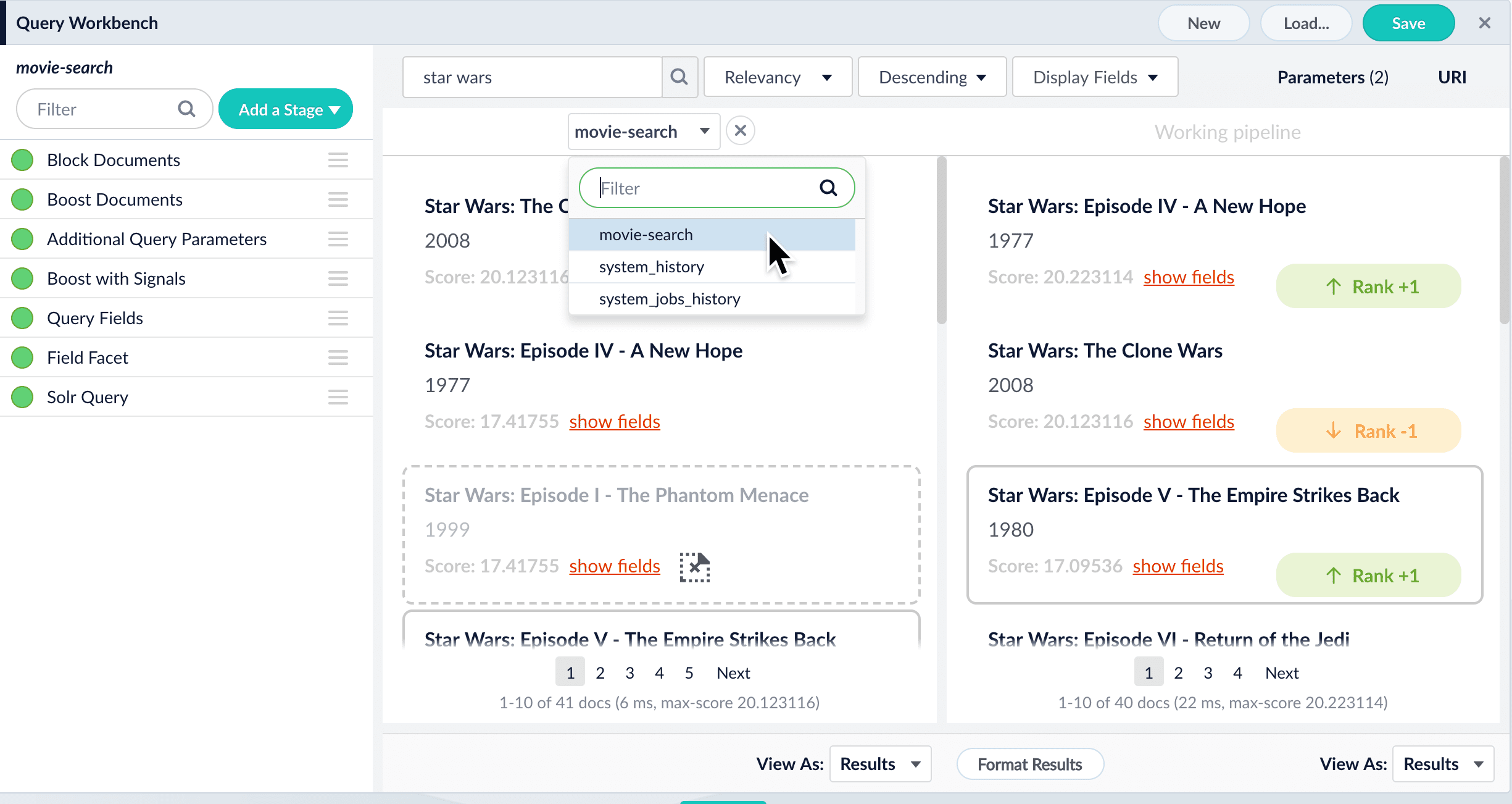
Query pipelines and pipeline stages
Query pipelines work by processing search requests and returning an ordered list of matching documents. Each pipeline consists of a series of query stages that can be added, ordered, and configured using the Query Workbench. Select any stage in the pipeline to open its configuration panel: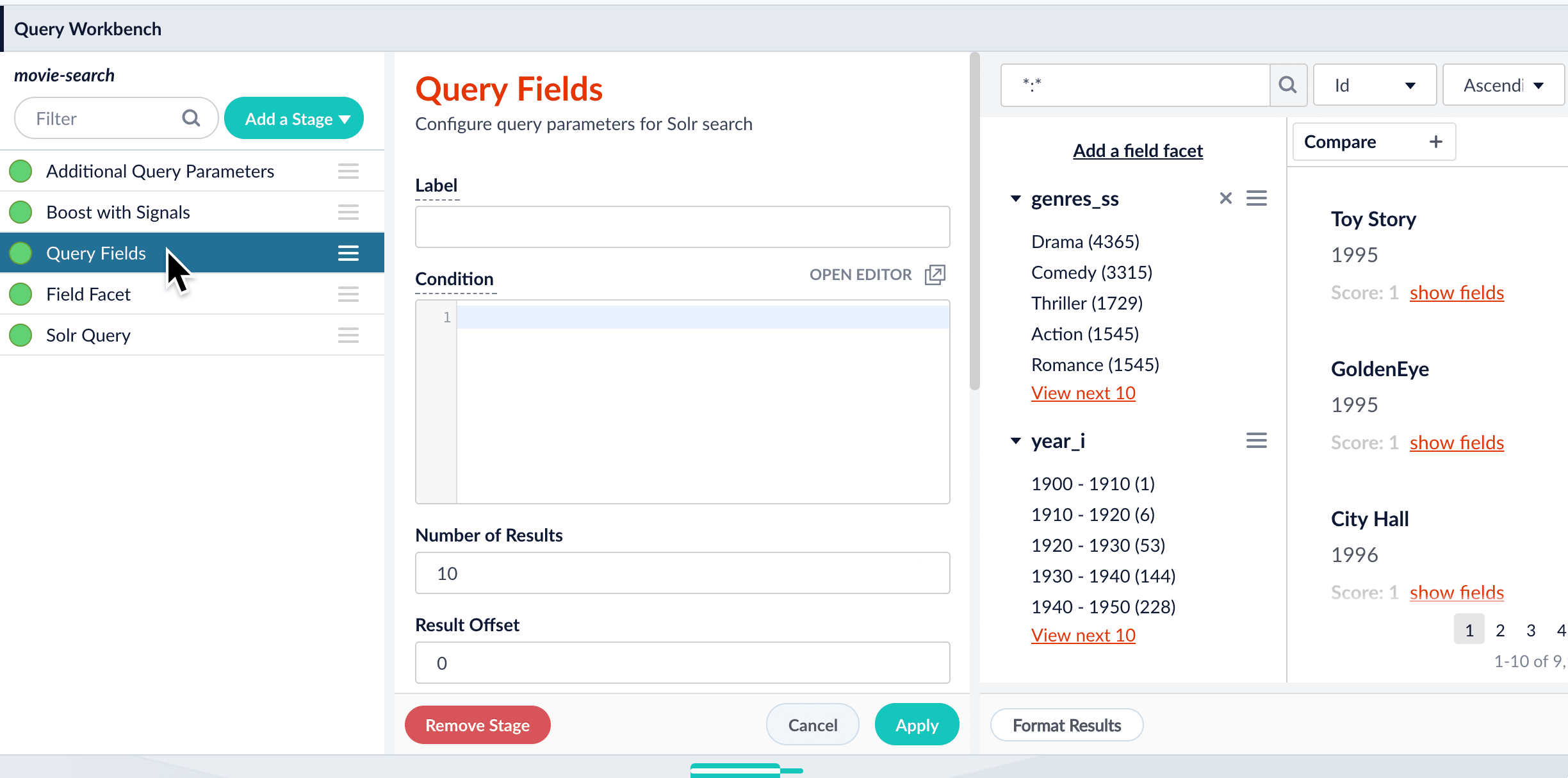
Boosting and blocking
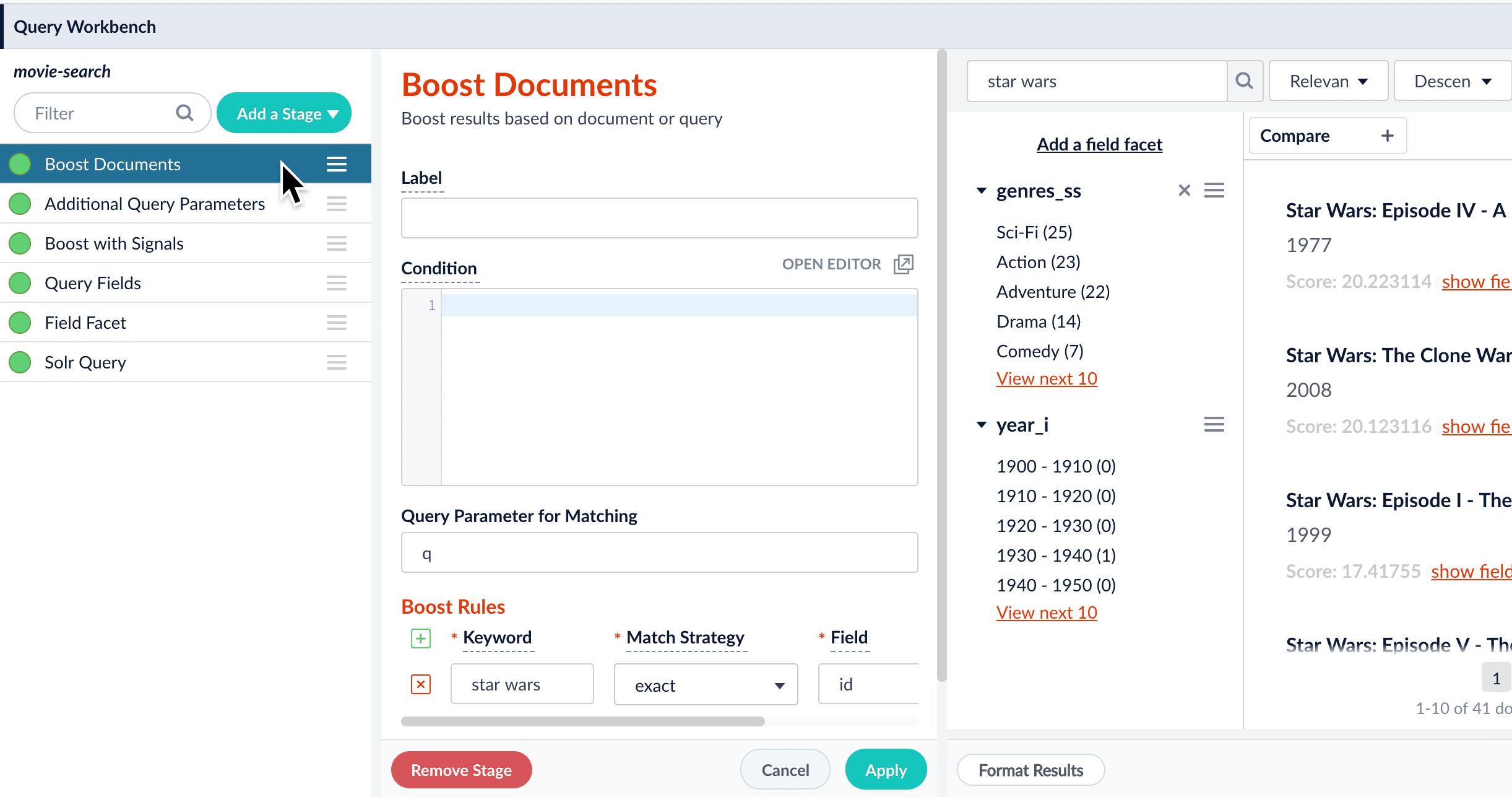
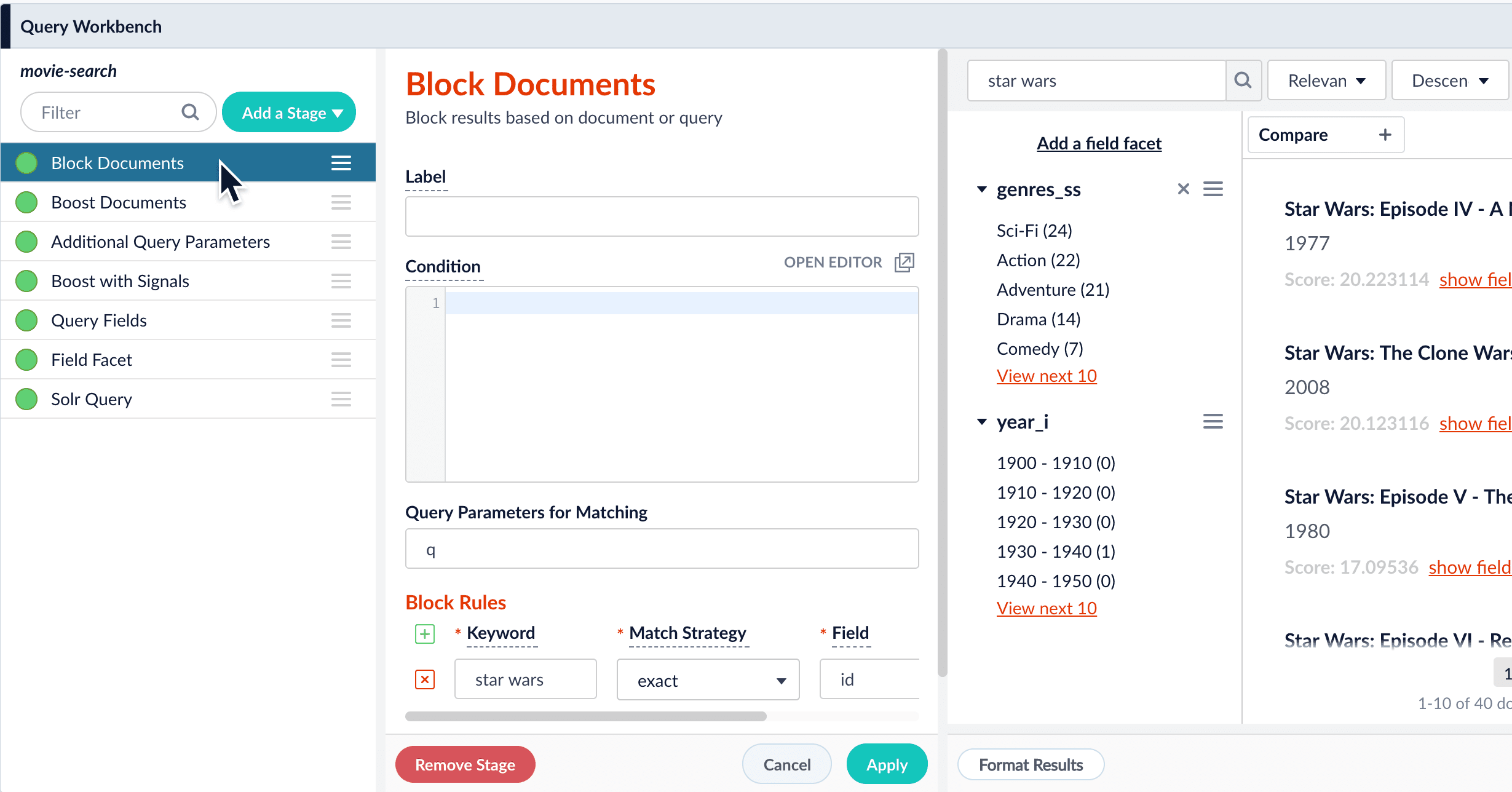
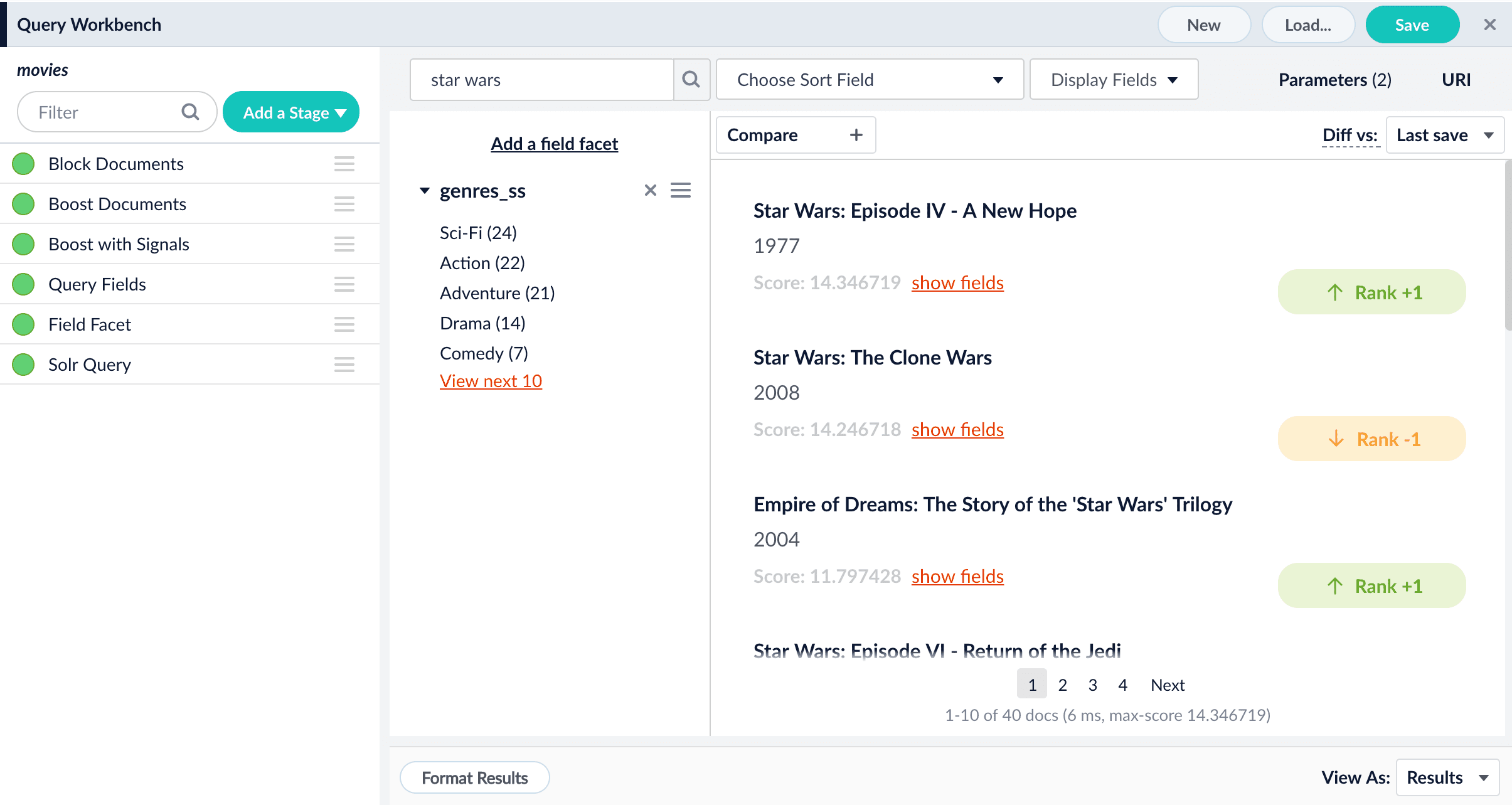
As you search your data and inspect the results, you can manipulate the rankings of individual documents. Boosting a document raises its ranking, while blocking a document removes it from search results. Boosting and blocking affects the results for specific queries. For example, when you search for “citizen” and boost the document for “Citizen Kane”, your end users will see that title boosted to the top when they also search for “citizen”, but not necessarily when they search for “kane”. The Query Workbench provides convenient buttons for instantly blocking or boosting the documents that you see in the preview panel. Clicking Boost automatically adds the Boost Documents stage to your query pipeline, with a boost rule that matches your query and the document you clicked. Likewise, clicking Block adds and configures the Block Documents stage.Compare mode
Compare mode allows you to compare search results using two different query pipelines, or compare search results from the original query pipeline and the copy being modified in the Query Workbench. On the right is the working pipeline, which you can edit. On the left is one of your saved pipelines.Learn more
Boost or Block with the Query Workbench
Boost or Block with the Query Workbench
- How to boost a document in the Query Workbench
- In the preview panel, hover over the document you want to boost.
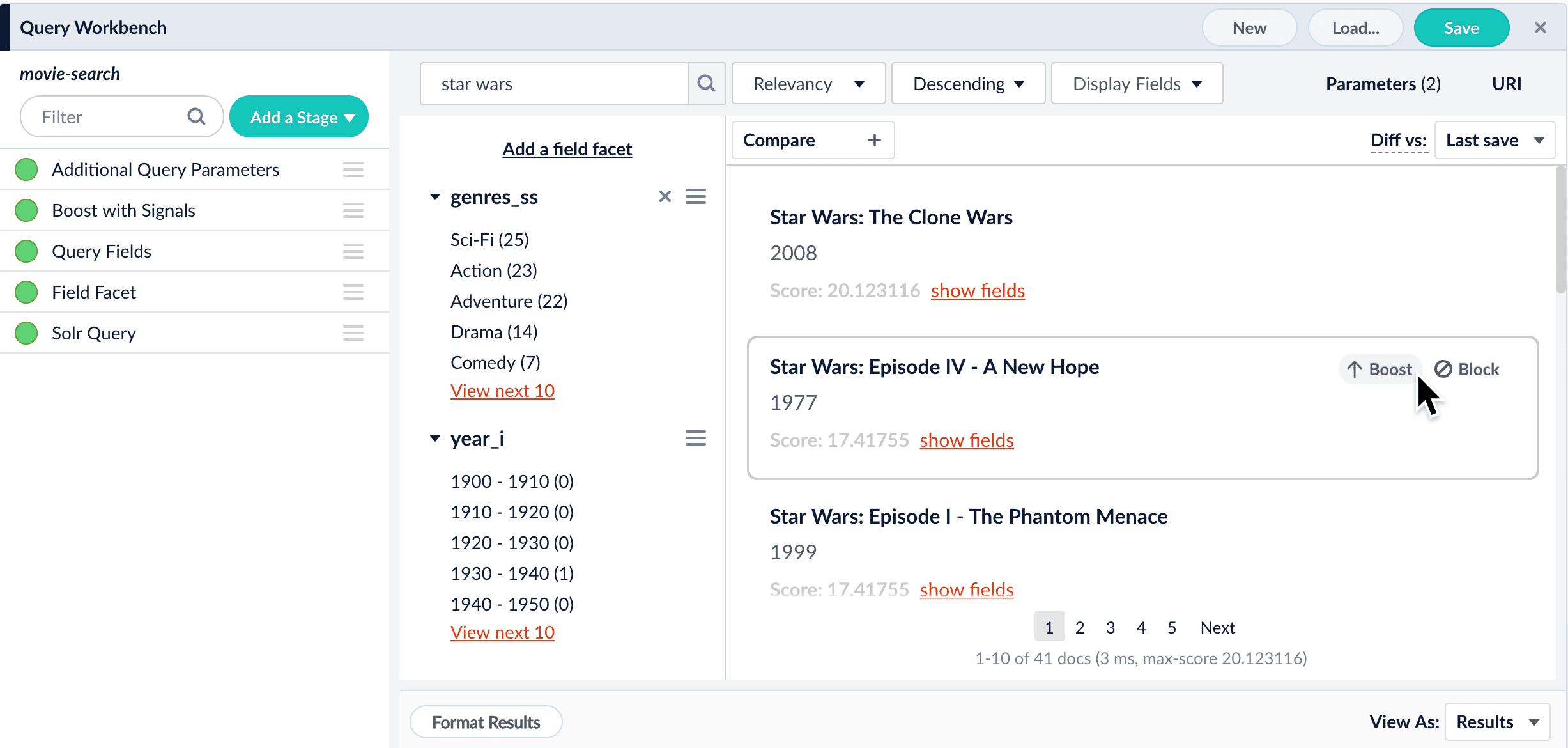
- Click Boost.
The preview panel automatically updates the rankings of the search results, and tags the differences: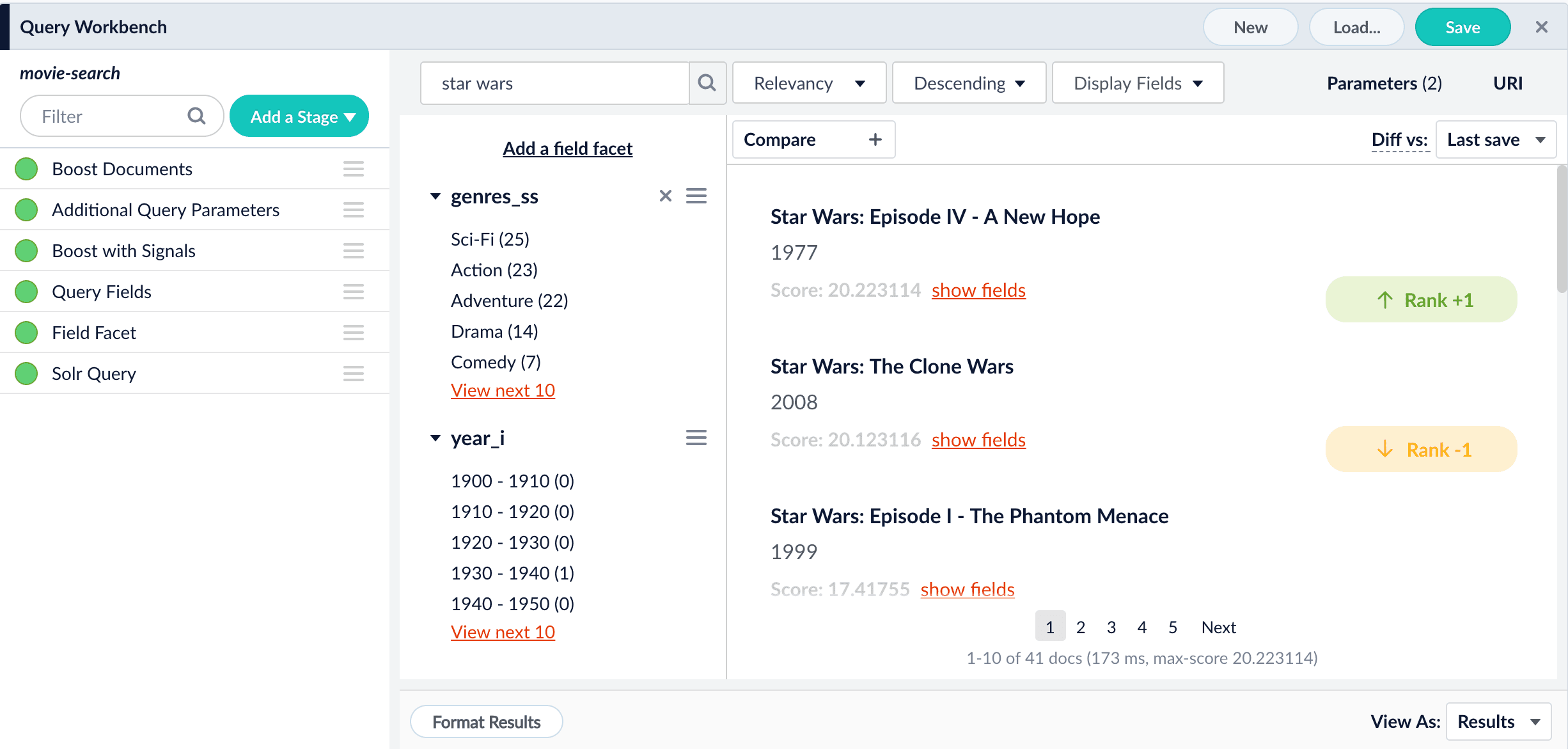
- When you are satisfied with the results, save the query pipeline.
-
In the preview panel, hover over the document you want to block.
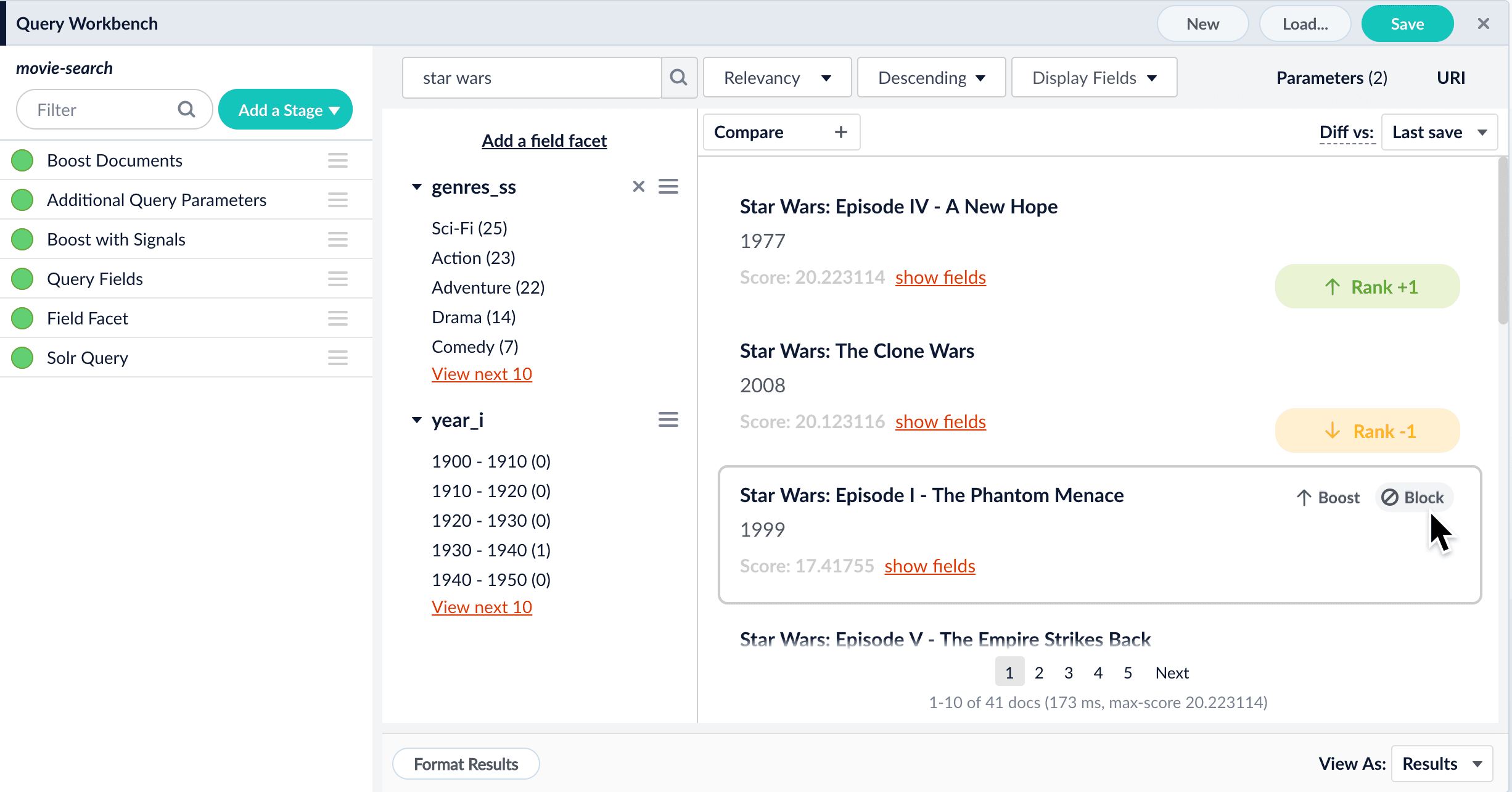
-
Click Block
The preview panel automatically updates the rankings of the search results, and tags the differences.
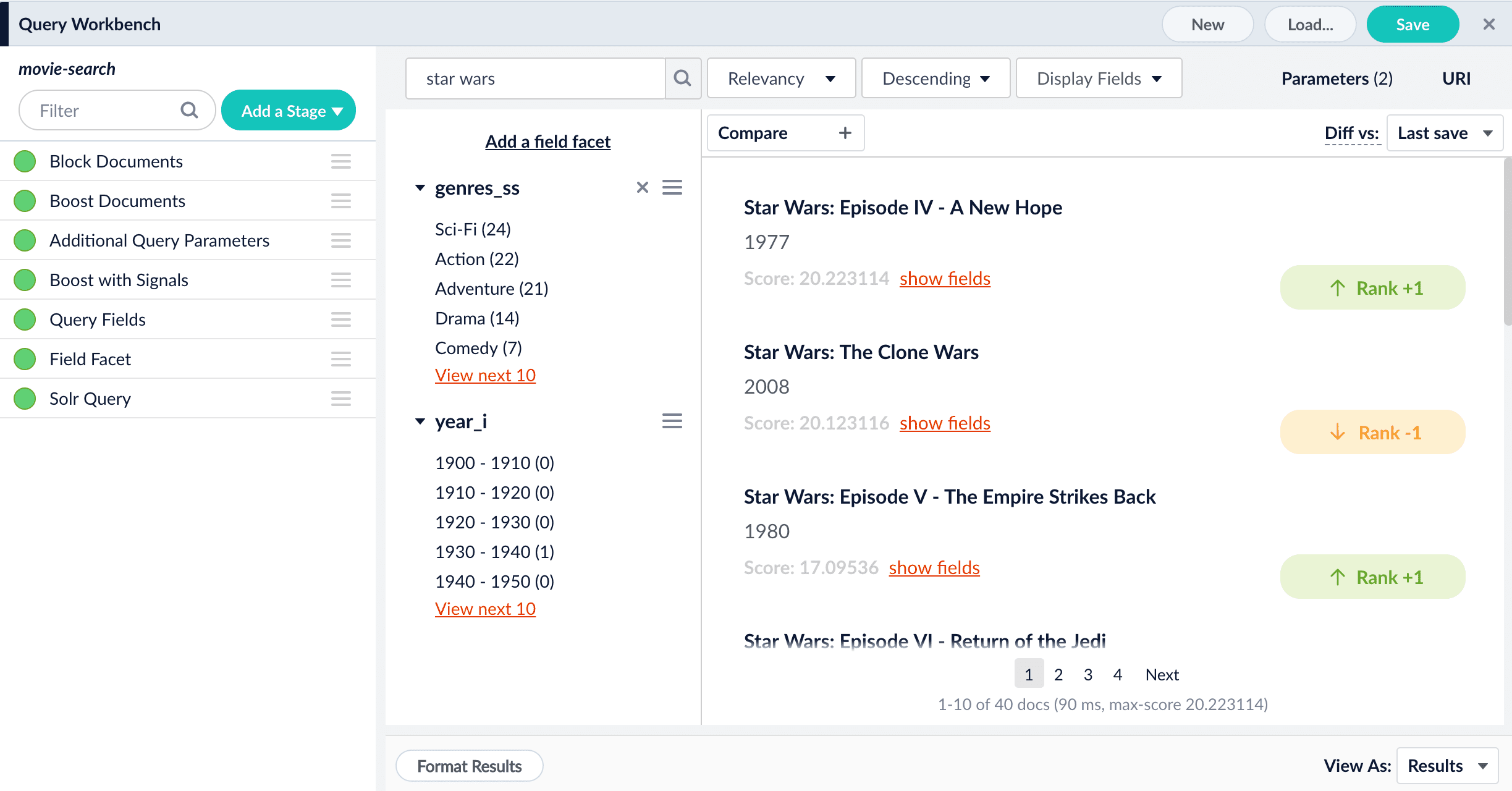
- When you are satisfied with the results, save the query pipeline.
Edit parameters in the Query Workbench
Edit parameters in the Query Workbench
The Query Workbench allows you to edit the search parameters.
- Click Parameters to display the current search parameters.
- Click Edit parameters.
- In the Parameters and Values screen, edit the parameters and click Close.
Enable Asynchronous Query Pipeline Processing
Enable Asynchronous Query Pipeline Processing
- In the Query Workbench, open the query pipeline you want to modify.
- Click Add a Stage and select a stage that supports asynchronous processing, or select the stage in your pipeline if it has already been added. The stages that support asynchronous processing are:
- Active Directory Security Trimming
- Security Trimming
- Boost with Signals
- Apply Rules
- JDBC Lookup
- LWAI Vectorize Query
- Solr Subquery
- LWAI Prediction Query
- In the stage configuration panel, select Asynchronous Execution Config.
- Select Enable Async Execution.\
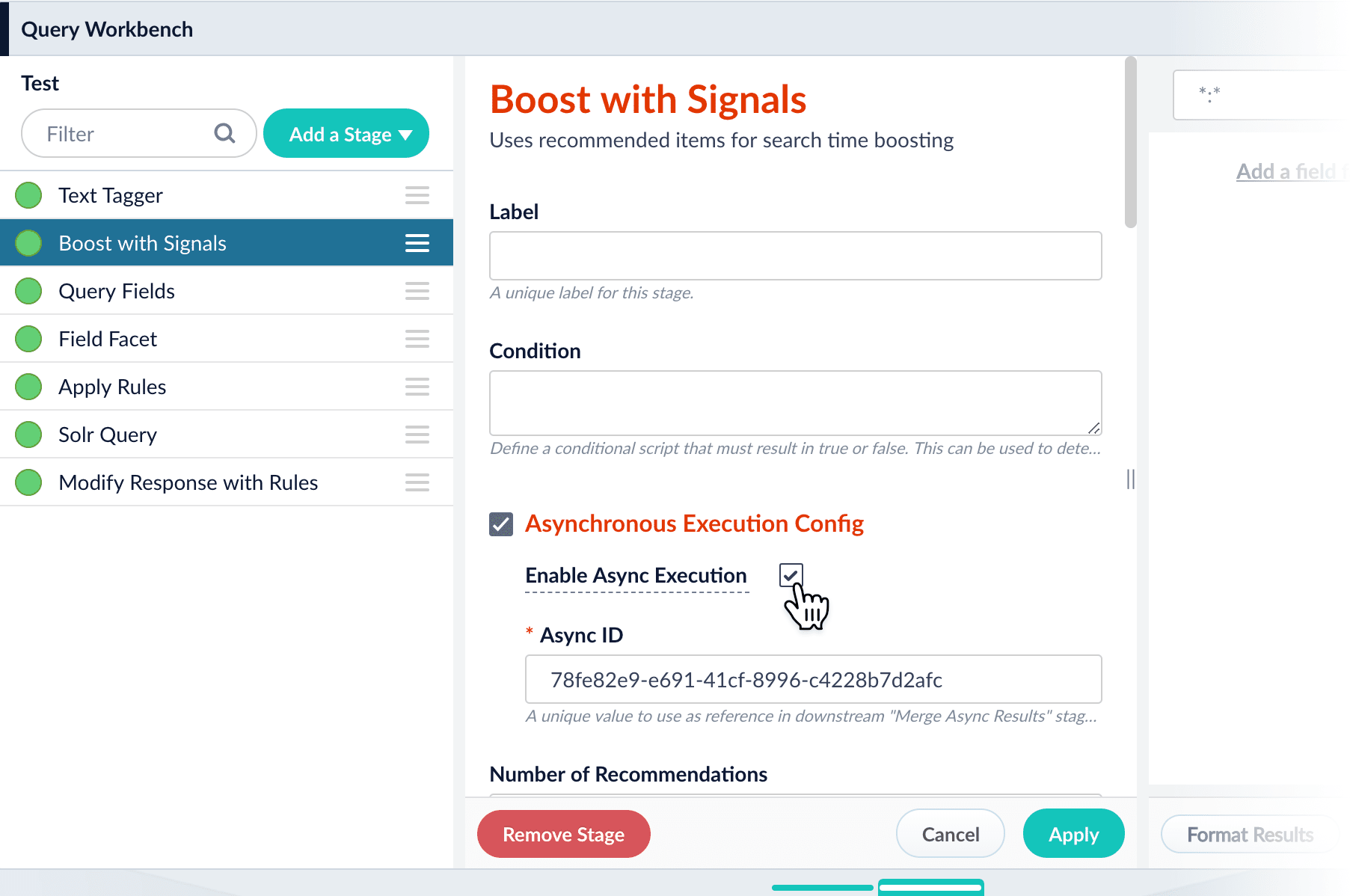
- Copy the Async ID value.
- Click Apply.
Verify that the stage is in the correct position in your pipeline. - Click Add a Stage and select the Merge Async Results stage.\
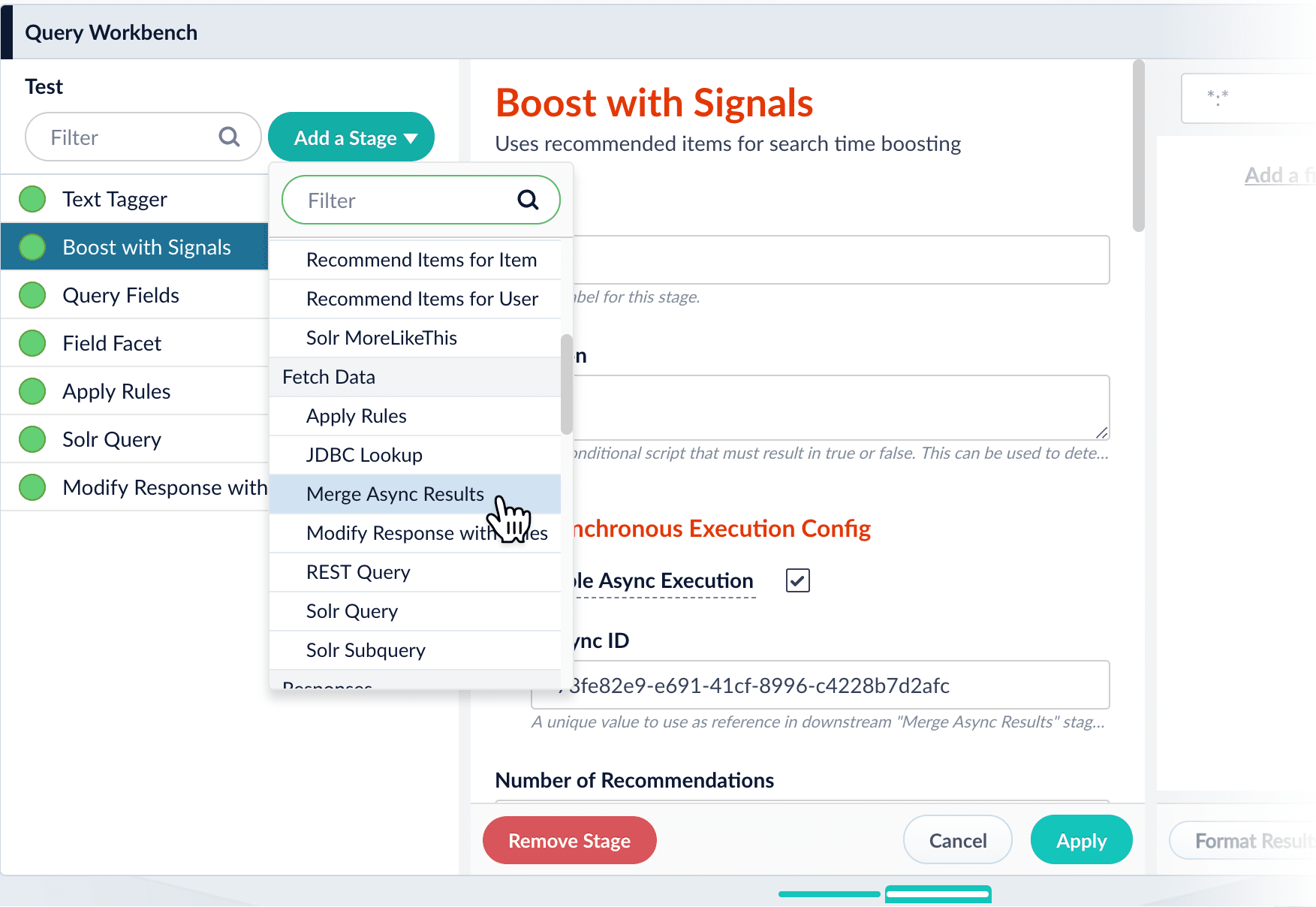
- In the stage configuration panel, click the Add
 button next to Async IDs.
button next to Async IDs. - Paste the ID from the asynchronous query stage into the new ID field.
- Click Apply.
The Merge Async Results stage is now the first stage in the pipeline. - Drag the Merge Async Results stage down so that it appears immediately before the Solr Query stage:
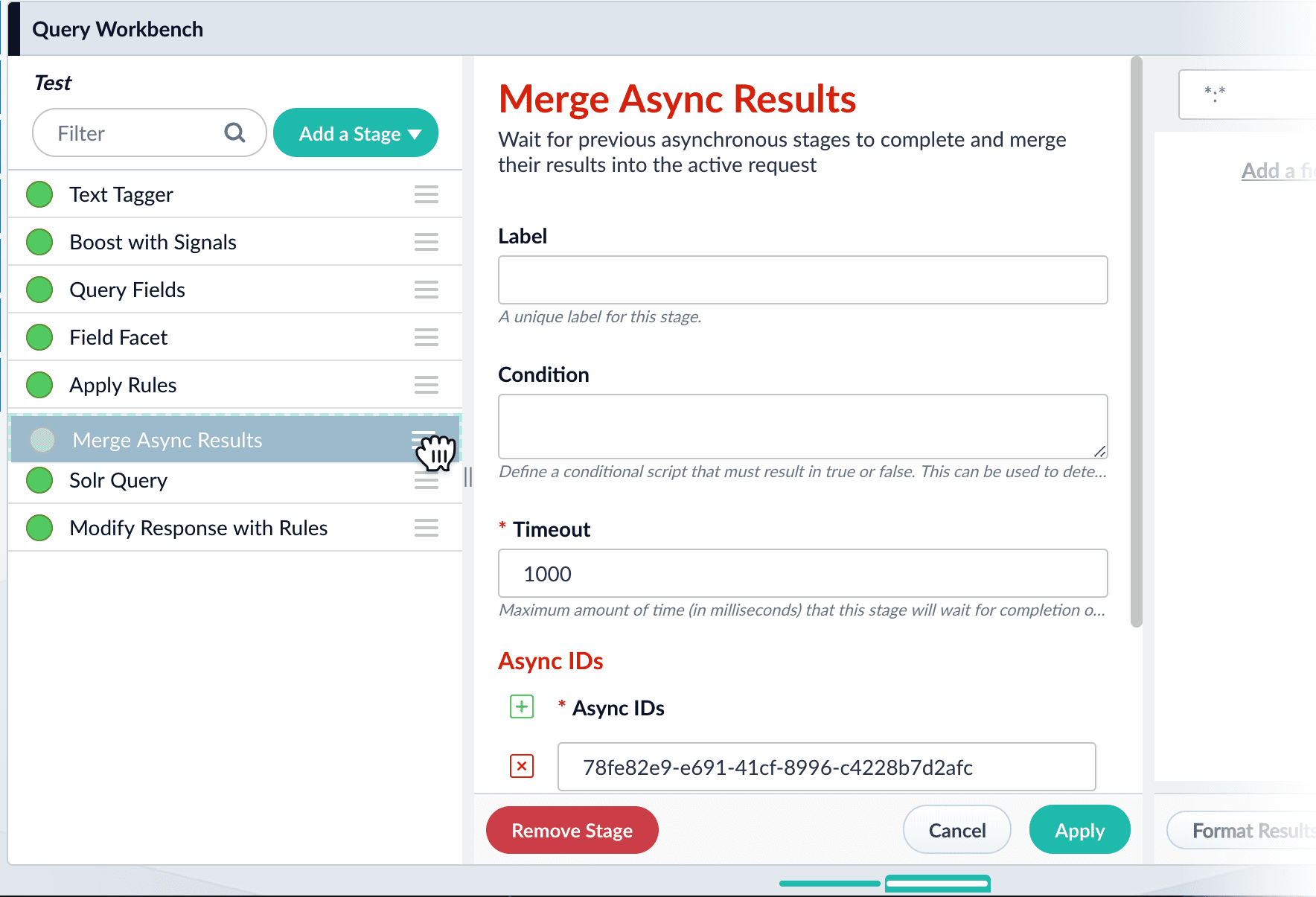
- Click Save.
Enable and disable query pipeline stages
Enable and disable query pipeline stages
By default, every stage in a query pipeline is enabled. While working with a query pipeline, it can be helpful to disable stages without removing them completely. This allows you to preserve a stage’s configuration while observing how the search results change in its absence. You can re-enable the stage at any time. When you save a query pipeline, the enabled/disabled state of each stage is also saved.
Use Federated Search
Use Federated Search
Federated search lets you query across multiple collections in Fusion. This is useful if you keep separate data collections for security or compliance reasons or maintain different collections based on data type.
- In the Fusion workspace, navigate to Querying > Query Workbench.
- Click Solr Query to open the Solr Query panel.
-
Enable Allow Federated Search then click Apply.\
- In the workbench area, click Parameters then click Edit Parameters.
-
Click Add to add a parameter. For the Name, enter
collectionand for the Parameter Value, enter a comma-separated list of collections you want to query. For example,movies-collection,books-collection,music-collection.\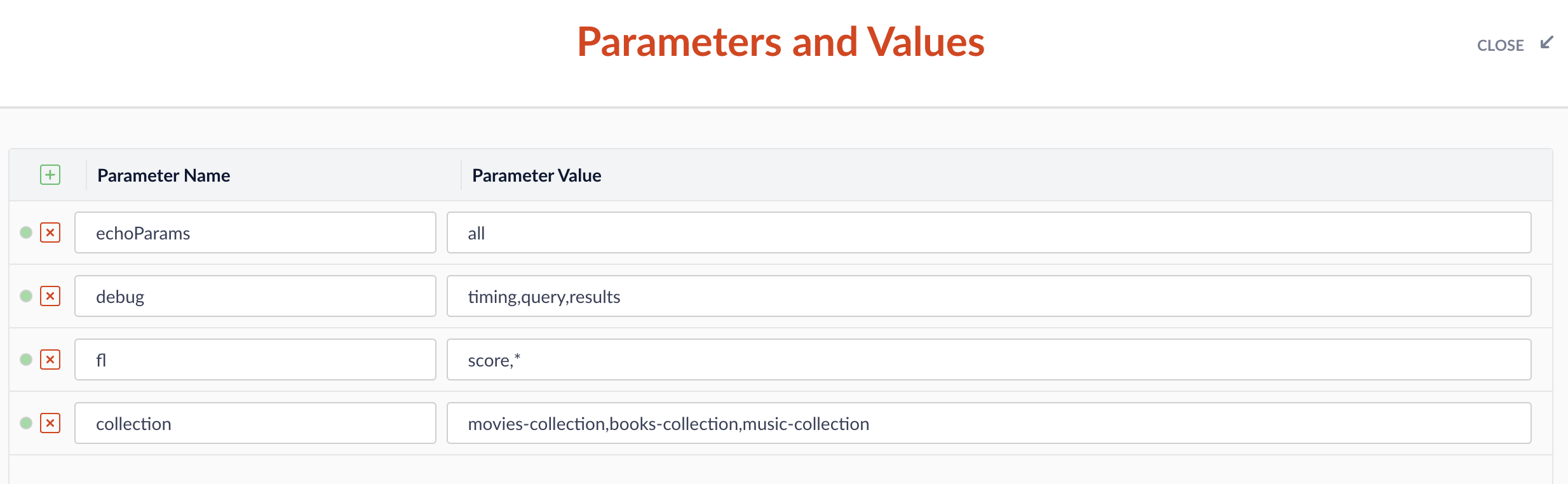
- Click Close.
-
Check that your pipeline is querying documents from all specified collections.\

Format search results in the Query Workbench
Format search results in the Query Workbench
Ultimately, your search application formats the search results that end users see. The Query Workbench provides some formatting options for the preview panel.At the bottom of the screen, click Format Results to configure how results are displayed in the Query Workbench.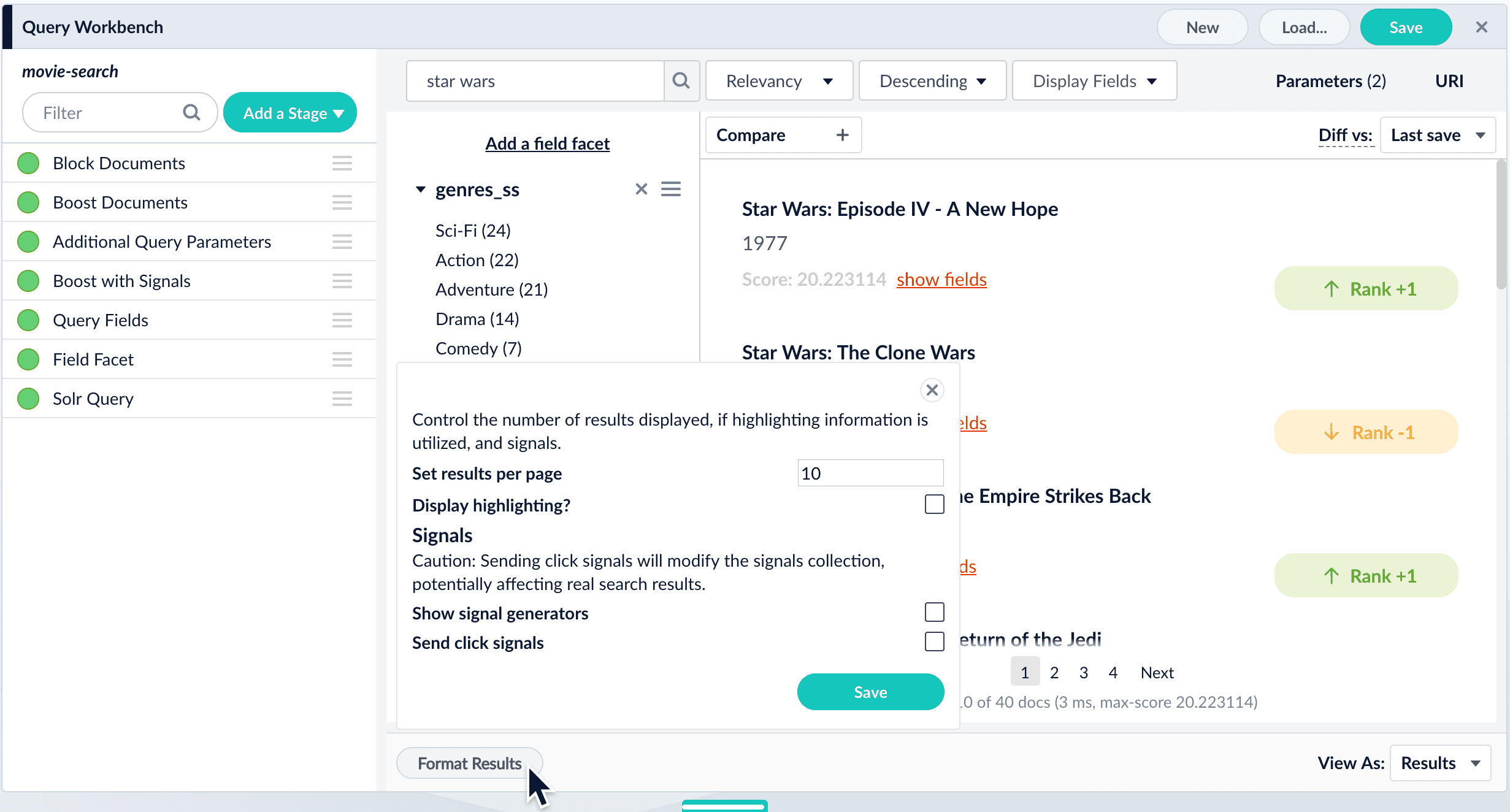
Step-by-step Query Workbench workflow
Step-by-step Query Workbench workflow
- Use the Index Workbench to set up datasource(s).
- Run a crawl on the data.
- Open the Query Workbench.
- Select a query pipeline to use or create a new, blank pipeline.
The Default pipeline is created automatically and can be used as-is or with modification. - Modify the pipeline stages and set the order in which the queries will run.
- Examine the live results in the Search panel.
- Modify any pertinent stage settings to fine tune your results.
- Click Save to commit the new settings to the pipeline
Reorder Query Pipeline Stages
Reorder Query Pipeline Stages
The order of the pipeline stages matters, because the output from one stage becomes the input to the next stage. For example, the Solr Query stage must always come last in the sequence, so that data is indexed only after it has been processed by all other stages. Putting this stage first in the sequence means that subsequent stages have no effect on the indexed data.
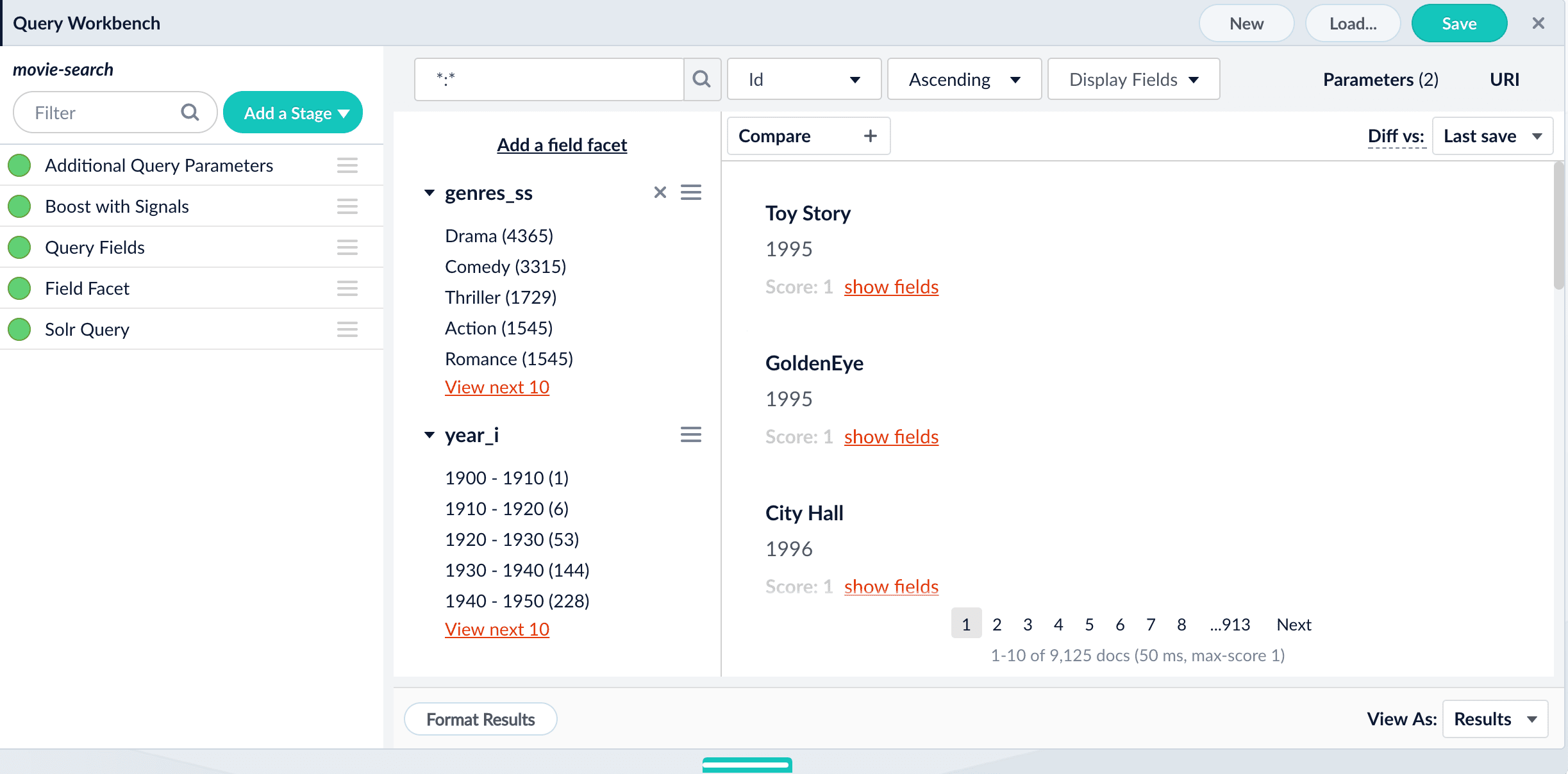
Select Fields to Display in the Query Workbench
Select Fields to Display in the Query Workbench
While the Query Fields stage configures which fields match against incoming queries, the search application itself determines which fields to display in the search results.For example, the search results below use the 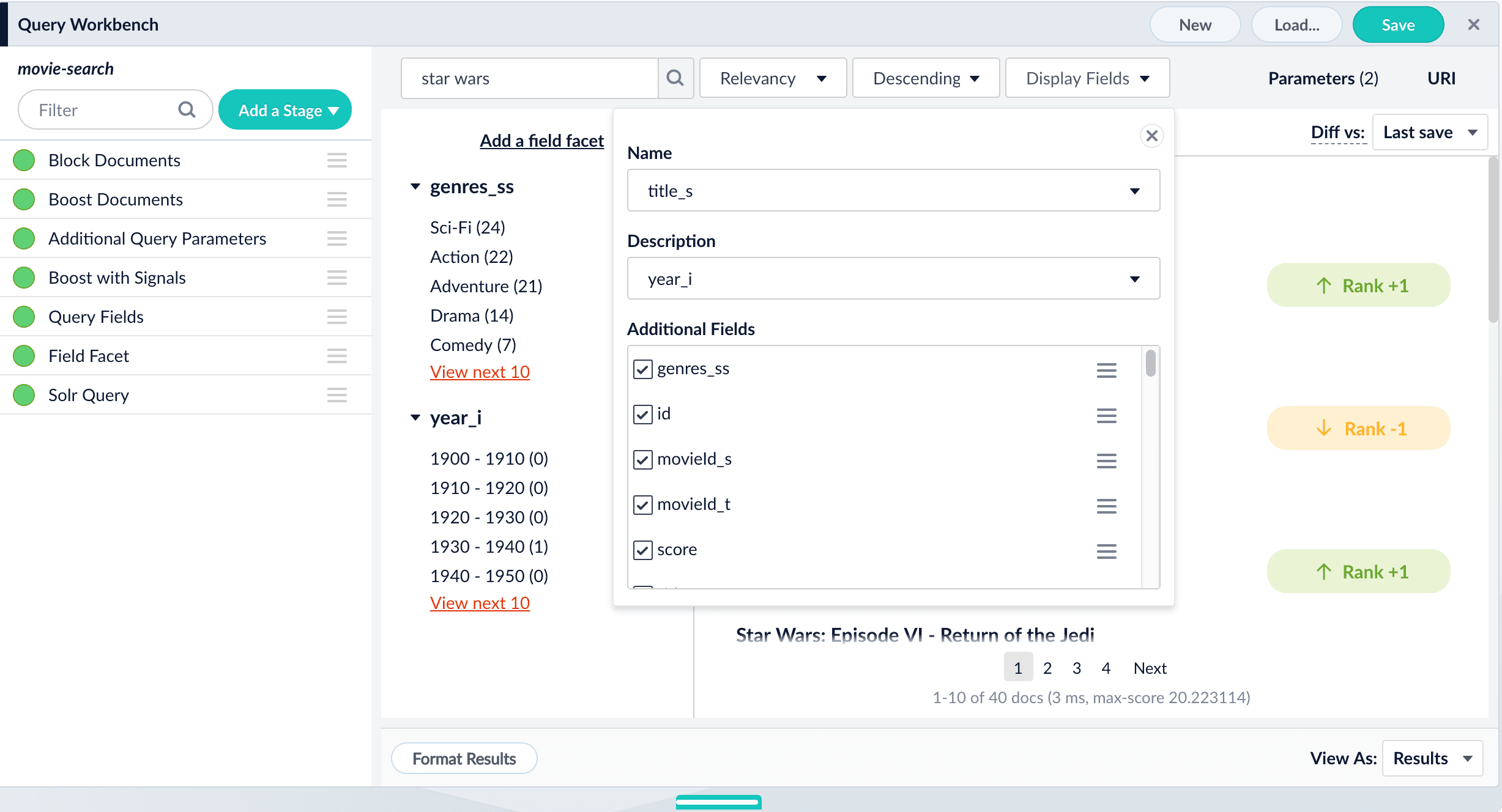
title_s field as the document name and the year_i field as the document description:year_i as the description removed it from the list of field facets and now we see the year of release for each movie title in the search results:Compare Two Query Pipelines
Compare Two Query Pipelines
- In the Query Workbench, click Compare.
Another preview panel opens. In this view, you can compare results from one query pipeline side by side with another query pipeline. - In the left panel, select a pipeline to compare to your working pipeline.
Now you can see how the search results differ between the two pipelines: