Neural Hybrid Search is a capability that combines lexical and semantic dense vector search to produce more accurate and relevant search results. Lexical search works by looking for literal matches of keywords. For example, a query forDocumentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
chips would result in potato chips and tortilla chips, but it could also result in chocolate chips.
Semantic vector search, however, imports meaning.
Semantic search could serve up results for potato chips, as well as other salty snacks like dried seaweed or cheddar crackers.
Both methods have their advantages, and often you’ll want one or the other depending on your use case or search query.
Neural Hybrid Search lets you use both: it combines the precision of lexical search with the nuance of semantic search.
To use semantic vector search in Lucidworks Search, you need to configure Neural Hybrid Search.
Then you can choose the balance between lexical and semantic vector search that works best for your use case.
For example, you can use a 70/30 split between semantic and lexical search, or a 50/50 split, or any other ratio that works for you.
This topic explains the concepts that you need to understand to configure and use Neural Hybrid Search in Lucidworks Search.
For instructions for enabling and configuring it in your pipeline, see Configure Neural Hybrid Search.
Configure Neural Hybrid Search
Configure Neural Hybrid Search
Neural Hybrid Search combines lexical-semantic search with semantic vector search.To use semantic vector search in Lucidworks Search, you need to configure Neural Hybrid Search.
Then you can choose the balance between lexical and semantic vector search that works best for your use case.Before you begin, see Neural Hybrid Search for conceptual information that can help you understand how to configure this feature.This query stage must be placed before the Solr Query stage.
This feature is currently only available to clients who have contracted with Lucidworks for features related to Neural Hybrid Search and Lucidworks AI.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
Configure vector search
This section explains how to configure vector search using Lucidworks AI, but you can also configure it using Ray or Seldon.Before you set up the Lucidworks AI index and query stages, make sure you have set up your Lucidworks AI Gateway integration.Configure the LWAI Vectorize Field index stage
To vectorize the index pipeline fields:- Sign in to Lucidworks Search and click Indexing > Index Pipelines.
- Click the pipeline you want to use.
- Click Add a new pipeline stage.
- In the AI section, click LWAI Vectorize Field.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
- In the Account Name field, select the Lucidworks AI API account name defined in Lucidworks AI Gateway. If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
- In the Model field, select the Lucidworks AI model to use for encoding. If you do not see your model name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks. For more information about models, see:
- In the Source field, enter the name of the string field where the value should be submitted to the model for encoding. If the field is blank or does not exist, this stage is not processed. Template expressions are supported.
- In the Destination field, enter the name of the field where the vector value from the model response is saved.
{Destination Field}is the vector field.{Destination Field}_bis the boolean value if the vector has been indexed.
- In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. - Optionally, you can use the Model Configuration section for any additional parameters you want to send to Lucidworks AI.
Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs while generating a prediction for a document.
- Click Save.
- Index data using the new pipeline. Verify the vector field is indexed by confirming the field is present in documents.
Configure the LWAI Vectorize query stage
To vectorize the query in the query pipeline:- Sign in to Lucidworks Search and click Querying > Query Pipelines.
- Select the pipeline you want to use.
- Click Add a new pipeline stage.
- Click LWAI Vectorize Query.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
-
Select Asynchronous Execution Config if you want to run this stage asynchronously. If this field is enabled, complete the following fields:
-
Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
signalsoraccess_control. -
Copy the Async ID value.
For detailed information, see Asynchronous query pipeline processing.
-
Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
- In the Account Name field, select the name of the Lucidworks AI account. If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
-
In the Model field, select the Lucidworks AI model to use for encoding.
If you do not see any model names and you are a non-admin Fusion user, verify with a Fusion administrator that your user account has these permissions:
PUT,POST,GET:/LWAI-ACCOUNT-NAME/**For more information about models, see: - In the Query Input field, enter the location from which the query is retrieved.
- In the Output context variable field, enter the name of the variable where the vector value from the response is saved.
-
In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. -
Optionally, you can use the Model Configuration section for any additional parameters you want to send to Lucidworks AI.
Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs during this stage.
- Click Save.
The Top K setting is 100 by default, but a value as high as 1000 provides better recall if you have fewer than one million indexed documents.
You can raise it even higher, but keep in mind that higher recall also causes higher latency.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
Modify Solr managed-schema (5.9.4 and earlier)
This step is required if you’re migrating a collection from a version of Lucidworks Search that does not support Neural Hybrid Search. If creating a new collection in Lucidworks Search 5.9.5, you can continue to Configure Hybrid Query stage.- Go to System > Solr Config and then click managed-schema to edit it.
-
Comment out
<copyField dest="\_text_" source="*"/>and add<copyField dest="text" source="*_t"/>below it. This will concatenate and index all*_t fields. -
Add the following code block to the managed-schema file:
This example uses 512 vector dimension. If your model uses a different dimension, modify the code block to match your model. For example,
_1024v. There is no limitation on supported vector dimensions.
Configure neural hybrid queries
In Lucidworks Search 5.9.10 and later, you use the Neural Hybrid Query stage to configure neural hybrid queries. In Lucidworks Search 5.9.9 and earlier, you use the Hybrid Query stage.Configure the Neural Hybrid Query stage (5.9.10 and later)
Configure the Neural Hybrid Query stage in Lucidworks Search 5.9.10 and later.- In the same query pipeline where you configured vector search, click Add a new pipeline stage, then select Neural Hybrid Query.
- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example, <request.params.q>. Template expressions are supported.
- In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Lexical Query Squash Factor field, enter a value that will be used to squash the lexical query score. The squash factor controls how much difference there is between the top-scoring documents and the rest. It helps ensure that documents with slightly lower scores still have a chance to show up near the top. For this value, Lucidworks recommends entering the inverse of the lexical maximum score across all queries for the given collection.
- In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
-
In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
- In the Min Return Vector Similarity field, enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- In the Min Traversal Vector Similarity field, enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query.
- When enabled, the Compute Vector Similarity for Lexical-Only Matches setting computes vector similarity scores for documents in lexical search results but not in the initial vector search results. Select the checkbox to enable this setting.
-
If you want to use pre-filtering:
-
Uncheck Block pre-filtering.
In the Javascript context (
ctx), thepreFilterKeyobject becomes available. -
Add a Javascript stage after the Neural Hybrid Query stage and use it to configure your pre-filter.
The
preFilterobject adds both the top-levelfqandpreFilterto the parameters for the vector query. You do not need to manually add the top levelfqin the javascript stage. See the example below:
-
Uncheck Block pre-filtering.
In the Javascript context (
- Click Save.
solrconfig.xml within the <config> tag:Configure the Hybrid Query stage (5.9.9 and earlier)
If you’re setting up Neural Hybrid Search in Lucidworks Search 5.9.9 and earlier, use the Hybrid Query stage. If you’re using Lucidworks Search 5.9.10 or later, use the Neural Hybrid Query stage.- In the same query pipeline where you configured vector search, click Add a new pipeline stage, then select Hybrid Query.
- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example, <request.params.q>. Template expressions are supported.
- In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Number of Lexical Results field, enter the number of lexical search results to include in re-ranking. For example, 1000. A value is 0 is ignored.
- In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
- In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
- Select the Use KNN Query checkbox to use the knn query parser and configure its options. This option cannot be selected if Use VecSim Query checkbox is selected. In addition, Use KNN Query is used if neither Use KNN Query or Use VecSim Query is selected.
- If the Use KNN Query checkbox is selected, enter a value in the Number of Vector Results field. For example, 1000.
- Select the Use VecSim Query checkbox to use the vecSim query parser and configure its options. This option cannot be selected if Use KNN Query checkbox is selected.
If the Use VecSim Query checkbox is selected, enter values in the following fields:
- Min Return Vector Similarity. Enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- Min Traversal Vector Similarity. Enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query. The value must be lower than, or equal to, the value in the Min Return Vector Similarity field.
- In the Minimum Vector Similarity Filter, enter the value for a minimum similarity threshold for filtering documents. This option applies to all documents, regardless of other score boosting such as rules or signals.
- Click Save.
Perform hybrid searches
After setting up the stages, you can perform hybrid searches via theknn query parser as you would with Solr. Specify the search vector and include it in the query. For example, change the q parameter to a knn query parser string.You can also preview the results in the Query Workbench.
Try a few different queries, and adjust the weights and parameters in the Hybrid Query stage to find the best balance between lexical and semantic vector search for your use case.
You can also disable and re-enable the Neural Hybrid Query stage to compare results with and without it.XDenseVectorField is not supported in Lucidworks Search 5.9.5. Instead, use DenseVectorField.Hybrid Scoring
The combination of lexical and semantic score is based on this function:scaled() means that the lexical scores are scaled close to 0 and 1 to be aligned with the bounded vector scores. This scaling of 1 is achieved by taking the largest lexical score and dividing all lexical scores by that high score.
Hybrid scoring tips:
- For highly tuned lexical and semantic search, the ratio will be closer to
0.3lexical weight and0.7semantic weight. - When using the Boost with Signals stage use
bq, notboost, and enable Scale Boosts to control how much the signals can impact the overall hybrid score. Lucidworks recommends keeping the scale boost values low, since SVS with scale scores with a max of1.
ImportantIn Fusion 5.9.5 - 5.9.9, all of the documents within the search collection must have an associated vector field. Otherwise, hybrid search fails on that vector field. This does not apply to Fusion 5.9.10 and later.
Solr Vector Query Types
Solr supports vector query types for semantic search that compare the similarity between encoded vector representations of content. These query types determine how results are retrieved and ranked based on proximity or similarity within the vector space. The two vector query types used at Lucidworks are K-Nearest Neighbors (KNN) and Vector Similarity Threshold (VecSim). The simplest difference between the two is how they return results:- KNN always returns a fixed number of results (topK), no matter the input. For example, if topK = 10, you’ll always get 10 results.
- VecSim returns a varying number of results based on similarity score (from 0 to 1). Only items above a set threshold are returned, so it’s possible to get zero results if nothing is similar enough.
K-Nearest Neighbors (KNN)
This is a query where a top value (k) is always returned, referred to as topK. Regardless of the input vector there will always be k vectors returned because within the vector space of your encoded vectors there is always something in proximity. Sharding with topK pulls k from each shard, so the final top k on a sharded collection will betopK*Shard_count.
Using prefiltering makes it possible for top level filters to filter out results and still allow for results that were collected by the KNN query. Otherwise, when prefiltering is blocked it is possible to have 0 results after the KNN query after the filters are applied, to mitigate that risk a larger topK can be used at the cost of performance.
KNN Solr Scoring
Solr supports three different similarity score metrics:euclidean, dot_product or cosine. In Lucidworks Search, the default is cosine. It’s important to note that Lucene bounds cosine to 0 to 1, and therefore differs from standard cosine similarity. For more information, refer to the Lucene documentation on scoring formula and the Solr documentation on Dense Vector Search.
In Lucidworks Search 5.9.5 - 5.9.9, Solr Collapse does not work well with Neural Hybrid Search because the computed hybrid score uses the vector score that is based on the
head node and not the most relevant vector document within the collapse. This does not apply to Lucidworks Search 5.9.10 and later.Vector Cosine Similarity Cutoff/Threshold (VecSim)
This is a query where a cosine float value between 0 and 1 is given to compare similarity scores of the vectors to the input vector, everything above and at the threshold is kept, everything else is left out. It is possible to get zero results when using a similarity threshold because there may not be any documents that are within the given threshold. This can be slower because the number of vectors is unknowable and it’s impossible to control the size of the vector result set. VecSim will speed up when prefiltering is enabled.Replica choice
Lucidworks recommends using PULL and TLOG replicas. These replica types copy the index of the leader replica, which results in the same HNSW graph on every replica. When querying, the HNSW approximation query will be consistent given a static index. In contrast, NRT replicas have their own index, so they will also have their own HNWS graph. HNSW is an Approximate Nearest Neighbor (ANN) algorithm, so it will not return exactly the same results for differently constructed graphs. This means that queries performed can and will return different results per HNWS graph (# of NRT replicas in a shard) which can lead to noticeable result shifts. When using NRT replicas, the shifts can be made less noticeable by increasing thetopK parameter. Variation will still occur, but should be lower in the documents. Another way to mitigate shifts is to use Neural Hybrid Search with a vector similarity cutoff.
For more information, refer to Solr Types of Replicas.
Considerations for multi-sharded collections
- The Lucidworks Search UI will show vectors floats encapsulated by
“ ”. This is expected behavior. - Sharding with
topKpullsKfrom each shardtopK*Shard_count.
More resources
Migrate Milvus to Solr vectors
Migrate Milvus to Solr vectors
Milvus is deprecated, but you may need to move Milvus data to Solr vectors.If in your Create Collections in Milvus job you have a vector dimension not included above, be sure to add it.If you are using Fusion 5.9.10 and later, add the following to the Solr schema because these query parsers are used with Solr-based vector search:
1. Add Solr vector schema
The first step to migration is to ensure the Solr schema for the collections has vector field definitions. If the collection was created in Fusion 5.9.5 or later, it will automatically have the vector schemas.Vector field definitions to add:2. Add query parsers used with Solr vector search
If you are using Fusion 5.9.5-5.9.9, add the following to the Solr schema because this query parser is used with Solr-based vector search:3. Add Ray/Seldon Vectorize stage
In the index pipeline, instead of using the Encode into Milvus stage you will need to use Ray/Seldon Vectorize Field (in Fusion 5.9.11 and earlier, this stage is called Seldon Vectorize Field).The Milvus stage field Encode into Milvus maps to the Vectorize stage field Source Field, Encoder Output Vector to Model Output Vector Field, and the other fields map to the fields of the same name.The last key field to know is Destination Field, which is the Solr vector field name. The field can be named anything as long as the suffix matches the dimension size of the vector your model returns in your Solr vector field definitions.For example, for a Milvus collection dimension size of384, the Destination Field should use the suffix _384v.At this point you can start indexing.On the query side, there is a Ray/Seldon Vectorize Field stage which will be set up mostly the same as on the index side. The only difference is there is no need to put in the vector field name, as it is done in the next step.4. Add hybrid stage
The final step before you are fully migrated over to Solr vectors is adding a variation of Fusion Neural Hybrid Query or Lucidworks Search Hybrid Query stage (known as Neural Hybrid Query stage in Lucidworks Search 5.9.10 and later).In this stage, all you need to do is put in the Vector Query Field you have defined in your index pipeline.Make sure the hybrid stage is placed before any boosting, Apply Rules, or Security Trimming stages.At this point you can query. After determining the query works you can tune your setup before removing your Milvus collections and pipelines.Configure Neural Hybrid Search
Configure Neural Hybrid Search
Neural Hybrid Search combines lexical-semantic search with semantic vector search.To use semantic vector search in Lucidworks Search, you need to configure Neural Hybrid Search.
Then you can choose the balance between lexical and semantic vector search that works best for your use case.Before you begin, see Neural Hybrid Search for conceptual information that can help you understand how to configure this feature.This query stage must be placed before the Solr Query stage.Construct a KNN exclusion query where topK is higher than the number of vectors in your collection
If the number of vectors in your collection exceeds 999,999 then increase the value to be at least equal to that value.If any are documents returned, there are orphans, and the
This feature is currently only available to clients who have contracted with Lucidworks for features related to Neural Hybrid Search and Lucidworks AI.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
Configure vector search
This section explains how to configure vector search using Lucidworks AI, but you can also configure it using Ray or Seldon.Before you set up the Lucidworks AI index and query stages, make sure you have set up your Lucidworks AI Gateway integration.Configure the LWAI Vectorize Field index stage
To vectorize the index pipeline fields:- Sign in to Lucidworks Search and click Indexing > Index Pipelines.
- Click the pipeline you want to use.
- Click Add a new pipeline stage.
- In the AI section, click LWAI Vectorize Field.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
- In the Account Name field, select the Lucidworks AI API account name defined in Lucidworks AI Gateway. If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
- In the Model field, select the Lucidworks AI model to use for encoding. If you do not see your model name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks. For more information about models, see:
- In the Source field, enter the name of the string field where the value should be submitted to the model for encoding. If the field is blank or does not exist, this stage is not processed. Template expressions are supported.
- In the Destination field, enter the name of the field where the vector value from the model response is saved.
{Destination Field}is the vector field.{Destination Field}_bis the boolean value if the vector has been indexed.
- In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. - Optionally, you can use the Model Configuration section for any additional parameters you want to send to Lucidworks AI.
Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs while generating a prediction for a document.
- Click Save.
- Index data using the new pipeline. Verify the vector field is indexed by confirming the field is present in documents.
Configure the LWAI Vectorize query stage
To vectorize the query in the query pipeline:- Sign in to Lucidworks Search and click Querying > Query Pipelines.
- Select the pipeline you want to use.
- Click Add a new pipeline stage.
- Click LWAI Vectorize Query.
- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
-
Select Asynchronous Execution Config if you want to run this stage asynchronously. If this field is enabled, complete the following fields:
-
Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
signalsoraccess_control. -
Copy the Async ID value.
For detailed information, see Asynchronous query pipeline processing.
-
Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
- In the Account Name field, select the name of the Lucidworks AI account. If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
-
In the Model field, select the Lucidworks AI model to use for encoding.
If you do not see any model names and you are a non-admin Fusion user, verify with a Fusion administrator that your user account has these permissions:
PUT,POST,GET:/LWAI-ACCOUNT-NAME/**For more information about models, see: - In the Query Input field, enter the location from which the query is retrieved.
- In the Output context variable field, enter the name of the variable where the vector value from the response is saved.
-
In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. -
Optionally, you can use the Model Configuration section for any additional parameters you want to send to Lucidworks AI.
Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs during this stage.
- Click Save.
The Top K setting is 100 by default, but a value as high as 1000 provides better recall if you have fewer than one million indexed documents.
You can raise it even higher, but keep in mind that higher recall also causes higher latency.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
Modify Solr managed-schema (5.9.4 and earlier)
This step is required if you’re migrating a collection from a version of Lucidworks Search that does not support Neural Hybrid Search. If creating a new collection in Lucidworks Search 5.9.5, you can continue to Configure Hybrid Query stage.- Go to System > Solr Config and then click managed-schema to edit it.
-
Comment out
<copyField dest="\_text_" source="*"/>and add<copyField dest="text" source="*_t"/>below it. This will concatenate and index all*_t fields. -
Add the following code block to the managed-schema file:
This example uses 512 vector dimension. If your model uses a different dimension, modify the code block to match your model. For example,
_1024v. There is no limitation on supported vector dimensions.
Configure neural hybrid queries
In Lucidworks Search 5.9.10 and later, you use the Neural Hybrid Query stage to configure neural hybrid queries. In Lucidworks Search 5.9.9 and earlier, you use the Hybrid Query stage.Configure the Neural Hybrid Query stage (5.9.10 and later)
Configure the Neural Hybrid Query stage in Lucidworks Search 5.9.10 and later.- In the same query pipeline where you configured vector search, click Add a new pipeline stage, then select Neural Hybrid Query.
- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example, <request.params.q>. Template expressions are supported.
- In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Lexical Query Squash Factor field, enter a value that will be used to squash the lexical query score. The squash factor controls how much difference there is between the top-scoring documents and the rest. It helps ensure that documents with slightly lower scores still have a chance to show up near the top. For this value, Lucidworks recommends entering the inverse of the lexical maximum score across all queries for the given collection.
- In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
-
In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
- In the Min Return Vector Similarity field, enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- In the Min Traversal Vector Similarity field, enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query.
- When enabled, the Compute Vector Similarity for Lexical-Only Matches setting computes vector similarity scores for documents in lexical search results but not in the initial vector search results. Select the checkbox to enable this setting.
-
If you want to use pre-filtering:
-
Uncheck Block pre-filtering.
In the Javascript context (
ctx), thepreFilterKeyobject becomes available. -
Add a Javascript stage after the Neural Hybrid Query stage and use it to configure your pre-filter.
The
preFilterobject adds both the top-levelfqandpreFilterto the parameters for the vector query. You do not need to manually add the top levelfqin the javascript stage. See the example below:
-
Uncheck Block pre-filtering.
In the Javascript context (
- Click Save.
solrconfig.xml within the <config> tag:Configure the Hybrid Query stage (5.9.9 and earlier)
If you’re setting up Neural Hybrid Search in Lucidworks Search 5.9.9 and earlier, use the Hybrid Query stage. If you’re using Lucidworks Search 5.9.10 or later, use the Neural Hybrid Query stage.- In the same query pipeline where you configured vector search, click Add a new pipeline stage, then select Hybrid Query.
- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example, <request.params.q>. Template expressions are supported.
- In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Number of Lexical Results field, enter the number of lexical search results to include in re-ranking. For example, 1000. A value is 0 is ignored.
- In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
- In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
- Select the Use KNN Query checkbox to use the knn query parser and configure its options. This option cannot be selected if Use VecSim Query checkbox is selected. In addition, Use KNN Query is used if neither Use KNN Query or Use VecSim Query is selected.
- If the Use KNN Query checkbox is selected, enter a value in the Number of Vector Results field. For example, 1000.
- Select the Use VecSim Query checkbox to use the vecSim query parser and configure its options. This option cannot be selected if Use KNN Query checkbox is selected.
If the Use VecSim Query checkbox is selected, enter values in the following fields:
- Min Return Vector Similarity. Enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- Min Traversal Vector Similarity. Enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query. The value must be lower than, or equal to, the value in the Min Return Vector Similarity field.
- In the Minimum Vector Similarity Filter, enter the value for a minimum similarity threshold for filtering documents. This option applies to all documents, regardless of other score boosting such as rules or signals.
- Click Save.
Perform hybrid searches
After setting up the stages, you can perform hybrid searches via theknn query parser as you would with Solr. Specify the search vector and include it in the query. For example, change the q parameter to a knn query parser string.You can also preview the results in the Query Workbench.
Try a few different queries, and adjust the weights and parameters in the Hybrid Query stage to find the best balance between lexical and semantic vector search for your use case.
You can also disable and re-enable the Neural Hybrid Query stage to compare results with and without it.XDenseVectorField is not supported in Lucidworks Search 5.9.5. Instead, use DenseVectorField.Troubleshoot inconsistent results
Neural Hybrid Search leverages Solr semantic vector search, which has known behaviors which can be inconsistent at query time. These behaviors include score fluctuations with re-querying, documents showing and disappearing on re-querying, and (when SVS is configured without Hybrid stages) completely unfindable documents. This section outlines possible reasons for inconsistent behavior and resolutions steps.NRT replicas and HNSW graph challenges
Lucidworks recommends using PULL and TLOG replicas. These replica types copy the index of the leader replica, which results in the same HNSW graph on every replica. When querying, the HNSW approximation query will be consistent given a static index.In contrast, NRT replicas have their own index, so they will also have their own HNWS graph. HNSW is an Approximate Nearest Neighbor (ANN) algorithm, so it will not return exactly the same results for differently constructed graphs. This means that queries performed can and will return different results per HNWS graph (# of NRT replicas in a shard) which can lead to noticeable result shifts. When using NRT replicas, the shifts can be made less noticeable by increasing thetopK parameter. Variation will still occur, but should be lower in the documents. Another way to mitigate shifts is to use Neural Hybrid Search with a vector similarity cutoff.For more information, refer to Solr Types of Replicas.In the case of Neural Hybrid Search, lexical BM25 and TF-IDF score differences that can occur with NRT replicas because of index differences for deleted documents can also affect combined Hybrid score.
If you choose to use NRT replicas, then it is possible that any lexical and semantic vectors variations can and will be made worse.Orphaning (Disconnected Nodes)
Solr’s implementation of dense vector search depends on the Lucene implementation of HNSW ANN. The Lucene implementation has a known issue where, in some collections, nodes in the HNSW graph become unreachable via graph traversal, essentially becoming disconnected or “orphaned.”Identify orphaning
Run the following command to identify orphaning:If the collection doesn’t have a vector for every document, include a filter so only the documents that have vectors are included. Filter on the boolean vector, as in this example:
--form-string 'fq=VECTOR_FIELD_b:true' \ids you see are the orphans.
Proceed to Resolving orphans.
If no documents are returned, there are likely no orphans.
You can try a few varying vectors to be certain.Resolving orphans
To resolve orphans, do the following:- Increase the HNSW Solr schema parameters
hnswBeamWidthandhnswMaxConnectionsper the Suggested values below. - Save the schema.
- Clear the index.
- Re-index your collection.
Suggested values
| Orphaning rate | hnswBeamWidth | hnswMaxConnections |
|---|---|---|
| 5% or less | 300 | 64 |
| 5% - 25% | 500 | 100 |
| 25% or more | 3200 | 512 |
Configure Ray/Seldon vector search
Configure Ray/Seldon vector search
You can use Seldon or Ray models to vectorize text for Neural Hybrid Search.To vectorize text with Ray, you first need to develop and deploy a machine learning model with Ray.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
Prerequisites
Seldon
To vectorize text with Seldon, you’ll first need to develop and deploy a machine learning model.Ray
This feature is available starting in Lucidworks Search 5.9.12 and in all subsequent Lucidworks Search 5.9 releases.
Configure index pipeline
- Sign into Lucidworks Search, go to Indexing > Index Pipelines, then select an existing pipeline or create a new one.
- Click Add a new pipeline stage, then select Ray/Seldon Vectorize Field. In Lucidworks Search 5.9.11 and earlier, this stage is called Seldon Vectorize Field.
- Fill in the required fields:
- Enter a Model ID. This is the name of the model you developed and deployed.
- Enter the Model Input Field. For example,
text. - Enter the Model Output Vector Field. For example,
vector. - Enter the Source Field. For example,
body_t. - Enter the Destination Field. For example,
body_512_v.
- Click Save.
- Make sure the Ray/Seldon Vectorize Field stage is ordered before the Solr Indexer stage.
Configure query pipeline
- Go to Querying > Query Pipelines, then select an existing pipeline.
- Click Add a new pipeline stage, then select Ray/Seldon Vectorize Query. In Lucidworks Search 5.9.11 and earlier, this stage is called Seldon Vectorize Query.
- Fill in the required fields, making sure to search against the field into which you indexed the vectors:
- Enter a Model ID. This is the name of the model you developed and deployed.
- Enter the Query Input.
- Enter the Model Input Field. For example,
text. - Enter the Model Output Vector Field. For example,
vector. - Enter the Vector Context Key. For example,
vector.
- Click Save.
- Make sure the Ray/Seldon Vectorize Query stage is ordered before the Solr Query stage.
Perform vector searches
After setting up the stages, you can perform vector searches via theknn query parser as you would with Solr. Specify the search vector and include it in the query. For example, change the q parameter to a knn query parser string.The Ray/Seldon Vectorize Query stage will encode user queries using the specified model and modify the q parameter to use the knn query parser, turning the query into a vector search.Develop and deploy a machine learning model with Ray
Develop and deploy a machine learning model with Ray
This tutorial walks you through deploying your own model to Fusion with Ray.A real instance of this class with the In the preceding code, logging has been added for debugging purposes.The preceding code example contains the following functions:In the preceding example, the Python file is named Any recent ray[serve] version should work, but the tested value and known supported version is 2.42.1.
In general, if an item was used in an Using the example model, the terminal commands would be as follows:This repository is public and you can visit it here: e5-small-v2-ray
This feature is only available in Fusion 5.9.x for versions 5.9.12 and later.
Prerequisites
- A Fusion instance with an app and indexed data.
- An understanding of Python and the ability to write Python code.
- Docker installed locally, plus a private or public Docker repository.
- Ray installed locally:
pip install ray[serve]using the version of ray[serve] found in the release notes for your version of Lucidworks Search. - Code editor; you can use any editor, but Visual Studio Code is used in this example.
- Model: intfloat/e5-small-v2
- Docker image: e5-small-v2-ray
Tips
- Always test your Python code locally before uploading to Docker and then Fusion. This simplifies troubleshooting significantly.
- Once you’ve created your Docker you can also test locally by doing
docker runwith a specified port, like 9000, which you can thencurlto confirm functionality in Fusion. See the testing example below. - If you previously deployed a model with Seldon, you can deploy the same model with Ray after making a few changes to your Docker image as explained in this topic. To avoid conflicts, deploy the model with a different name. When you have verified that the Ray model is working after deployment with Ray, you can delete the Seldon model using the Delete Seldon Core Model Deployment job.
- If you run into an issue with the model not deploying and you’re using the ‘real’ example, there is a very good chance you haven’t allocated enough memory or CPU in your job spec or in the Ray-Argo config.
It’s easy to increase the resources. To edit the ConfigMap, run
kubectl edit configmap argo-deploy-ray-model-workflow -n <namespace>and then find theray-headcontainer in the artisanal escaped YAML and change the memory limit. Exercise caution when editing because it can break the YAML. Just delete and replace a single character at a time without changing any formatting.- For additional guidance, see the testing locally e5-model example.
Intro to Machine Learning in Fusion
The course for Intro to Machine Learning in Fusion focuses on using machine learning to infer the goals of customers and users in order to deliver a more sophisticated search experience.
Local testing example
- Docker command:
- Curl to hit Docker:
- Curl model in Fusion:
- See all your deployed models:
- Check the Ray UI to see Replica State, Resources, and Logs.
If you are getting an internal model error, the best way to see what is going on is to query via port-forwarding the model.
TheMODEL_DEPLOYMENTin the command below can be found withkubectl get svc -n NAMESPACE. It will have the same name as set in the model name in the Create Ray Model Deployment job.Once port-forwarding is successful, you can use the below cURL command to see the issue. At that point your worker logs should show helpful error messages.
Download the model
This tutorial uses thee5-small-v2 model from Hugging Face, but any pre-trained model from https://huggingface.co will work with this tutorial.If you want to use your own model instead, you can do so, but your model must have been trained and then saved though a function similar to the PyTorch’s torch.save(model, PATH) function.
See Saving and Loading Models in the PyTorch documentation.Format a Python class
The next step is to format a Python class which will be invoked by Fusion to get the results from your model. The skeleton below represents the format that you should follow. See also Getting Started in the Ray Serve documentation.e5-small-v2 model is as follows:This code pulls from Hugging Face. To have the model load in the image without pulling from Hugging Face or other external sources, download the model weights into a folder name and change the model name to the folder name preceded by
./.__call__: This function is non-negotiable.init: Theinitfunction is where models, tokenizers, vectorizers, and the like should be set to self for invoking. It is recommended that you include your model’s trained parameters directly into the Docker container rather than reaching out to external storage insideinit.encode: Theencodefunction is where the field or query that is passed to the model from Fusion is processed. Alternatively, you can process it all in the__call__function, but it is cleaner not to. Theencodefunction can handle any text processing needed for the model to accept input invoked in itsmodel.predict()or equivalent function which gets the expected model result.
Use the exact name of the class when naming this file.
deployment.py and the class name is Deployment().Create a Dockerfile
The next step is to create a Dockerfile. The Dockerfile should follow this general outline; read the comments for additional details:Create a requirements file
Therequirements.txt file is a list of installs for the Dockerfile to run to ensure the Docker container has the right resources to run the model.
For the e5-small-v2 model, the requirements are as follows:import statement in your Python file, it should be included in the requirements file.To populate the requirements, use the following command in the terminal, inside the directory that contains your code:Build and push the Docker image
After creating theMODEL_NAME.py, Dockerfile, and requirements.txt files, you need to run a few Docker commands.
Run the following commands in order:Deploy the model in Fusion
Now you can go to Fusion to deploy your model.When deploying your Ray model, you have two options for handling traffic:- Use a single deployment. Deploy one model job that handles both indexing and query traffic. This is simpler to manage and requires only one deployment.
- Use separate deployments for indexing and querying. Deploy two separate model jobs: one dedicated to indexing and another for query traffic. This approach eliminates the risk of indexing workloads impacting query response times, providing better performance isolation and independent scaling control.
EXAMPLE_MODEL_INDEX and EXAMPLE_MODEL_QUERY). Use the index-specific model in your index pipeline stages and the query-specific model in your query pipeline stages. To keep both deployments in sync, ensure both jobs use the exact same model name, Ray deployment import path, Docker repository, and image name.- In Fusion, navigate to Collections > Jobs.
- Add a job by clicking the Add+ Button and selecting Create Ray Model Deployment.
-
Fill in each of the text fields:
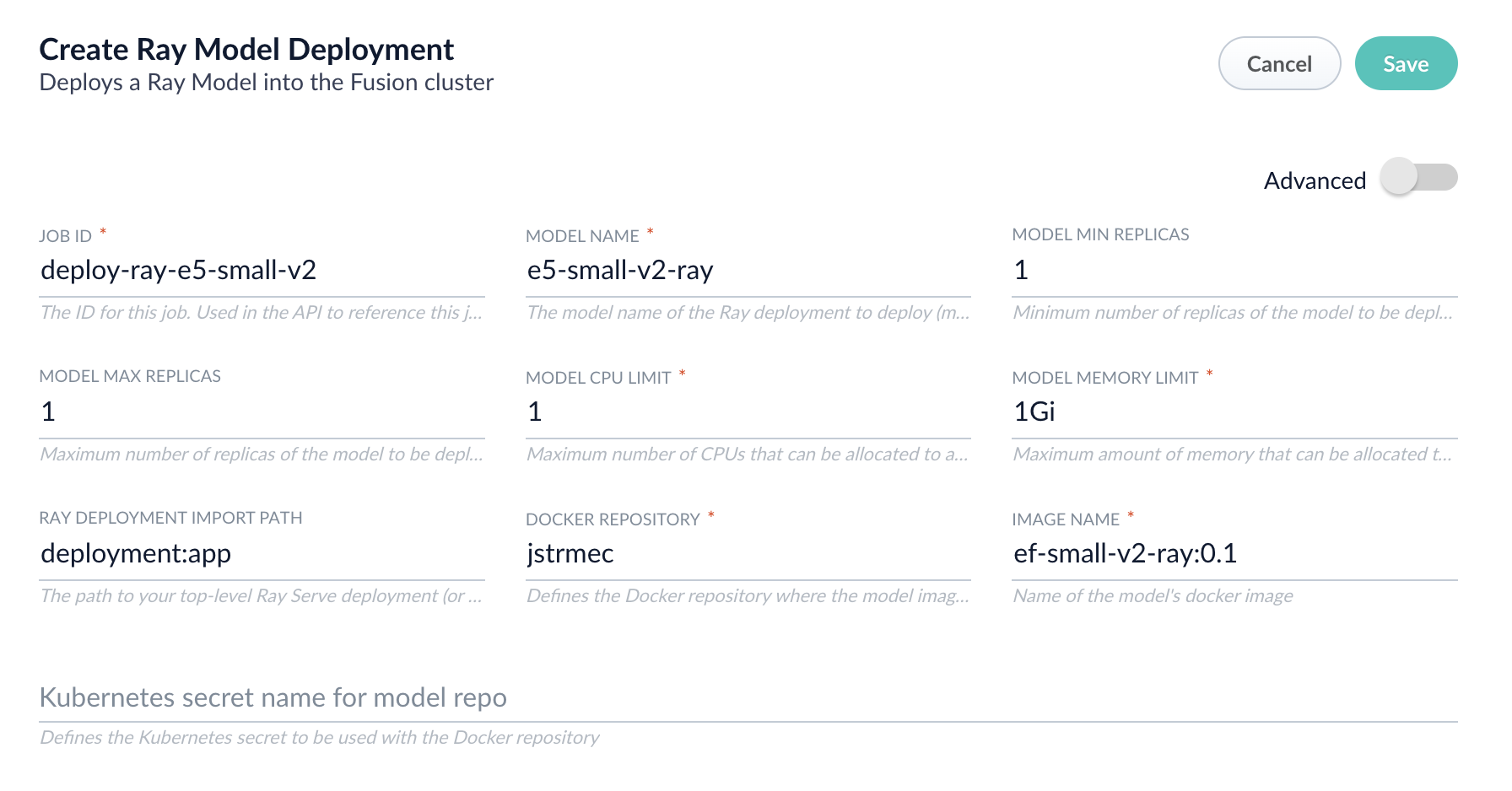
Parameter Description Job ID A string used by the Fusion API to reference the job after its creation. Model name A name for the deployed model. This is used to generate the deployment name in Ray. It is also the name that you reference as a model-idwhen making predictions with the ML Service.Model min replicas The minimum number of load-balanced replicas of the model to deploy. Model max replicas The maximum number of load-balanced replicas of the model to deploy. Specify multiple replicas for a higher-volume intake. Model CPU limit The number of CPUs to allocate to a single model replica. Model memory limit The maximum amount of memory to allocate to a single model replica. Ray Deployment Import Path The path to your top-level Ray Serve deployment (or the same path passed to serve run). For example,deployment:appDocker Repository The public or private repository where the Docker image is located. If you’re using Docker Hub, fill in the Docker Hub username here. Image name The name of the image. For example, e5-small-v2-ray:0.1.Kubernetes secret If you’re using a private repository, supply the name of the Kubernetes secret used for access. -
Click Advanced to view and configure advanced details:
Parameter Description Additional parameters. This section lets you enter parameter name:parametervalue options to be injected into the training JSON map at runtime. The values are inserted as they are entered, so you must surround string values with". This is the sparkConfig field in the configuration file.Write Options. This section lets you enter parameter name:parametervalue options to use when writing output to Solr or other sources. This is the writeOptions field in the configuration file.Read Options. This section lets you enter parameter name:parametervalue options to use when reading input from Solr or other sources. This is the readOptions field in the configuration file. -
Click Save, then Run and Start.
Configure the Fusion pipelines
Your real-world pipeline configuration depends on your use case and model, but for our example we will configure the index pipeline and then the query pipeline.Configure the index pipeline- Create a new index pipeline or load an existing one for editing.
- Click Add a Stage and then Machine Learning.
- In the new stage, fill in these fields:
- The model ID
- The model input
- The model output
- Save the stage in the pipeline and index your data with it.
- Create a new query pipeline or load an existing one for editing.
- Click Add a Stage and then Machine Learning
- In the new stage, fill in these fields:
- The model ID
- The model input
- The model output
- Save the stage and then run a query by typing a search term.
- To verify the Ray results are correct, use the Compare+ button to see another pipeline without the model implementation and compare the number of results.
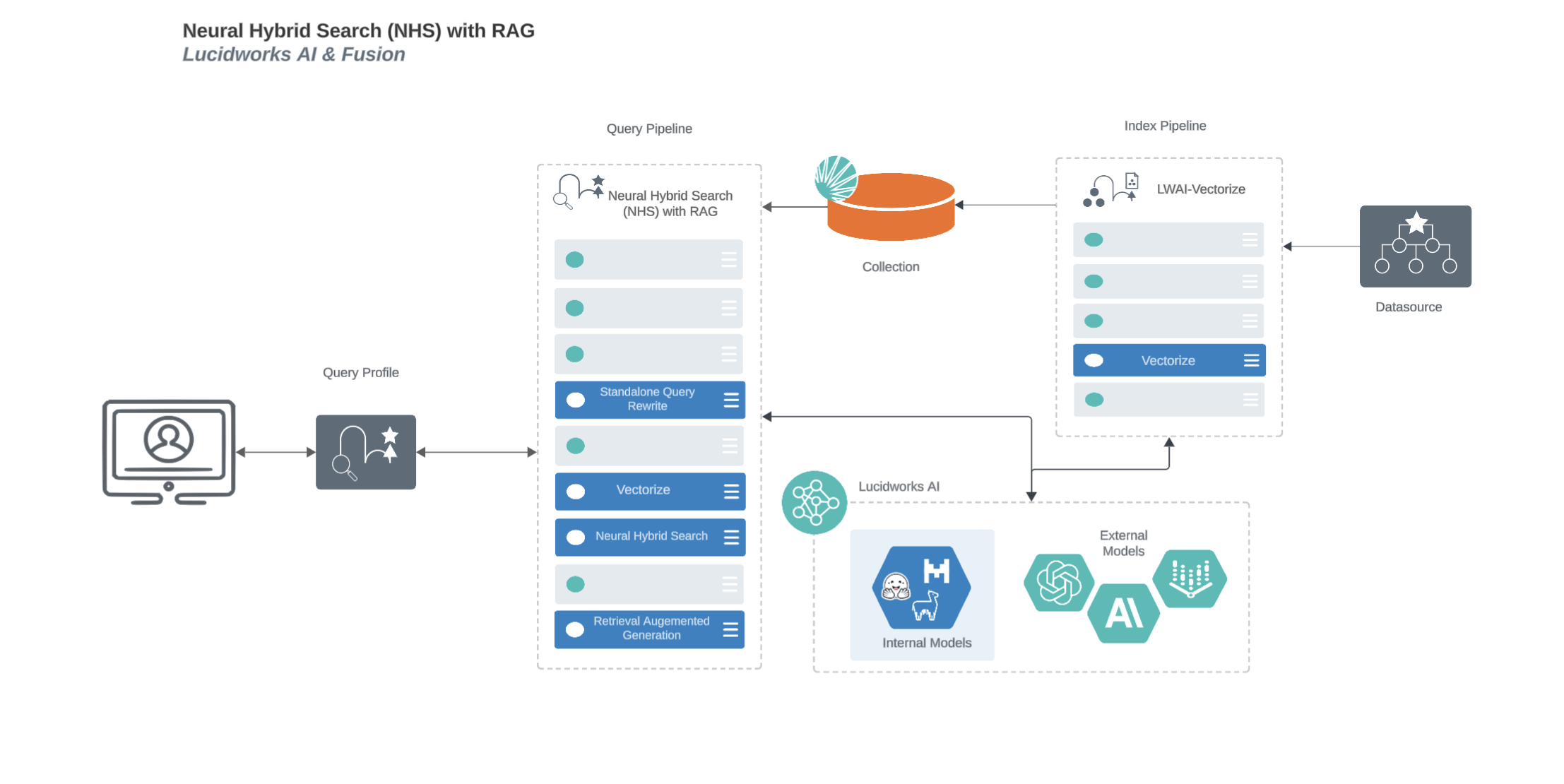
Configure the LWAI Neural Hybrid Search pipeline
Configure the LWAI Neural Hybrid Search pipeline
The LWAI Neural Hybrid Search pipeline is a default pipeline that contains all the required query stages to set up Neural Hybrid Search using Lucidworks AI.This pipeline uses the following stages:This query stage must be placed before the Solr Query stage.
This feature is currently only available to clients who have contracted with Lucidworks for features related to Neural Hybrid Search and Lucidworks AI.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
- Text Tagger
- Boost with Signals
- Query Fields
- LWAI Vectorize Query
- Hybrid Query (5.9.9 and earlier)
- Neural Hybrid Query (5.9.10 and later)
- Apply Rules
- Solr Query
- Modify Response with Rules
Milvus is deprecated. To migrate an existing Milvus collection to Solr vector, see the Milvus to Solr migration guide. Migrating prior to Milvus removal is important to prevent disruptions to pipeline performance.
Configure the pipeline
To add the Neural Hybrid Search (NHS) query pipeline:- Sign in to Lucidworks Search and click Querying > Query Pipelines.
- Select the default LWAI-neural-hybrid-search-NHS pipeline.
- Configure the following stages included in the default pipeline.
Text Tagger
The Text Tagger stage queries a Solr text tagger request handler to perform spell correction, phrase boosting, and synonym expansion.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Tagger Collection field, enter where the tagger request is sent. The default is the query_rewrite collection for the application selected. You must enter a collection with only one shard because Text Tagger does not support multi-shard collections. Template expressions are supported.
- In the Param to Tag field, enter a value of q, which is the name of the parameter in the request containing text to tag. This field is ignored on DSL requests.
- In the Save Tags in Context field, enter the tags to save in context instead of applying directly to the incoming query in this stage. This enables downstream stages to apply the tags after completing other processing. This field is ignored on DSL requests.
-
Select the following checkboxes:
- Spell Correction
- Phrase Boosting
- Synonym Expansion
- Remove Words
- Tail Rewrites
- In the Filter Override field, enter your filter to override filtering for built-in tagger doc types.
- In the Original Term Boost for Synonyms field, enter the boost to use for the original term during synonym expansion. For example, 2. To disable this function, enter -1.
- In the Default Phrase Boost field, enter the boost to use as a default for phrases that do not have a boost value set. For example, 2. To disable this function, enter -1.
- In the Default Phrase Slop field, enter the distance between the terms of the query while still considering it a phrase match. For example, 10.
- In the Overlapping Tag Policy field, select the default value of longest_dominant_right to ensure the retained tags have no overlaps. The value is the algorithm that determines which tags in an overlapping set should be retained, versus being pruned away. On DSL requests, this field is ignored so the default value of longest_dominant_right is always used. The available options correspond to Solr Tagger Handler overlaps: all, no_sub, or longest_dominant_right. Setting the value to all or no_sub allows more rewrites to potentially be applied to a query, but can increase the chance of producing undesirable rewrites.
- In the Additional Params to be included in the Text Tagger Request section, enter optional values you want to include.
- In the Max Wait for Lookup (ms) field, enter the number of milliseconds to wait for the call to the remote tagger collection to return. For example, 500. To disable this function, enter -1.
- In the Skip Query Regex field, enter the pattern that identifies queries that are skipped because they contain that pattern. For example, you may want to skip single term queries with wildcards.
- Click Save.
Boost with Signals
The Boost with Signals stage uses aggregated signals to selectively boost items in the set of search results.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- Select the Asynchronous Execution Config check box to process this stage asynchronously.
- In the Number of Recommendations field, enter the number of documents to return in the query. For example, 10.
- In the Number of Signals field, enter the number of signals to process when getting recommended items. For example, 100.
- In the Aggregation Type field, enter an applicable value. For example, click@doc_id,filters,query.
- In the Solr Field to Boost On field, enter which Solr field to use when applying recommendation boosts. For example, id.
- In the Boost Method field, select the boost method to use. If the defType!=edismax for the main query, select query-parser. Another example is query-param.
-
In the Boost Param field, select one of the following values:
- boost to multiply scores by the boost values
- bq to add optional clauses to main query
-
In the Solr Query parameters section, enter the following Parameter Name:Parameter Value entries:
qf:query_tpf:query_t^50pf:query_t-3^20pf2:query_t^20pf2:query_t~3^10pf3:query_t^10pf3:query_t~3^5boost:map(query({!field f=query_s v=$q}),0,0,1,20)mm:50%defType:edismaxsort:score desc, weight_d descfq:weight_d:[** TO **]
- In the Rollup Field, enter the field name to use when rolling up documents that have the same doc id. For example, doc_id_s.
- In the Rollup weight field, enter the field name to use for signal weights. For example, weight_d.
-
In the Rollup weight strategy field, select one of the following methods to use when rolling up the weight:
- max
- sum
- In the Final Boost Weight Expression field, enter the optional expression to compute the final boost weight using a combination of fields returned by Solr. For example, score and weight_d. Set to weight_d for similar behavior as older versions. Another example is math:log(weight_d + 1) + 10 * math:log(score+1).
- In the Document Weights Context Key field, enter the context key in which to save boosts for docId:weight_d.
- In the Query Param field, enter the default value of q, which is the name of the parameter in the request containing query to boost.
-
Select the Include Enriched Query checkbox to:
- Enable the stage to combine the user’s original query with the output of any stages that enrich the query, such as the Text Tagger stage.
- Expand the recall of the boost lookup. However, precision may be impacted.
- Enable the stage to change the configured mm parameter to accommodate additional terms added to the boost lookup query.
- In the Update Policy field, select to replace or append the boost parameter in the final query.
- Click Save.
Query Fields
The Query Fields stage configures query parameters for a Solr search.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Number of Results field, enter the number of query fields to return. For example, 10.
- In the Result Offset field, enter the value that designates the starting position of the first result from the beginning of the data being queried. Offset is zero-based, so a value of 9 counts from 0 through 9 and the first record returned is the 10th record discovered in the query.
-
In the Results Sort Order section, enter values for the following fields:
- Sort Type. For example, sort on expression, field, query, or relevancy.
- Field Name or Expression on which to sort.
- Sort Order. Select either asc or desc.
- In the Search Fields section, enter the field name and boost values to include in this stage.
- In the Return Fields section, enter the field names to include in this stage.
- Select the Return Score checkbox to set as true and determine if a score is determined for this stage.
- In the Minimum Should Match field, enter the minimum string to match for this stage.
-
Select the Grouping Options checkbox to enter values in the following fields:
- Grouping Field. The field name on which to group results.
- Group Size. The number of results per group.
- Group Sort. Enter values in the following fields:
- Sort Type. For example, sort on expression, field, query, or relevancy.
- Field Name or Expression on which to sort.
- Sort Order. Select either asc or desc.
- Group Leader Strategy. Select this checkbox to define selection criteria for the representative document from each group. Only one method may be used at a time. Defaults to relevancy if not specified. Values are:
- By Field Value. If selected, include documents with the minimum or maximum value for the indicated field to be the representative document for each group.
- By Sort. If selected, include the representative document for each group based on the order in which they are returned with the given sort criteria.
- Click Save.
LWAI Vectorize Query
The LWAI Vectorize Query stage configures parameters to generate a vector by using a Lucidworks AI (LWAI) embedding model to encode the input to a vector representation. This stage is ignored if the input is blank or a wildcard of either an asterisk\* or a colon : is used.- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
-
Select Asynchronous Execution Config if you want to run this stage asynchronously. If this field is enabled, complete the following fields:
- Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
signalsoraccess_control. - Copy the Async ID value.
For detailed information, see Asynchronous query pipeline processing. - Select Enable Async Execution. Fusion automatically assigns an Async ID value to this stage. Change this to a more memorable string that describes the asynchronous stages you are merging, such as
- In the Account Name field, select the name of the Lucidworks AI account. If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
-
In the Model field, select the Lucidworks AI model to use for encoding.
If you do not see any model names and you are a non-admin Fusion user, verify with a Fusion administrator that your user account has these permissions:PUT,POST,GET:/LWAI-ACCOUNT-NAME/**For more information, see: - In the Query Input field, enter the location from which the query is retrieved.
- In the Output context variable field, enter the name of the variable where the vector value from the response is saved.
-
In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to generative AI and embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. -
In the Model Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs during this stage.
- Click Save.
The Top K setting is 100 by default, but a value as high as 1000 provides better recall if you have fewer than one million indexed documents.
You can raise it even higher, but keep in mind that higher recall also causes higher latency.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
When raising this value, we recommend also setting a higher Min Return Vector Similarity value, in the 0.7-0.85 range.
Hybrid Query (5.9.9 and earlier)
The Hybrid Query stage is a combination of semantic vector search and lexical search. This stage is ignored if the input is blank or a wildcard of either an asterisk\* or a colon :.In addition, this stage does not function correctly if the incoming q parameter is a Solr query parser string. For example, field_t:foo rather than a raw user query string.The resulting query is always written to<request.params.q>.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
-
In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example,
<request.params.q>. Template expressions are supported. - In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Number of Lexical Results field, enter the number of lexical search results to include in re-ranking. For example, 1000. A value is 0 is ignored.
- In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
-
In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
-
Select the Use KNN Query checkbox to use the knn query parser and configure its options. This option cannot be selected if Use VecSim Query checkbox is selected. In addition, Use KNN Query is used if neither Use KNN Query or Use VecSim Query is selected.
- If the Use KNN Query checkbox is selected, enter a value in the Number of Vector Results field. For example, 1000.
-
Select the Use VecSim Query checkbox to use the vecSim query parser and configure its options. This option cannot be selected if Use KNN Query checkbox is selected.
If the Use VecSim Query checkbox is selected, enter values in the following fields:- Min Return Vector Similarity. Enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- Min Traversal Vector Similarity. Enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query. The value must be lower than, or equal to, the value in the Min Return Vector Similarity field.
- In the Minimum Vector Similarity Filter, enter the value for a minimum similarity threshold for filtering documents. This option applies to all documents, regardless of other score boosting such as rules or signals.
- Click Save.
Neural Hybrid Query (5.9.10 and later)
The Neural Hybrid Query stage is a combination of semantic vector search and lexical search. This stage is ignored if the input is blank or a wildcard of either an asterisk\* or a colon :.In addition, this stage does not function correctly if the incoming q parameter is a Solr query parser string. For example, field_t:foo rather than a raw user query string.The resulting query is always written to<request.params.q>.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Lexical Query Input field, enter the location from which the lexical query is retrieved. For example,
<request.params.q>. Template expressions are supported. - In the Lexical Query Weight field, enter the relative weight of the lexical query. For example, 0.3. If this value is 0, no re-ranking will be applied using the lexical query scores.
- In the Lexical Query Squash Factor field, enter a value that will be used to squash the lexical query score.
The squash factor controls how much difference there is between the top-scoring documents and the rest. It helps ensure that documents with slightly lower scores still have a chance to show up near the top. For this value, Lucidworks recommends entering the inverse of the lexical maximum score across all queries for the given collection. - In the Vector Query Field, enter the name of the Solr field for k-nearest neighbor (KNN) vector search.
- In the Vector Input field, enter the location from which the vector is retrieved. Template expressions are supported. For example, a value of
<ctx.vector>evaluates the context variable resulting from a previous stage, such as the LWAI Vectorize Query stage. - In the Vector Query Weight field, enter the relative weight of the vector query. For example, 0.7.
- In the Min Return Vector Similarity field, enter the minimum vector similarity value to qualify as a match from the Vector portion of the hybrid query.
- In the Min Traversal Vector Similarity field, enter the minimum vector similarity value to use when walking through the graph during the Vector portion of the hybrid query.
- When enabled, the Compute Vector Similarity for Lexical-Only Matches setting computes vector similarity scores for documents in lexical search results but not in the initial vector search results. Select the checkbox to enable this setting.
- If you want to use pre-filtering:
- Uncheck Block pre-filtering.
In the Javascript context (ctx), thepreFilterKeyobject becomes available. - Add a Javascript stage after the Neural Hybrid Query stage and use it to configure your pre-filter.
ThepreFilterobject adds both the top-levelfqandpreFilterto the parameters for the vector query.
You do not need to manually add the top levelfqin the javascript stage.
See the example below:
- Uncheck Block pre-filtering.
- Click Save.
Apply Rules
The Apply Rules stage applies the rules configured in the collection to the query.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- Select the Asynchronous Execution Config check box to process this stage asynchronously.
- In the Collection field, enter the name of the collection that contains the rules. If this field does not contain a value, the default rules collection for the selected application is used. Template expressions are supported.
- In the Request Handler field, enter a value of select.
- In the HTTP Method field, select POST.
- In the Rule Triggering Limit field, enter the maximum number of business rules to be triggered by the query. The default rules matching limit is 100. This configuration overwrites the rows parameter set in Query Parameters section.
- In the Query Parameters section, enter the names and values to use when querying the rules collection. If you set the rows parameter here, it will be overwritten by the configuration in the Rule Triggering Limit field.
- In the Subquery Rewrite Pipeline id field, enter the value to call a Lucidworks Search query pipeline to modify the rule-retrieving subquery. Template expressions are supported.
- In the Headers section, enter the names and values to use in this stage.
- Select the Use Original Query If No Rules Match checkbox so the stage will try to match rules using the original query (un-tagged) sent into the Text Tagger stage, if available.
- Select the Partially Matched Filter Queries Will Trigger the Rule checkbox so the stage will trigger filter rules as long as there is one filter query in the query parameter that matches the filter specified in the rule.
- In the Max Wait for Lookup (ms), enter the number of milliseconds to wait for the call to the remote tagger collection to return. For example, 500. To disable this function, enter -1.
- Click Save.
Solr Query
The Solr Query stage sends the search request to Solr.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Configure Request Handlers Allowed for Queries section, enter a value for the request handlers used in this stage.
- In the HTTP Method field, select POST.
- Select the Allow Federated Search checkbox to enable the use of Solr collection and shards parameters for this stage.
- Select the Generate Response Signal checkbox to generate a response signal containing metadata about the response from Solr. Response signals are used by App Insights and experiments. This setting only applies if the searchLogs and signals features are enabled for the collection. To avoid generating response signals as Users type, do not select this option.
- In the Exclude Response Signal Criteria section, enter query parameters and Regex patterns to prevent generating a response signal based on specific parameters in the query. For example, use these fields to enable response signals in general, but to disable for auto-complete queries.
- In the Preferred Replica Type field, select pull to specify a replicate type that will be given a higher order of precedence when querying Solr. This preference will only be applied for queries that target multiple shards.
- Click Save.
Modify Response with Rules
The Modify Response with Rules stage modifies the response from Solr using matching rules from the Apply Rules stage.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- In the Facet Field Label Blob ID, enter the ID for a blob containing labels for facet fields to add to the response.
- In the Facet Label Parse Delimiter field, enter
||as the delimiter to parse each facet label mapping in the blob. A Java regular expression is also a valid value. Regex must start with^and end with$. - Click Save.
Order the stages
For the pipeline to operate correctly, the stages must be in the following order:- Text Tagger
- Boost with Signals
- Query Fields
- LWAI Vectorize Query
- Hybrid Query
- Apply Rules
- Solr Query
- Modify Response with Rules
Configure the LWAI Vectorize pipeline
Configure the LWAI Vectorize pipeline
The LWAI Vectorize pipeline is a default pipeline that contains the required index stages to set up vector search using Lucidworks AI.This pipeline uses the following stages:
This feature is currently only available to clients who have contracted with Lucidworks for features related to Neural Hybrid Search and Lucidworks AI.
This feature is only available in Lucidworks Search 5.9.x for versions 5.9.6+.
Configure the pipeline
To add the Lucidworks AI (LWAI) Vectorize index pipeline:- Sign in to Lucidworks Search and click Indexing > Index Pipelines.
- Select the default LWAI-vectorize pipeline.
- Configure the following stages included in the default pipeline.
Field Mapping
The Field Mapping stage customizes mapping of the fields in an index pipeline document to fields in the Solr scheme.To configure this stage for the index pipeline:- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- Select the Allow System Fields Mapping? checkbox to map system fields in this stage.
- In the Field Retention section, enter specific fields to either keep or delete.
- In the Field Value Updates section, enter specific fields and then designate the value to either add to the field, or set on the field. When a value is added, any values previously on the field are retained. When a value is set, any values previously on the field are overwritten by the new value entered.
- In the Field Translations section, enter specific fields to either move or copy to a different field. When a field is moved, the values from the source field are moved over to the target field and the source field is removed. When a field is copied, the values from the source field are copied over to the target field and the source field is retained.
- Select the Unmapped Fields checkbox to specify the operation on the fields not mapped in the previous sections. Select the Keep checkbox to keep all unmapped fields. This is the only option you need to select for the LWAI-vectorize stage.
- Click Save.
Solr Dynamic Field Name Mapping
The Solr Dynamic Field Name Mapping stage maps pipeline document fields to Solr dynamic fields.- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- Select the Duplicate Single-Valued Fields as Multi-Valued Fields checkbox to enable indexing of field data into both single-valued and multi-valued Solr fields. For example, if this option is selected, the
phonefield is indexed into both thephone_ssingle-valued field and thephone_ssmulti-valued field. If this option is not selected, thephonefield is indexed into only thephone_ssingle-valued field. - In the Field Not To Map section, enter the names of the fields that should not be mapped by this stage.
- Select the Text Fields Advanced Indexing checkbox to enable indexing of text data that doesn’t exceed a specific maximum length, into both tokenized and non-tokenized fields. For example, if this option is selected, the
nametext field with a value of John Smith is indexed into both thename_tandname_sfields allowing relevant search usingname_tfield (by matching to a Smith query) and also proper faceting and sorting usingname_sfield (using John Smith for sorting or faceting). If this option is not selected, thenametext field is indexed into only thename_ttext field by default. - In the Max Length for Advanced Indexing of Text Fields field, enter a value used to determine how many characters of the incoming text is indexed. For example, 100.
- Click Save.
LWAI Vectorize Field
The LWAI Vectorize stage invokes a Lucidworks AI model to encode a string field to a vector representation. This stage is skipped if the field to encode doesn’t exist or is null on the pipeline document.- In the Label field, enter a unique identifier for this stage.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process.
-
In the Account Name field, select the Lucidworks AI API account name defined in Lucidworks AI Gateway.
If you do not see your account name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks. -
In the Model field, select the Lucidworks AI model to use for encoding.
If you do not see your model name or you are unsure which one to select, contact the Lucidworks Search team at Lucidworks.
For more information, see: - In the Source field, enter the name of the string field where the value should be submitted to the model for encoding. If the field is blank or does not exist, this stage is not processed. Template expressions are supported.
-
In the Destination field, enter the name of the field where the vector value from the model response is saved.
- If a value is entered in this field, the following information added to the document:
-
{Destination Field}_bis the boolean value if the vector has been indexed. -
{Destination Field}is the vector field.
-
In the Use Case Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. The
useCaseConfigparameter that is common to embedding use cases isdataType, but each use case may have other parameters. The value for the query stage isquery. -
In the Model Configuration section, click the + sign to enter the parameter name and value to send to Lucidworks AI. Several
modelConfigparameters are common to generative AI use cases. For more information, see Prediction API. - Select the Fail on Error checkbox to generate an exception if an error occurs while generating a prediction for a document.
- Click Save.
- Index data using the new pipeline. Verify the vector field is indexed by confirming the field is present in documents.
Solr Indexer
The Solr Indexer stage transforms a Lucidworks Search pipeline document into a Solr document, and sends it to Solr for indexing into a collection.To configure this stage for the index pipeline:- In the Label field, enter a unique identifier for this stage or leave blank to use the default value.
- In the Condition field, enter a script that results in true or false, which determines if the stage should process, or leave blank.
- Select the Map to Solr Schema checkbox to select and add static and dynamic fields to map in this stage.
-
Select the Add a field listing all document fields checkbox to add the
_lw_fields_ssmulti-valued field to the document, which lists all fields that are being sent to Solr. - In the Additional Date Formats section, enter date formats to include in this stage.
- In the Additional Update Request Parameters section, enter the parameter names and values to update the request parameters.
- Select the Buffer Documents and Send Them To Solr in Batches checkbox to process the documents in batches for this stage.
- In the Buffer Size field, enter the number of documents in a batch before sending the batch to Solr. If no value is specified, the default value for this search cluster is used.
- In the Buffer Flush Interval (milliseconds) field, enter the maximum number of milliseconds to hold the batch before sending the batch to Solr. If no value is specified, the default value for this search cluster is used.
-
Select the Allow expensive request parameters checkbox to allow
commit=trueandoptimize=trueto be passed to Solr when specified as request parameters coming into this pipeline. Document commands that specify commit or optimize are still respected even if this checkbox is not selected. -
Select the Unmapped Fields Mapping checkbox to specify the information for all of the fields not mapped in the previous sections.
- In the Source Field, enter the name of the unmapped field to be mapped.
- In the Target Field, enter the name of the Solr field to which the unmapped field is mapped.
- In the Operation field, select how the field is mapped. The options are:
- Add the unmapped field to the Solr field.
- Copy the unmapped field to the Solr field and retain the value in the Source field.
- Delete the unmapped field.
- Keep the unmapped field and do not map it to a Solr field.
- Move (replace) the Solr field value with the unmapped field Source value and remove the value from the Source field.
- Set the value of the unmapped field to the value in the Solr field.
- Click Save.
Order the stages
For the pipeline to operate correctly, the stages must be in the following order:When you have ordered the stages, click Save.Index stages
Query stages
- Hybrid Query (5.9.9 and earlier)
- Neural Hybrid Query (5.9.10 and later)
- Chunking Neural Hybrid Query (5.9.12 and later)
- LWAI Vectorize Query
- Ray/Seldon Vectorize Query Stage
For information about which hybrid stage to select and why, see Differences between hybrid query stages.
Neural Hybrid Search diagrams
These diagrams display neural hybrid search process flows for different pipelines, models, and use cases.Neural Hybrid Search process flow for Lucidworks AI models
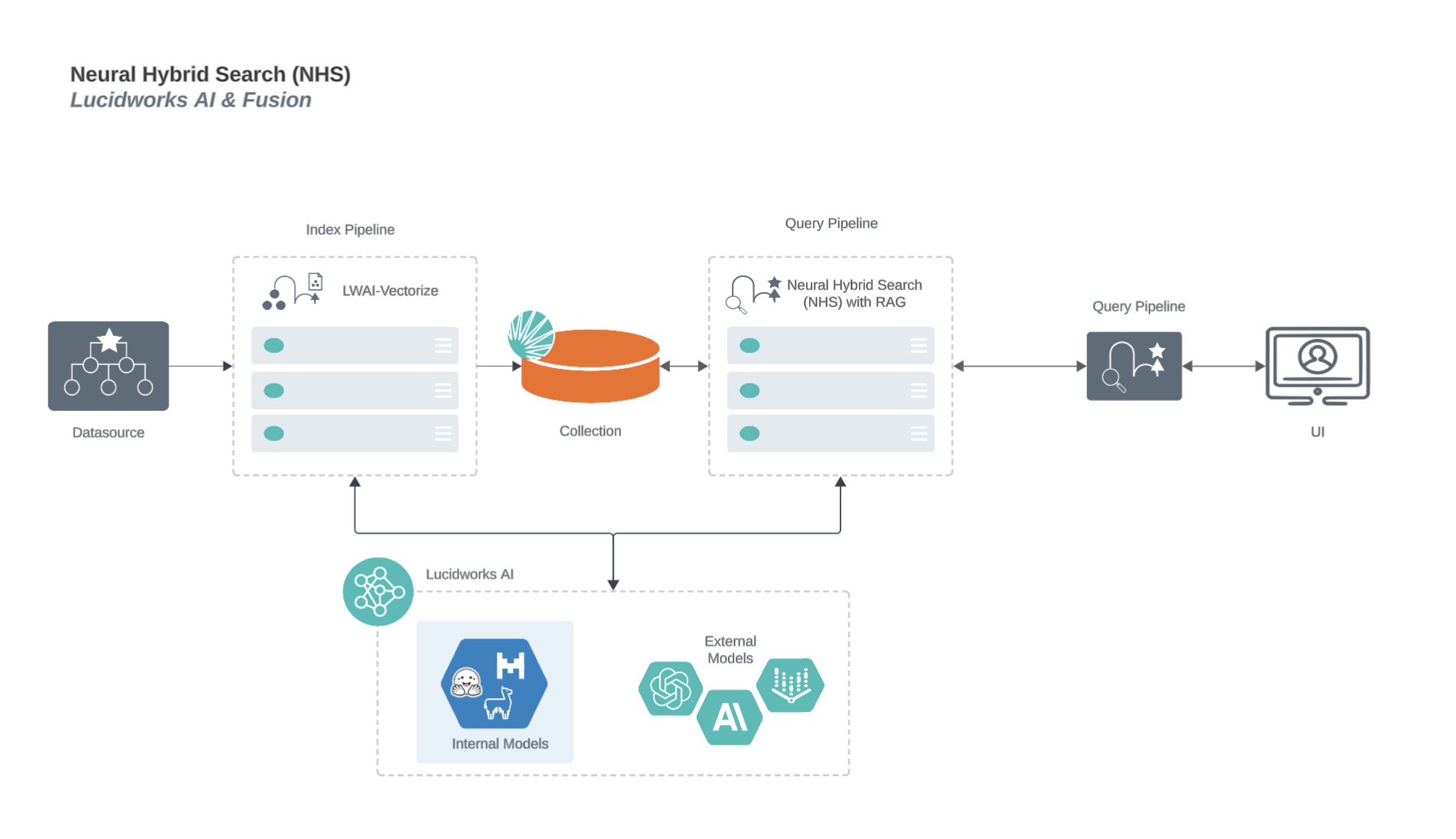
Neural Hybrid Search process flow for Seldon/Ray models
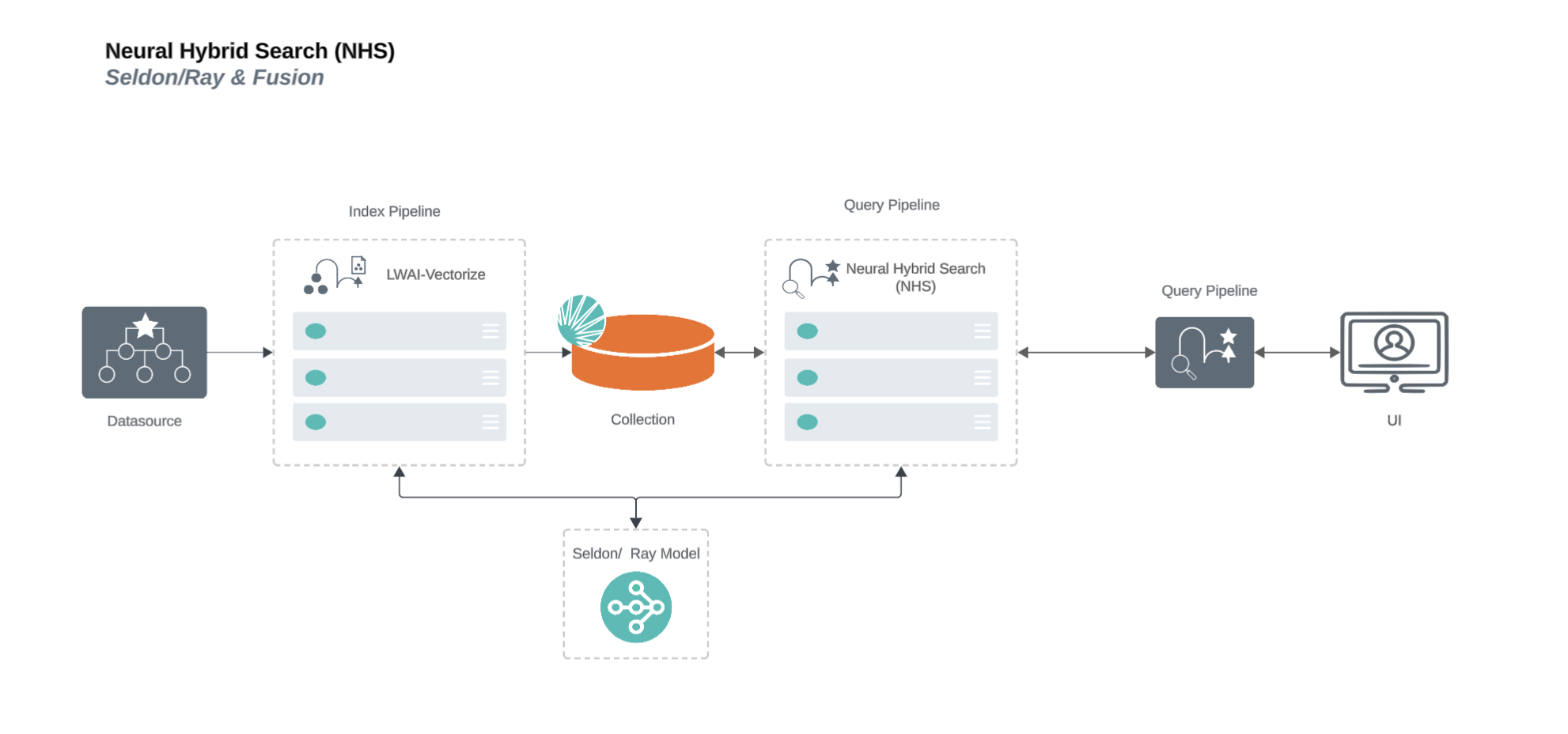
Neural Hybrid Search process flow for Lucidworks AI RAG use case