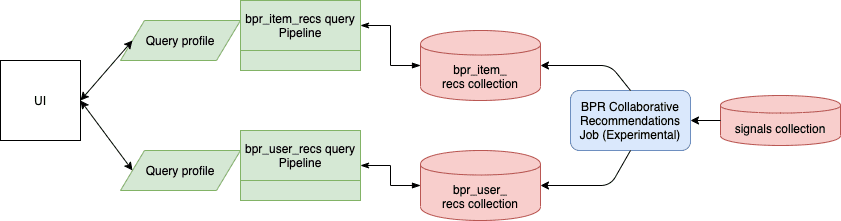
| Default job name | COLLECTION_NAME_bpr_item_recs |
| Input | Aggregated signals (the COLLECTION_NAME_recs_aggr collection by default) |
| Output | Items-for-item recommendations (the COLLECTION_NAME_bpr_item_recs collection by default) and Items-for-user recommendations (the COLLECTION_NAME_bpr_user_recs collection by default). |
- User. Use Training Collection User Id Field to specify the name of the user ID field, usually
user_id_s. - Item. Use Training Collection Item Id Field to specify the name of the item ID field, usually
item_id_s. - Interaction-value. Use Training Collection Counts/Weights Field to specify the name of the interaction value field, usually
aggr_count_i.
You can also configure this job to read from or write to cloud storage. See Configure An Argo-Based Job to Access GCS and Configure An Argo-Based Job to Access S3.
Configure An Argo-Based Job to Access GCS
Configure An Argo-Based Job to Access GCS
Some jobs can be configured to read from or write to Google Cloud Storage (GCS).You can configure a combination of Solr and cloud-based input or output, that is, you can read from GCS and then write to Solr or vice versa.
However, you cannot configure multiple storage sources for input or multiple storage targets for output; only one can be configured for each.See also Configure An Argo-Based Job to Access S3.
Supported jobs
This procedure applies to these Argo jobs:- Content based Recommender
- BPR Recommender
- Classification
- Evaluate QnA Pipeline
- QnA Coldstart Training
- QnA Supervised Training
How to configure a job to access GCS
- Gather the access key for your GCS account.
See the GCS documentation. - Create a Kubernetes secret:
- In the job’s Cloud storage secret name field, enter the name of the secret for the GCS target as mounted in the Kubernetes namespace.
This is the name you specified in the previous step. In the example above, the secret name ismy-gcs-serviceaccount-key. - In the job’s Additional Parameters, add this parameter:
- Parameter name:
google.cloud.auth.service.account.json.keyfile - Parameter value:
<name of the keyfile that is available when the GCS secret is mounted to the pod>The file name may be different than the secret name. You can check usingkubectl get secret -n <fusion-namespace> <secretname> -o yaml.
- Parameter name:
Configure An Argo-Based Job to Access S3
Configure An Argo-Based Job to Access S3
Some jobs can be configured to read from or write to Amazon S3 (S3).You can configure a combination of Solr and cloud-based input or output, that is, you can read from S3 and then write to Solr or vice versa.
However, you cannot configure multiple storage sources for input or multiple storage targets for output; only one can be configured for each.See also Configure An Argo-Based Job to Access GCS.
Supported jobs
This procedure applies to these Argo jobs:- Content based Recommender
- BPR Recommender
- Classification
- Evaluate QnA Pipeline
- QnA Coldstart Training
- QnA Supervised Training
How to configure a job to access S3
- Gather the access key and secret key for your S3 account.
See the AWS documentation. - Create a Kubernetes secret:
- In the job’s Cloud storage secret name field, enter the name of the secret for the S3 target as mounted in the Kubernetes namespace.
This is the name you specified in the previous step. In the example above, the secret name isaws-secret. - In the job’s Additional Parameters, add these two parameters:
- Param name:
fs.s3a.access.keyPath
Param value:<name of the file containing the access key that is available when the S3 secret is mounted to the pod> - Param name:
fs.s3a.secret.keyPath
Param value:<name of the file containing the access secret that is available when the S3 secret is mounted to the pod>The file name may be different than the secret name. You can check usingkubectl get secret -n <fusion-namespace> <secretname> -o yaml.
- Param name:
If using Solr as the training data source, ensure that the source collection contains the
random_* dynamic field defined in its managed-schema.xml. This field is required for sampling the data. If it is not present, add the following entry to the managed-schema.xml alongside other dynamic fields <dynamicField name="random_*" type="random"/> and <fieldType class=“solr.RandomSortField” indexed=“true” name=“random”/> alongside other field types.Tuning tips
The BPR Recommender job has a few unique tuning parameters compared to the ALS Recommender job:- Training Data Filtered By Popular Items. By setting the minimum number of user interactions required for items to be included in training and recommendations, you can suppress items that do not yet have enough signals data for meaningful recommendations.
- Filter already clicked items. This feature produces only “fresh” recommendations, by omitting items the user has already clicked. (It also increases the job’s running time.)
- Perform approximate nearest neighbor search. This option reduces the job’s running time significantly, with a small decrease in accuracy. If your training dataset is very small, then you can disable this option.
- Evaluate on test data. This feature samples the original dataset to evaluate how well the trained model predicts unseen user interactions. The clicks that are sampled for testing are not used for training. For example, with the default configuration, users who have at least three total clicks are selected for testing. For each of those users, one click is used for testing and the rest are used for training. The trained model is applied to the test data, and the evaluation results are written to the log.
- Metadata fields for item-item evaluation. These fields are used during evaluation to determine whether pairs belong to the same category.
Query pipeline setup
- For items-for-item recommendations, Download the APPName_item_item_rec_pipelines_bpr.json file and Migrate Lucidworks Search Objects to create the query pipeline that consumes this job’s output. See Fetch Items-for-Item Recommendations (Collaborative/BPR Method) for details.
- For items-for-user recommendations, Download the APPName_item_user_rec_pipelines_bpr.json file and Migrate Lucidworks Search Objects to create the query pipeline that consumes this job’s output. See Fetch Items-for-User Recommendations (Collaborative/BPR Method) for details.
Migrate Lucidworks Search Objects
Migrate Lucidworks Search Objects
You can use the Fusion UI and the Objects API to migrate collections and related objects, including your searchable data, configuration data, pipelines, aggregations, and other objects on which your collections depend. You can also migrate entire apps.You might need to migrate objects in the following circumstances:
For more information about using the Objects API to export and import objects, see Objects API.The remainder of this topic describes approaches in the Fusion UI.Use the parts of the Fusion UI indicated in the table to export and import apps and specific objects. Exporting creates a zip file. To import, you select a data file and possibly a variable file.The approach with Object Explorer differs. With Object Explorer, you can add objects from other apps (or that are not linked to any apps) to the currently open app.
To upgrade from one Fusion version to a 5.x version, see Fusion 5 Upgrades to migrate objects.
- When migrating data from development environments into testing and production environments
- To back up data, so you can restore it after an incident of data loss
- When the migrator script was not able to migrate an object automatically
Migration approaches
Several approaches are available for migrating Fusion objects. This table summarizes the approaches.| Export an app | Import an app | Export an object | Import an object | Add an object to an app | |
|---|---|---|---|---|---|
| Fusion UI | App configuration | Launcher (entire app) App configuration (combine apps) | - | - | Object Explorer |
| Objects API (endpoints) | GET from export endpoint | POST to import endpoint | GET from export endpoint | POST to import endpoint | - |
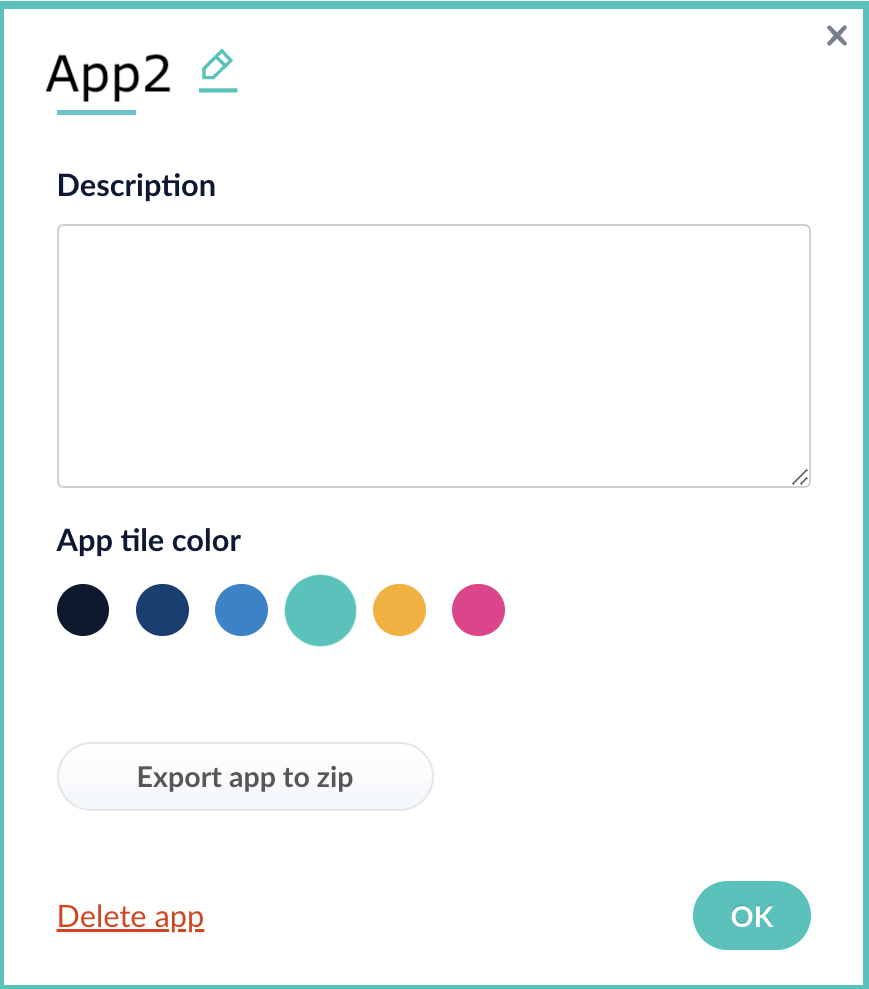
Export an app with the Fusion UI
How to export an app with the Fusion UI- Navigate to the launcher.
-
Hover over the app you want to export and click the Configure icon:

-
In the app config window, click Export app to zip:
Import an app with the Fusion UI
How to import an app with the Fusion UI- Navigate to the launcher.
-
Click Import app.
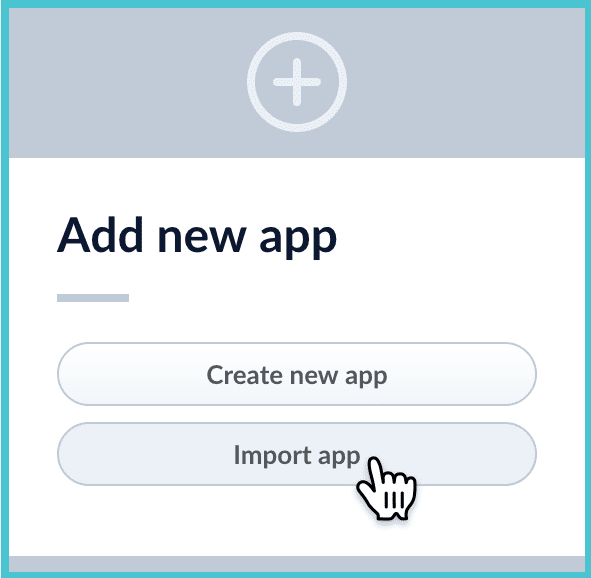
- Under Data File, click Choose File and select the zip file containing the app you want to import.
-
If your app has usernames and passwords in a separate file, select it under Variables File.
If the Variables File is needed, it must be a separate file that is not in a .zip file. It is a .json map of variables to values. The following is an example:
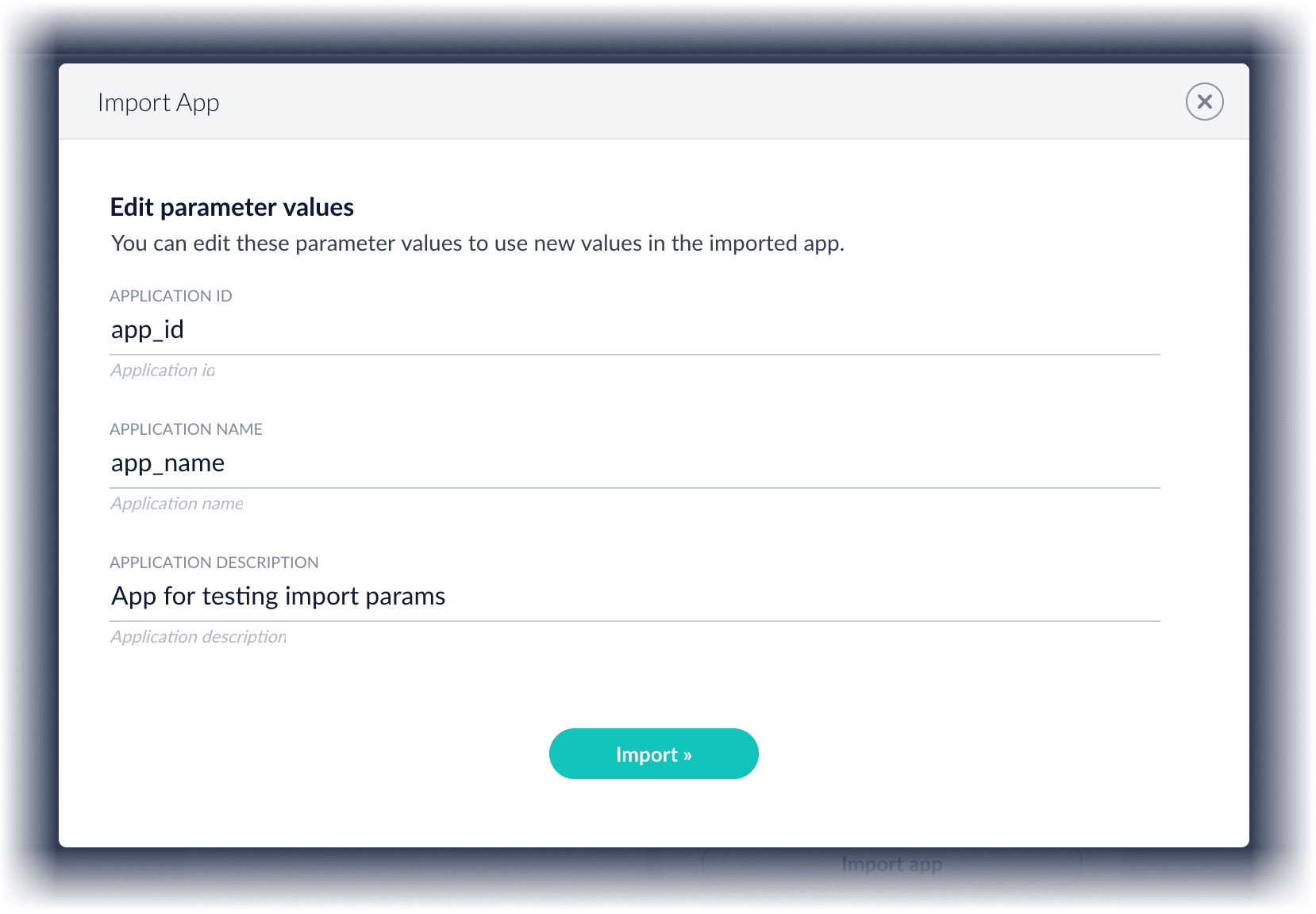
-
You can sometimes edit parameter values to use the new values in the imported app. If this is the case, Fusion displays a dialog box that lets you edit the parameter values.
Copy an app
To copy an app from one deployment to a different one, export the app on the source deployment, and then import the app on the target deployment.Import objects into an app
You can import objects into the currently open app.How to import objects into an open app- In the Fusion launcher, click the app into which you want to import objects. The Fusion workspace appears.
- Click System > Import Fusion Objects.
The Import Fusion Objects window opens.
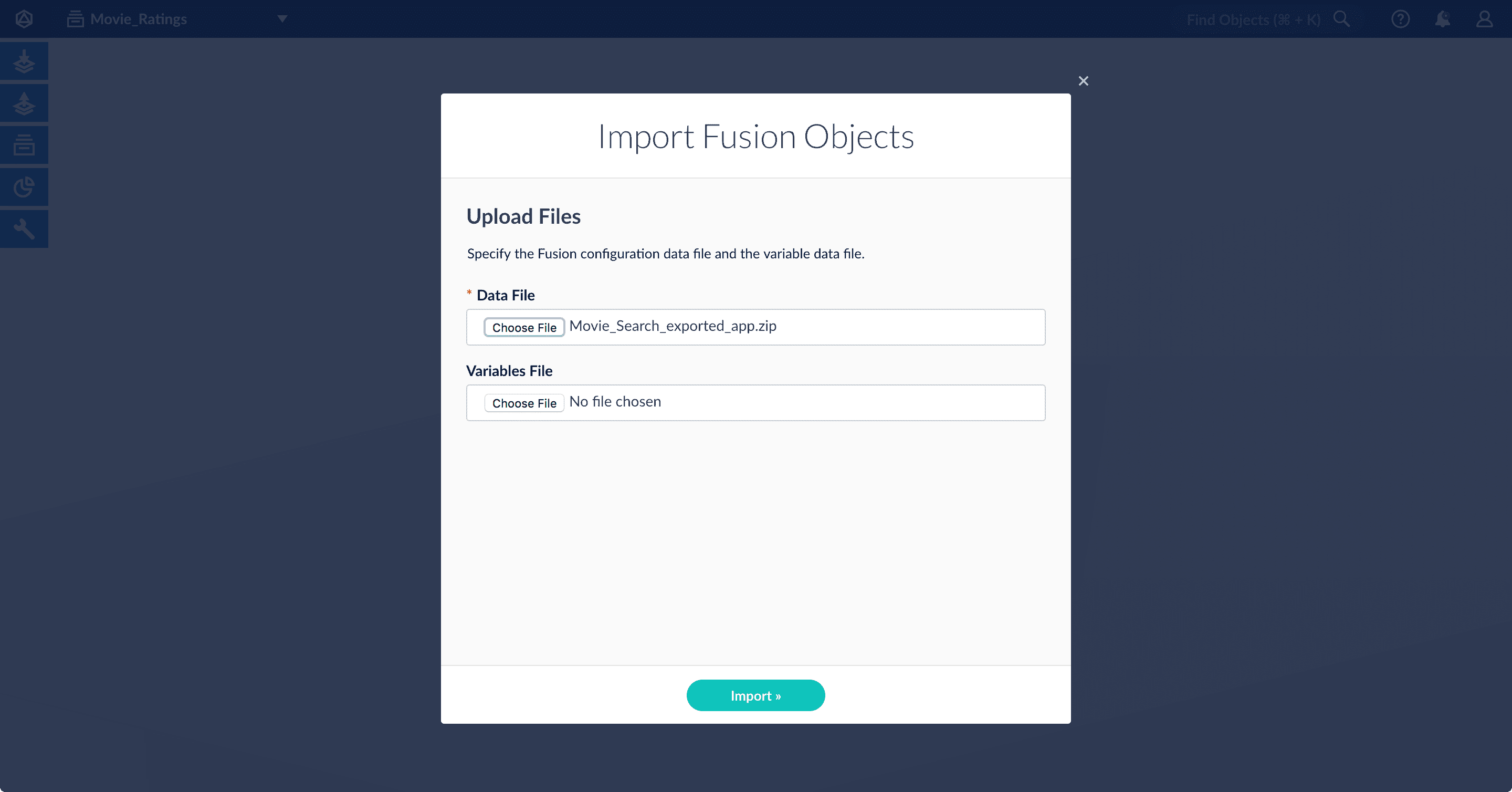
- Select the data file from your local filesystem. If you are importing usernames and passwords in a separate file, select it under Variables File.
- Click Import.
If there are conflicts, Fusion prompts you to specify an import policy:
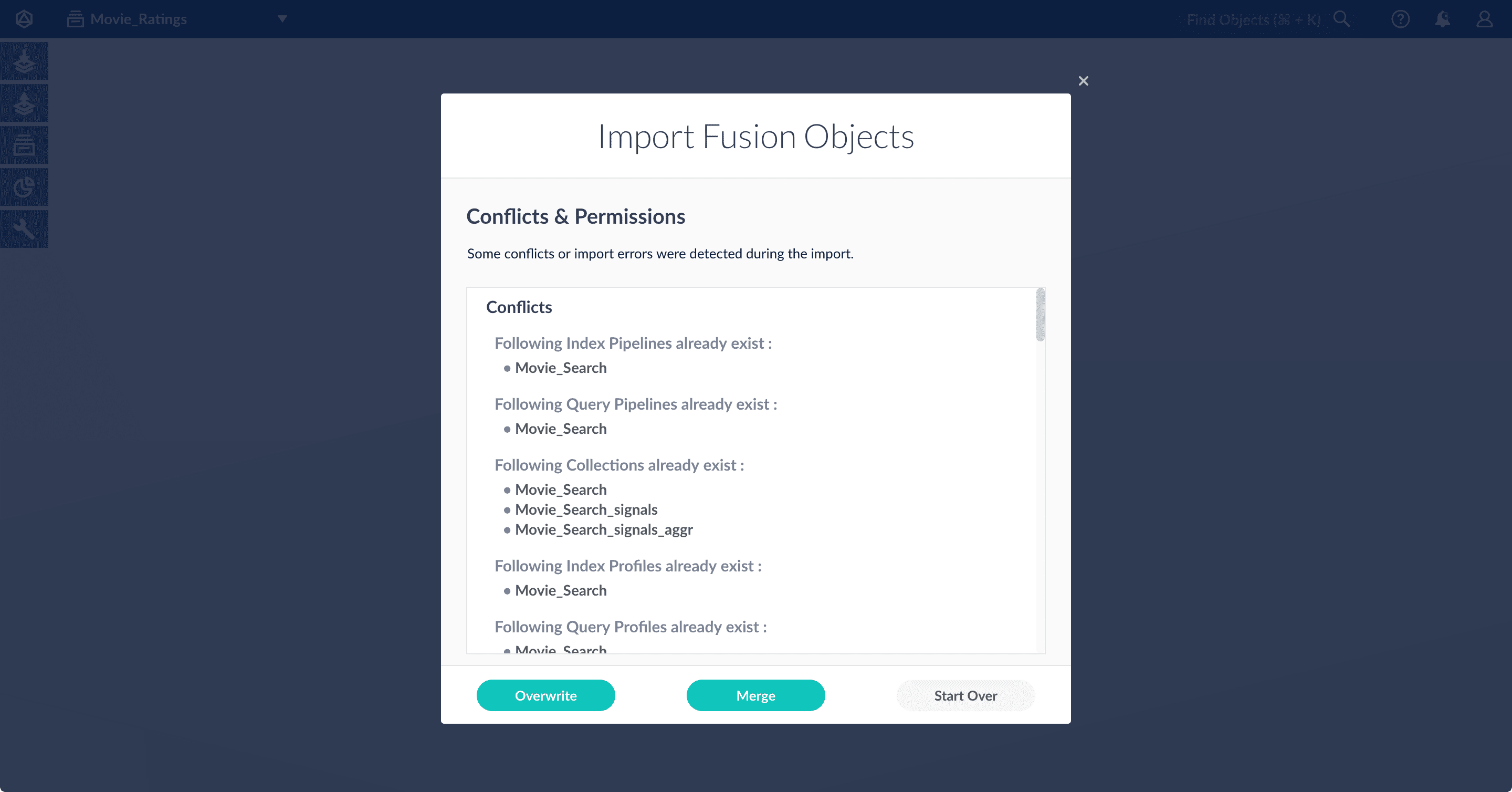
- Click Overwrite to overwrite the objects on the target system with the ones in the import file.
- Click Merge to skip all conflicting objects and import only the non-conflicting objects.
- Click Start Over to abort the import.
Fusion confirms that the import was successful:

- Click Close to close the Import Fusion Objects window.
Add an object to an app
You can add objects present in other apps (or in no apps) to the open app. Some objects are linked to other apps. You can also add those directly to an app.-
Add an object to an app – While in the Fusion workspace for the app to which you want to add an object, open Object Explorer and click In Any App. Search for or browse to the object you want to add. Hover over the object, click the App
 icon, and then click Add to this app.
icon, and then click Add to this app.
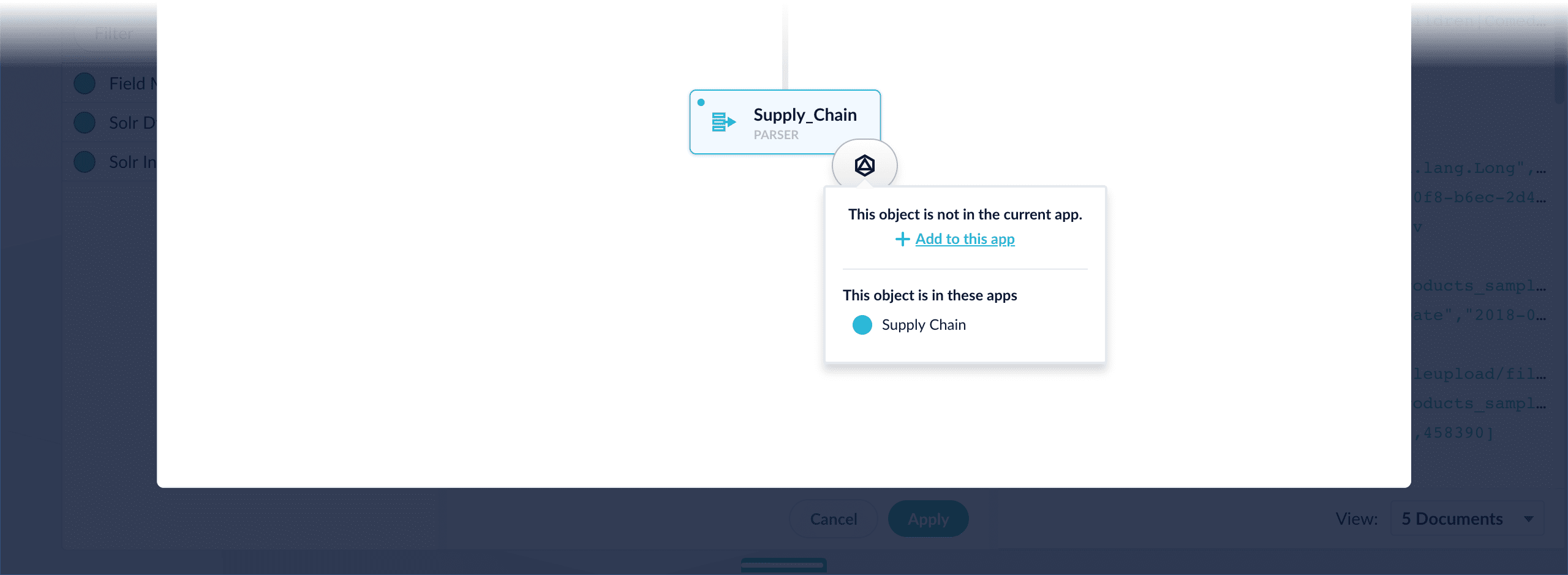
-
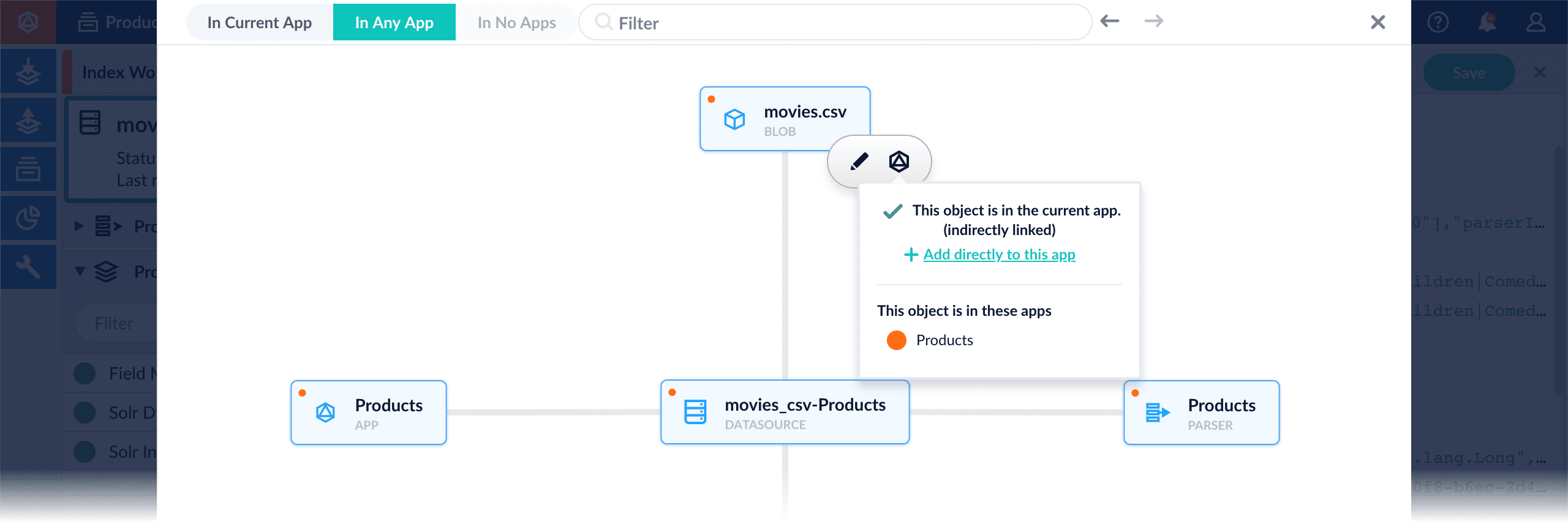
Add an object to an app directly – In cases when an object is linked to an app, but is not linked directly to the app (it is linked via some dependency), you can add the object to an app directly.
While in the Fusion workspace for the app to which you want to add an object directly, open Object Explorer and click In Any App. Search for or browse to the object you want to add. Hover over the object, click the App icon, and then click Add to this app directly.
Fetch Items-for-Item Recommendations (Collaborative/BPR Method)
Fetch Items-for-Item Recommendations (Collaborative/BPR Method)
In Lucidworks Search, you can download and import a query pipeline that works out of the box with the default BPR Recommender job.There are two separate pipelines attached below which work in different ways to query and return recommendations.Query for recommendations onlyNo additional configuration is needed to use this pipeline with the default BPR job configuration.See also
-
Download the
APPName_item_item_rec_pipelines_bpr.jsonfile. -
Rename the file to replace
APPNamewith the name of your Lucidworks Search app, such asProductCatalog_item_item_rec_pipelines_bpr.json. -
Open the JSON file, replace all instances of
APPNamewith the name of your Lucidworks Search app, such asProductCatalog, and save it. -
Import the JSON file into your Lucidworks Search instance using the Query Pipelines REST API:
-
In the Lucidworks Search UI, navigate to Query > Query Pipelines to verify that the new pipeline is available.
This pipeline should be used to query the collection where the recommendations are stored. It makes a query against the
itemIdfield and only returns the recommendeditemIdvalues. To get the actual items, you need to make a second query to the respective catalog collection with the returneditemIdvalues.
-
Download the
APPName_items_for_item_bpr_boost.jsonfile - Rename the file to replace
APPNamewith the name of your Lucidworks Search app, such asProductCatalog_item_item_rec_pipelines_bpr.json. - Open the JSON file, replace all instances of
APPNamewith the name of your Lucidworks Search app, such asProductCatalog. - Fill in the
collectionname field in the firstRecommend Items for Itemstage and save the file. - Import the JSON file into your Lucidworks Search instance using the Query Pipelines REST API:
- In the Lucidworks Search UI, navigate to Query > Query Pipelines to verify that the new pipeline is available.
This pipeline queries the recommendations collection and then makes a subsequent query to the actual catalog collection boosting the recommended items and returning the actual items from the catalog. This pipeline will therefore also return recommendations even if none were generated/available.
This pipeline expects a request parameter called
id=<itemId> to be appended to the request in order to work. An example query URL to this pipeline would look like https://EXAMPLE_COMPANY.b.lucidworks.cloud/api/query-pipelines/APPName_items_for_item_bpr_boost/collections/catalog/select?q=**:**&id=SomeItemIdIf the pipeline does not appear in the Query Pipelines panel, you may need to attach it to your app like this: Go to System > Object Explorer, click the In No Apps filter, hover over the pipeline, click the icon, and select Add to this app.
Fetch Items-for-User Recommendations (Collaborative/BPR Method)
Fetch Items-for-User Recommendations (Collaborative/BPR Method)
You can download and import a query pipeline that works out of the box to fetch items-for-user recommendations generated by the default BPR Recommender job.There are two separate pipelines attached below which work in different ways to query and return recommendations.Query for recommendations onlySee also
-
Download the
APPName_item_user_rec_pipelines_bpr.jsonfile. -
Rename the file to replace
APPNamewith the name of your Fusion app, such asProductCatalog_item_item_rec_pipelines_bpr.json. -
Open the JSON file, replace all instances of
APPNamewith the name of your Fusion app, such asProductCatalog, and save it. -
Import the JSON file into your Fusion instance using the Query Pipelines REST API:
-
In the Fusion UI, navigate to Query > Query Pipelines to verify that the new pipeline is available.
This pipeline should be used to query the collection where the recommendations are stored. It makes a query against the
userIdfield and only returns the recommendeditemIdvalues. To get the actual items, you need to make a second query to the respective catalog collection with the returneditemIdvalues.
-
Download the
APPName_items_for_user_bpr_boost.jsonfile - Rename the file to replace
APPNamewith the name of your Fusion app, such asProductCatalog_items_for_user_bpr_boost.json. - Open the JSON file, replace all instances of
APPNamewith the name of your Fusion app, such asProductCatalog. - Fill in the
collectionname field in the firstRecommend Items for Userstage and save the file. - Import the JSON file into your Fusion instance using the Query Pipelines REST API:
- In the Fusion UI, navigate to Query > Query Pipelines to verify that the new pipeline is available.
This pipeline queries the recommendations collection and then makes a subsequent query to the actual catalog collection boosting the recommended items and returning the actual items from the catalog. This pipeline will therefore also return recommendations even if none were generated/available.
This pipeline expects a request parameter called
id=<userId> to be appended to the request in order to work. An example query URL to this pipeline would look like https://example-recs-fusion.com/api/query-pipelines/APPName_items_for_user_bpr_boost/collections/catalog/select?q=**:**&id=SomeUserIdIf the pipeline does not appear in the Query Pipelines panel, you may need to attach it to your app like this: Go to System > Object Explorer, click the In No Apps filter, hover over the pipeline, click the icon, and select Add to this app.