Connector
A connector fetches and processes data according to the datasource configuration.
Datasource
A datasource is a Fusion object that configures how connectors ingest data and routes that data through parsers, index pipelines, and into collections.
Pro
Pro connectors are V2 connectors that meet the highest standards for reliability and stability, representing the premier tier of Fusion’s connector platform.
V2
V2 connectors are the current generation built on a Java SDK framework that enables independent updates, horizontal scaling, and custom connector development.
V1
V1 connectors are deprecated components built on the Anda crawler framework and included in the Fusion 5 image.Deprecated
Data ingestion process
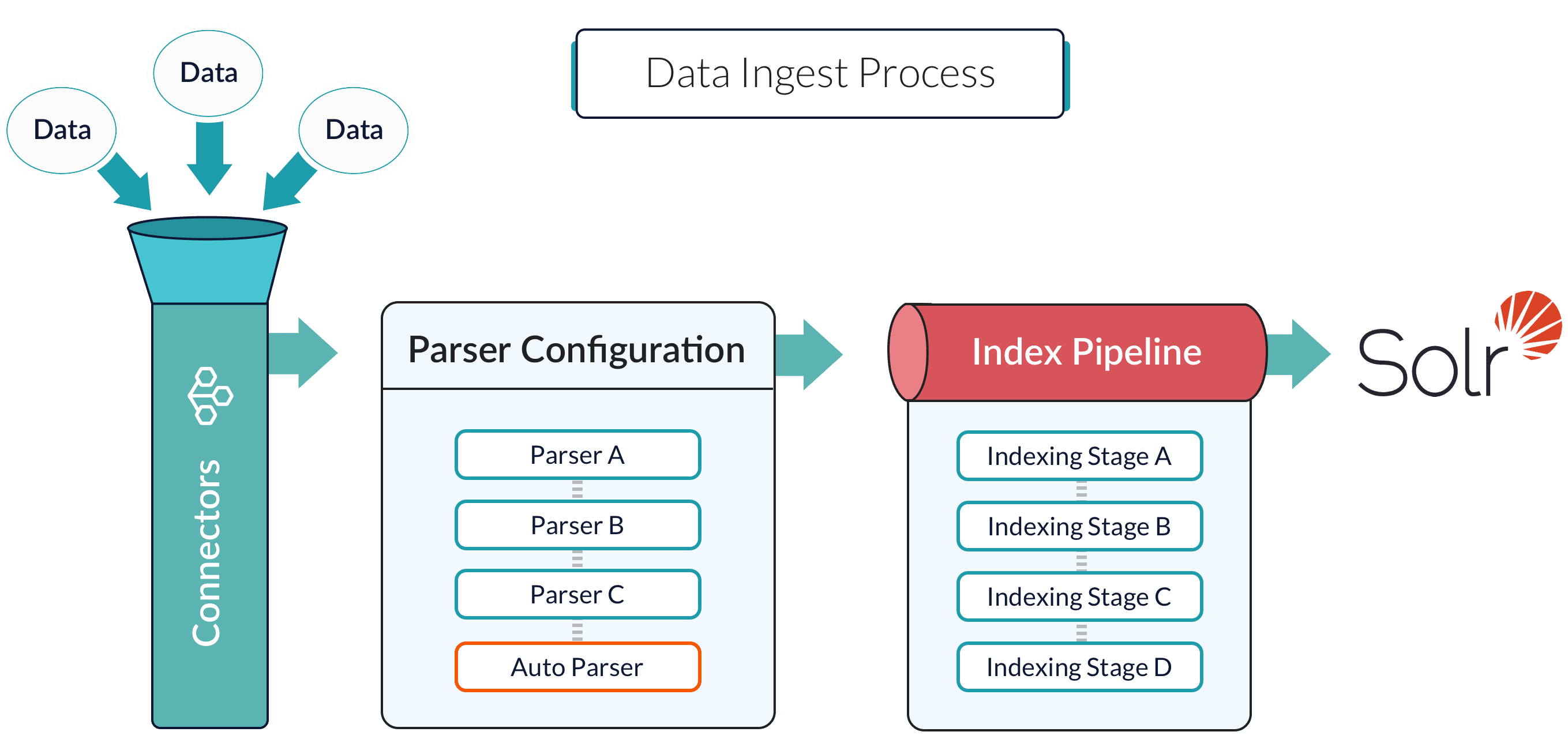
Fusion connects to your data
Connectors fetch data from your source systems based on the datasource configuration.
Data is processed according to your datasource configuration
The datasource configuration determines which parser stages and index pipeline stages process the ingested data.Parser stages transform raw data into structured documents with defined fields and values.Index pipeline stages prepare documents for search by normalizing values, enriching content, applying transformations, and filtering unwanted data.
Find your connector
Platforms
Pro
Pro connectors are V2 connectors that have been built to a notably high standard of quality, ensuring exceptional reliability and stability. They represent the premier tier of Fusion’s data integration platform, tested and validated to meet rigorous performance criteria. Lucidworks prioritizes development efforts to elevate V2 connectors to Pro status. When a connector achieves this quality threshold, the promotion is announced in the release notes.V2
V2 connectors represent the current generation of Fusion’s data integration platform. They are built on a Java SDK framework and replace the deprecated V1 connector architecture.Why V2 exists
The V2 platform addresses fundamental limitations in the original V1 connector design. V1 connectors were tightly coupled to Fusion releases, making updates slow and requiring full Fusion upgrades to get connector improvements. Security models mixed content and access controls together. Scaling required complex configuration rather than simply adding resources. V2 solves these problems. Connectors now update independently from Fusion itself, so you can deploy the latest plugin version without upgrading Fusion. Access controls are separated from content through standalone Security Access-control Lists (ACL). V2 also supports horizontal scaling, which lets you add more connector instances to work on the same job. The V2 platform also opens custom connector development through the Java SDK framework, giving you the tools to integrate any data source. For more information, see Build your own.Technical architecture
The V2 platform is built on Google’s gRPC framework, a high-performance RPC system. gRPC provides HTTP/2 transport, protocol buffer serialization for efficient data handling, and support for bi-directional and multiplexed streams. This foundation enables the flexible service definitions, efficient communication, and distributed architecture that power the V2 platform.Remote connectors
V2 connectors support two deployment models. Hosted connectors run inside the Fusion environment itself, with each node running independent connector instances. Remote connectors run outside Fusion as lightweight client processes that communicate back to the platform using efficient messaging. The remote model gives you deployment flexibility. Place connectors wherever your data lives, whether that’s for performance reasons, security requirements, or network access constraints. Learn more about remote deployment.V1
V1 connectors are developed with a general-purpose crawler framework called Anda, created by Lucidworks. Anda helps simplify and streamline crawler development, reducing the task of developing a new crawler to gain access to your data. In Fusion 5, V1 connectors are included in the Fusion image.Install and manage
Learn how to install, update, and manage V2 connectors in Fusion.Install the latest version
Install the latest version
- Navigate to Indexing > Datasources.
- Click Add.
- Select the connector from the list. It will install the latest version automatically.
It may take several minutes before the connector appears in the list of installed connectors.
Update to the latest version
Update to the latest version
This process always installs the latest version of the connector. Check the documentation for compatibility and release notes for key changes.
- Navigate to System > Blobs.
- Expand the Connector Plugin accordion.
- Select and delete the current connector version.
- Reinstall the connector using the instructions found in Install a Connector.
Install a specific version
Install a specific version
- Download the V2 connector Zip file.
- Navigate to System > Blobs.
- Expand the Connector Plugin accordion.
- Select and delete the current connector version.
- Click Add.
- Upload the Zip file containing the specific connector version.