Compatible with Fusion version: 4.0.0 through 5.12.0
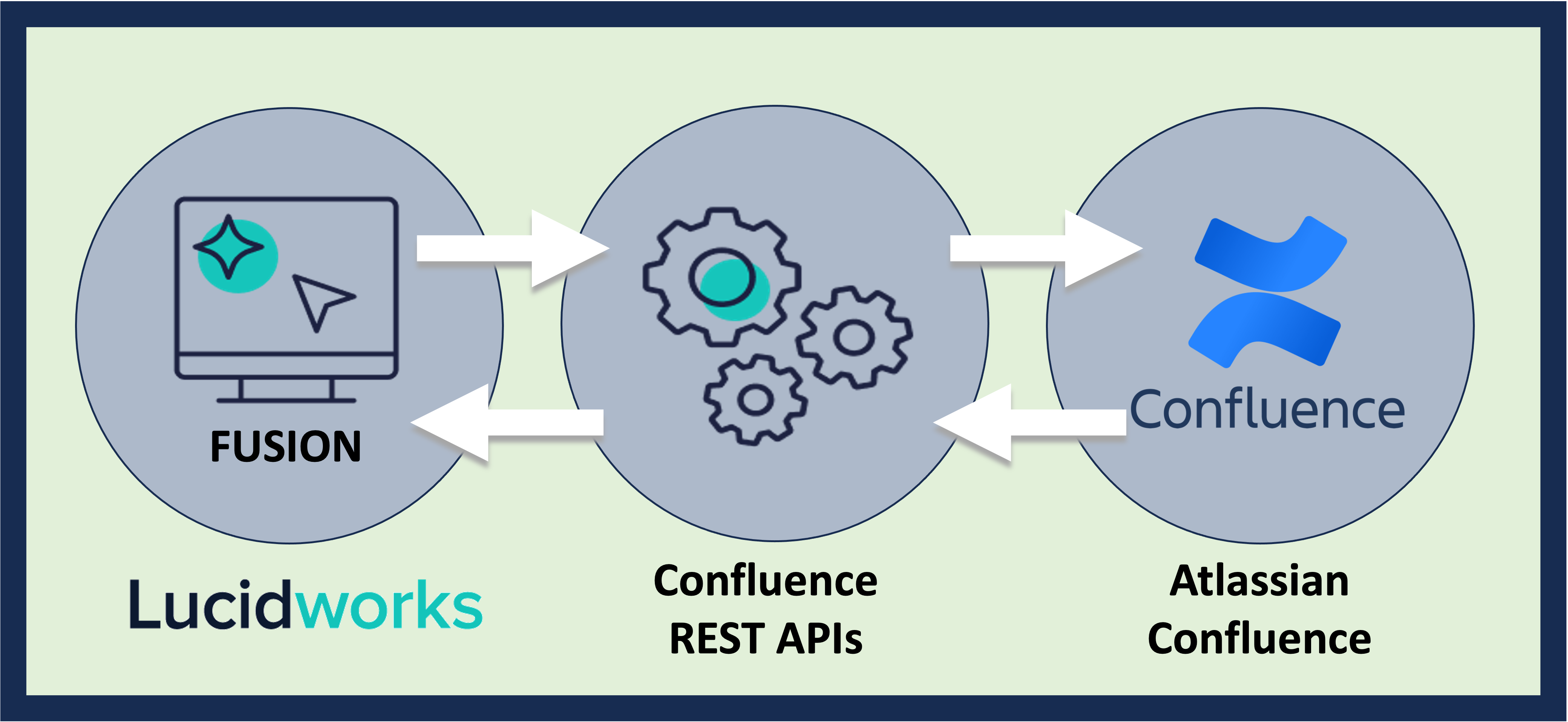
Prerequisites
Perform these prerequisites to ensure the connector can reliably access, crawl, and index your data. Proper setup helps avoid configuration or permission errors, so use the following guidelines to keep your content available for discovery and search in Fusion.- The user account in Confluence must be set up.
- Grant read access to the user account for any spaces and pages being crawled.
- If you want to crawl attachments, then grant read access to the user account for attachments.
- If you are indexing ACLs for security trimming, the user account must have the ability to query Users and Groups APIs.
Authentication
Setting up the correct authentication according to your organization’s data governance policies helps keep sensitive data secure while allowing authorized indexing. The methods of authenticating are basic authentication, NTLM authentication for Windows-based enterprise networks with Active Directory, and request authentication for OAuth or a personal access token.Basic authentication
The authentication options for the Confluence V1 connector in Lucidworks Fusion depend on whether you’re using Confluence Cloud or Confluence Server/Data Center. For Confluence Server/Data Center, you can use a username and password, unless it’s disabled by your organization’s policies. Confluence Cloud does not support password-based login. Instead, use the request authentication method with an API token.NTLM authentication for Windows/Active Directory
Gather credentials with read access to the Confluence pages and any attachments or APIs you want the connector to crawl. Enter the following in Fusion:- Your AD account username as
Confluence Username. - Your AD account password as
Confluence Password or API Token. - Your Windows domain as
Domain (NTLM auth only).
Request authentication
Request authentication is a flexible method that can use a Bearer token, API key, or OAuth token, depending on your Confluence setup. For Confluence Cloud, go to Atlassian API tokens and generate a new token. After entering your credentials in Fusion, save and test the connection. Fusion should return “Success” or a detailed error such as401, invalid token.
Common Issues
If you encounter any of the following problems, take the suggested actions to try and resolve them:401 Unauthorized: Check your token/credentials and ensure your user account has proper access.- Token works in browser but not Fusion: Verify HTTPS is used and ensure no firewall blocks Fusion from reaching Confluence.
- “User does not have permission” error: Ensure the user account has read access to the spaces, pages, and attachments.
Confluence Connector’s security trimming
Why do some field names have different numbers? After crawling some test Confluence content, the Solr index has ACL fields such asacl_users_0_s and acl_groups_0_ss, but the field names can have different numbers. For example, some documents have acl_users_1_s or acl_users_6_s.
This is due to the strange way that Confluence handles user and group viewing permissions. Each of these fields represents an ancestor of the item’s security. If a user does not match EACH level of permissions, the user cannot see the document and the doc will be filtered out.
You will see three fields that are used during security trimming:
ancestorCount_istores the number of ancestors this item hasacl_users_i_sstores the users allowed to see this item at ancestor numberiacl_groups_i_sstores the groups allowed to see this item at ancestor numberi
queryUser and we return the Confluence documents this user can access.
The Confluence security trimming algorithm does the following:
- Calculate the maximum
ancestorCount_iof all documents in the index (max(ancestorCount_i)). - Query Confluence for the Confluence Security Groups that
queryUseris part of. - Then
for i from [0 to max(ancestorCount_i)], append an AND clause for the security filter to match against each ancestor level for theacl_users_i_sandacl_groups_1_sfields:
Learn more
Set Up NT Lan Manager Authentication for Confluence Connector
Set Up NT Lan Manager Authentication for Confluence Connector
This topic describes how to configure a Confluence site and authenticate with NT Lan Manager (NTLM) to use the Fusion connector.
Configure Active Directory for Confluence
Add a new directory with the following settings:- Name. Directory name.
- Directory Type. Microsoft Active Directory.
- Hostname. Hostname of server running Lightweight Directory Access Protocol (LDAP).
- Port. Port number.
- Username. LDAP user login.
- Password. LDAP user password.
- Base DN. Distinguished Name (DN) of the LDAP object that is the root node from which to search for users and groups.
- Additional User DN. DN prepended to the base DN to limit user search scope.
- Additional Group DN. DN prepended to the base DN to limit group search scope.
- Permissions > Read/Write
Create authenticating account
- Access the Server Manager in the Active Directory.
- Select Roles > Active Directory Domain Services.
- Select Active Directory Users and Computers to expand the node.
- Expand the directory and right-click Computers to create the new account.
- Select the Member of tab.
- Select Domain Computers.
- Select the General tab and enter values in each field.
The Computer name field is required.
Configure delegation for the authenticating account
- Access the authenticating account and select the Delegation tab.
- Select Trust this computer for delegation to specified services only.
- In the Trust field, select Use any authentication protocol.
- Select Add.
- In the Add Services window, select Users or Computers.
- Select the server running the netlogon service from the results list and select OK.
- In the Service Type column, select netlogon and select OK.
The Delegation tab displays the netlogon service available for the account. - Save the following script to the Active Directory server:
- Execute the command with the hostname and password to set:
SetComputerPassword.vbs Confluence$@WIN-424E42TCKBB FroFro123#
The following is a sample result:
Install and configure EasySSO
- Access General Configuration > Find New Apps.
- Search for NTLM and select the EasySSO Admin app to install it.
- In the jespa Licensing section, select the latest
jespa.zipfile and download the file. - Install the file and buy a license.
- Enter values in the following fields to configure the app:
- Domain. Fully-qualified domain name (FQDN) of your domain.
- Account. Active directory authentication account.
- Password. Authentication account password.
- Select Save.
- Select Test Connection to verify NTLM authentication with the account logs in to Confluence.