Create and Run a SQL Aggregation Job
Create and Run a SQL Aggregation Job
You can perform a SQL aggregation on a signals collection for a datasource (or on some other collection), through the Fusion UI or using the Fusion API.
Preliminaries
Before you can create and run a SQL aggregation job, you must create an app, create a collection (or use the default collection for the app), and add a datasource. Before you run a SQL aggregation job, you need signal data. Otherwise, there is nothing to aggregate.Use the Fusion UI
You can use the Fusion UI to perform a SQL aggregation.- In the Fusion application, navigate to Collections > Jobs.
- Click Add and select SQL Aggregation from the dropdown list.
- Specify an arbitrary Spark Job ID.
- For the Source Collection, select the collection that contains the data to aggregate.
-
Click the SQL field to enter aggregation statements. Click Close to close the dialog box.
Select the Advanced option in the top right corner to enter detailed parameters. See SQL Aggregation Jobs for more information.
- Enter applicable Signal Types.
- Enter the Data Format.
- Save the job.
- With the app open, navigate to Collections > Jobs.
-
In the list of jobs, click the job you want to run, and then click Run.
If you do not want to run the job manually, you can also schedule a job.
Use the Fusion API
You can use the Fusion API to perform a SQL aggregation. For example: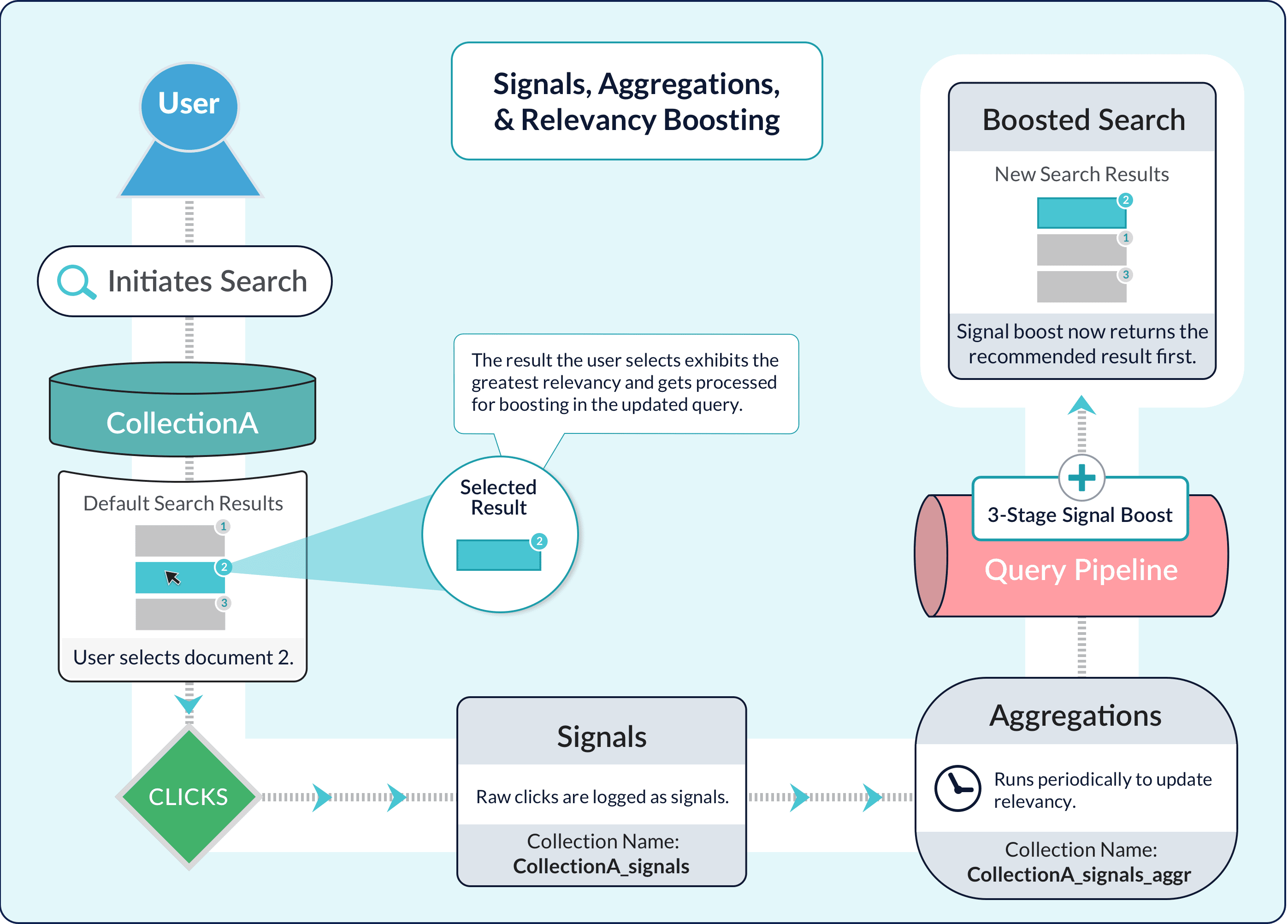
Rollup SQL
Most aggregation jobs run with the catch-up flag set totrue, which means that Fusion only computes aggregations for new signals that have arrived since the last time the job was run, and up to and including ref_time, which is usually the run time of the current job. Fusion must “roll up” the newly aggregated rows into any existing aggregated rows in the COLLECTION_NAME_aggr collection.
If you are using SQL to do aggregation but have not supplied a custom rollup SQL, Fusion generates a basic rollup SQL script automatically by consulting the schema of the aggregated documents. If your rollup logic is complex, you can provide a custom rollup SQL script.
Fusion’s basic rollup is a SUM of numeric types (long, integer, double, and float) and can support time_decay for the weight field. If you are not using time_decay in your weight calculations, then the weight is calculated using weight_d. If you do include time_decay with your weight calculations, then the weight is calculated as a combination of timestamp, halfLife, ref_time, and weight_d.
The basic rollup SQL can be grouped by DOC_ID, QUERY, USER_ID, and FILTERS. The last GROUP BY field in the main SQL is used so it will ultimately group any newly aggregated rows with existing rows.
This is an example of a rollup query:
Time-range filtering
When Fusion rolls up new data into an aggregation, time-range filtering lets you ensure that Fusion does not aggregate the same data over and over again. Fusion applies a time-range filter when loading rows from Solr, before executing the aggregation SQL statement. In other words, the SQL executes over rows that are already filtered by the appropriate time range for the aggregation job. Notice that the examples Perform the Default SQL Aggregation and Use Different Weights Based on Signal Types do not include a time-range filter. Fusion computes the time-range filter automatically as follows:- If the catch-up flag is set to
true, Fusion uses the last time the job was run andref_time(which you typically set to the current time). This is equivalent to the WHERE clauseWHERE time > last_run_time AND time <= ref_time. - If the catch-up flag is not set to
true, Fusion uses a filter withref_time(and no start time). This is equivalent to the WHERE clauseWHERE time <= ref_time.
[* TO NOW]- all past events[2000-11-01 TO 2020-12-01]– specify by exact date[* TO 2020-12-01]– from the first data point to the end of the day specified[2000 TO 2020]- from the start of a year to the end of another year
SQL functions
A Spark SQL aggregation query can use any of the functions provided by Spark SQL. Use these functions to perform complex aggregations or to enrich aggregation results.Weight aggregated values using a time-decay function
Fusion automatically uses a defaulttime_decay function to compute and apply appropriate weights to aggregation groups during aggregation. Larger weights are assigned to more recent events. This reduces the impact of less-recent signals. Intuitively, older signals (and the user behavior they represent) should count less than newer signals.
If the default time_decay function does not meet your needs, you can modify it. The time_decay function is implemented as a User Defined Aggregate Function (UDAF).
Full function signature
This is the UDAF signature of the defaulttime_decay function:
halfLife, ref_time, and weight_d:
halfLife = 30 days, ref_time = NOW, and weight_d = 0.1.
Users indexing custom signals with
weight_d specified should ensure that the “default” value matches the weight_d parameter used by time_decay.Matching legacy aggregation
To match the results of legacy aggregation, either use the abbreviated function signature or supply these values for the mentioned parameters:halfLife = 30 days, ref_time = NOW, and weight_d = 0.1.
Parameters
Parameters fortime_decay are:
| Parameter | Description |
|---|---|
count | Number of occurrences of the event. Typically, the increment is 1, though there is no reason it could not be some other number. In most cases, you pass count_i, which is the event count field used by Fusion signals, as shown in the SQL aggregation examples. |
timestamp | The date-and-time for the event. This time is the beginning of the interval used to calculate the time-based decay factor. |
halfLife | Half life for the exponential decay that Fusion calculates. It is some interval of time, for example, 30 days or 10 minutes. The interval prefix is optional. Fusion treats 30 days as equivalent to interval 30 days. |
ref_time | Reference time used to compute the age of an event for the time-decay computation. It is usually the time when the aggregation job runs (NOW). The reference time is not present in the data; Fusion determines the reference time at runtime. Fusion automatically attaches a ref_time column to every row before executing the SQL. |
weight_d | Initial weight for an event if not specified in the signal, prior to the decay calculation. This value is typically not present in the signal data. If some signals do contain weight_d values, this parameter should be set to match the “neutral” value there. You can use SQL to compute weight_d; see Use Different Weights Based on Signal Types for an example. |
Sample calculation of the age of a signal
This is an example of how Fusion calculates the age of a signal: Imagine a SQL aggregation job that runs atTuesday, July 11, 2017 1:00:00 AM (1499734800).
For a signal with the timestamp Tuesday, July 11, 2017 12:00:00 AM (1499731200), the age of the signal in relation to the reference time is 1 hour.
Learn more
Join Signals with Item Metadata
Join Signals with Item Metadata
Fusion’s basic aggregation jobs aggregate using the document ID. You can also aggregate at a more coarse-grained level using other fields available for documents (item metadata), such as manufacturer or brand for products. Aggregating with item metadata is useful for building personalization boosts into your search application.The following PUT request creates additional aggregation jobs that join signals with the primary After performing the PUT request shown above, you will have two additional aggregation jobs in Fusion.
products collection to compute an aggregated weight for a manufacturer field:COLLECTION_NAME_user_METADATA_preferences_aggregation
This job computes an aggregated weight for each user/item metadata combination, e.g. user/manufacturer, found in the signals collection. Fusion computes the weight for each group using an exponential time-decay on signal count (30 day half-life) and a weighted sum based on the signal type. Use thesignalTypeWeights parameter to set the correct signal types and weights for your dataset. Use the primaryCollectionMetadataField parameter to set the name of a field from the primary collection to join into the results, e.g. manufacturer. You can use the results of this job to boost queries based on user preferences regarding item-specific metadata such as manufacturer (e.g. Ford vs. BMW) or brand (e.g. Ralph Lauren vs. Abercrombie & Fitch).COLLECTION_NAME_query_METADATA_preferences_aggregation
This job computes an aggregated weight for each query/item metadata combination, e.g. query/manufacturer, found in the signals collection. Fusion computes the weight for each group using an exponential time-decay on signal count (30 day half-life) and a weighted sum based on the signal type. Use thesignalTypeWeights parameter to set the correct signal types and weights for your dataset. Use the primaryCollectionMetadataField parameter to set the name of a field from the primary collection to join into the results.