down automatically whenever the connection to the server is disrupted, to prevent it from getting into a bad state. Communication disruption can happen, for example, when the server running in theconnectors-backend pod shuts down and is replaced by a new pod. Once the connector shuts down, connector configuration and job execution are disabled. To prevent that from happening, you should restart the connector as soon as possible.You can use Linux scripts and utilities to restart the connector automatically, such as Monit.Recoverable bridge (5.8 and later)
If communication to the remote connector is disrupted, the connector will try to recover communication and gRPC calls. By default, six attempts will be made to recover each gRPC call. The number of attempts can be configured with themax-grpc-retries bridge parameters.Job expiration duration (5.9.5 only)
The timeout value for irresponsive backend jobs can be configured with thejob-expiration-duration-seconds parameter. The default value is 120 seconds.Use the remote connector
Once the connector is running, it is available in the Datasources dropdown. If the standalone connector terminates, it disappears from the list of available connectors. Once it is re-run, it is available again and configured connector instances will not get lost.Enable asynchronous parsing (5.9 and later)
To separate document crawling from document parsing, enable Tika Asynchronous Parsing on remote V2 connectors.-
Added additional diagnostics between the
connectors-backendandfusion-indexingservices. - Added more detail to the messages that appear in the Lucidworks Search UI when a connector job fails.
-
Added the
resetaction parameter to thesubscriptions/{id}/refresh?action=some-actionPOST API endpoint. Callingresetwill clear the subscription indexing topic from pending documents. See Indexing APIs.
Bug fixes
- Fixed an issue that prevented successful configuration of new Kerberos security realms for authentication of external applications.
Deprecations
For full details on deprecations, see Deprecations and Removals. With the release of Solr supported embeddings and Solr Semantic Vector Search, Lucidworks is deprecating Milvus. The following Milvus query stages are deprecated and will be removed in a future release:- Milvus Ensemble Query Stage
- Milvus Query Stage
- Milvus Response Update Query Stage