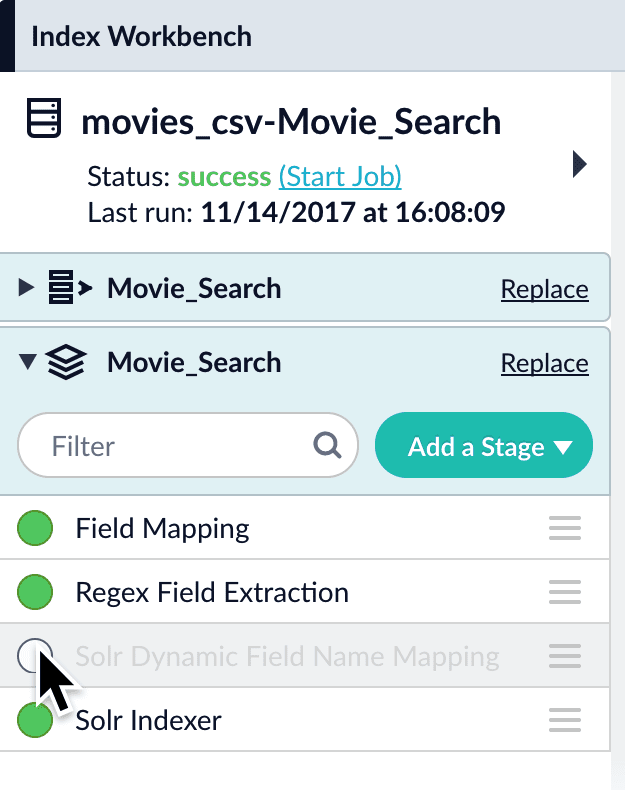
The Index Workbench is a powerful tool that combines key aspects of the data indexing configuration process into one user-friendly panel. It guides the user through the workflow for configuring datasources, parsers and index pipelines, and then running a datasource job to index your data.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
Datasources
A datasource is a complete data ingest configuration that consists of the following components:- Connector. Connectors are out-of-the-box components for pulling your data into Fusion. Lucidworks provides a wide variety of connectors, each specialized for a particular data type. For a list of connectors, see Fusion Connectors.
- Parser. Parsers provide fine-grained configuration for inbound data.
-
Index pipeline. Index pipelines transform incoming data for indexing by Fusion.
- For Fusion 5.x, see Index Pipelines for more information.
- For Fusion 4.x, see Index Pipelines for more information.
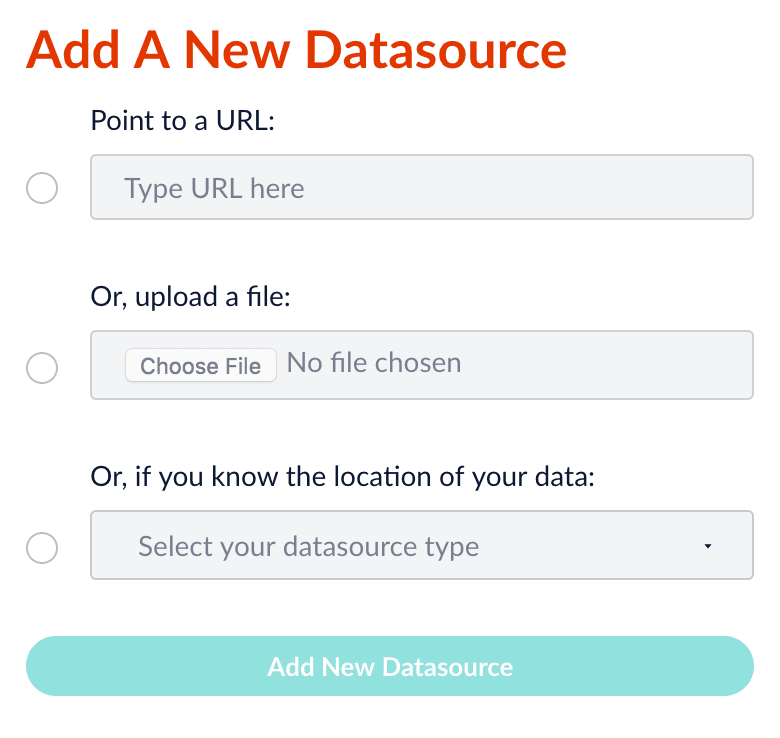
- By URL
- By local file upload
- By selecting an installed connector to configure
See Connectors Configuration Reference for a complete list of available connectors. Some are installed by default, and others require separate download and installation.
Parsers
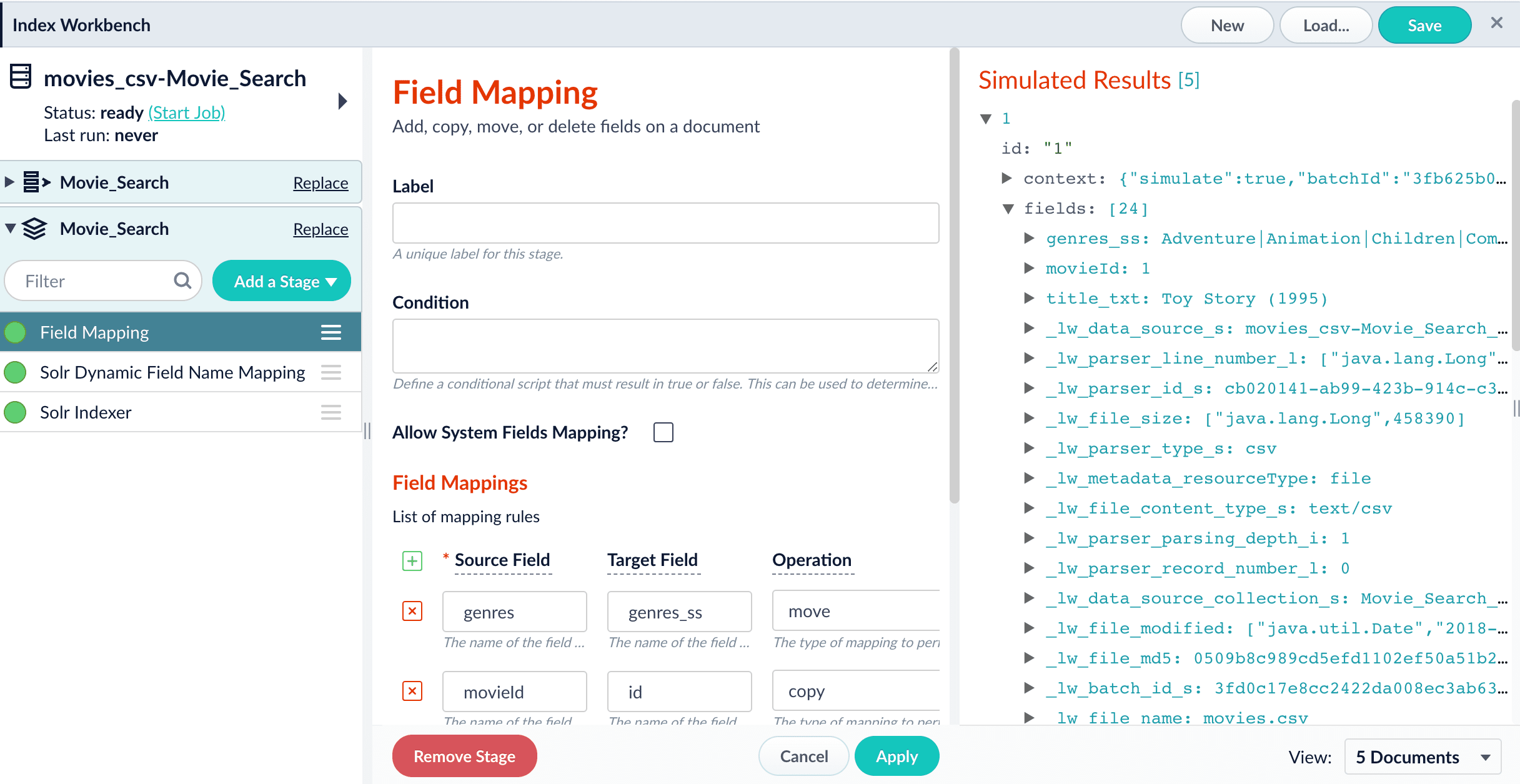
Parsers are a configurable component of the indexing workflow, for flexibility and specificity when parsing inbound data.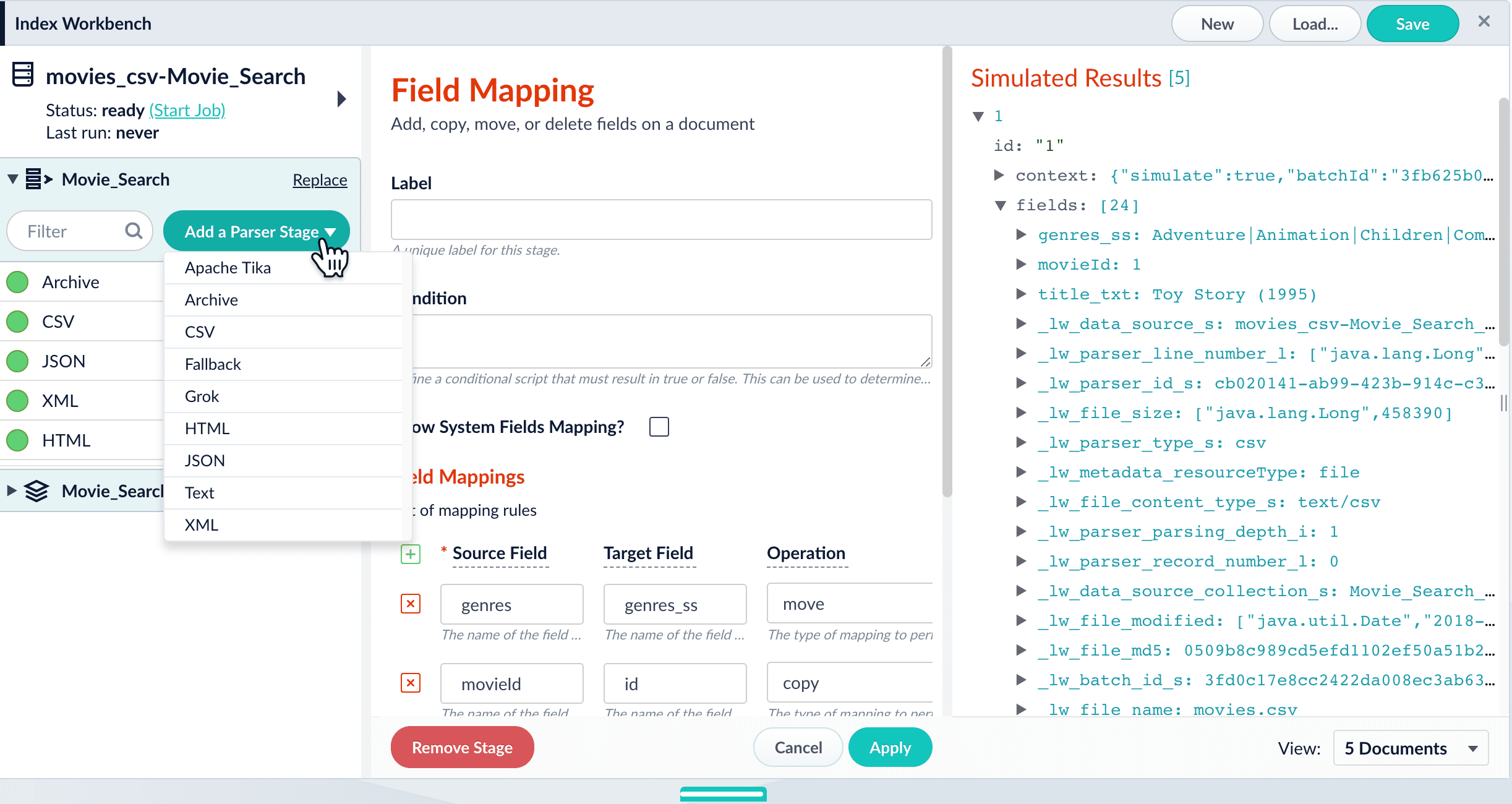
Index pipelines
An Index Pipeline transforms incoming data into a document suitable for indexing by Solr via a series of modularized operations called stages. Fusion provides a variety of specialized index stages to index data effectively. Stages can be selected, configured, and enabled or disabled in the Index Pipeline section of the Index Workbench. Once you finish configuring a datasource using the Index Workbench, you can move on to setting up queries using the Query Workbench, which provides a similar workflow for configuring and previewing search results.Adding a pipeline stage
Click Add a Stage to add index pipeline stages that can perform data filtering, transformations, and more.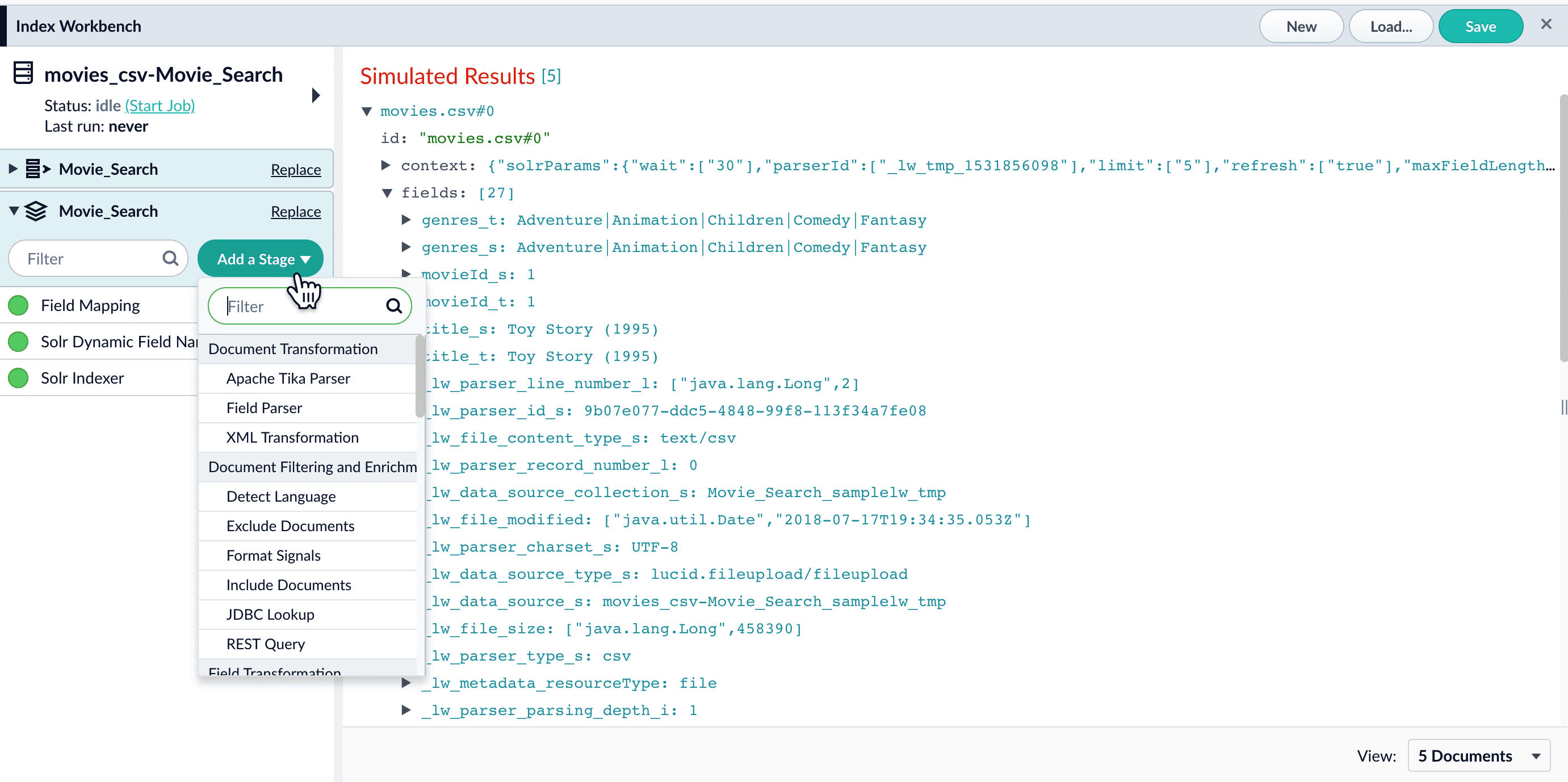
Re-ordering pipeline stages
The order of the pipeline stages matters, because the output from one stage becomes the input to the next stage. For example, the Solr Indexer stage must always come last in the sequence, so that data is indexed only after it has been processed by all other stages. Putting this stage first in the sequence means that subsequent stages have no effect on the indexed data. Click and drag any stage in the pipeline to move it up or down in the sequence of stages. The preview panel automatically updates the results to reflect the output of the new sequence.Enabling and disabling pipeline stages
By default, every stage in an index pipeline is enabled. While working with a pipeline, it can be helpful to disable stages without removing them completely. This allows you to preserve a stage’s configuration while observing how the search results change in its absence. You can re-enable the stage at any time. When you save a query pipeline, the enabled/disabled state of each stage is also saved.