Apps
Fusion apps provide tailored search functionality to specific groups of users. An app is a named set of linked objects, including collections, datasources, index and query pipelines, index and query profiles, parsers, and more. Using roles and security realms, you can define security on a per-app basis.Collections
Collections consist of stored data and the datasources that determine how the data is ingested and indexed. Collections are a way to logically group your data sets. Fusion’s concept of collections is the same as Solr collections. See Collection Management.Datasources
Datasources are the configurations that determine how data is ingested and indexed. Each datasource includes a connector configuration, a parser configuration, and an index pipeline configuration. See Datasource Configuration.Connectors
Connectors are the conduit between Fusion and your external data sources. Connectors retrieve your data and import it into Fusion Server. See the Connectors Reference Guide for a complete list of available connectors.Parsers
Parsers interpret incoming data in order to determine its format and fields. A parser consists of a sequence of parsing stages, each designed to parse a different data format, sometimes recursively. See the Parser Stages Reference Guide for complete details about all available parsing stages.Index pipelines
Index pipelines format the incoming raw data into fielded documents that it can be indexed and searched by the Solr core. A pipeline consists of a sequence of stages, and each stage performs a different kind of processing based on user-configured logic. See the Index Pipeline Stages Reference Guide for a complete list of available index pipeline stages.Query Pipelines
Query pipelines manipulate incoming queries and return an ordered list of matching results from Solr. Individual search results are called documents. See Query Pipeline Configuration.Fusion Components
Apache Solr
Solr is the search platform that powers Fusion. There are multiple aspects to Fusion’s use of Solr:- Fusion components manage Solr search and indexing and provide analytics over these collections. Fusion’s analytics components depend on aggregations over information which is stored in a Solr collection.
- Fusion collections are all Solr collections.
- Application data is stored as one or more Solr collections.
- Fusion’s own logs are stored as Solr collections.
- A few Fusion service APIs use Solr as a backing store, notably Parameter Sets.
Solr configuration
Fusion requires that Solr run with SolrCloud enabled. Configuration for Solr’s Web service is inhttps://FUSION_HOST:FUSION_PORT/apps/jetty/solr.
Solr logs
Solr log files are inhttps://FUSION_HOST:FUSION_PORT/var/log/solr.
Accessing the Solr UI
With Fusion installed out of the box, you can still access the Solr UI athttp://localhost:8983/solr/.
Solr documentation
Solr documentation and additional resources are available at http://lucene.apache.org/solr/resources.html. You can also find plenty of Solr tips and technical discussions in our blog and webinars.Apache Spark
Apache Spark is a fast and general execution engine for large-scale data processing jobs that can be decomposed into stepwise tasks which are distributed across a cluster of networked computers. Spark provides faster processing and better fault-tolerance than previous MapReduce implementations. The following schematic shows the Spark components available from Fusion: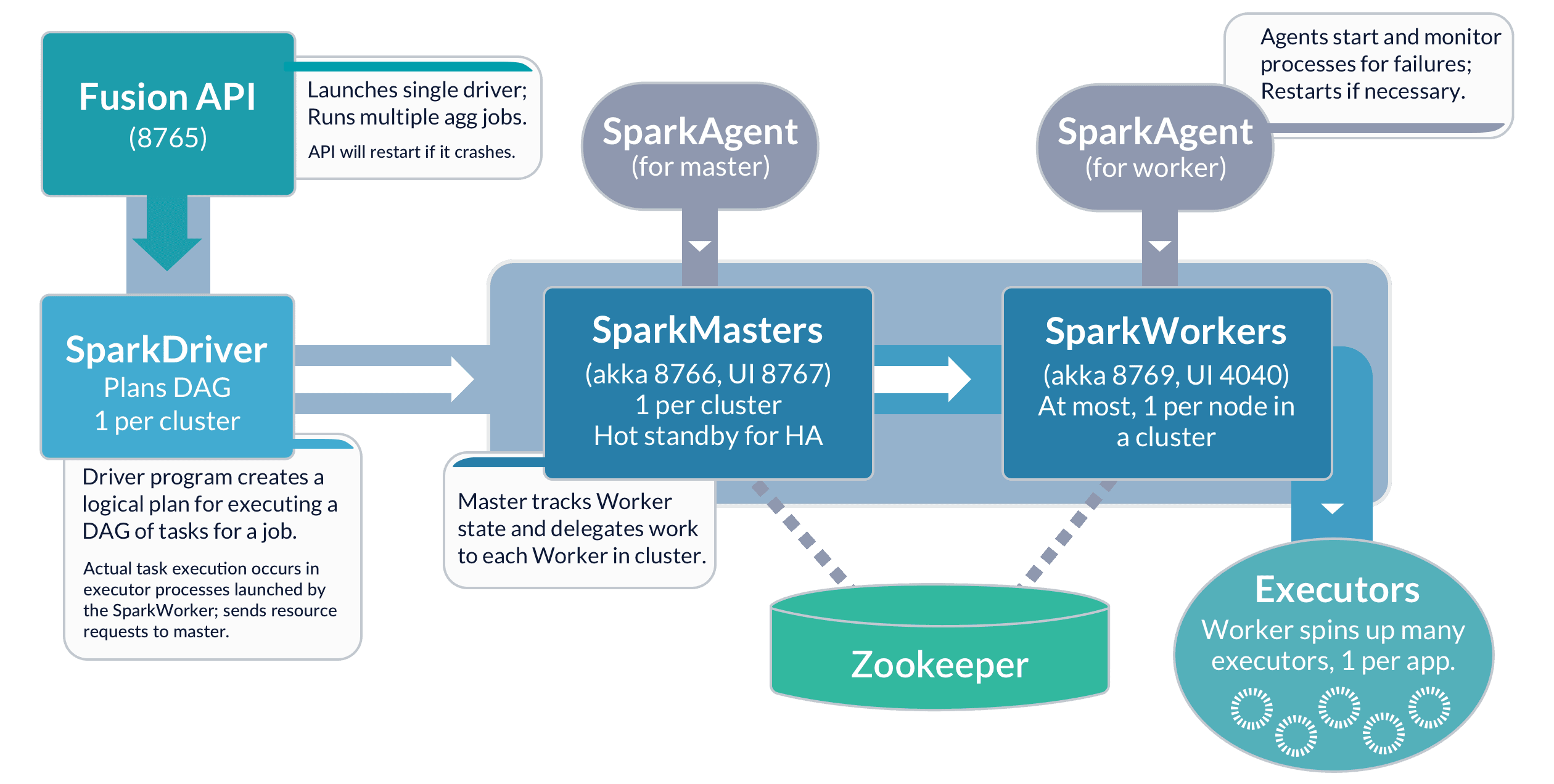
Apache ZooKeeper
Apache ZooKeeper is a distributed configuration service, synchronization service, and naming registry. Fusion uses ZooKeeper to configure and manage all Fusion components in a single Fusion deployment, therefore a ZooKeeper service must always be running as part of the Fusion deployment. For high availability, this should be an external 3-node ZooKeeper cluster. All Fusion Java components communicate with ZooKeeper using the ZooKeeper API. For ZooKeeper installation instructions, see the ZooKeeper documentation. You can find ZooKeeper’s logs athttps://FUSION_HOST:FUSION_PORT/var/log/zookeeper.
ZooKeeper Terminology
- znode. ZooKeeper data is organized into a hierarchal name space of data nodes called znodes.
A znode can have data associated with it as well as child znodes.
The data in a znode is stored in a binary format, but it is possible to import, export, and view this information as JSON data.
Paths to znodes are always expressed as canonical, absolute, slash-separated paths; there are no relative reference. - ephemeral nodes. An ephemeral node is a znode which exists only for the duration of an active session.
When the session ends the znode is deleted. An ephemeral znode cannot have children. - server. A ZooKeeper service consists of one or more machines; each machine is a server which runs in its own JVM and listens on its own set of ports.
For testing, you can run several ZooKeeper servers at once on a single workstation by configuring the ports for each server. - quorum. A quorum is a set of ZooKeeper servers. It must be an odd number. For most deployments, only 3 servers are required.
- client. A client is any host or process which uses a ZooKeeper service.
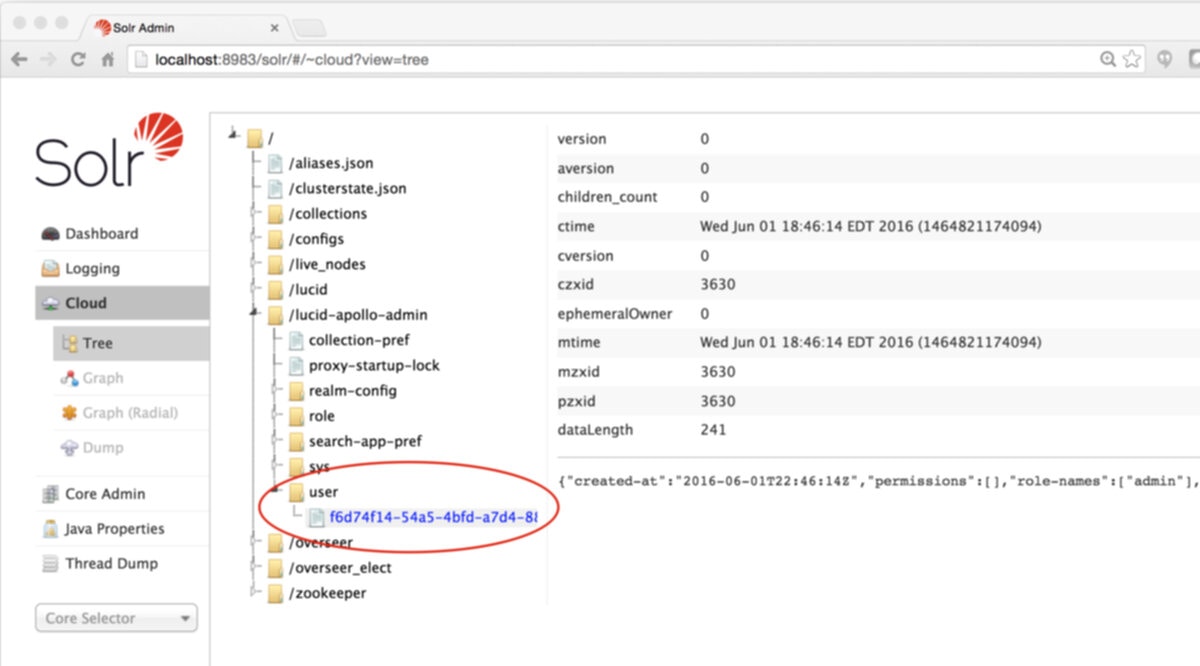
Fusion ZooKeeper Nodes
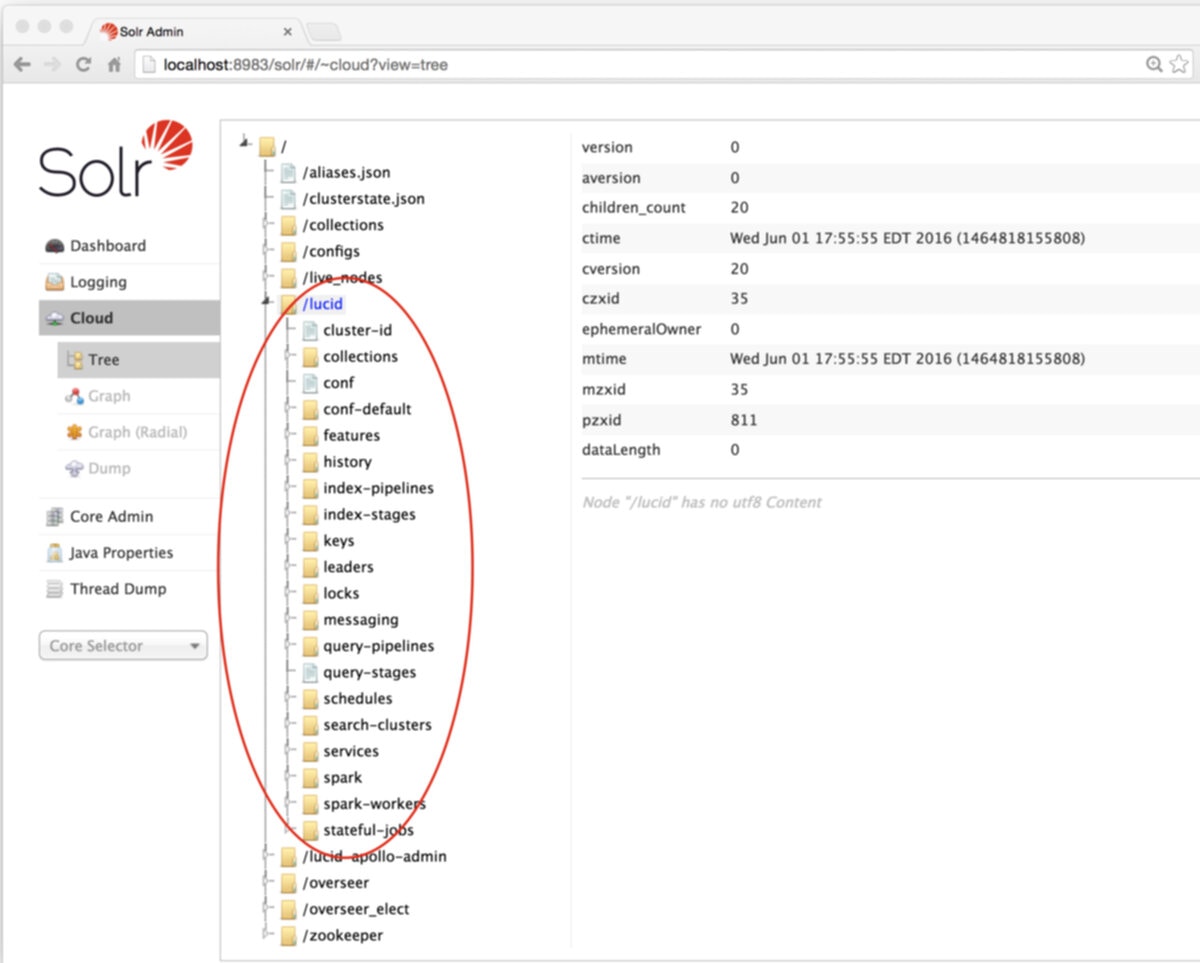
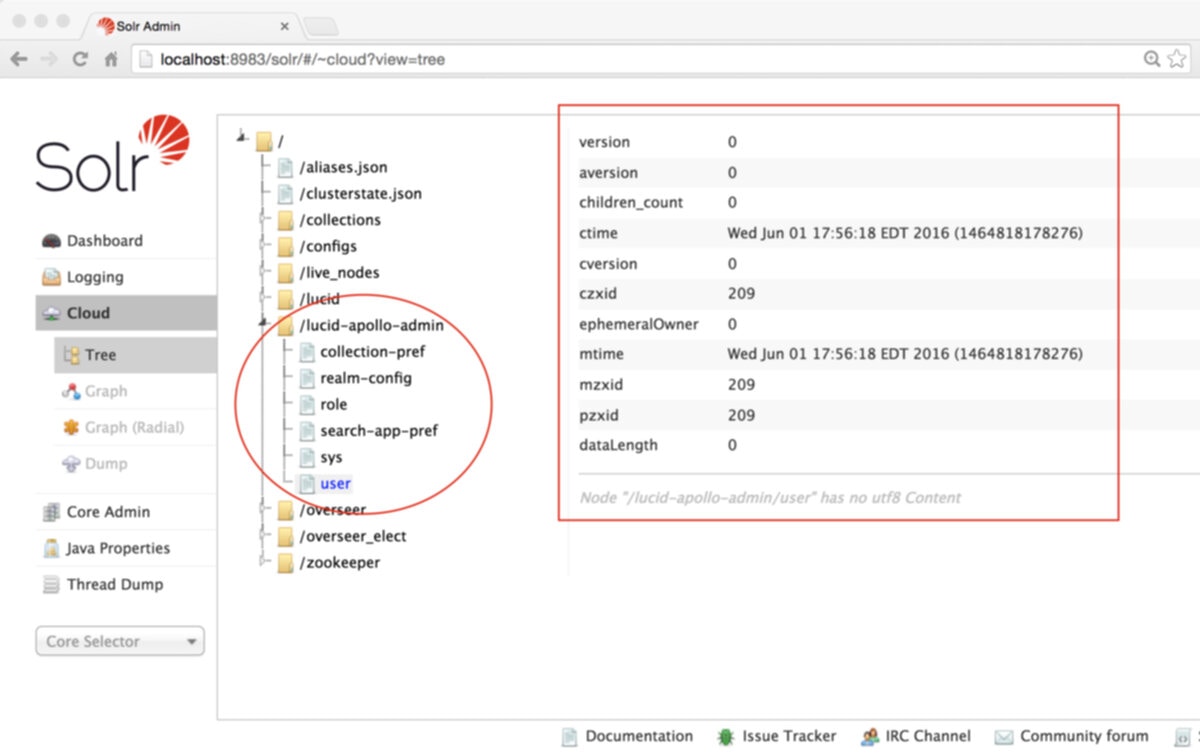
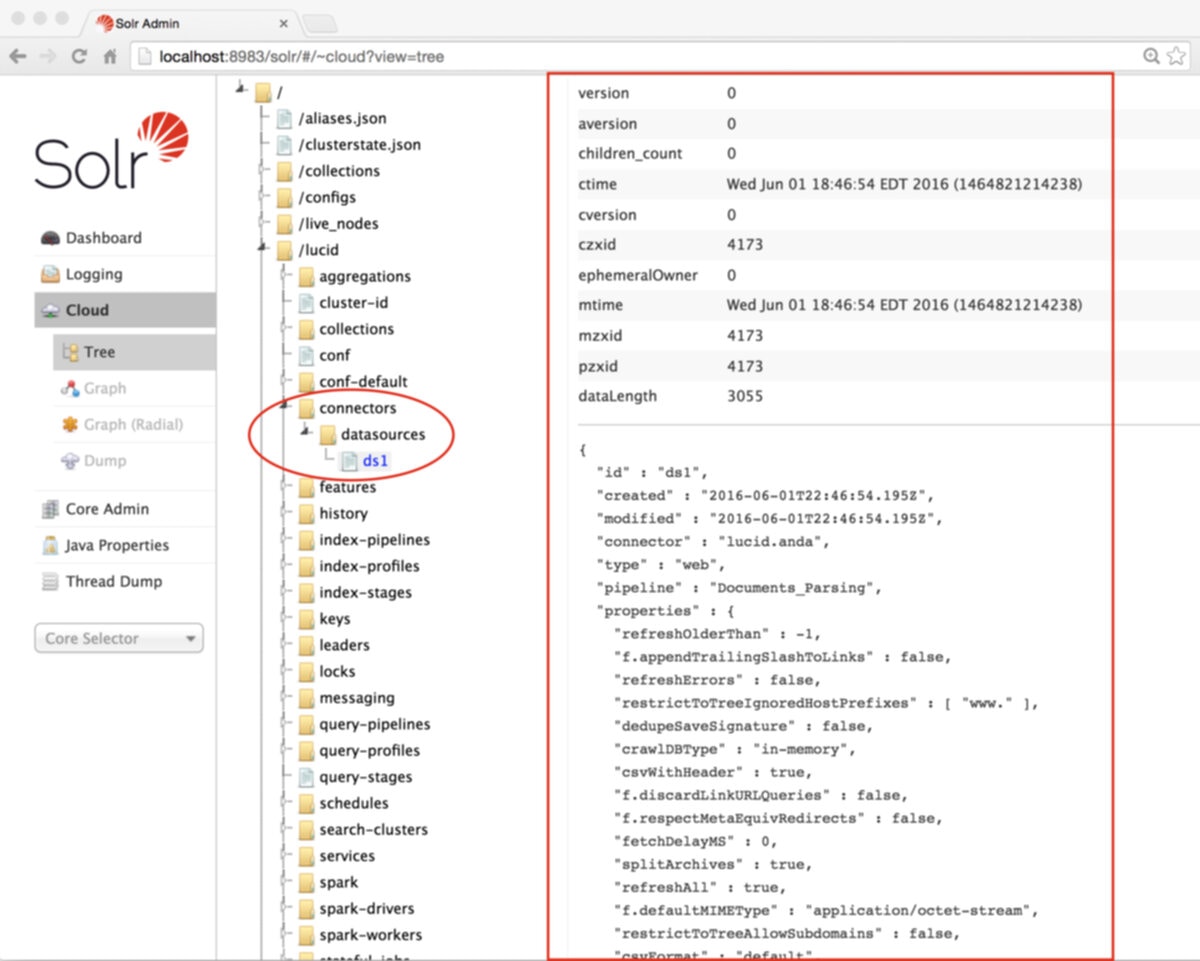
Fusion configuration data is stored in ZooKeeper under two znodes:- Node
lucidstores all application-specific configurations, including collection, datasource, pipeline, signals, aggregations, and associated scheduling, jobs, and metrics. - Node
lucid-apollo-adminstores all access control information, including all users, groups, roles, and realms.
Jetty
Jetty provides Web services for Fusion’s UI, APIs, and Connectors, plus Solr. Each of those components runs inside its own instance of Jetty, using a separate configuration. Configurations for each component are located inhttps://FUSION_HOST:FUSION_PORT/apps/jetty.
Securing Fusion using SSL requires configuring Jetty to use SSL. For example, to secure the UI you need to modify the configuration in https://FUSION_HOST:FUSION_PORT/apps/jetty/admin-ui.
SSL Security (Unix)
SSL Security (Unix)
Fusion’s UI (which is accessed through the Fusion Proxy service) can run over SSL for secure communication with any HTTP client, using the
Java Secure Socket Extension (JSSE) framework. You configure Fusion for SSL by configuring Fusion’s Proxy and UI services.If Fusion is behind a firewall, you can use a self-signed certificate for SSL communication with other hosts in your internal network. Create a keystore for the Fusion Proxy service and load the keystore with the self-signed PKCS #12 certificate.To store certificates, you can use the Java keytool
Key and Certificate Management utility which is a part of the JDK.How to create a keystore and load a self-signed certificateWhere In a production environment, SSL certificates typically originate with certificate signing requests (CSRs) and are signed by a trusted third-party Certificate Authority (CA).The steps here assume that you are the person who will be obtaining the SSL certificate chain and private key files. If you are not that person, contact your system administrator.With the certificate chain and private key as separate files, use the You can only use this alternative if your SSL certificate covers a hostname that can be accessed from the local host. For example, if your certificate only covers
Fusion 4.0.2 or later is required to enable SSL security. Version 4.0.2 fixed a bug in the authentication proxy that incorrectly redirected some requests when SSL is enabled.
Required software
Configuring Fusion for SSL requires the following software:- Java Development Kit. To store certificates, you can use the Java keytool Key and Certificate Management utility which is a part of the JDK. The JDK is also a requirement for Fusion Server.
-
OpenSSL. You might need the
opensslcommand line tool:- If you have the certificate chain and private key as separate files, then you can use the
opensslcommand line tool to create a PKCS #12 file. - If you have an intermediate CA certificate, then you can use it and
opensslto generate the certificate chain and private key files.
- If you have the certificate chain and private key as separate files, then you can use the
Load an SSL certificate into a Fusion keystore
The SSL protocol is based on public-key cryptography where encryption keys come in public key/private key pairs. An SSL certificate is used to verify the authenticity of a particular server. It contains the web site name, contact email address, company information and the public key used to encrypt the communication which is shared with the entities that communicate with the owner of the public/private key pair.The server has a locally-protected private key that is accessible via a JSEE keystore.The keystore maintains both the server certificate and the private key, so that when a server authenticates itself to the client, it uses the private key from its keystore for the initial SSL handshake.Load the certificate into a Fusion keystore. Perform the tasks in the appropriate section:- Self-signed certificate. If Fusion is behind a firewall, you can use a self-signed certificate for SSL communication with other hosts in your internal network. Create a keystore for the Fusion Proxy service and load the keystore with the self-signed PKCS #12 certificate.
- Certificate signed by a certificate authority. In a production environment, SSL certificates typically originate with certificate signing requests (CSRs) and are signed by a trusted third-party Certificate Authority (CA). Create a keystore for the Fusion Proxy service and load the keystore with the PKCS #12 certificate from a CA.
Alternative 1: Self-signed certificate
If you are using a CSR-originated certificate from a trusted certificate authority, proceed to Alternative 2: CA-signed certificate.
-
Set environment variables:
For example, in Fusion 4.1:In Fusion 4.0.x:
-
Create the Fusion Proxy service keystore, generate the key pair and self-signed certificate, and load them into the keystore:
Example command:You must include the qualified domain name and/or the IP address of the Fusion server in the
-ext SANpart of the command. Failure to do so results in SSL validation errors.
ProxyPort is the Fusion Proxy port.Alternative 2: CA-signed certificate
If Fusion is behind a firewall and you are using a self-signed certificate, skip this section. Perform the tasks in Alternative 1: Self-signed certificate.
Preliminary steps
- Obtain a domain from a domain registrar.
- Change the A record of your domain to the public IP address of your web server instance.
Generate SSL certificate files
Use an SSL certificate provider to generate the certificate chain and private key files, or a PKCS #12 certificate, from a trusted CA:- Certificate chain and private key files. In this case, you will need to convert these files into a single certificate file in PKCS #12 format.
- A PKCS #12 certificate. This must contain both the certificate chain and private key. In this case, no conversion is necessary.
- In most cases, you will need to temporarily open ports 80 and 443 in your firewall configuration. The SSL certificate provider must be able to make successful HTTP and HTTPS requests to your server through the Domain Name System (DNS).
- Use an SSL certificate provider to generate the certificate chain (
fullchain.pem) and private key (privkey.pem) files, or the PKCS #12 certificate, from a trusted CA. Steps will vary based on the certificate provider. Contact your certificate provider for details. - Close ports 80 and 443 in your firewall configuration.
- Change the A record of your domain to the public domain-name address of your web server instance.
- If you have certificate chain and private key files, perform the steps in Convert the certificate chain and private key files to a PKCS #12 certificate and Import the PKCS #12 certificate into the Fusion Proxy service keystore.
- If you have a PKCS #12 certificate, perform the steps in Import the PKCS #12 certificate into the Fusion Proxy service keystore.
Convert the certificate chain and private key files to a PKCS #12 certificate
If you have a PKCS #12 certificate, skip this section and proceed to the section Import the PKCS #12 certificate into the Fusion Proxy service keystore.
openssl command line tool in OpenSSL to create a PKCS #12 certificate.Do not enter a blank password.
Create the Fusion Proxy service keystore and import the PKCS #12 certificate
Use the Java keytool Key and Certificate Management utility to create a keystore for the Fusion Proxy service ($FUSION_HOME/apps/jetty/proxy/etc/keystore) and import the PKCS #12 certificate file. Fusion uses this certificate to perform SSL.- To create the keystore and import the PKCS #12 certificate:
-
Use the keytool
importcommand to create a JSSE keystore. -
(Optional) If desired, delete the PKCS #12 certificate file that resides outside of the Fusion Proxy service keystore (the one you created from the certificate chain and private key files, or obtained from a trusted CA.
Enable HTTPS in the Fusion Proxy service
Before beginning these steps, load an SSL certificate into a Fusion keystore.How to enable HTTPS in the Fusion Proxy service:-
(Only for Fusion Server 4.0.x and 4.1.0) Prevent the
start.jarprogram from downloading a default keystore file, which is not needed. Edit$FUSION_HOME/apps/jetty/home/modules/ssl.mod. Comment out the indicated line using#. Change:To: -
Set environment variables:
For example, in Fusion 4.1:In Fusion 4.0:
-
Add HTTPS protocol support to the Jetty TLS (SSL) connector:
Example output:
-
Get the obfuscated version of your keystore password:
Replace
PASSWORDwith the password you used for the keystore. If the password contains special characters, URL encode them. Example output: -
Edit the file
$FUSION_HOME/apps/jetty/proxy/start.ini:-
Include obfuscated passwords by adding these properties to the end of the file:
-
Use the OBF-encrypted password from step 4 (including the
OBF:string) as the value for all three of the properties.
For example: -
Set the local SSL port by adding the
jetty.ssl.portproperty to the end of the file, and providing the port number. For example: -
Save the file
$FUSION_HOME/apps/jetty/proxy/start.ini.
-
Include obfuscated passwords by adding these properties to the end of the file:
Restart Fusion and test access through HTTPS
-
Restart all Fusion services:
HTTPS should now be enabled in the Fusion Proxy service.
-
Sign in to the Fusion UI. Specify the HTTPS URL scheme and SSL port, for example,
https://search.mycorp:8443.
Disable HTTP access to the Fusion Proxy service
Disable HTTP access. You have a choice. Perform the tasks in the appropriate section:- Disable HTTP access on the firewall or load balancer - This is the preferred approach.
- Disable listening for HTTP requests in the Fusion Proxy service
Alternative 1: Disable HTTP access on the firewall or load balancer
Disable HTTP access to the Fusion Proxy service on the firewall or load balancer:- Disallow all requests for port 8764 from the outside world. Only
localhostshould be able to communicate with Fusion on the non-SSL port 8764. Block all other requestors. - If you are using a firewall or load balancer in front of Fusion, use it to redirect all HTTP requests to use HTTPS instead. For example, Apache would redirect all incoming HTTP traffic to HTTPS.
Alternative 2: Disable listening for HTTP requests in the Fusion Proxy service
Ideally, you should disable HTTP access using the firewall or load balancer. Follow the steps in this section only if disabling HTTP access on the firewall or load balancer is not feasible.
https://fusion.com, then your local machine must be able to access Fusion from that exact host. If necessary, change the hosts file so that this can work.How to disable HTTP- Edit
/opt/lucidworks/fusion/latest.x/apps/jetty/proxy/start.d/http.ini.-
Change this line:
To:
- Save the file.
-
Change this line:
- Edit the Fusion configuration file,
/opt/lucidworks/fusion/latest.x/conf/fusion.cors(fusion.propertiesin Fusion 4.x).-
Ensure that the Agent JVM uses the Fusion Proxy service’s keystore by adding this to the end of the file:
Replace
PASSWORDwith your Fusion keystore password. -
Uncomment the
default.addressand change it to the hostname of the server that is validated by your SSL certificate.
If the hostname saved indefault.addressis not validated by your SSL certificate, then the Fusion Proxy service will not start, because the agent’s liveness detector will not be able to access the HTTPS port to determine whether Fusion is running.For example, if your SSL certificate’s validated hostname isIf you self-signed the certificate, then thedefault.addressmust match the hostname you specified while signing the certificate. Failure to do this will result in the Fusion Proxy service not starting after you have disabled HTTP.search.mycorp, then change:To: -
Change the
proxy.portto the SSL port you chose. -
Uncomment
proxy.ssland change its value totrue. Change:To:
-
Ensure that the Agent JVM uses the Fusion Proxy service’s keystore by adding this to the end of the file:
References and tutorials
- Transport Layer Security (Wikipedia)
- Public Key Certificate (Wikipedia)
- OpenSSL Cookbook (free ebook)
- OpenSSL Command Line Utilities (OpenSSL wiki)
- Java Tutorials: Generating and Verifying Certificates
- IBM developerWorks: What is the JSSE all about?
SSL Security (Windows)
SSL Security (Windows)
Fusion’s UI (which is accessed through the Fusion Proxy service) can run over SSL for secure communication with any HTTP client, using the
Java Secure Socket Extension (JSSE) framework. You configure Fusion for SSL by configuring Fusion’s Proxy and UI services.If Fusion is behind a firewall, you can use a self-signed certificate for SSL communication with other hosts in your internal network. Create a keystore for the Fusion Proxy service and load the keystore with the self-signed PKCS #12 certificate.To store certificates, you can use the Java keytool
Key and Certificate Management utility which is a part of the JDK.How to create a keystore and load a self-signed certificateWhere In a production environment, SSL certificates typically originate with certificate signing requests (CSRs) and are signed by a trusted third-party Certificate Authority (CA).The steps here assume that you are the person who will be obtaining the SSL certificate chain and private key files. If you are not that person, contact your system administrator.How to create a PKCS #12 certificateWith the certificate chain and private key as separate files, use the You can only use this alternative if your SSL certificate covers a hostname that can be accessed from the local host. For example, if your certificate only covers
Fusion 4.0.2 or later is required to enable SSL security. Version 4.0.2 fixed a bug in the authentication proxy that incorrectly redirected some requests when SSL is enabled.
Required software
Configuring Fusion for SSL requires the following software:- Java Development Kit. To store certificates, you can use the Java keytool Key and Certificate Management utility which is a part of the JDK. The JDK is also a requirement for Fusion Server.
-
OpenSSL. You might need the
opensslcommand line tool:- If you have the certificate chain and private key as separate files, then you can use the
opensslcommand line tool to create a PKCS #12 file. - If you have an intermediate CA certificate, then you can use it and
opensslto generate the certificate chain and private key files.
- If you have the certificate chain and private key as separate files, then you can use the
Overview of procedure
How to configure Fusion for SSL:- Load an SSL certificate into a Fusion keystore.
- Enable SSL in the Fusion Proxy service.
- Restart Fusion and test access through HTTPS.
- Disable HTTP access to the Fusion Proxy service.
Load an SSL certificate into a Fusion keystore
The SSL protocol is based on public-key cryptography where encryption keys come in public key/private key pairs. An SSL certificate is used to verify the authenticity of a particular server. It contains the web site name, contact email address, company information and the public key used to encrypt the communication which is shared with the entities that communicate with the owner of the public/private key pair.The server has a locally-protected private key that is accessible via a JSEE keystore.The keystore maintains both the server certificate and the private key, so that when a server authenticates itself to the client, it uses the private key from its keystore for the initial SSL handshake.Load the certificate into a Fusion keystore. Perform the tasks in the appropriate section:- Self-signed certificate. If Fusion is behind a firewall, you can use a self-signed certificate for SSL communication with other hosts in your internal network. Create a keystore for the Fusion Proxy service and load the keystore with the self-signed PKCS #12 certificate.
- Certificate signed by a certificate authority. In a production environment, SSL certificates typically originate with certificate signing requests (CSRs) and are signed by a trusted third-party Certificate Authority (CA). Create a keystore for the Fusion Proxy service and load the keystore with the PKCS #12 certificate from a CA.
Alternative 1: Self-signed certificate
If you are using a CSR-originated certificate from a trusted certificate authority, proceed to Alternative 2: CA-signed certificate.
-
Set environment variables:
-
Create the Fusion Proxy service keystore, generate the key pair and self-signed certificate, and load them into the keystore:
Example command:You must include the qualified domain name and/or the IP address of the Fusion server in the
-ext SANpart of the command. Failure to do so results in SSL validation errors.The resulting certificate enables validated SSL transport to these hosts:
ProxyPort is the Fusion Proxy port.Alternative 2: CA-signed certificate
If Fusion is behind a firewall and you are using a self-signed certificate, skip this section. Perform the tasks in Alternative 1: Self-signed certificate.
Preliminary steps
- Obtain a domain from a domain registrar.
- Change the A record of your domain to the public IP address of your web server instance.
Generate SSL certificate files
Use an SSL certificate provider to generate the certificate chain and private key files, or a PKCS #12 certificate, from a trusted CA:- Certificate chain and private key files. In this case, you will need to convert these files into a single certificate file in PKCS #12 format.
- A PKCS #12 certificate that contains both the certificate chain and private key. In this case, no conversion is necessary.
- In most cases, you will need to temporarily open ports 80 and 443 in your firewall configuration. The SSL certificate provider must be able to make successful HTTP and HTTPS requests to your server through the Domain Name System (DNS).
- Use an SSL certificate provider to generate the certificate chain (
fullchain.pem) and private key (privkey.pem) files, or the PKCS #12 certificate, from a trusted CA. Steps will vary based on the certificate provider. Contact your certificate provider for details. - Close ports 80 and 443 in your firewall configuration.
- Change the A record of your domain to the public domain-name address of your web server instance.
- If you have certificate chain and private key files, perform the steps in Convert the certificate chain and private key files to a PKCS #12 certificate and Import the PKCS #12 certificate into the Fusion Proxy service keystore.
- If you have a PKCS #12 certificate, perform the steps in Import the PKCS #12 certificate into the Fusion Proxy service keystore.
Convert the certificate chain and private key files to a PKCS #12 certificate
If you have a PKCS #12 certificate, skip this section and proceed to the section Import the PKCS #12 certificate into the Fusion Proxy service keystore.
openssl command line tool in OpenSSL to create a PKCS #12 certificate.Do not enter a blank password.
Create the Fusion Proxy service keystore and import the PKCS #12 certificate
Use the Java keytool Key and Certificate Management utility to create a keystore for the Fusion Proxy service (%FUSION_HOME%\apps\jetty\proxy\etc\keystore) and import the PKCS #12 certificate file. Fusion uses this certificate to perform SSL.If you are starting with a certificate file in PFX format (file extension
.pfx), that format is now identical to PKCS #12 format.-
To create the keystore and import the PKCS #12 certificate:
-
Use the keytool
importcommand to create a JSSE keystore. -
(Optional) If desired, delete the PKCS #12 certificate file that resides outside of the Fusion Proxy service keystore (the one you created from the certificate chain and private key files, or obtained from a trusted CA.
Enable HTTPS in the Fusion Proxy service
Before beginning these steps, load an SSL certificate into a Fusion keystore.How to enable HTTPS in the Fusion Proxy service:-
Set environment variables:
-
Add HTTPS protocol support to the Jetty TLS (SSL) connector:
Example output:
-
Get the obfuscated version of your keystore password:
Replace
PASSWORDwith the password you used for the keystore. If the password contains special characters, URL encode them. Example output: -
Edit the file
%FUSION_HOME%\apps\jetty\proxy\start.ini:-
Include obfuscated passwords by adding these properties to the end of the file:
jetty.sslContext.keyStorePasswordjetty.sslContext.keyManagerPasswordjetty.sslContext.trustStorePassword
-
Use the OBF-encrypted password from step 4 (including the
OBF:string) as the value for all three of the properties.
For example: -
Set the local SSL port by adding the
jetty.ssl.portproperty to the end of the file, and providing the port number. For example: -
Save the file
%FUSION_HOME%\apps\jetty\proxy\start.ini.
-
Include obfuscated passwords by adding these properties to the end of the file:
Restart Fusion and test access through HTTPS
-
Restart all Fusion services:
HTTPS should now be enabled in the Fusion Proxy service.
-
Sign in to the Fusion UI. Specify the HTTPS URL scheme and SSL port, for example,
https://search.mycorp:8443.
Disable HTTP access to the Fusion Proxy service
Disable HTTP access. You have a choice. Perform the tasks in the appropriate section:- Disable HTTP access on the firewall or load balancer - This is the preferred approach.
- Disable listening for HTTP requests in the Fusion Proxy service
Alternative 1: Disable HTTP access on the firewall or load balancer
Disable HTTP access to the Fusion Proxy service on the firewall or load balancer:- Disallow all requests for port 8764 from the outside world. Only
localhostshould be able to communicate with Fusion on the non-SSL port 8764. Block all other requestors. - If you are using a firewall or load balancer in front of Fusion, use it to redirect all HTTP requests to use HTTPS instead. For example, Apache would redirect all incoming HTTP traffic to HTTPS.
Alternative 2: Disable listening for HTTP requests in the Fusion Proxy service
Ideally, you should disable HTTP access using the firewall or load balancer. Follow the steps in this section only if disabling HTTP access on the firewall or load balancer is not feasible.
https://fusion.com, then your local machine must be able to access Fusion from that exact host. If necessary, change the hosts file so that this can work.How to disable HTTP- Edit
\lucidworks\fusion{backslash}latest.x\apps\jetty\proxy\start.d\http.ini.-
Change this line:
To:
- Save the file.
-
Change this line:
- Edit the Fusion configuration file,
\lucidworks\fusion{backslash}latest.x\conf\fusion.cors(fusion.propertiesin Fusion 4.x).-
Ensure that the Agent JVM uses the Fusion Proxy service’s keystore by adding this to the end of the file:
Replace
PASSWORDwith your Fusion keystore password. -
Uncomment the
default.addressand change it to the hostname of the server that is validated by your SSL certificate.
If the hostname saved indefault.addressis not validated by your SSL certificate, then the Fusion Proxy service will not start, because the agent’s liveness detector will not be able to access the HTTPS port to determine whether Fusion is running.For example, if your SSL certificate’s validated hostname isIf you self-signed the certificate, then thedefault.addressmust match the hostname you specified while signing the certificate. Failure to do this will result in the Fusion Proxy service not starting after you have disabled HTTP.search.mycorp, then change:To: -
Change the
proxy.portto the SSL port you chose. For example, change:To: -
Uncomment
proxy.ssland change its value totrue. Change:To:
-
Ensure that the Agent JVM uses the Fusion Proxy service’s keystore by adding this to the end of the file:
References and tutorials
- Transport Layer Security (Wikipedia)
- Public Key Certificate (Wikipedia)
- OpenSSL Cookbook (free ebook)
- OpenSSL Command Line Utilities (OpenSSL wiki)
- Java Tutorials: Generating and Verifying Certificates
- IBM developerWorks: What is the JSSE all about?
https://FUSION_HOST:FUSION_PORT/var/log/uihttps://FUSION_HOST:FUSION_PORT/var/log/apihttps://FUSION_HOST:FUSION_PORT/var/log/connectorshttps://FUSION_HOST:FUSION_PORT/var/log/solr
Learn more
Receive Technical Support
Receive Technical Support
When you need personalized, expert assistance, the Lucidworks technical support team is available 24/7.Before you open a support case, see the instructions below to learn how to gather data that the technical support team can use to evaluate your issue and provide a solution.Once you have obtained the relevant data from Fusion, Submit a request.The DevOps Center provides an easy way to export logs for the timeframe that pertains to your issue.How to export data from the DevOps CenterTo open a support case, complete the following:
Support Portal Overview
The course for Support Portal Overview focuses on how to navigate the support portal, open a support ticket, identify the severity of your issue, and escalate issues as needed.
Exporting log files from the DevOps Center
This section only applies to Fusion 4.2 through 5.5.
- In the Fusion UI, navigate to System > DevOps Center > Log Viewer.
- Select the time period that is relevant to the incident you are interested in.
Log files will be exported according to the tab you are viewing.\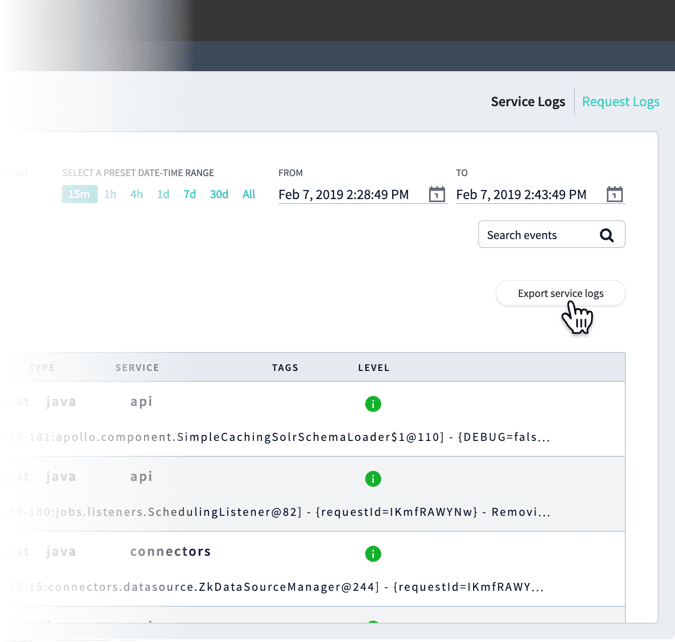
.csvfile containing the logs (shown here with example timestamps):serviceLogs[2019-02-07T22:28:49.000Z-2019-02-07T22:43:49.695Z].csvrequestLogs[2019-02-07T22:28:49.000Z-2019-02-07T22:43:49.695Z].csv
Finding log files in the filesystem
Log files are located in thehttps://FUSION_HOST:FUSION_PORT/var/log directory. Generally, the log files below are the most useful in diagnosing an issue:-
API logs
https://FUSION_HOST:FUSION_PORT/var/log/api/api.logandhttps://FUSION_HOST:FUSION_PORT/var/log/api/gc_<timestamp>.log.0.current -
Connectors logs
https://FUSION_HOST:FUSION_PORT/var/log/connectors-classic/connectors-classic.logandhttps://FUSION_HOST:FUSION_PORT/var/log/connectors-rpc/connectors-rpc.log
gc logs from the https://FUSION_HOST:FUSION_PORT/var/log directory.Opening a support case
Lucidworks provides technical support to customers 24 hours a day, 7 days a week, with unlimited incidents. Once you have obtained the relevant data from Fusion as described above, you can open a support case.For detailed information about submitting a support case, see Lucidworks Customer Center Training.
- Access the Lucidworks Submit a request page.
You can also select Contact Support from any page on the Lucidworks support site. - Enter information in the following fields:
- Your email address
- Subject
- Description
- In the Severity field, select the appropriate severity value for your issue according to the guidelines below.
Severity Time Definition Example S1 1 Hour Severe commercial impact on Customer ‘s business which either makes the system inoperable or prevents content discovery. Production search is down. S2 12 Hours Significant commercial impact on Customer ‘s business which makes one or more critical areas of functionality inoperable. Search performance has slowed down to a crawl. S3 24 Hours Moderate commercial impact on Customer ‘s business which makes one or more non-critical areas of functionality inoperable. Slight increase in query time. S4 48 Hours No commercial impact on Customer ‘s business. How to implement a certain search feature. - Select values in the following fields:
- Product Line
- Fusion Version (optional)
- Solr Version (optional)
- In the Environment field, select one of the following:
- Dev/Sandbox/POC
- Performance
- Production
- QA/UAT
- Staging
- In the Attachments field, drag files or click to add log files.
- When you have attached all pertinent data, click Submit.