| Component | Version |
|---|---|
| Solr | fusion-solr 5.8.0 (based on Solr 9.1.1) |
| ZooKeeper | 3.7.1 |
| Spark | 3.2.2 |
| Kubernetes | GKE, AKS, EKS 1.24 Rancher (RKE) and OpenShift 4 compatible with Kubernetes 1.24 OpenStack and customized Kubernetes installs not supported. See Kubernetes support for end of support dates. |
| Ingress Controllers | Nginx, Ambassador (Envoy), GKE Ingress Controller Istio not supported. |
New Features
- Lucidworks Search only: Added a new feature called Dynamic Pricing which improves scalability for custom pricing. This feature lets B2B organizations with large product and pricing inventories sort, facet, boost, and filter on custom prices and entitlements.
Dynamic Pricing
The course for Dynamic Pricing focuses on how Dynamic Pricing maximizes custom pricing strategies.
- Lucidworks Search only: Fusion now supports Reverse Search, which lets you set up monitoring queries that automatically include new documents. Instead of running a query multiple times to see if new documents have been added, this feature matches incoming documents to existing relevant queries, improving content awareness and productivity.
- Tika Asynchronous Parsing improves document crawl speeds and prevents memory and stability issues during connector processes. You can Use Tika Asynchronous Parsing to separate document crawling from document parsing, which is useful for large sets of complex documents. For more information, see Asynchronous Tika Parsing.
Use Tika Asynchronous Parsing
Use Tika Asynchronous Parsing
This document describes how to set up your application to use Tika asynchronous parsing.Unlike synchronous Tika parsing, which uses a parser stage, asynchronous Tika parsing is configured in the datasource and index pipeline. For more information, see Asynchronous Tika Parsing.
Field names change with asynchronous Tika parsing.In contrast to synchronous parsing, asynchronous Tika parsing prepends
parser_ to fields added to a document. System fields, which start with \_lw_, are not prepended with parser_. If you are migrating to asynchronous Tika parsing, and your search application configuration relies on specific field names, update your search application to use the new fields.Configure the connectors datasource
- Navigate to your datasource.
- Enable the Advanced view.
-
Enable the Async Parsing option.
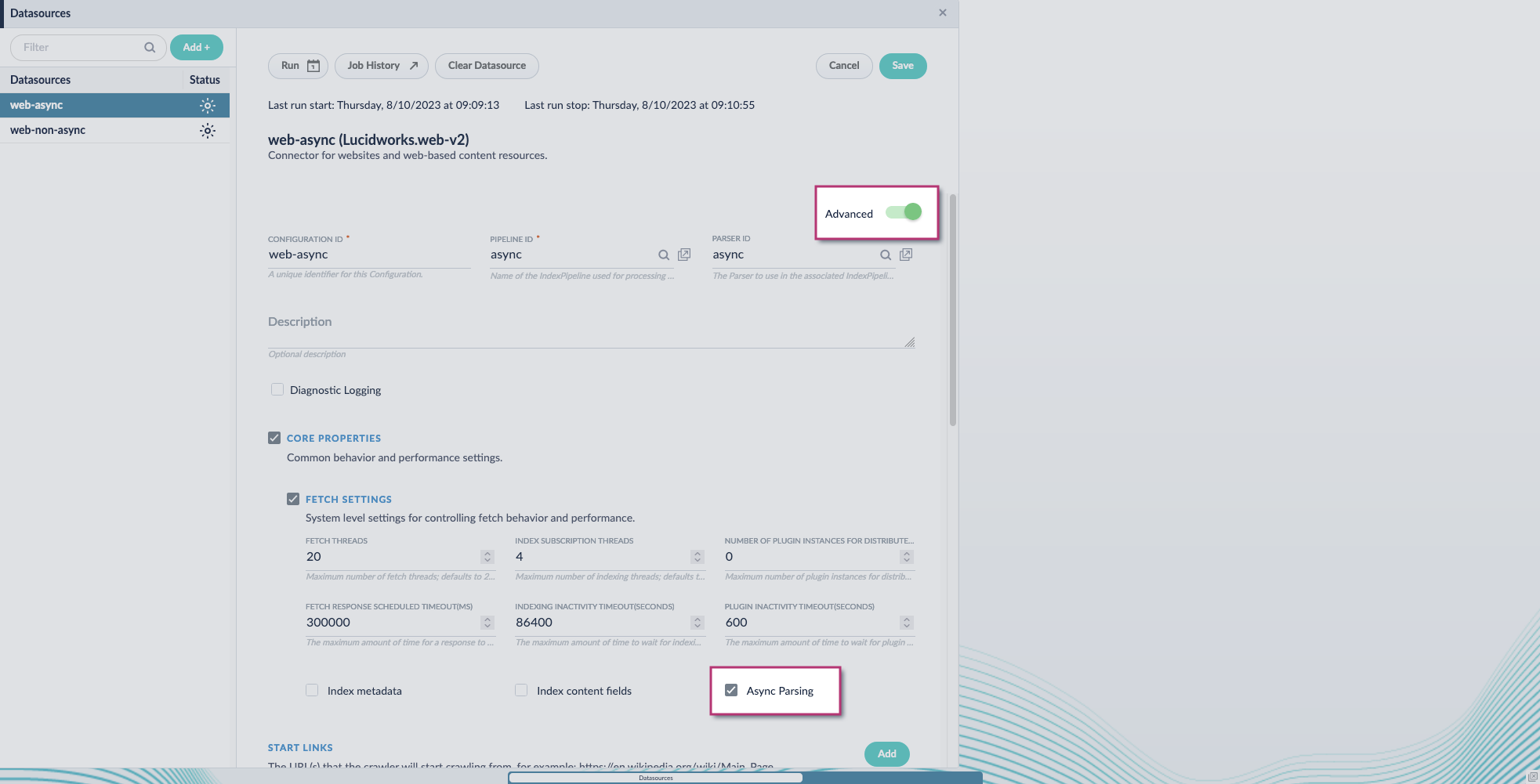 Fusion 5.9.11 and later uses your parser configuration when using asynchronous parsing.The asynchronous parsing service performs Tika parsing using Apache Tika Server. In Fusion 5.8 through 5.9.10, other parsers, such as HTML and JSON, are not supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is ignored. In Fusion 5.9.11 and later, other parsers, such as HTML and JSON, are supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is used.
Fusion 5.9.11 and later uses your parser configuration when using asynchronous parsing.The asynchronous parsing service performs Tika parsing using Apache Tika Server. In Fusion 5.8 through 5.9.10, other parsers, such as HTML and JSON, are not supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is ignored. In Fusion 5.9.11 and later, other parsers, such as HTML and JSON, are supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is used. - Save the datasource configuration.
Configure the parser stage
You must do this step in Fusion 5.9.11 and later.
- Navigate to Parsers.
- Select the parser, or create a new parser.
- From the Add a parser stage menu, select Apache Tika Container Parser.
- (Optional) Enter a label for this stage. This label changes the names from Apache Tika Container Parser to the value you enter in this field.
- If the Apache Tika Container Parser stage is not already the first stage, drag and drop the stage to the top of the stage list so it is the first stage that runs.
Configure the index pipeline
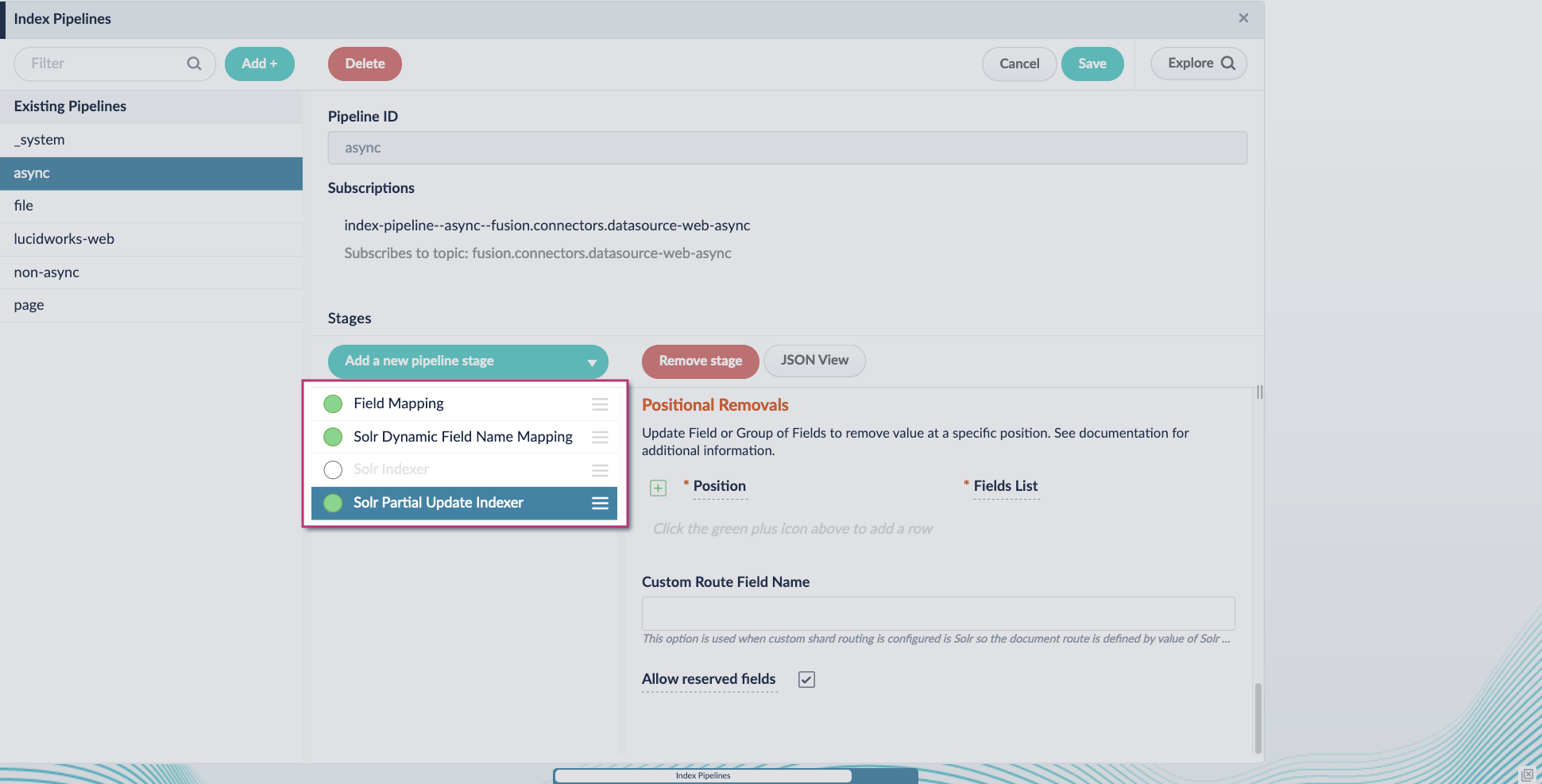
- Go to the Index Pipeline screen.
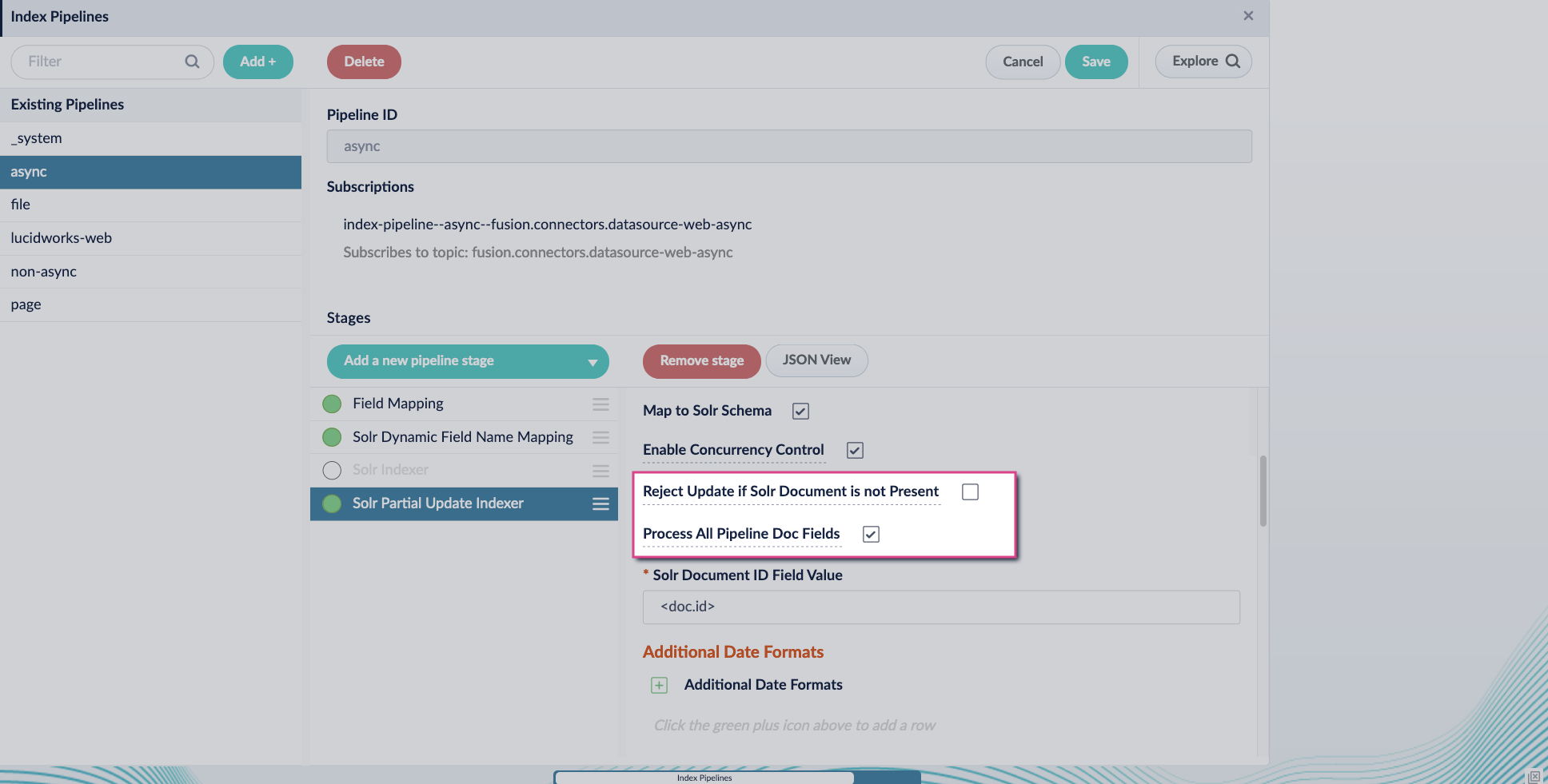
- Add the Solr Partial Update Indexer stage.
-
Turn off the Reject Update if Solr Document is not Present option and turn on the Process All Pipeline Doc Fields option:
-
Include an extra update field in the stage configuration using any update type and field name. In this example, an incremental field
docs_counter_iwith an increment value of1is added: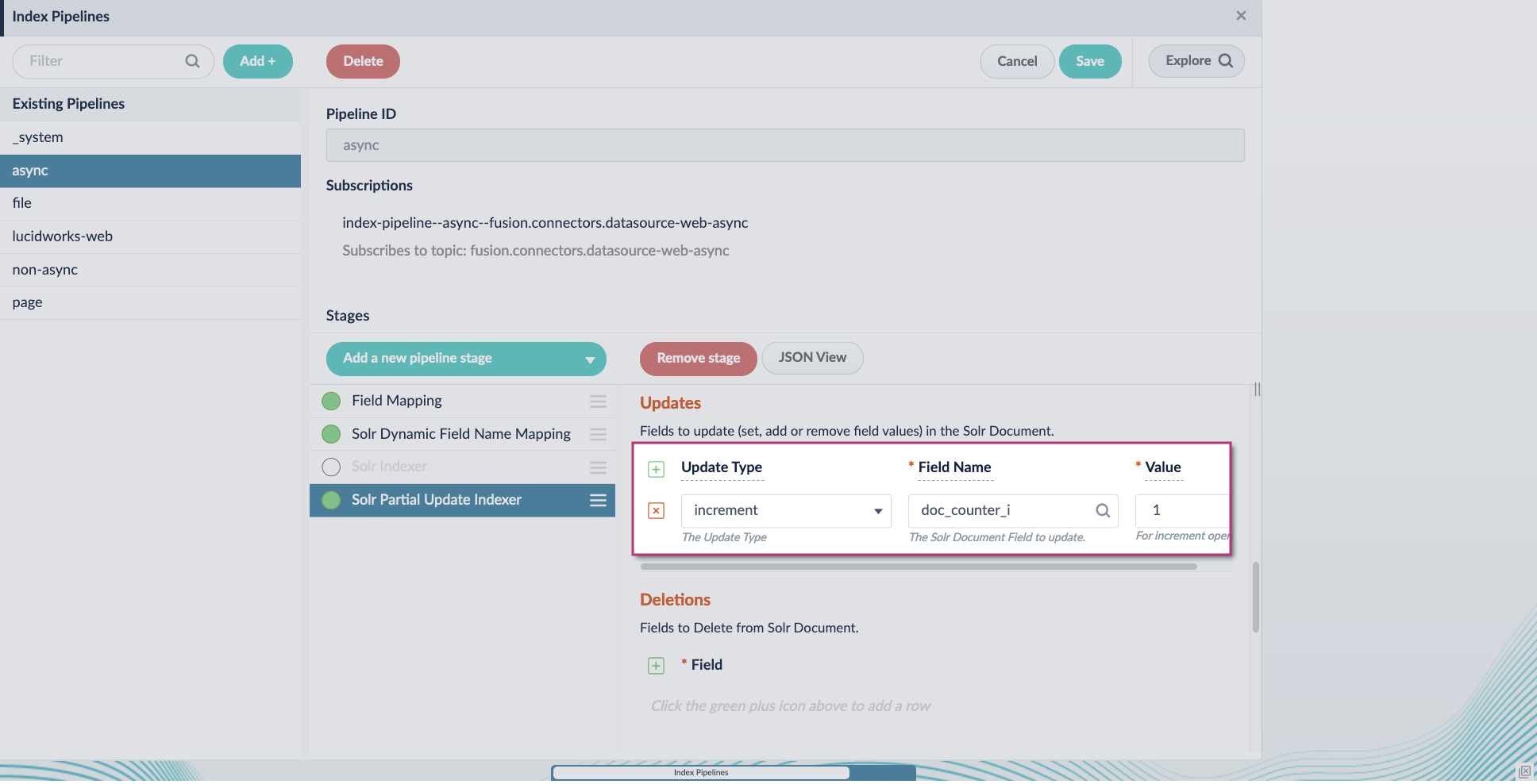
-
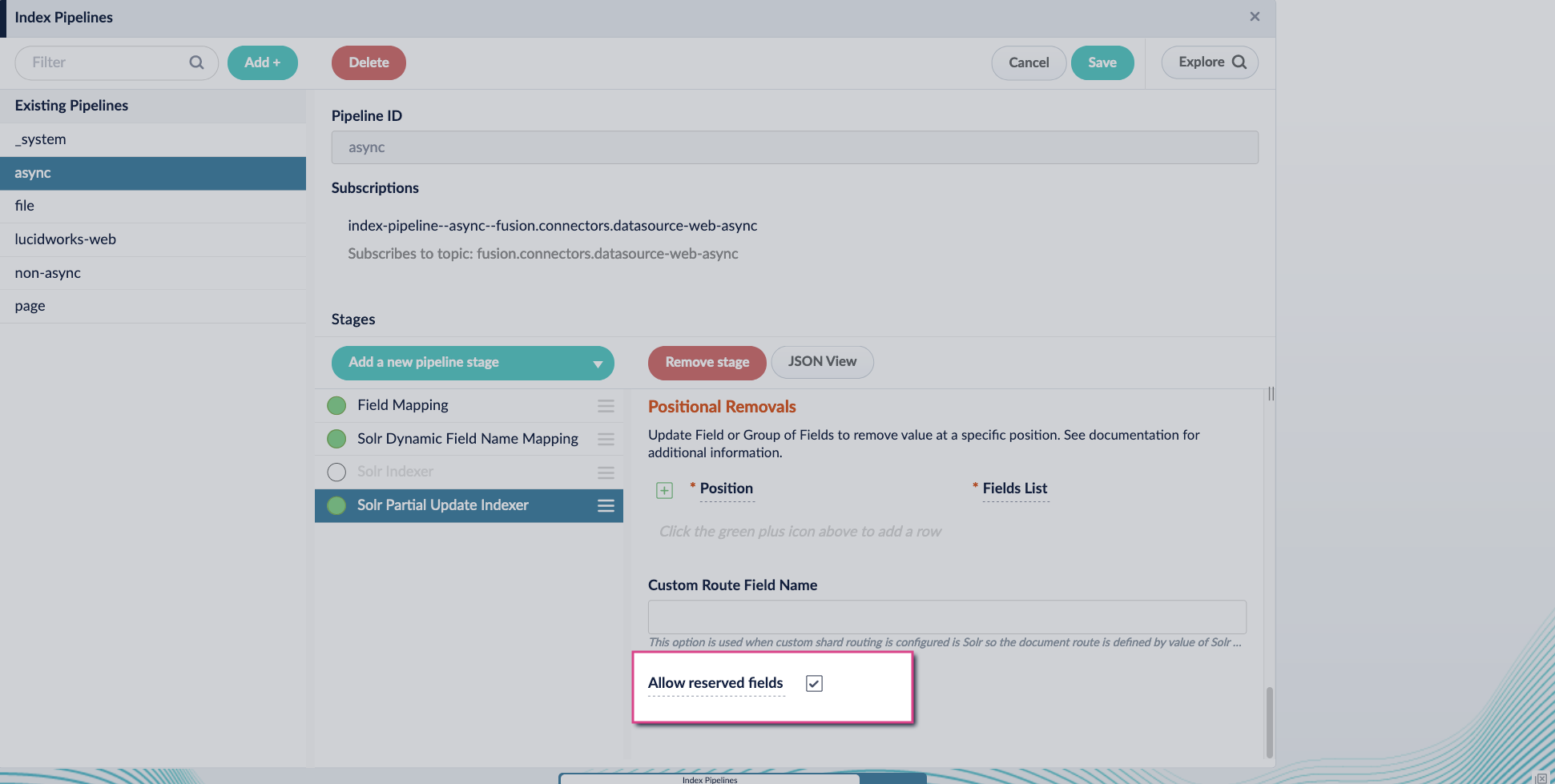
Enable the Allow reserved fields option:
- Click Save.
-
Turn off or remove the Solr Indexer stage, and move the Solr Partial Update Indexer stage to be the last stage in the pipeline.
The Apache Tika and Forked Tika stages are now deprecated. Follow the migration steps to begin using asynchronous parsing.
Improvements
- Improved recoverability for on-prem connectors in high network traffic environments.
- Fusion’s custom Solr image has been updated to fusion-solr 5.8.0. This upgrade includes the benefits and new features in Solr 9, while also including custom plugins to support Dynamic Pricing, Reverse Search, and autoscaling.
- Developed new authentication methods for the MongoDB connector.
Bug Fixes
Fusion
- Fixed a bug where the indexing service failed to load some classes from some JDBC drivers.
- Updated the Helm charts used when deploying Prometheus, Grafana, Loki, and Promtail for monitoring.
- Fixed an error with permissions required for the Upload Model Parameters To Cloud job.
- Graph Security Trimming stage now works when collections have multiple shards and replicas.
- Fixed a bug where having the same document updated twice in the same job could cause the job to hang.
- Fixed an issue where the Solr API was unable to pass through raw requests using the proxy.
- Updated the query pipeline and indexing container base images to use Java 11 so they are more secure.
- Removed UI link to view logs dashboard as its target screen is no longer available.
- Fixed a UI bug where zone display fields could not be manually removed.
- Fusion panel text editors can now scroll as expected in Firefox.
Predictive Merchandiser
- Fixed a bug in Predictive Merchandiser where templates having a higher precedence using a specified trigger phrase and facet were not appearing when that phrase was searched with that facet selected.
Deprecations
- Field Parser Index Stage is no longer used by Fusion connectors. It is officially deprecated in this release and will be removed entirely in a later release.
-
Streaming documents to the
/indexand/reindexendpoints of the Index Pipelines APIis deprecated and will eventually stop working altogether in the continuing switch to asynchronous parsing. - Tika Server Parser is deprecated and will be replaced by Tika Asynchronous Parser.
- Apache Tika Parser stage is deprecated and will be removed in a later release.
- The Forked Apache Tika Parser stage is deprecated and will be removed completely in a later release.
Known issues
- New Kerberos security realms cannot be configured successfully in this version of Fusion.
- When using the JavaScript query stage to query Solr, you have to provide parameters including
rows. Previouslyrowsaccepted an integer, but now it must be entered as a string as in("rows", "1").