Configuration Reference
Connectors are the conduit between Fusion and your external data sources. Connectors retrieve your data and import it into Fusion.
To ensure compatibility between the connector and your Fusion version, please refer to the Fusion compatibility declaration located at the beginning of each connector configuration reference article. For example:

- Latest version. This is the latest version of the connector. To check the connector version you’re using, navigate to System > Blobs, open the Connector Plugin directory, and select the connector. The version value is declared in the connectorVersion field.
- Compatible with Fusion version. This provides the versions of Fusion that are compatible with the latest version of the connector.
Installation instructions
Fusion includes all available connectors in Indexing > Datasources. Some connectors come pre-installed, but you must install others manually. See the following resources for your version of Fusion:Install or update a connector - Fusion 5
Install or update a connector - Fusion 5
When you create a new datasource that requires an uninstalled connector, Fusion releases 5.2 and later automatically download and install the connector using the Datasources dropdown. You can also update the connector using the Blob Store UI or via the Connector API.
Install a connector using the Datasources dropdown
- In your Fusion app, navigate to Indexing > Datasources.
- Click Add.
- In the list of connectors, scroll down to the connectors marked Not Installed and select the one you want to install. Fusion automatically downloads it and moves it to the list of installed connectors.
You can view and download all current and previous V2 connector releases at Download Connectors.
Install or update a connector using the Blob Store UI
- Download the connector zip file from Download V2 connectors.
Do not expand the archive; Fusion consumes it as-is.
- In your Fusion app, navigate to System > Blobs.
- Click Add.
- Select Connector Plugin.
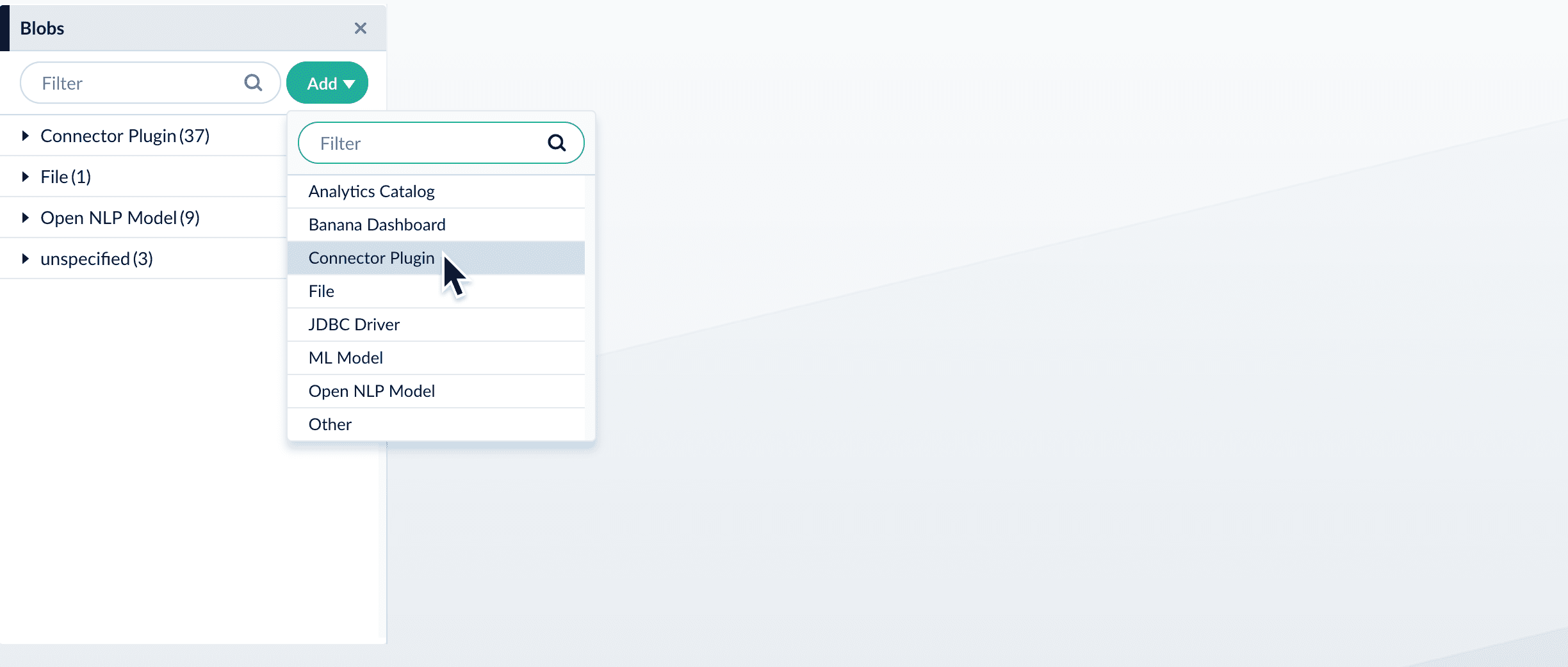
- Click Choose File and select the downloaded zip file from your file system.
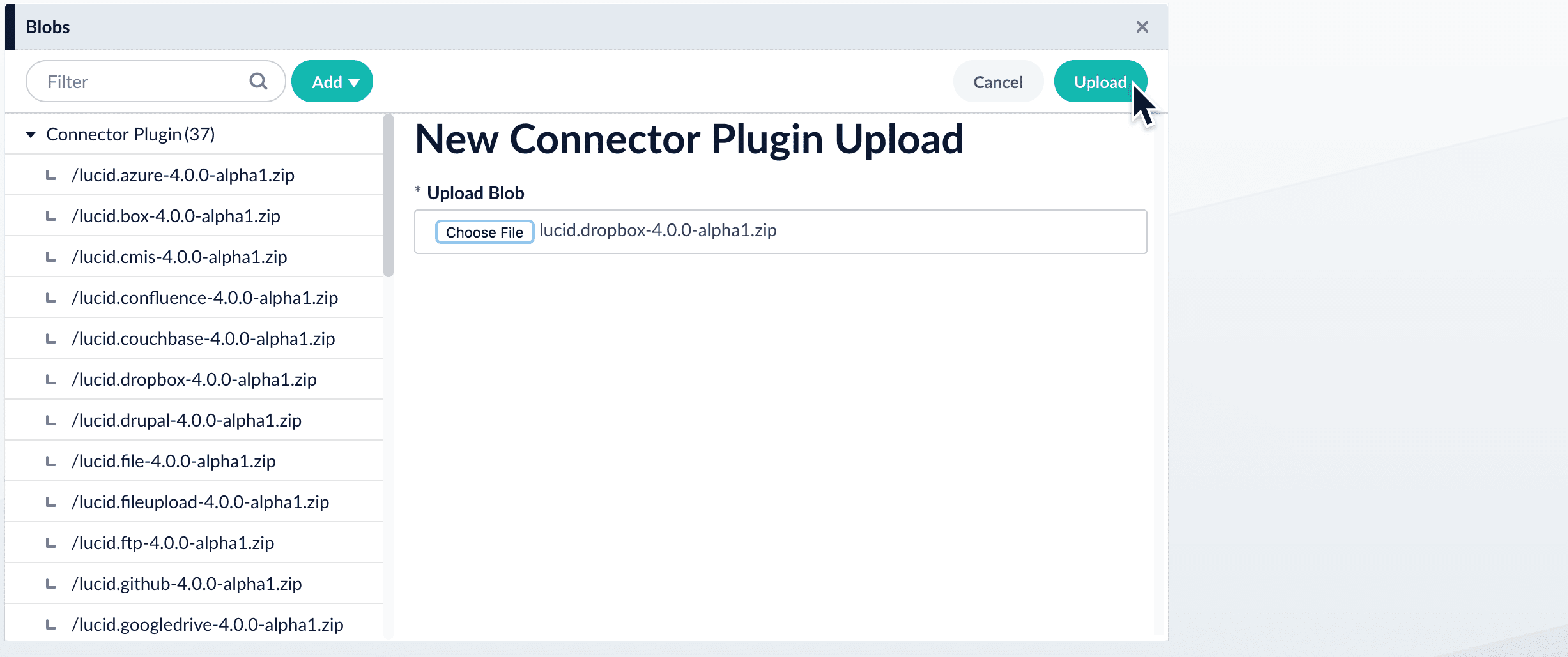
- Click Upload.
The new connector’s blob manifest appears.
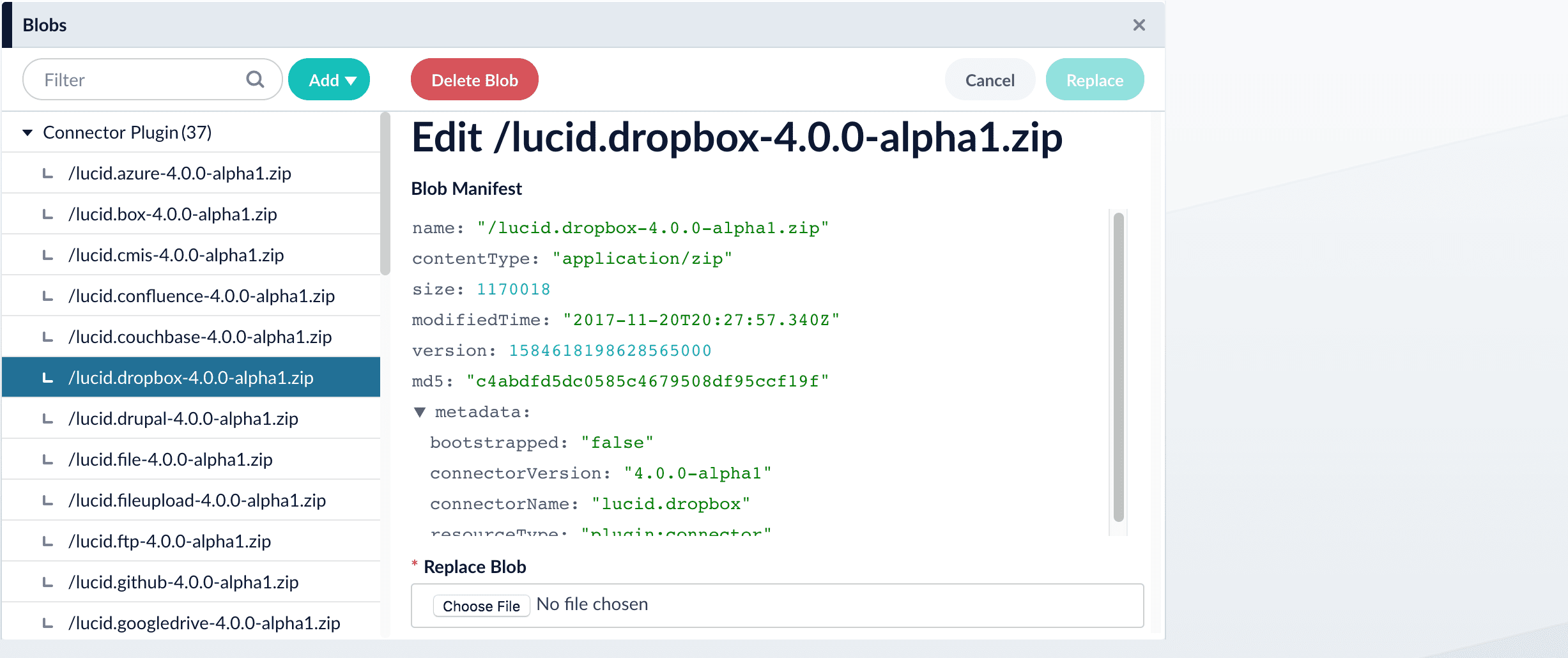
Wait several minutes for the connector to finish uploading to the blob store before installing the connector using the Datasources dropdown.
Install or update a connector using the Connector API
-
Download the connector zip file from Download V2 connectors.
Do not expand the archive; Fusion consumes it as-is.
-
Upload the connector zip file to Fusion’s plugins.
Specify a
pluginIdas in this example:Fusion automatically publishes the event to the cluster, and the listeners perform the connector installation process on each node.If thepluginIdis identical to an existing one, the old connector will be uninstalled and the new connector will be installed in its place. To get the list of existing plugin IDs, run:curl -u USERNAME:PASSWORD https://FUSION_HOST:FUSION_PORT/api/connectors/plugins -
Look in
https://FUSION_HOST:FUSION_PORT/apps/connectors/plugins/to verify the new connector is installed.
Reinstall a connector
To reinstall a connector for any reason, first delete the connector then use the preceding steps to install it again. This may take a few minutes to complete depending on how quickly the pods are deleted and recreated.Install a Connector - Fusion 4.x
Install a Connector - Fusion 4.x
In Fusion 4.x, connectors are installed by uploading them to the blob store. You can use any of these methods to install a connector:After you install a connector, you can Configure A New Datasource.
- By installing connectors as “bootstrap plugins”, that is, by putting them in the
bootstrap-pluginsdirectory during initial installation or an upgrade - By using the Blob Store UI after installation or an upgrade
- By using the Blob Store API after installation or an upgrade.
During upgrades, the migrator handles some aspects of installing connectors. Depending on the target version and the presence or absence of an Internet connection, there might be manual steps. Installing connectors during upgrades is explained where needed in the upgrade procedures.
You can view and download all current and previous V2 connector releases at plugins.lucidworks.com.
Install a connector as a bootstrap plugin
Fusion can install connectors as “bootstrap plugins.” All this means is that you put the connectorzip files in a specific directory named bootstrap-plugins, and Fusion installs the connectors the first time it starts during initial installation or an upgrade.- Download the connector zip file from Fusion 4.x Connector Downloads. Do not expand the archive; Fusion consumes it as-is. Also, do not start Fusion until instructed to do so by the installation or upgrade instructions.
-
Under the version-numbered Fusion directory, place the connector in the directory
apps/connectors/bootstrap-plugins/(on Unix) or\apps\connectors\bootstrap-plugins\(on Windows). - Start Fusion when instructed to do so in the installation or upgrade procedure.
Install a connector using the Blob Store UI
-
Download the connector zip file from Fusion 4.x Connector Downloads.
Do not expand the archive; Fusion consumes it as-is.
- In the Fusion workspace, navigate to System > Blobs.
- Click Add.
-
Select Connector Plugin.
-
Click Choose File and select the downloaded zip file from your file system.
-
Click Upload.
The new connector’s blob manifest appears.
Install a connector using the Blob Store API
-
Download the connector zip file from Fusion 4.x Connector Downloads.
Do not expand the archive; Fusion consumes it as-is.
-
Upload the connector zip file to Fusion’s blob store.
Specify an arbitrary blob ID, and a
resourceTypevalue ofplugin:connector, as in this example:Fusion automatically publishes the event to the cluster, and the listeners perform the connector installation process on each node.If the blob ID is identical to an existing one, the old connector will be uninstalled and the new connector will installed in its place. To get the list of existing blob IDs, run:curl -u USERNAME:PASSWORD localhost:8764/api/blobs -
Look in
https://FUSION_HOST:FUSION_PORT/apps/connectors/plugins/to verify the new connector is installed.
Reinstall a connector
To reinstall a connector for any reason, first delete the connector then use the preceding steps to install it again. This may take a few minutes to complete depending on how quickly the pods are deleted and recreated.ImportantCheck the connector reference page linked in the table for Fusion compatibility information.
| Database connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Couchbase V2 | The Couchbase V2 connector uses the Couchbase Java client to retrieve data stored in Couchbase. | Couchbase Server 6.0.3 Enterprise Edition (V2) | V2 | No |
| Couchbase V1 | The Couchbase V1 connector uses the Cross-Datacenter Replication (XDCR) feature of Couchbase to retrieve data stored in Couchbase continuously in real-time. | Couchbase Server 2.5.1 Enterprise Edition (V1) - Due to a dependency issue, the Couchbase V1 connector does not work as expected in Fusion 4.2.x. | V1 | No |
| JDBC V1 | The JDBC connector fetches documents from a relational database via SQL queries. Under the hood, this connector implements the Solr DataImportHandler (DIH) plugin. | Any JDBC compliant Database | V1 | No |
| JDBC V2 connector | The JDBC connector fetches documents from a relational database via SQL queries. Under the hood, this connector implements the Solr DataImportHandler (DIH) plugin. | Any JDBC V2 compliant Database | V2 | No |
| MongoDB | Retrieve data from a MongoDB instance. | MongoDB 2.6, 3.0, 3.2, 3.4, 3.6, 4.0 | V1 | No |
| Filesystem connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Box.com V1 | The Box connector retrieves data from a Box.com cloud-based data repository. To fetch content from multiple Box users, you must configure a Box.com datasource. For limited testing using a single user account, you can configure Box.com tokens. | N/A | V1 | Yes |
| Box.com V2 | The Box connector retrieves data from a Box.com cloud-based data repository. To fetch content from multiple Box users, you must configure a Box.com datasource. For limited testing using a single user account, you can configure Box.com tokens. | N/A | V2 | Yes |
| File Upload | The File Upload connector provides a convenient way to quickly ingest data from your local filesystem. | N/A | V1 | No |
| File Upload V2 | The File Upload V2 connector provides a convenient way to quickly ingest data from your local filesystem. | N/A | V2 | No |
| FTP | Retrieve documents using the File Transfer Protocol (FTP). | N/A | V1 | No |
| Google Cloud | The Fusion Google Cloud Storage (GCS) V2 connector enables indexing datasets from GCS buckets into Fusion 5. The connector leverages the Google Cloud API for authentication and fetching content and metadata. | All | V2 | Yes |
| Google Drive V1 | The Google Drive connector is used to index the documents in a Google Drive account. | Google V3 API | V1 | Yes |
| HDFS | Hadoop Distributed File System (HDFS). It traverses the Hadoop file system as it would a regular Unix filesystem. | 2.7.1 | V1 | No |
| Local Filesystem V2 | This connector traverses a network file system (NFS), where a shared drive is mounted to the same location on all hosts in the cluster that are running this connector. | All | V2 | No |
| Local Filesystem V1 | This connector traverses a network file system (NFS), where a shared drive is mounted to the same location on all hosts in the cluster that are running this connector. | All | V1 | No |
| OneDrive | OneDrive is a file hosting service that is part of the Microsoft Office Online services. The Fusion OneDrive connector crawls a OneDrive for Business instance and retrieves data from it for indexing within Fusion. | All | V2 | Yes |
| AWS S3 V1 | The AWS S3 V1 Connector can access AWS S3 buckets in native format. | All | V1 | No |
| AWS S3 V2 | The AWS S3 V2 connector crawls items in a single bucket. You must specify the bucket name and AWS region in which that bucket is located. You may crawl specific items in a bucket. If no items are specified, the entire bucket will be crawled. | All | V2 | No |
| SolrXML | The SolrXML connector indexes XML files formatted according to Solr’s XML structure. It is not a generic XML file crawler; it can only index SolrXML-formatted documents. | All | V1 | No |
| Windows Share (deprecated) | The Windows Share connector can access content in a Windows Share or Server Message Block (SMB)/Common Internet File System (CIFS) filesystem. | SMB 1 protocol | V1 | Yes |
| Windows Share SMB2/3 V1 (classic) | The Windows Share connector can access content in a Windows Share or Server Message Block (SMB 2 and 3 protocols)/Common Internet File System (CIFS) filesystem. Available in Fusion 5.x.x releases. | SMB 2, 3 protocols | V1 | Yes |
| Windows Share SMB2/3 V2 | The Windows Share connector can access content in a Windows Share or Server Message Block (SMB 2 and 3 protocols)/Common Internet File System (CIFS) filesystem. | SMB 2, 3 protocols | V2 | Yes |
| Hadoop cluster connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Apache Hadoop 2 | The Apache Hadoop 2 Connector is a MapReduce-enabled crawler that is compatible with Apache Hadoop v2.x. | 2.x | V1 | No |
| Hortonworks | The Hortonworks Connector is a MapReduce-enabled crawler that is compatible with Hortonworks Data Platform v2.x. | 2.x | V1 | No |
| MapR | The MapR Connector is a MapReduce-enabled crawler that is compatible with MapR 4.x and 5.x. | 4.x, 5.x | V1 | No |
| Cloudera | The Cloudera Connector is a MapReduce-enabled crawler that is compatible with Cloudera CDH v4.x and v5.x. | 4.x, 5.x | V1 | No |
| Push content connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Solr Push Endpoint | The Solr Push Endpoint accepts documents and pushes them to Solr using the Fusion index pipelines. You might use this, for example, if you are indexing Solr XML documents from a content management system that natively integrates with Solr, for example using SolrJ. | All | V1 | No |
| Repository connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Active Directory Connector for ACLs V2 | The Active Directory Connector for ACLs V2 plugin: ● Is a special connector that supports other data sources with collecting Access Control List (ACL) data ● Indexes ACL information into a configured “sidecar” Solr collection, for use by other connectors ● Connects to LDAP, AD, and Azure AD instances to add objects directly to a special collection for use in security trimming queries ● Extends the Azure AD model from V1 to return a delta link at the end of a crawl, allowing incremental delta searches for groups and users | N/A | V2 | Yes |
| Active Directory Connector for ACLs V1 | The Active Directory Connector for ACLs indexes Access Control List (ACL) information into a configured “sidecar” Solr collection, so that it can be used by other connectors. | N/A | V1 | Yes |
| AEM V2 | This connector retrieves data from an Adobe Experience Manager (AEM) repository. The AEM V2 connector is compatible with AEM version 6.5. | AEM 6.5 | V2 | Yes |
| Alfresco | The Alfresco Connector is a crawler for the Alfresco server, which adheres to the Content Management Interoperability Services (CMIS) standard. | CMIS 1.1 compliant versions | V1 | Yes |
| Azure | The Azure connector is used to crawl an Azure instance. Its connector type is “lucid.azure” and its plugin type is “azure”. | Blob and Table storage | V1 | No |
| Confluence | Retrieve data from the Atlassian Confluence Wiki CMS. You can configure this datasource to crawl pages, spaces, blog posts, comments, and attachments. | Confluence Server 5.5 and later; Confluence Cloud | V1 | Yes |
| Drupal | The Drupal connector requires Drupal’s Services 7.x3.11 Module REST API. Refer to this page to install the necessary packages: www.drupal.org/node/783236 | Drupal 7.x | V1 | No |
| GitHub | The GitHub connector retrieves data from GitHub repositories using the GitHub REST API. | N/A | V1 | No |
| JIRA | The JIRA connector retrieves data from an instance of Atlassian’s JIRA issue tracking system. | 6.x, 7.x | V1 | Yes |
| LDAP ACLs V2 | The Active Directory Connector for ACLs indexes Access Control List (ACL) information so that it can be used by other connectors. | N/A | V2 | Yes (with SharePoint Optimized V2) |
| Salesforce | Use the Salesforce REST API to extract data from a Salesforce repository via a Salesforce Connected App. | N/A | V1 | Yes |
| ServiceNow | The ServiceNow Datasource retrieves data from the ServiceNow repository. | N/A | V1 | Yes |
| SharePoint Optimized V2 | The SharePoint Optimized V2 connector indexes content and metadata from SharePoint Online and on-premises environments, making it searchable in Fusion. It supports fine-grained scoping and filtering, so teams can include only the content that matters. Security trimming ensures that users see only content they are authorized to access, which protects sensitive data and enforces compliance. This enables a secure, unified search experience across SharePoint and other enterprise systems. | 2013, 2016, 2019, Online | V2 | Yes |
| SharePoint V2 | The SharePoint connector retrieves content and metadata from an on-premises SharePoint repository. | 2013, 2016, 2019, Online | V2 | Yes |
| SharePoint V1 Optimized | The SharePoint connector retrieves content and metadata from an on-premises SharePoint repository. | 2010, 2013, 2016, Online | V1 Optimized | Yes |
| SharePoint Online V1 Optimized | The SharePoint Online V1 Optimized connector retrieves data from cloud-based SharePoint repositories. Authentication requires a Sharepoint user who has permissions to access Sharepoint via the SOAP API. This user must be registered with the Sharepoint Online authentication server; it is not necessarily the same as the user in Active Directory or LDAP. | N/A | V1 Optimized | Yes |
| SharePoint V1 (deprecated as of 5.2) | The SharePoint connector retrieves content and metadata from an on-premises SharePoint repository. | 2010, 2013, 2016, Online | V1 | Yes |
| SharePoint Online V1 (deprecated as of 5.2) | The SharePoint Online V1 connector retrieves data from cloud-based SharePoint repositories. Authentication requires a Sharepoint user who has permissions to access Sharepoint via the SOAP API. This user must be registered with the Sharepoint Online authentication server; it is not necessarily the same as the user in Active Directory or LDAP. | N/A | V1 | Yes |
| Sitecore | This connector provides full crawl and incremental crawl support for Sitecore versions 8.x and 9.x. It indexes document content and all metadata. | 8.x, 9.x | V2 | No |
| Slack V2 | The Slack V2 connector allows you to index Slack channels and messages. | N/A | V2 | Yes |
| Solr Index | A Solr connector pulls documents from an external standalone Solr instance or SolrCloud cluster using Solr’s javabin response type and streaming response parser. | All | V1 | No |
| Subversion (deprecated) | This connector requires a Subversion client that is compatible with JavaHL. | 1.8 and below | V1 | No |
| Zendesk | The Zendesk connector uses the Zendesk REST API to retrieve tickets and their associated comments and attachments from a Zendesk repository. | N/A | V1 | Yes |
| Script connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Javascript | The Javascript connector allows users to write ad-hoc document retrieval routines to fetch content from filesystems and websites. | All | V1 | No |
| Social media connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Jive | Retrieve content from a Jive instance. | REST API +V3.12 | V1 | Yes |
| Kaltura | The Kaltura V2 connector uses the Kaltura Java API client to retrieve data stored in Kaltura. | All | V2 | Yes |
| Twitter Search | The Twitter Search connector uses Twitter’s search API to query Twitter for tweets that match specific parameters. It allows querying for any keyword, location or other query terms. | All | V1 | No |
| Twitter Stream | The Twitter Stream connector uses Twitter’s streaming API to continually index Twitter. The datasource can be configured to limit tweets or it can be run indefinitely, until Twitter cuts off your access or you stop the datasource. This connector only retrieves tweets created after the datasource has been started. | All | V1 | No |
| Web connectors | ||||
| Name | Description | Source Compatibility | Platform Version | Security Trimming |
| Web V1 | The Web V1 connector retrieves data from a Web site using HTTP and starting from a specified URL. | All Fusion 4.x and 5.x releases | V1 | No |
| Web V2 | The Web V2 connector retrieves data from a Web site using HTTP and starting from a specified URL. | Fusion release 5.6.1 and later | V2 | No |