- Latest version. This is the latest version of the connector. To check the connector version you’re using, navigate to System > Blobs, open the Connector Plugin directory, and select the connector. The version value is declared in the connectorVersion field.
- Compatible with Fusion version. This provides the versions of Fusion that are compatible with the latest version of the connector.
Find your connector
Installation instructions
Fusion includes all available connectors in Indexing > Datasources. Some connectors come pre-installed, but you must install others manually. See the following resources for your version of Fusion:Install or update a connector - Fusion 5
Install or update a connector - Fusion 5
When you create a new datasource that requires an uninstalled connector, Fusion releases 5.2 and later automatically download and install the connector using the Datasources dropdown. You can also update the connector using the Blob Store UI or via the Connector API.
Install a connector using the Datasources dropdown
- In your Fusion app, navigate to Indexing > Datasources.
- Click Add.
- In the list of connectors, scroll down to the connectors marked Not Installed and select the one you want to install.
Fusion automatically downloads it and moves it to the list of installed connectors.
Install or update a connector using the Blob Store UI
- Download the connector zip file from Download V2 connectors.
Do not expand the archive; Fusion consumes it as-is.
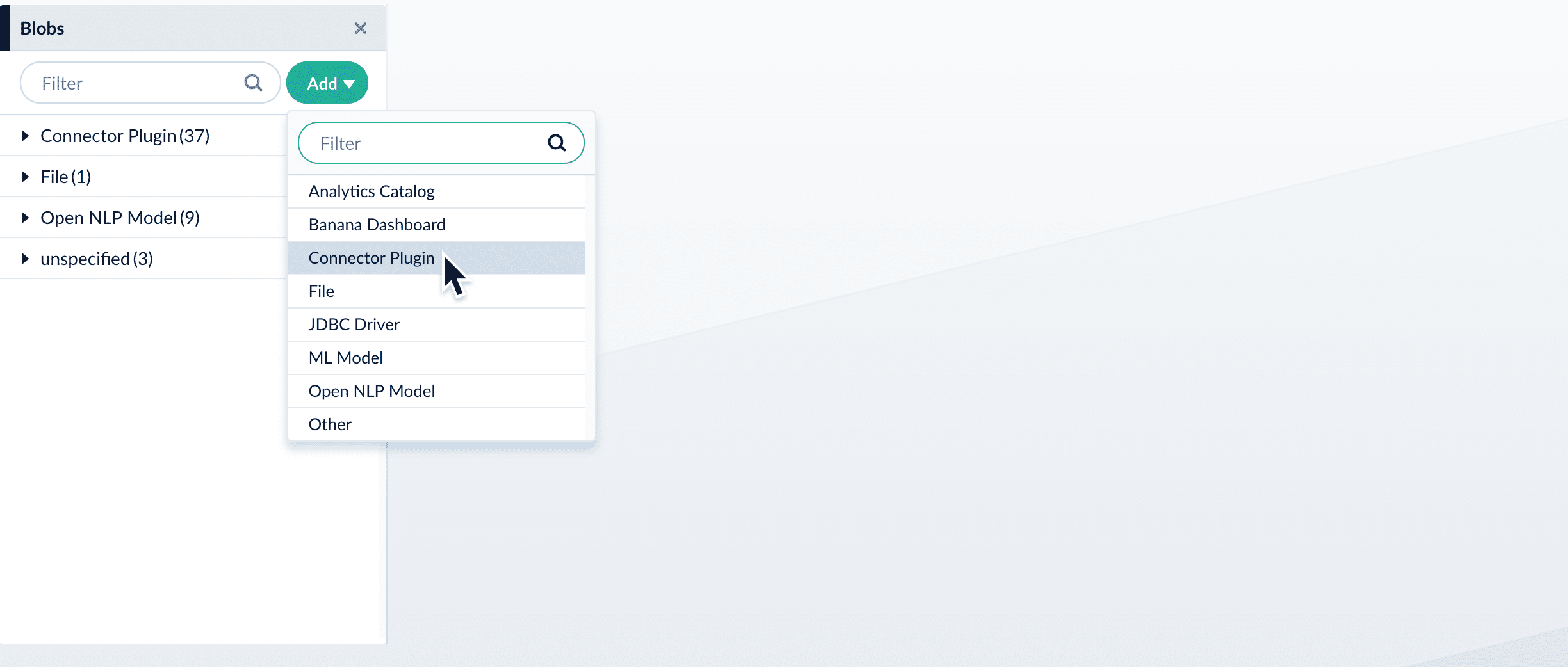
- In your Fusion app, navigate to System > Blobs.
- Click Add.
- Select Connector Plugin.
- Click Choose File and select the downloaded zip file from your file system.
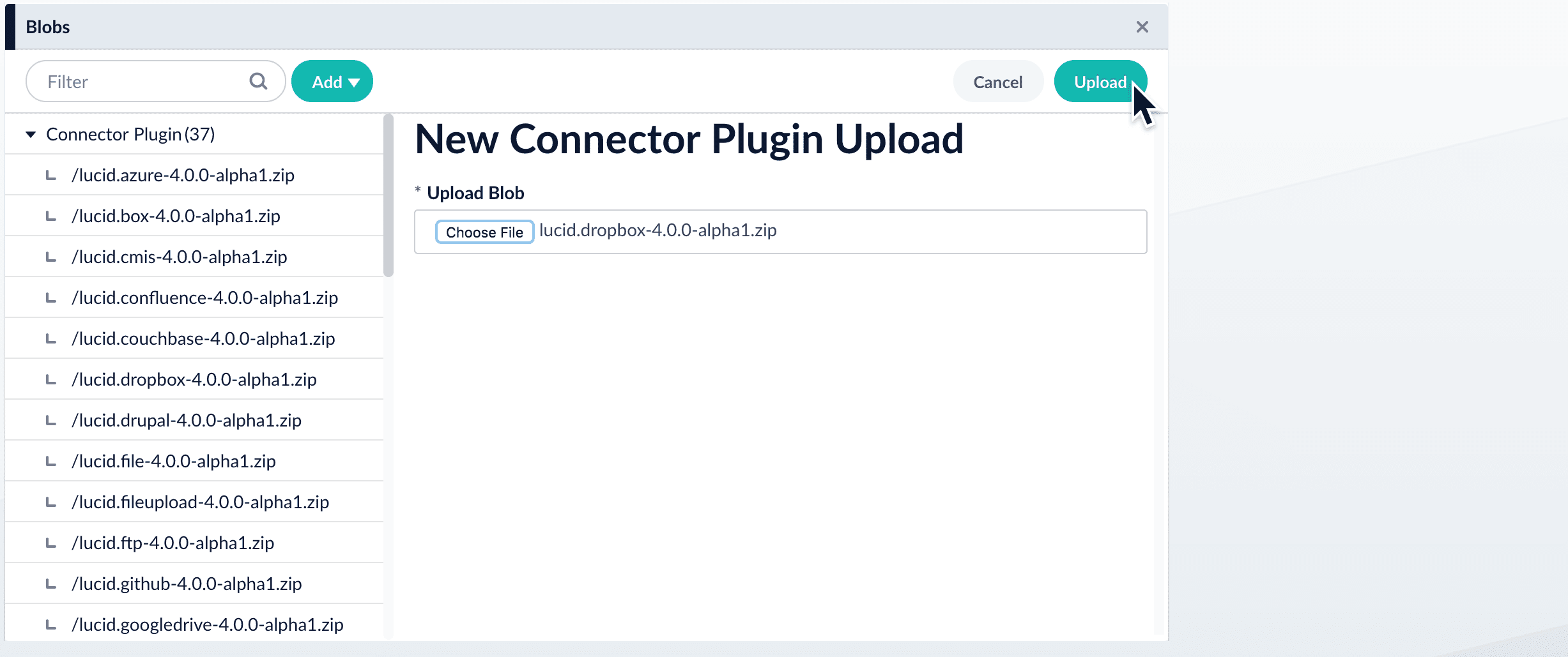
- Click Upload.
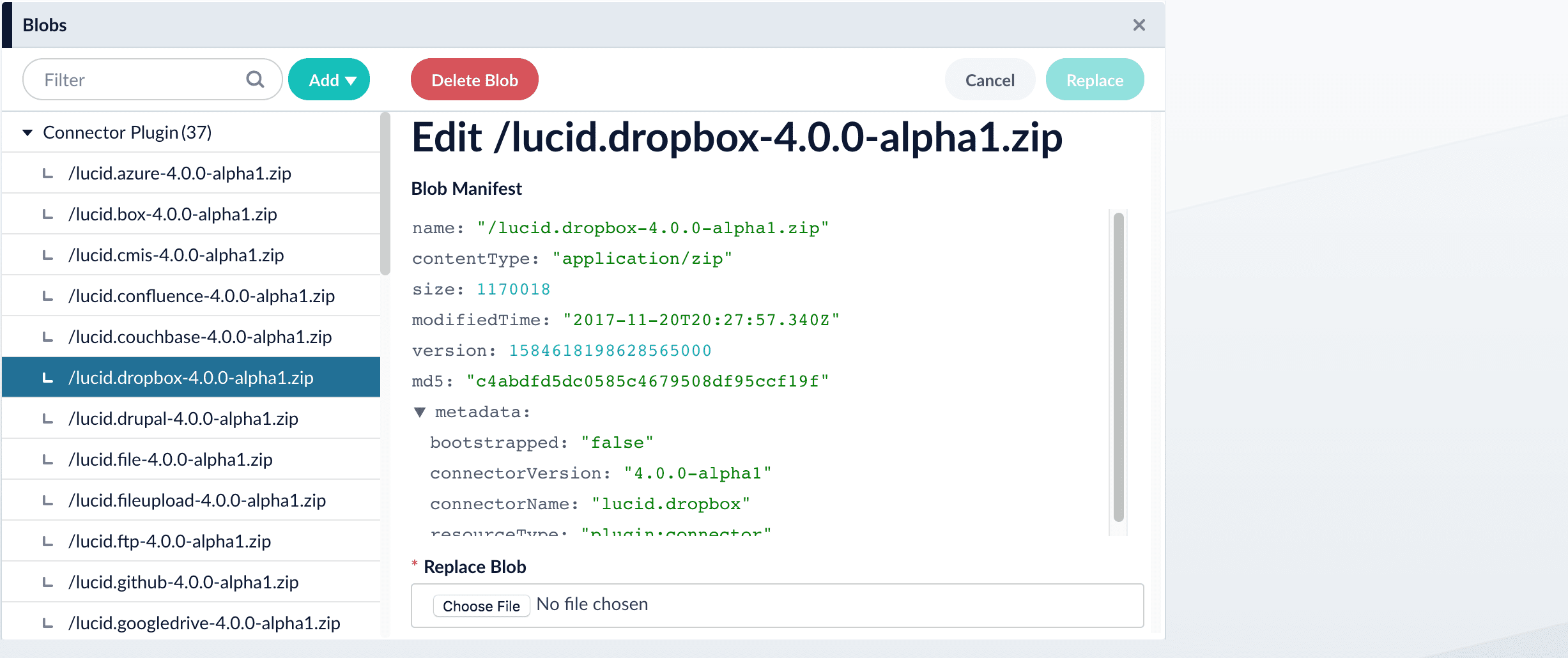
The new connector’s blob manifest appears.
Install or update a connector using the Connector API
-
Download the connector zip file from Download V2 connectors.
Do not expand the archive; Fusion consumes it as-is.
-
Upload the connector zip file to Fusion’s plugins.
Specify a
pluginIdas in this example:Fusion automatically publishes the event to the cluster, and the listeners perform the connector installation process on each node. -
Look in
https://FUSION_HOST:FUSION_PORT/apps/connectors/plugins/to verify the new connector is installed.
Reinstall a connector
To reinstall a connector for any reason, first delete the connector then use the preceding steps to install it again. This may take a few minutes to complete depending on how quickly the pods are deleted and recreated.Install a Connector - Fusion 4.x
Install a Connector - Fusion 4.x
In Fusion 4.x, connectors are installed by uploading them to the blob store. You can use any of these methods to install a connector:After you install a connector, you can Configure A New Datasource.
- By installing connectors as “bootstrap plugins”, that is, by putting them in the
bootstrap-pluginsdirectory during initial installation or an upgrade - By using the Blob Store UI after installation or an upgrade
- By using the Blob Store API after installation or an upgrade.
During upgrades, the migrator handles some aspects of installing connectors. Depending on the target version and the presence or absence of an Internet connection, there might be manual steps. Installing connectors during upgrades is explained where needed in the upgrade procedures.
Install a connector as a bootstrap plugin
Fusion can install connectors as “bootstrap plugins.” All this means is that you put the connectorzip files in a specific directory named bootstrap-plugins, and Fusion installs the connectors the first time it starts during initial installation or an upgrade.- Download the connector zip file from Fusion 4.x Connector Downloads.
Do not expand the archive; Fusion consumes it as-is. Also, do not start Fusion until instructed to do so by the installation or upgrade instructions. - Under the version-numbered Fusion directory, place the connector in the directory
apps/connectors/bootstrap-plugins/(on Unix) or\apps\connectors\bootstrap-plugins\(on Windows). - Start Fusion when instructed to do so in the installation or upgrade procedure.
Install or update a connector using the Blob Store UI
-
Download the connector zip file from Fusion 4.x Connector Downloads.
Do not expand the archive; Fusion consumes it as-is.
- In the Fusion workspace, navigate to System > Blobs.
- Click Add.
-
Select Connector Plugin.
-
Click Choose File and select the downloaded zip file from your file system.
-
Click Upload.
The new connector’s blob manifest appears.
Install or update a connector using the Blob Store API
-
Download the connector zip file from Fusion 4.x Connector Downloads.
Do not expand the archive; Fusion consumes it as-is.
-
Upload the connector zip file to Fusion’s blob store.
Specify an arbitrary blob ID, and aresourceTypevalue ofplugin:connector, as in this example:Fusion automatically publishes the event to the cluster, and the listeners perform the connector installation process on each node. -
Look in
https://FUSION_HOST:FUSION_PORT/apps/connectors/plugins/to verify the new connector is installed.