Parsers provide fine-grained configuration for inbound data. You configure parsers with stages, much like index pipelines and query pipelines. Parsers can include conditional parsing and nested parsing. You can configure them through the Fusion UI or the Parsers API. Connectors receive the inbound data, convert it into a byte stream, and send the byte stream to a parser’s configured parsing stages. The parser selects a parsing stage to handle the stream, which parses the data and produces documents that are sent to the index pipeline. Each parsing stage evaluates whether the inbound stream matches the stage’s default media types or filename extensions. The first stage that finds a match processes the data and can output one or both of the following:Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
- Zero or more pipeline documents for consumption by the index pipeline
- Zero or more new input streams for re-parsing
This recursive approach is useful for containers (for example,zipandtarfiles). The output of the container parsing can be another container or a stream of uncompressed content that requires its own parsing.
| Field | Description |
|---|---|
| Document ID Source Field | Field in the source file that contains the document ID |
| Maximum Parser Recursion Depth | Maximum number of times the parser may recurse over the file, before proceeding to the next parser. This is useful for files with hierarchical structures (for example, zip and tar files). |
| Enable automatic media type detection | Whether to automatically detect the media type of the source files. If disabled, the parser uses the media type application/octet-stream. |
Built-in parser stages
These parser stages are available for configuration:- Forked Apache Tika parser stage
- Apache Tika parser stage
- Archive parser stage
- CSV parser stage
- Fallback parser stage
- Grok parser stage
- HTML parser stage
- JSON parser stage
- Solr Update parser stage
- Text parser stage
- XML parser stage
Configure parsers
When you configure a datasource, you can use the Index Workbench or the Parsers API to create a parser. A parser consists of an ordered list of parser stages, some global parser parameters, and the stage-specific parameters. You can re-order the stages list by dragging them up or down in the Index Workbench. Any parser stage can be added to the same parser multiple times if different configuration options are needed for different stages. Datasources with fixed-structure data will also be parsed by Fusion, but with default settings that do not need to be customized. There is no limit to the number of stages that can be included in a parser. The priority-order of the stages is completely flexible. In a default parser configuration, a fallback parser is provided at the end of the parsing stage list to handle streams no other stage matches. If present, this stage is selected and attempts to parse anything that has not yet been matched.Configure a parser in the Fusion UI
To configure parser stages using the Fusion UI:- In the Fusion workspace, navigate to the Index Workbench.
- At the upper right of the Index Workbench panel, click Load.
- Under Load, click the name of the index pipeline.
-
Click the parser to open its configuration:
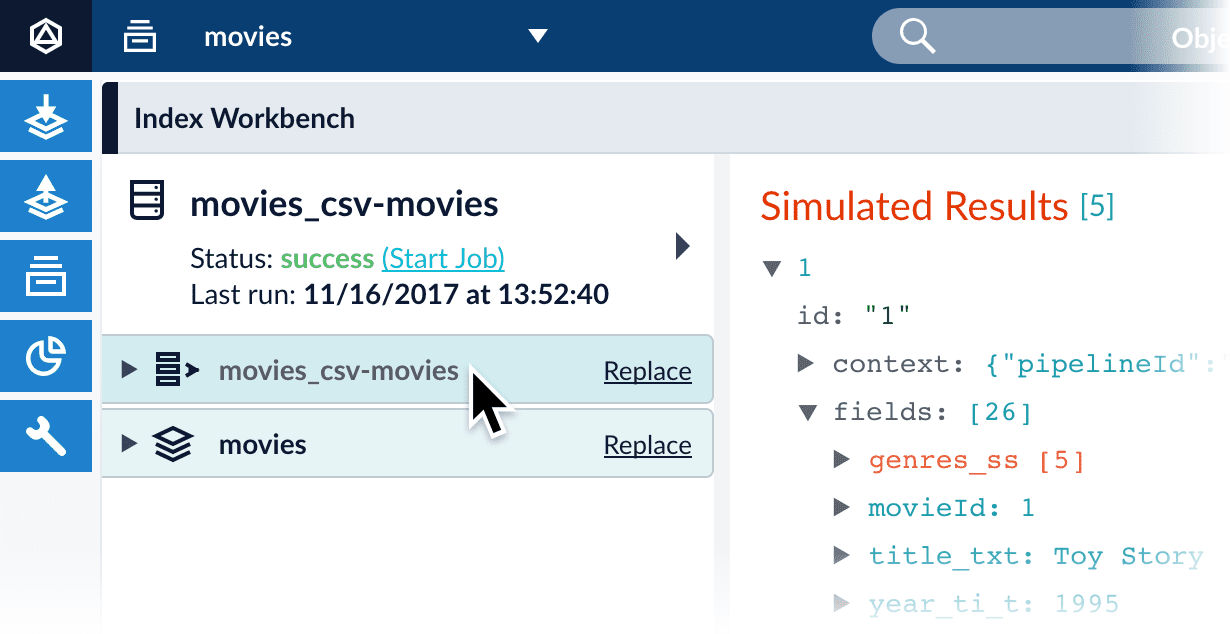
-
Click a specific stage to open its configuration panel:
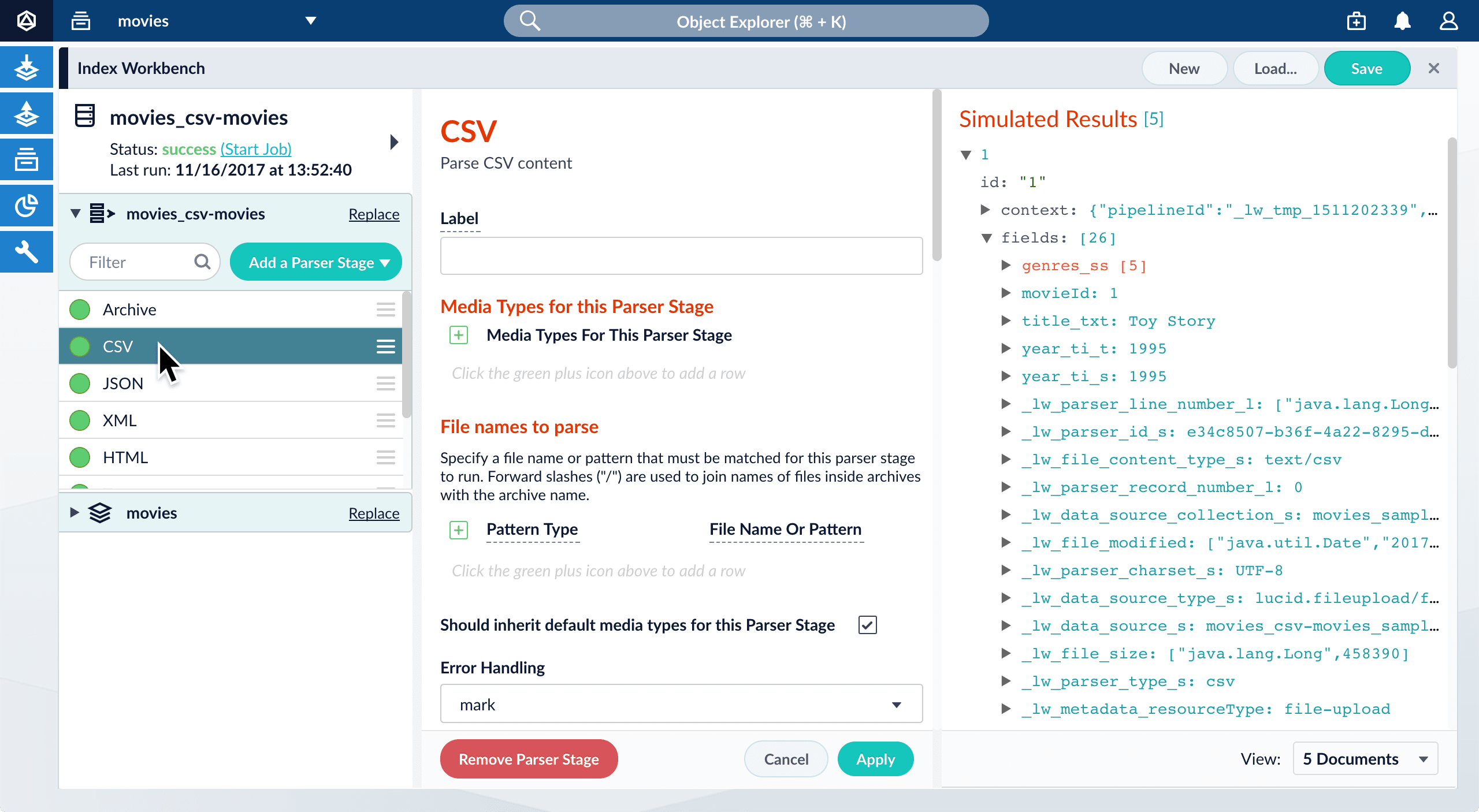
Configure a parser in the REST API
The Parsers API provides a programmatic interface for viewing, creating, and modifying parsers, as well as sending documents directly to a parser.- To get all currently-defined parsers:
http://localhost:8764/api/parsers/ - To get the parser schema:
http://localhost:8764/api/parsers/_schema
type.