Examples
Get the list of deployed models500 server error indicates that either the model is not properly deployed, the model ID is wrong, or the input fields are wrong.
Additional resources
- Spark Jobs
- Develop and Deploy a Machine Learning Model
Develop and Deploy a Machine Learning Model
Develop and Deploy a Machine Learning Model
This tutorial walks you through deploying your own model to Fusion with Seldon Core.A real instance of this class with the Paraphrase Multilingual MiniLM L12 v2 model is as follows:In the above code, an additional function has been added in the class; this is completely fine to do.
Logging has also been added for debugging purposes.Two functions are non-negotiable:For the example, above the Python file is named
For the Paraphrase Multilingual MiniLM L12 v2 model, the requirements are as follows:In general, if an item was used in an Using the example model, the terminal commands would be as follows:This repository is public and you can visit it here: example_sbert_model
Prerequisites
- A Fusion instance with an app and indexed data
- An understanding of Python and the ability to write Python code
- Docker installed locally, plus a private or public Docker repository
- Seldon-core installed locally:
pip install seldon-core - Code editor; you can use any editor, but Visual Studio Code is used in the example
- Model: paraphrase-multilingual-MiniLM-L12-v2 from Hugging Face
- Docker image: example_sbert_model
Tips
- Always test your Python code locally before uploading to Docker and then Fusion. This simplifies troubleshooting significantly.
- Once you’ve created your Docker you can also test locally by doing
docker runwith a specified port, like 9000, which you can thencurlto confirm functionality in Fusion. See the testing example below.
LucidAcademyLucidworks offers free training to help you get started.The Course for Intro to Machine Learning in Fusion focuses on using machine learning to infer the goals of customers and users in order to deliver a more sophisticated search experience:

Local testing example
The examples in this section use the following models:- Docker command:
- Curl to hit Docker:
- Curl model in Fusion:
- See all your deployed models:
Download the model
This tutorial uses the paraphrase-multilingual-MiniLM-L12-v2 model from Hugging Face, but any pre-trained model from https://huggingface.co will work with this tutorial.If you want to use your own model instead, you can do so, but your model must have been trained and then saved though a function similar to the PyTorch’storch.save(model, PATH) function.
See Saving and Loading Models in the PyTorch documentation.Format a Python class
The next step is to format a Python class which will be invoked by Fusion to get the results from your model. The skeleton below represents the format that you should follow. See also Packaging a Python model for Seldon Core using Docker in the Seldon Core documentation.-
init: Theinitfunction is where models, tokenizers, vectorizers, and the like should be set to self for invoking.
It is recommended that you include your model’s trained parameters directly into the Docker container rather than reaching out to external storage insideinit. -
predict: Thepredictfunction processes the field or query that Fusion passes to the model.
Thepredictfunction must be able to handle any text processing needed for the model to accept input invoked in itsmodel.evaluate(),model.predict(), or equivalent function to get the expected model result. If the output needs additional manipulation, that should be done before the result is returned.
For embedding models the return value must have the shape of (1, DIM), where DIM (dimension) is a consistent integer, to enable Fusion to handle the vector encoding into Milvus or Solr.
Use the exact name of the class when naming this file.
mini.py and the class name is mini().Create a Dockerfile
The next step is to create a Dockerfile. The Dockerfile should follow this general outline; read the comments for additional details:Create a requirements file
Therequirements.txt file is a list of installs for the Dockerfile to run to ensure the Docker container has the right resources to run the model.For the Paraphrase Multilingual MiniLM L12 v2 model, the requirements are as follows:
import statement in your Python file, it should be included in the requirements file.An easy way to populate the requirements is by using in the following command in the terminal, inside the directory that contains your code:If you use
pip freeze, you must manually add seldon-core to the requirements file because it is not invoked in the Python file but is required for containerization.Build and push the Docker image
After creating the<your_model>.py, Dockerfile, and requirements.txt files, you need to run a few Docker commands.
Run the commands below in order:Deploy the model in Fusion
Now you can go to Fusion to deploy your model.- In Fusion, navigate to Collections > Jobs.
- Add a job by clicking the Add+ Button and selecting Create Seldon Core Model Deployment.
-
Fill in each of the text fields:
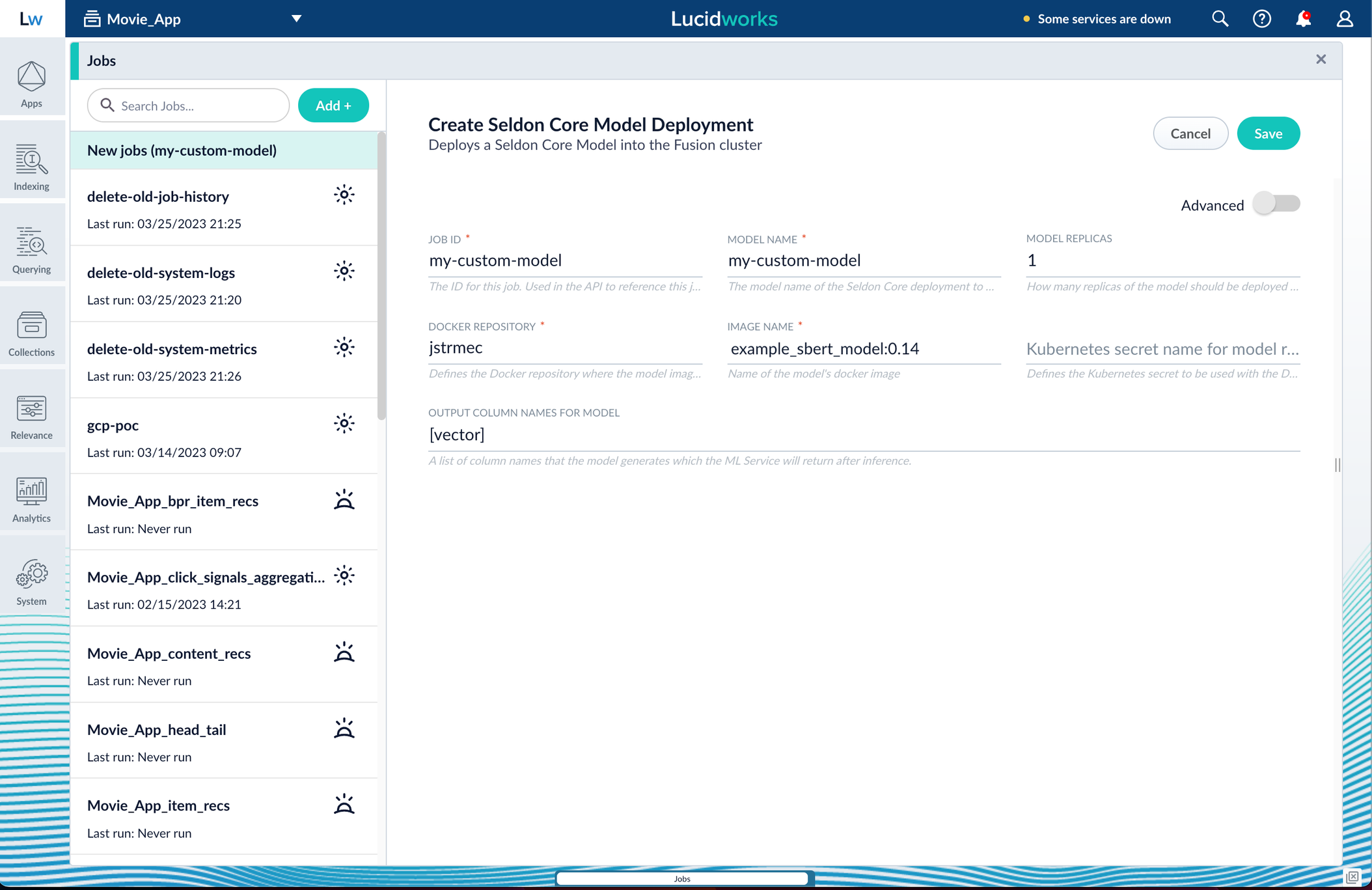
Parameter Description Job ID A string used by the Fusion API to reference the job after its creation. Model name A name for the deployed model. This is used to generate the deployment name in Seldon Core. It is also the name that you reference as a model-idwhen making predictions with the ML Service.Model replicas The number of load-balanced replicas of the model to deploy; specify multiple replicas for a higher-volume intake. Docker Repository The public or private repository where the Docker image is located. If you’re using Docker Hub, fill in the Docker Hub username here. Image name The name of the image with an optional tag. If no tag is given, latestis used.Kubernetes secret If you’re using a private repository, supply the name of the Kubernetes secret used for access. Output columns A list of column names that the model’s predictmethod returns. -
Click Save, then Run and Start.
Apply an API key to the deployment
These steps are only needed if your model utilizes any kind of secret, such as an API key. If not, skip this section and proceed to the next.- Create and modify a
<seldon_model_name>_sdep.yamlfile.
In the first line,kubectl get sdepgets the details for the currently running Seldon Deployment job and saves those details to a YAML file.kubectl apply -f open_sdep.yamladds the key to the Seldon Deployment job the next time it launches. - Delete
sdepbefore redeploying the model. The currently running Seldon Deployment job does not have the key applied to it. Delete it before redeploying and the new job will have the key. - Lastly, you can encode into Milvus.
Create a Milvus collection
- In Fusion, navigate to Collections > Jobs.
- Click the Add+ Button and select Create Collections in Milvus.
This job creates a collection in Milvus for storing the vectors sent to it. The job is needed because a collection does not automatically spawn at indexing or query time if it does not already exist. - Name the job and the collection.
- Click Add on the right side of the job panel.
The key to creating the collection is the Dimension text field; this must exactly match the shape value your output prediction has.
In our example the shape is (1,384), so 384 will be in the collections Dimension field: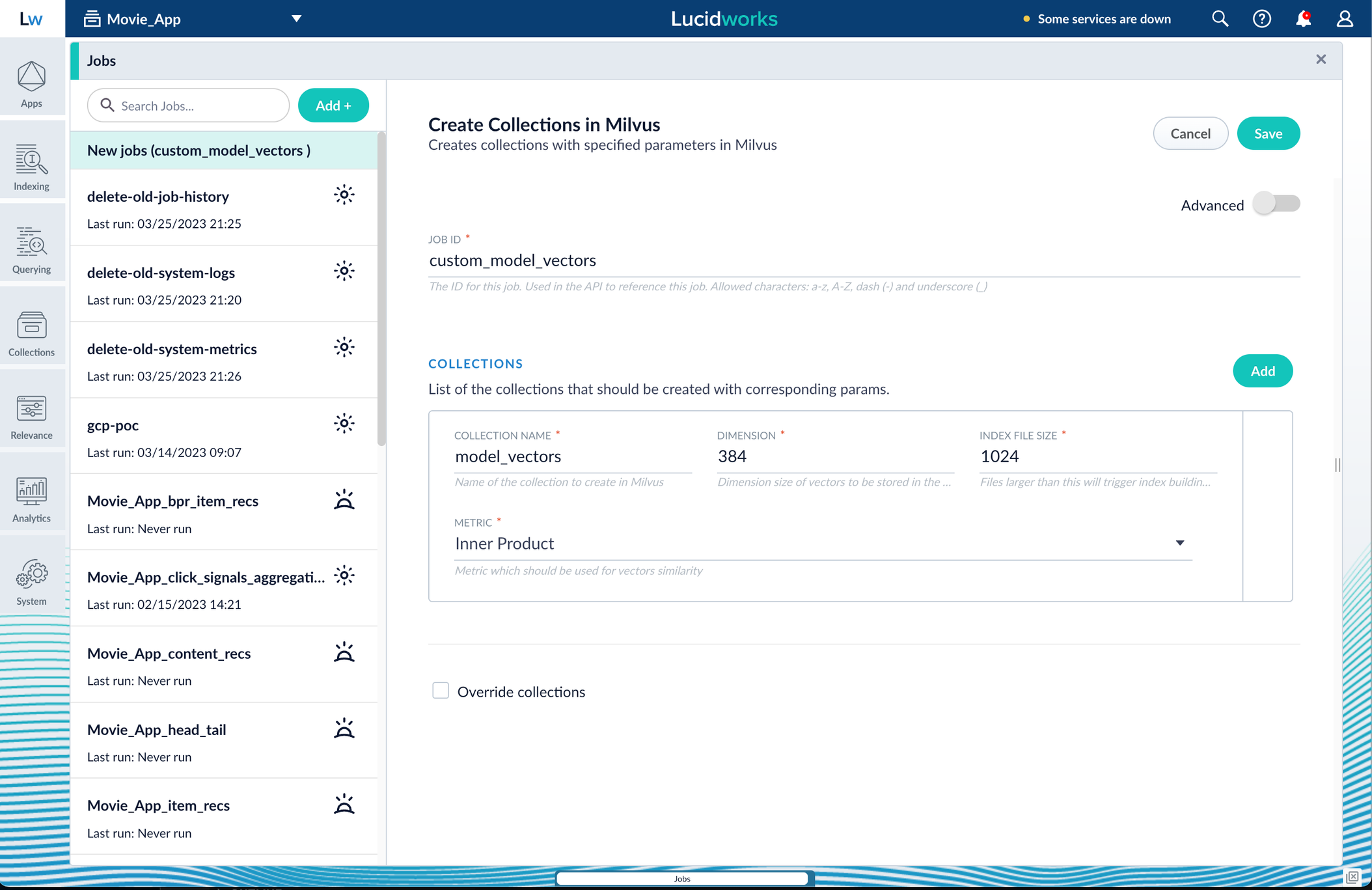
Inner Product, but this also depends on use case and model type. - Click Save, then Run and Start.
Configure the Fusion pipelines
Your real-world pipeline configuration depends on your use case and model, but for our example we will configure the index pipeline and then the query pipeline.Configure the index pipeline- Create a new index pipeline or load an existing one for editing.
- Click Add a Stage and then Encode to Milvus.
- In the new stage, fill in these fields:
- The name of your model
- The output name you have for your model job
- The field you’d like to encode
- The collection name
- Save the stage in the pipeline and index your data with it.
- Create a new query pipeline or load an existing one for editing.
- Click Add a Stage and then Milvus Query.
- Fill in the configuration fields, then save the stage.
- Add a Milvus Ensemble Query stage.
This stage is necessary to have the Milvus collection scores taken into account in ranking and to weight multiple collections. The Milvus Results Context Key from the Milvus Query Stage is used in this stage to preform math on the Milvus result scores. One (1) is a typical multiplier for the Milvus results but any number can be used. - Save the stage and then run a query by typing a search term.
- To verify the Milvus results are correct, use the Compare+ button to see another pipeline without the model implementation and compare the number of results.
LucidAcademyLucidworks offers free training to help you get started.The Course for Machine Learning Demystified focuses on key concepts in machine learning, plus the available Fusion machine learning jobs and pipeline stages: