Managed Fusion 5.9.5
Released on August 27, 2024, this maintenance release includes the new Neural Hybrid Search capability, as well as upgrades to Solr, Kubernetes, Zookeeper, and some bug fixes.
To learn more, skip to the release notes.
Platform Support and Component Versions
Kubernetes platform support
Lucidworks has tested and validated support for the following Kubernetes platform and versions:
-
Google Kubernetes Engine (GKE): 1.28, 1.29, 1.30
For more information on Kubernetes version support, see the Kubernetes support policy.
Component versions
The following table details the versions of key components that may be critical to deployments and upgrades.
| Component | Version |
|---|---|
Solr |
fusion-solr 5.9.5 |
ZooKeeper |
3.9.1 |
Spark |
3.2.2 |
Ingress Controllers |
Nginx, Ambassador (Envoy), GKE Ingress Controller Istio not supported. |
More information about support dates can be found at Lucidworks Fusion Product Lifecycle.
New Features
Neural Hybrid Search
Managed Fusion 5.9.5 introduces Neural Hybrid Search, a capability that combines lexical and semantic vector search. This feature includes:
-
A new index pipeline to vectorize fields with Lucidworks AI. See Configure the LWAI Vectorize pipeline.
-
A new query pipeline to set up Neural Hybrid Search with Lucidworks AI. See Configure the LWAI Neural Hybrid Search pipeline.
-
Query and index stages for vectorizing text using Lucidworks AI. See LWAI Vectorize Query stage and LWAI Vectorize Field stage.
-
Query and index stages for vectorizing text with Seldon. See Seldon Vectorize Query stage and Seldon Vectorize Field stage.
-
A new query stage for hybrid search that works with Lucidworks AI or Seldon. See Hybrid Query stage.
-
A new service,
lwai-gateway, provides a secure, authenticated connection between Managed Fusion and your Lucidworks AI-hosted models. See Lucidworks AI Gateway for details. -
Solr config changes to support dense vector dynamic fields.
-
A custom Solr plugin containing a new
vectorSimilarityQParser that will not be available in Apache Solr until 9.7.
|
Lucidworks offers free training to help you get started. The Course for Neural Hybrid Search focuses on how neural hybrid search combines lexical and semantic search to improve the relevance and accuracy of results:
Visit the LucidAcademy to see the full training catalog. |
Configure use case for embedding
In the LWAI Vectorize Field stage, you can specify the use case for your embedding model.
To learn how to configure your embedding use case, see the following demonstration:
Fine tune lexical and semantic settings
The Hybrid Query stage is highly customizable. You can lower the Min Return Vector Similarity threshold for vector results to include more semantic results. For example, a lower threshold would return "From Dusk Till Dawn" when querying night against a movie dataset. A higher threshold prioritizes high scoring results and in this case only returns movie names with night in the title.
To learn how to configure the Hybrid Query stage, see the following demonstration:
Vector dimension size
There is no limitation on vector dimension sizes. If you’re setting up vector search and Neural Hybrid Search with an embedding model with large dimensions, simply configure your managed-schema to support the appropriate dimension. See Configure Neural Hybrid Search.
Improvements
-
Managed Fusion now supports Kubernetes 1.30 for GKE. Refer to Kubernetes documentation at Kubernetes v1.30 for more information.
-
Solr has been upgraded to 9.6.1.
-
Zookeeper has been upgraded to 3.9.1.
-
The default value for
kafka.logRetentionBytesis increased to 5 GB. This improvement helps prevent failed datasource jobs due to full disk space. Refer to Troubleshoot failed datasource jobs.
-
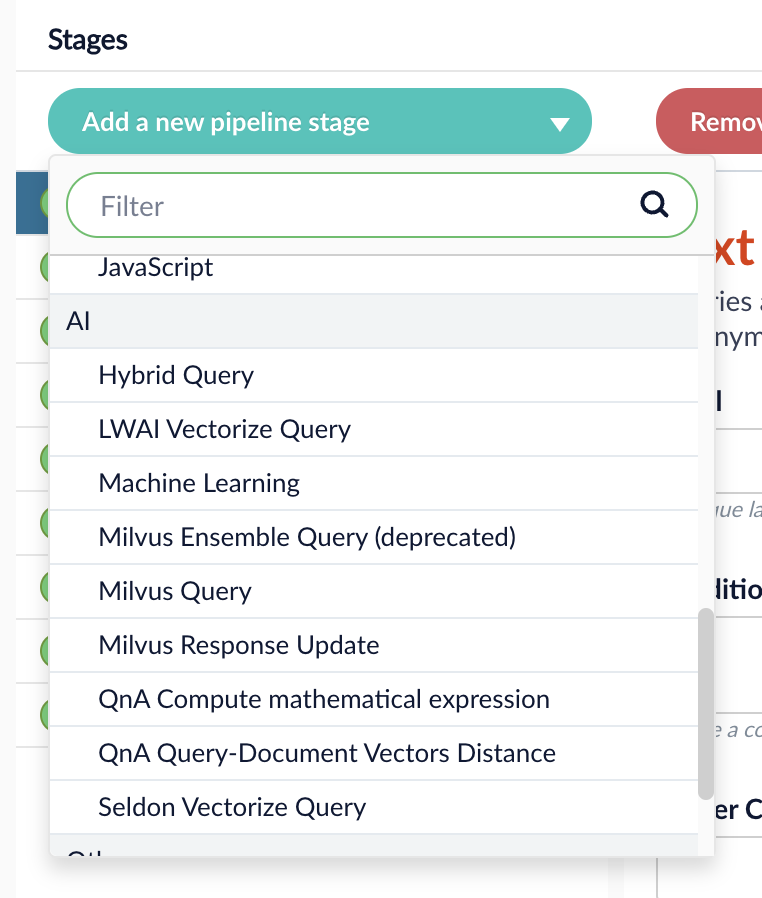
There is a new AI category in the Add a new pipeline stage dropdown for Query and Index Pipelines. This category contains the new stages for Neural Hybrid Search, as well as existing machine learning and AI stages.
-
The Managed Fusion migration script is updated to align with changes from the Solr upgrade. The migration script:
-
Removes the unused configuration,
<circuitBreaker>, fromsolrconfig.xml. Solr no longer supports this configuration. -
Removes the query response writer of class
solr.XSLTResponseWriter. -
Comments out processors of type
solr.StatelessScriptUpdateProcessorFactory. -
Removes
<bool name="preferLocalShards"/>element from request handler. -
Changes cache class attribute of elements
"filterCache","cache","documentCache","queryResultCache"tosolr.search.CaffeineCache. -
Removes
keepShortTermattribute from filter of classsolr.NGramFilterFactory.
-
-
Added the parameter
job-expiration-duration-secondsfor remote connectors that lets you configure the timeout value. Refer to Configure Remote V2 Connectors.
-
Added additional diagnostics between the
connectors-backendandfusion-indexingservices.
-
Added more detail to the messages that appear in the Managed Fusion UI when a connector job fails.
-
Added the
resetaction parameter to thesubscriptions/{id}/refresh?action=some-actionPOST API endpoint. Callingresetwill clear the subscription indexing topic from pending documents. See Indexing APIs.
Bug fixes
-
Fixed an issue that prevented successful configuration of new Kerberos security realms for authentication of external applications.
Deprecations
For full details on deprecations, see Deprecations and Removals.
With the release of Solr supported embeddings and Solr Semantic Vector Search, Lucidworks is deprecating Milvus. The following Milvus query stages are deprecated and will be removed in a future release:
-
Milvus Ensemble Query Stage
-
Milvus Query Stage
-
Milvus Response Update Query Stage
Use Seldon or Lucidworks AI vector query stages instead.
For more information, see Deprecations and Removals.