Setup
To add Fusion search connectors to a Maven project, you must add this dependency to your project’spom.xml file:
Usage
Assuming you have added the correct dependencies to your project (see above), the Fusion platform configuration can be accessed by pointing to it in the search:platform tag. In this case the platform is placed in a variable namedplatform using the var attribute, and points to a platform configuration in ../conf/platforms/fusion/search.conf:
platforms/fusion/search.conf
In this example platform configuration, we set some general settings for the platform:services/api/fusion.conf
This file controls which Fusion to use:platforms/fusion/social.conf
This file configures the Lucidworks Appkit Social Module:message/service/fusion.conf
This file configures how Signals are sent to Fusion:Required attributes
query-profile (java.lang.String)The Fusion query profile being accessed. If you have created an app via the Fusion UI called MyAwesomeApp, then you will have a default Query Profile called MyAwesomeApp as well - this is a good starting point.
Applied in: configuration
Optional attributes
-
requestHandler (java.lang.String)Name of the Request Handler to use. Use this to specify an alternate Request Handler to use for example, the ‘/dismax’ request handler. Note you can override this by specifying a ‘custom’ attribute on the query. -
requestMethod (java.lang.String)Which HTTP request method to use (GET or POST). -
strategy (java.lang.String)Whether to cluster multiple hosts (value should be either combine, or round-robin). To enable sharding, set strategy to combine. -
groupField (java.lang.String)Setting this enables Solr Result Grouping or Field Collapsing on the given field. This will create a Result for each Group returned. Matching documents for the group will be available as related results. -
timeOut (java.lang.Integer)Time out for platform query requests (in milliseconds).
Default: 5000 -
ignoreAppliedFilters (java.lang.Boolean)If this is set to false, facet filters that have already been applied to the Query are added to the list of filters for the facet.
Default: true -
backwardsCompatible (java.lang.Boolean)For Solr 1.x (for example, 1.4) set backwardsCompatible to true.
Default: false -
highlight (java.lang.Boolean)Whether to enable hit highlighting (hl parameter) in Solr.
Default: true
Attributes shared across platforms
-
aliases (java.lang.String)Manage mappings from field names to aliases (use a comma-separated list). All references to the field (via this platform) in results, facets, filters, and query strings are mapped. For example, to refer to a field in the index namedfirstnamelastnameasnameandcountryofresidenceascountry, use these mappings:aliases="firstnamelastname=name,countryofresidence=country" -
defaultQuery (java.lang.String)Default query to use when none is specified. For Solr use:to bring back all items (for example, for ‘zero term search’). -
defaultFacets (java.lang.String)Default facets to request when none are specified. This is a comma separated list. -
spellCheck (java.lang.Boolean)Spellcheck the Query term if supported by the Platform.
Default:true -
expandQuery (java.lang.Boolean)Apply advanced linguistics such as stemming or lemmatization if supported by the Platform.
Default:true -
autoCorrect (java.lang.Boolean)Whether to auto-correct and resubmit futile queries (queries with zero results).
Default:true -
fileTypeField (java.lang.String)Set which field contains information about file type (mime type).
Applied in: configuration -
resultIDField (java.lang.String)Set which field represents the unique identifier for a given result. Should correspond to the <uniqueKey> element in the Solr schema.xml.
Applied in: JSP tag, configuration -
pageLimit (java.lang.Long)A limitation to which page the platform will offset.
Applied in: JSP tag, configuration
Hit highlighting
Hit highlighting is enabled by default, and assumes that the unique uniqueKey field in the Solrschema.xml file is named id. If your uniqueKey is set to a different field highlighting will not work unless you set the resultIDfield key in the Appkit configuration to the right field.
<em></em> are used. Ensure that this has not been set to something different using hl.simple.pre and hl.simple.post settings in the Solr or request handler configurations.
Learn more
Fusion Impersonation via a Service Account
Fusion Impersonation via a Service Account
To securely access Fusion via Appkit, a user has several options. They can either adopt Appkit’s Fusion security provider making use of session cookies to send repeated requests back to Fusion, or they can access Fusion via a service account if they are planning to use query pipelines. In this section, we describe how to set up the latter.Here, the
1 Set up a service account on the Fusion server
If a user wants to query Fusion through a pipeline by impersonating another user via a service account, they must first ensure such an account has been set up on the Fusion server. This account should have access rights to the required resources.2 Add Security Trimming query stages to required pipelines
Query pipelines can have additional security filtering applied to ensure specific users do or do not have access to specific resources. This filtering can be set up by adding a Security Trimming stage to the query pipeline via the Fusion UI. The User ID key that is used in the security trimming stage to filter on results is supported in Appkit via theuser-id attribute, which is described in the next section.3 Update fusion.conf
To query Fusion using this approach, this attributes must be added to the platformfusion.conf file in src/main/resources/conf/platforms/fusion/:impersonate attribute informs Appkit that users will be querying Fusion pipelines via a service account. Below that, both the userName and the password are the credentials for the service account that Fusion will authenticate against. The last attribute user-id is optional and by default takes the value of username. This is the parameter that will be appended to the query string and filtered on in the security trimming stage. For example, the complete query URL might appear as:Fusion Query Terms and Suggestions
Fusion Query Terms and Suggestions
Appkit supports the ability to generate suggestions as-you-type for successive query terms with Fusion via our Solr suggestion services.Here, the Here, the
Accessing the Suggest Component
To access the Solr suggester in a Fusion application, refer to the section Suggester.For reference, here is an example of how the Appkit configuration might appear for this particular service:source defines the location of the fusion platform configuration. This will be used to identify the Fusion host and collection.Accessing the Terms Component
To access the Solr Terms component in a Fusion application, refer to the section Terms Component.For reference, here is an example of how the Appkit configuration might appear for this particular service:source defines the location of the fusion platform configuration. This will be used to identify the Fusion host and subsequently a collection that will contain fields as listed in term-fields.Ensure the terms request handler can be used with the Fusion query pipeline
The terms component and request handler are provided out-of-the-box in thesolrconfig.xml with Fusion. However, to ensure the query pipeline you are using does allow the terms handler to be used with queries, check that the Query Solr stage of your query-pipeline does list terms as an allowed request handler.Dynamic updates to multiple term queries
Because the terms component only allows suggestions one term at a time, in cases when multiple terms are being typed, suggestions will be given for the last term to be typed.Learn more
Configure the Suggest Component
Configure the Suggest Component
- Choose a suggester implementation from the Solr Suggester documentation, and define it in the solrconfig.xml file.
You can edit the solrconfig.xml file inside of the Fusion Admin UI. Navigate to System > Solr Config, and select the solrconfig.xml file to begin.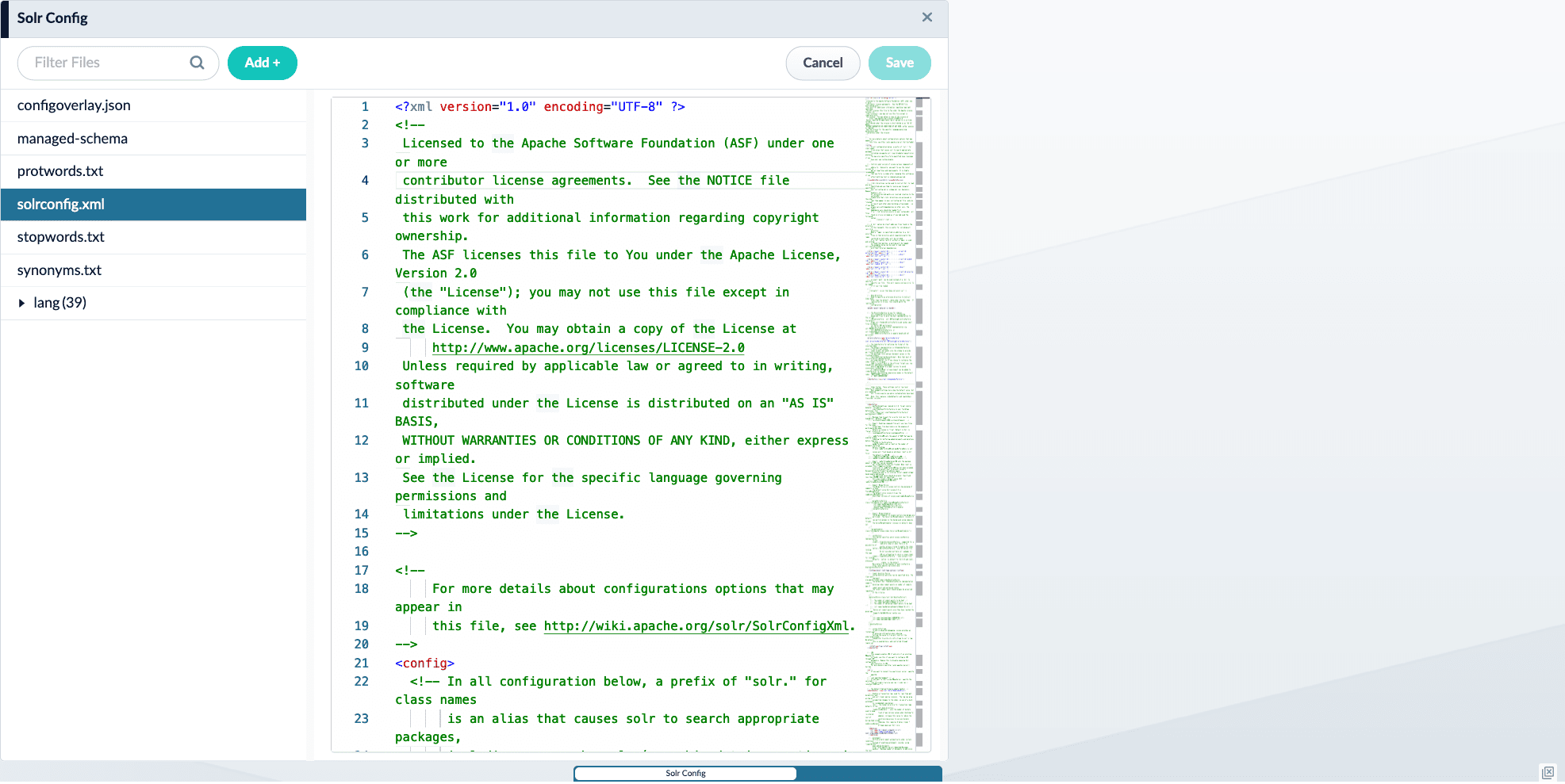
In this example, create a suggester called mySuggester in solrconfig.xml using theAnalyzingInfixLookupFactory. Definedescriptionas the suggester’s target field: - Ensure that the field used for autosuggest is correctly defined in the schema:
- Once modified, upload the custom configuration files to ZooKeeper using ZooKeeper’s command line interface.
Use the zkcli commandputfileto replace an existing ZooKeeper configuration file. Typically,CONFIG_NAMEwill likely represent the name of the collection. Alternatively, the name represents a custom configuration. - To enable autosuggest in Fusion, add the
suggestrequest handler to the allowed request handlers in the Solr Query stage of the query pipeline.
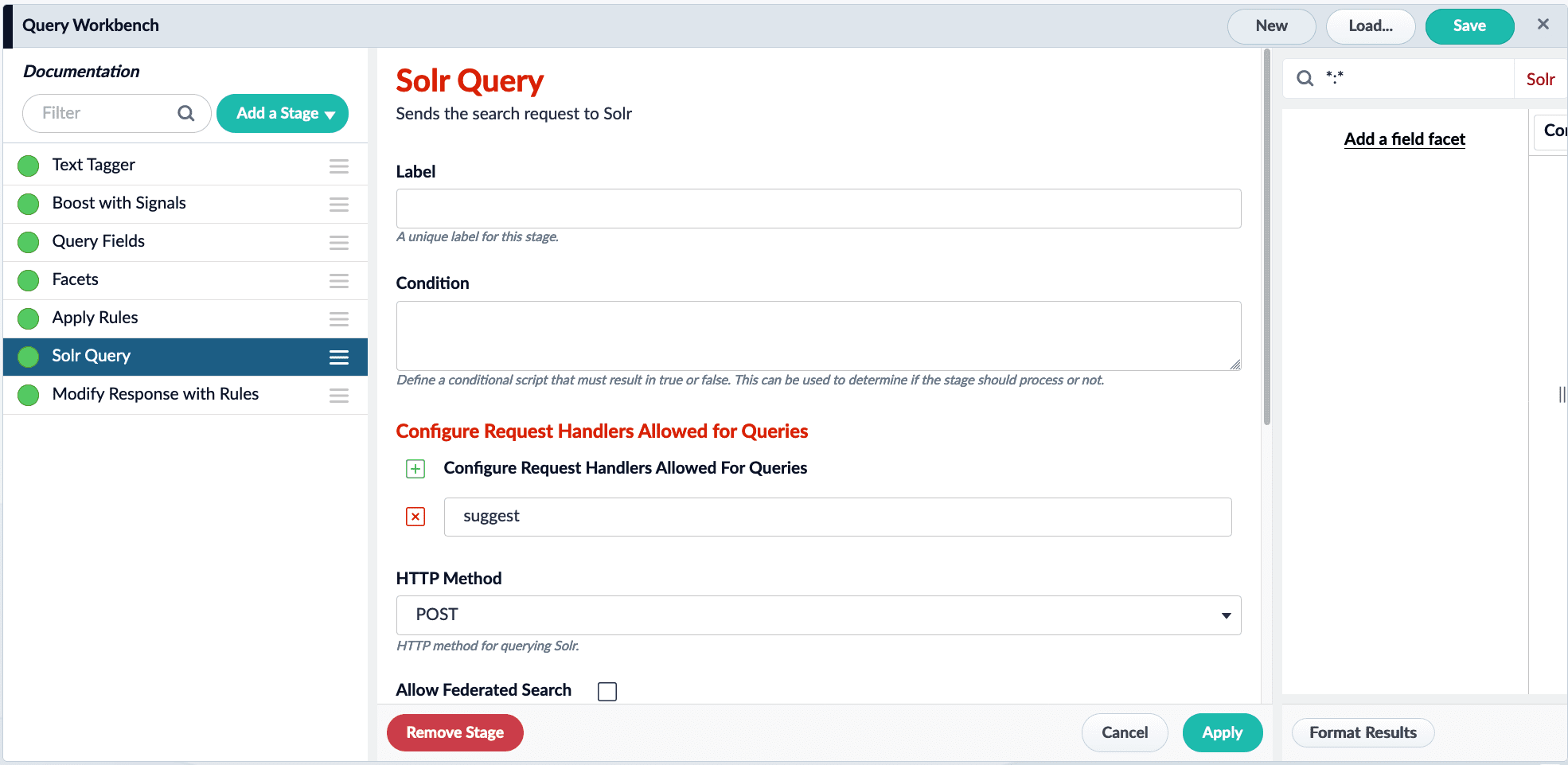
Build the suggester should using.../suggest?suggest.build=true. For example: - Start searching!