Connectors 101
The course for Connectors 101 focuses on how to choose, install, and configure connectors in Fusion.
Connector frameworks
Fusion connectors are built using two different frameworks. Learn more about V1 and V2 connectors.Connector configuration
Connector plugins can be hosted within Fusion, or can run remotely. The communication of messages between Fusion and a remote connector or hosted connector are identical; Fusion sees them as the same kind of connector. This means you can implement a plugin locally, connect to a remote Fusion for initial testing, and when done, upload the same artifact into Fusion, so Fusion can host it for you.Hosted connectors
Connectors hosted in Fusion are cluster aware. This means that when a new instance of Fusion starts up, the connectors on other Fusion nodes become aware of the new connectors, and vice versa. This makes scaling the crawling process very natural and simple.Remote connectors
In Fusion 5.x, Remote connectors become clients of Fusion. These clients run a very lightweight process and communicate to Fusion using a very efficient messaging format. This option makes it possible to put the connector wherever the data lives. This may be done for performance reasons, or for security/access reasons. If you are using Fusion 4.x, see Remote Connectors for more details.Connector logs
You can find connector logs inhttps://FUSION_HOST:FUSION_PORT/var/log/connectors.
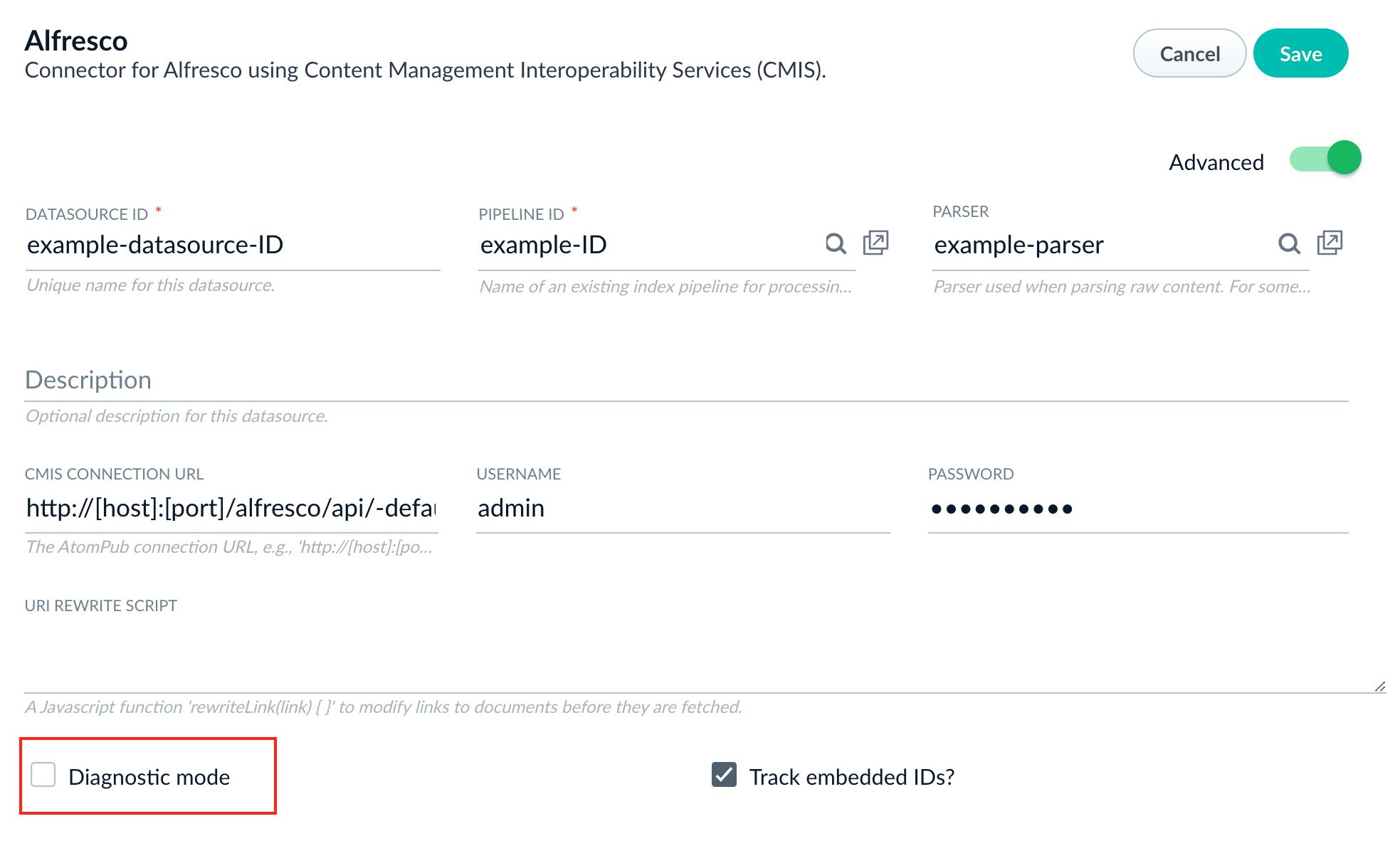
Most connectors support Diagnostic Mode (also known as Diagnostic Logging), which enables Fusion to print more detailed information to the logs about each request, including the ID of every document inserted, updated, or deleted in the oplog. More information on Diagnostic Mode can be found in the Configuration section of the connectors which offer it. You may need to click on the Advanced slider to show more settings.
Security trimming
Security trimming in Fusion connectors ensures that users can only access the data they have permissions for, maintaining security and compliance. It works by filtering out unauthorized documents or data based on user access rights before the data is exposed in search results.Security Trimming With Fusion Connectors
The course for Security Trimming With Fusion Connectors focuses on how to apply security trimming using Fusion connectors.
Descriptions of crawl types
In Fusion connectors, “crawl,” “recrawl,” “incremental crawl,” “stray content deletion,” and “dedupe” describe different behaviors during data collection. The terms often appear together, but each one controls a specific aspect of how content is added, updated, or removed.- Full Crawl:
A full crawl is performed the first time you run a datasource job to discover and ingest all items in scope. Some connectors expose a full crawl option to force this behavior. - Recrawl:
A recrawl is any subsequent run of the same datasource. The connector uses the CrawlDB and checkpoints to determine what has changed since the previous run.- Incremental crawl:
An incremental crawl is a mode of recrawl that fetches only new or modified items since the last run. - Stray content deletion:
Enabling stray content deletion removes items during a recrawl when those itmes no longer exist at the source.
- Incremental crawl:
- Dedupe:
Dedupe prevents duplicate documents from being indexed, such as identical pages or items that resolve to the same canonical record.
Learn more
Delete a Connector
Delete a Connector
You can delete a connector using the Fusion UI or the Blob Store API.
Deleting a connector using the Fusion UI
- In the Fusion UI, navigate to System > Blobs.
- Under Connector Plugin, select the connector to delete.
- Click Delete Blob. Fusion prompts you to confirm that you want to delete the blob.
- Click Yes, Delete. The connector disappears from the blob list.
Deleting a connector using the REST API
-
Get the list of blobs of the connector plugin type:
-
Locate the connector you want to delete, and copy its ID.
For example, the Jive connector ID is
lucid.jive: -
Delete the connector as follows:
For exampleA null response indicates success. You can verify that the connector is deleted like this: