- Index billions of records of any type, from any data source
- Process thousands of queries per second from thousands of concurrent users
- Conduct full-text search using standard SQL capabilities and powerful analytics
Key Concepts
Fusion’s ecosystem allows you to manage and access your data in an intuitive fashion. See Concepts for more information.Apache Solr
Solr is the fast open source search platform built on Apache Lucene™ that provides scalable indexing and search, as well as faceting, hit highlighting, and advanced analysis/tokenization capabilities. Solr and Lucene are managed by the Apache Software Foundation. For more information, see the Solr Reference Guide for your Fusion release.Apache Spark
Apache Spark is an open source cluster-computing framework that serves as a fast and general execution engine for large-scale data processing jobs that can be decomposed into stepwise tasks, which are distributed across a cluster of networked computers. Spark improves on previous MapReduce implementations by using resilient distributed datasets (RDDs), a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner. See Apache Spark for more information.Connectors
Connectors are the out-of-the-box components for pulling your data into Fusion. Lucidworks provides a wide variety of connectors, each specialized for a particular data type. When you add a datasource to a collection, you specify the connector to use for ingesting data. Connectors are distributed separately from Fusion Server. For complete information, see Fusion Connectors. Fusion offers dozens of connectors so you can access your data from a large variety of sources. To learn more about Fusion connectors, see connectors concepts or the connectors section.Pipelines
Pipelines dictate how data flows through Fusion and becomes accessible by a search application. Fusion has two types of pipelines: index pipelines and query pipelines. Index pipelines ingest data, indexes it, and stores it in a format that is optimized for searching. Query pipelines filter, transform, and augment Solr queries and responses in order to return all and only the most relevant search results.How-to Information
Want to start right away?Getting Started with Fusion Server
Getting Started with Fusion Server
This tutorial takes you from installation to application-ready search data in four easy parts, using a MovieLens dataset.
- Part 1: Run Fusion and Create an App Download, install Fusion, and run Fusion, then create a Movie Search app.
- Part 2: Get Data In Use the Index Workbench to configure an index pipeline, preview the results, and get data into the Movie Search app in a format that is useful for search.
- Part 3: Get Data Out Use Query Workbench to get data out of the Movie Search app, explore the role of query pipeline stages, configure faceting, and preview search results.
- Part 4: Improve Relevancy Use signals and boosting to make search results more relevant.
Upgrade to Fusion 4.x
Upgrade to Fusion 4.x
When you have a Fusion-based search application running, at some point it might be necessary to upgrade to a later version of Fusion. We provide a migrator tool to simplify the upgrade process.The migrator transfers over most of the objects that make up your search application, all configurations and customizations for your application, and all data in collections in the application.These upgrade sequences are supported.
In some cases, manual steps are required for objects that the migrator cannot handle automatically. We give you instructions and guidance about what might be required. You should also review the log of the upgrade in
/opt/fusion/x.y.z/var/upgrade/tmp/migrator.log (on Unix) or C:\lucidworks\var\fusion\x.y.z\upgrade\tmp\migrator.log (on Windows). The x.y.z directory is for the Fusion version that you are migrating from.Key points
Following are some key points about upgrading Fusion:- Migration involves down time. The upgrade process involves multiple starts and stops of Fusion services. Please plan accordingly, especially in terms of disabling external load balancers or monitors that might react adversely to the starts and stops.
- Current deployment is preserved. Upgrades preserve the current Fusion deployment, copying information over from the current deployment to the new one. This provides a rapid roll-back option if you encounter problems during the upgrade process.
- If the upgrade fails. If an upgrade fails, there is a procedure for dealing with that.
Supported upgrade sequences
Only specific version-to-version upgrade sequences are supported. Some upgrades require multiple steps.
Upgrades to the current version
- 3.1.x to 4.2.y. From any 3.1.x version to 4.2.6 SP1 (one step, using the migrator)
- 4.0.x to 4.2.y. From any 4.0.x version to 4.2.6 SP1 (one step, using the migrator)
- 4.1.x to 4.2.y. From any 4.1.x version to 4.2.6 SP1 (one step, using the migrator)
Upgrades to prior versions
Using the migrator:- 3.1.x to 4.0.y. From 3.1.5 directly to 4.0.2 (one step) For more information, see Upgrade Fusion 3.1.x to 4.0.y.
- 4.0.x to 4.0.y. From 4.0.0 or 4.0.1 to 4.0.2 (one step) For more information, see Upgrade Fusion Server 4.0.x to 4.0.y.
- 3.1.x to 4.1.y. From any 3.1.x version to 4.1.3 (one step, using the migrator) For more information, see Upgrade Fusion Server 3.1.x to 4.1.y.
- 4.0.x to 4.1.y. From 4.0.2 to 4.1.3 (one step, using the migrator) For more information, see Upgrade Fusion Server 4.0.x to 4.1.y.
- 4.1.x to 4.1.y. From 4.1.0 to 4.1.3 (one step, using the migrator) For more information, see Upgrade Fusion Server 4.1.x to 4.1.y.
Example
For example, to upgrade from Fusion 3.0.1 to Fusion Server 4.2.5, you would perform the following upgrades (both of them using the migrator):- Upgrade from Fusion 3.0.1 to Fusion 3.1.5
- Upgrade from Fusion 3.1.5 to Fusion Server 4.2.5
Per-version instruction sets
To upgrade to a later version of Fusion from an existing installation requires transferring over all configurations and data from your existing Fusion installation to the new version.How to upgrade from Fusion 3.1.x to Fusion Server 4.2.yPerform the steps in this article:Upgrade from Fusion Server 3.1.x to 4.2.y - Run a migrator to upgrade from Fusion Server 3.1.x to 4.2.y.How to upgrade from Fusion 4.0.x to Fusion Server 4.2.yPerform the steps in this article:Upgrade from Fusion Server 4.0.x to 4.2.y - Run a migrator to upgrade from Fusion Server 4.0.x to 4.2.y.How to upgrade from Fusion 4.1.x to Fusion Server 4.2.yPerform the steps in this article:Upgrade from Fusion Server 4.1.x to 4.2.y - Run a migrator to upgrade from Fusion Server 4.1.x to 4.2.y.How to upgrade from Fusion 4.2.x to Fusion Server 4.2.yPerform the steps in this article:Upgrade from Fusion Server 4.2.x to 4.2.y - Run a migrator to upgrade from Fusion Server 4.2.x to 4.2.y.Important Reference Information
Our reference section includes information on Fusion’s API, index pipelines stages, query pipelines stages, connections, and more. See Reference for complete reference information.Learn more
Getting Started with Fusion Server
Getting Started with Fusion Server
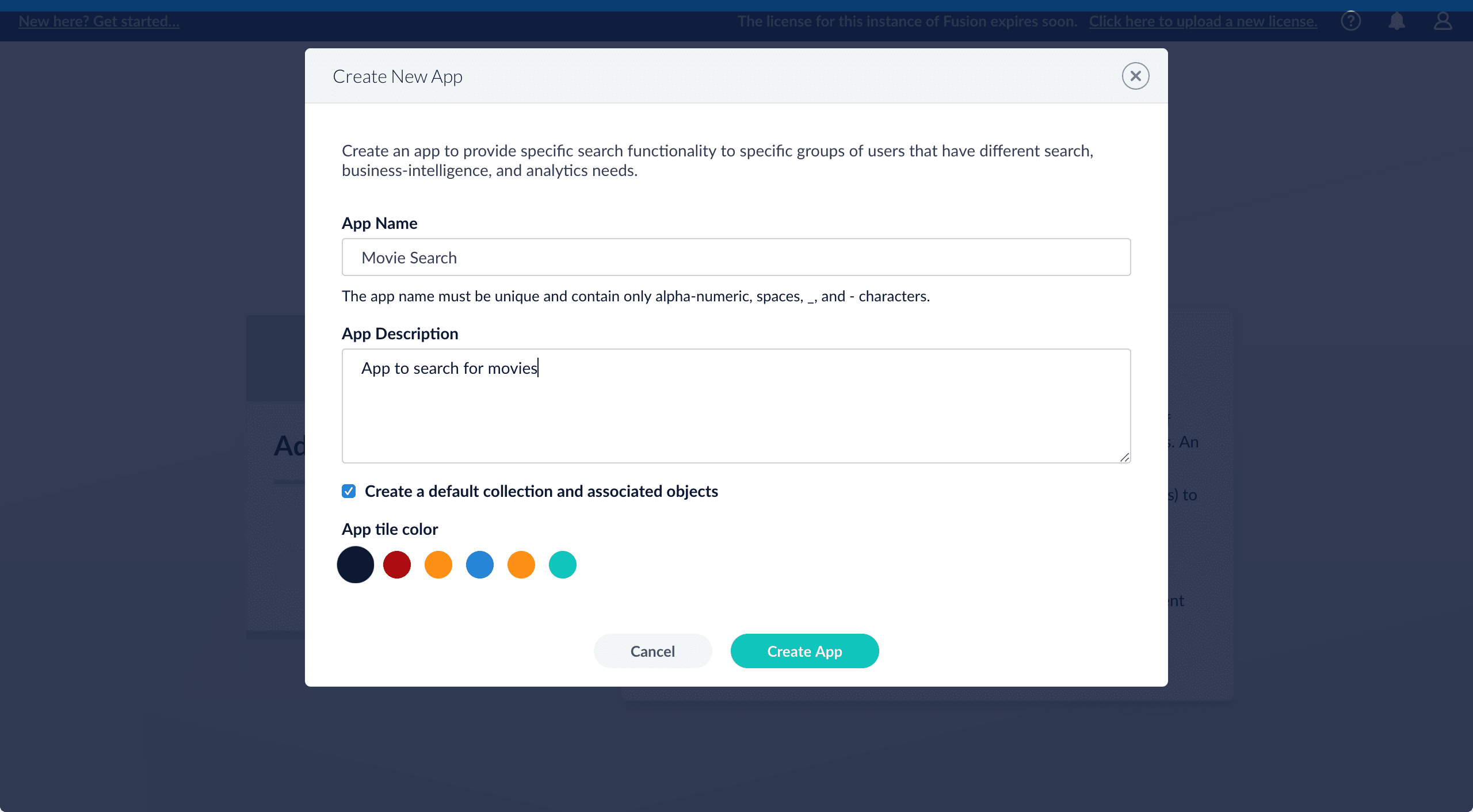
Create an app
Create a Movie Search app. An app is a set of Fusion objects that performs a specific searching task (such as searching for movies).- In the Fusion launcher, click Create new app.
-
In the App Name field, enter
Movie Search. -
In the App Description field, enter
App to search for movies. -
Click Create App.

Getting Started with Fusion Server
Getting Started with Fusion Server
You used Index Workbench to get data into Fusion by previewing the dataset, configuring the index pipeline, and then indexing the data.Now you will explore Query Workbench and learn how to configure Fusion’s output (search results), including faceting. Facets are the ubiquitous, dynamic lists of categories or features offered as filters within a search results page.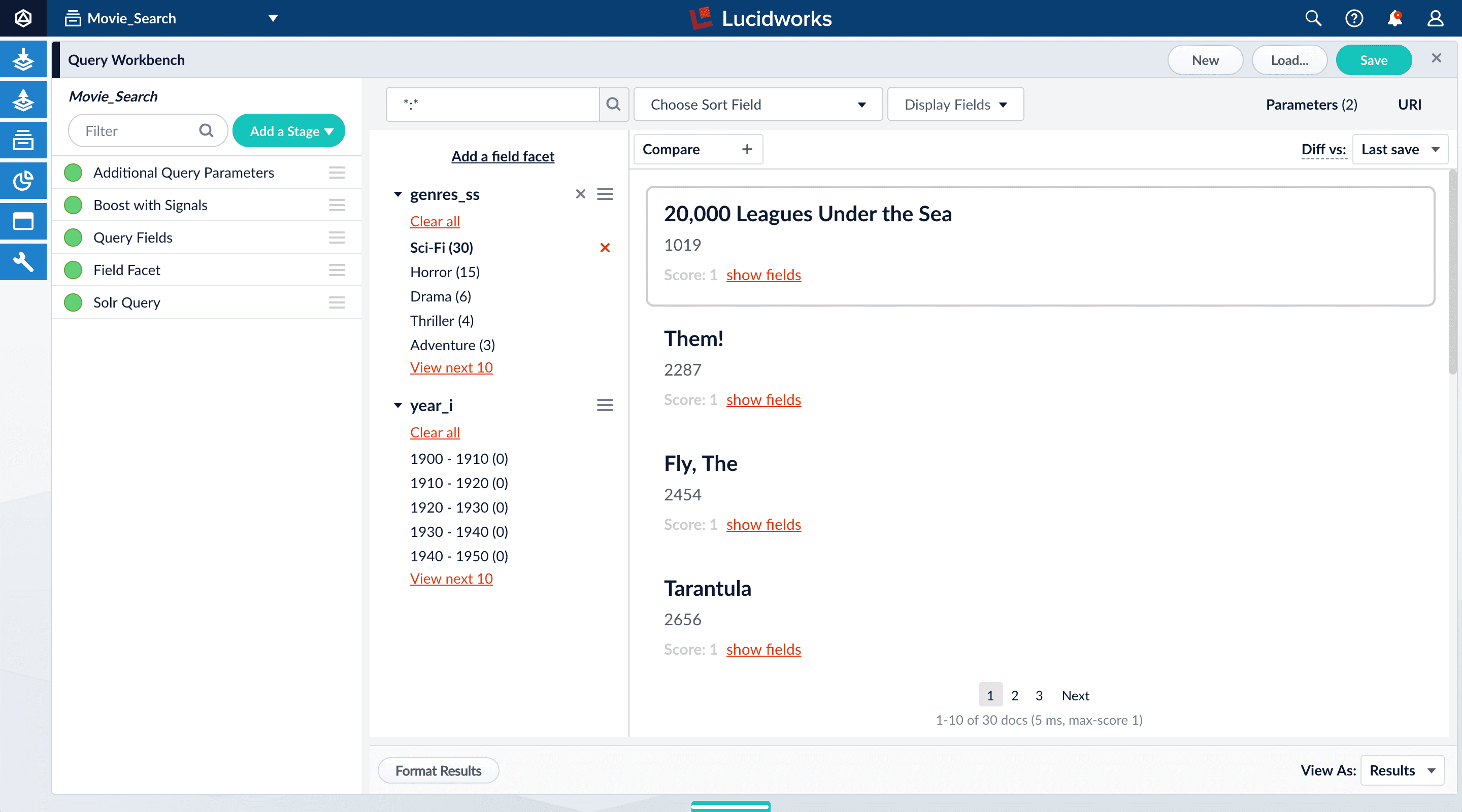
Before you begin
The dataset has three fields that users of your search application might find relevant:genres_ss. A list of one or more genre labelstitle_txt. The name of the movieyear_i. The movie’s year of release
-
Fields with the suffix
_ss(multi-valued string fields) contain one or more strings values. String fields require an exact match between the query string and the string value stored in that field. -
Fields with the suffix
_txt(text fields) contain text. Text fields allow for free text search over the field contents. For example, because the movie titles are stored in a text field, a search on the word “Star” will match movies titled “Star”, “A Star is Born”, all movies in the Star Wars and Star Trek franchises, as well as “Dark Star”, “Lone Star”, and “Star Kid”. -
Fields with the suffix
_i(point integer fields) contain integer values. Numeric fields allow range matches as well as exact matches, and point integer fields allow efficient comparisons between the field’s values and the search criteria.
Explore search results
Query Workbench lets you interactively configure a query pipeline while previewing the search results it produces. A query pipeline converts a free text query submitted to your search application into a structured query for Solr.- Log in to Fusion.
- Click the Movie Search app. The Fusion workspace appears.
-
Open Query Workbench. Navigate to Querying
 > Query Workbench.
> Query Workbench.
Perform a search
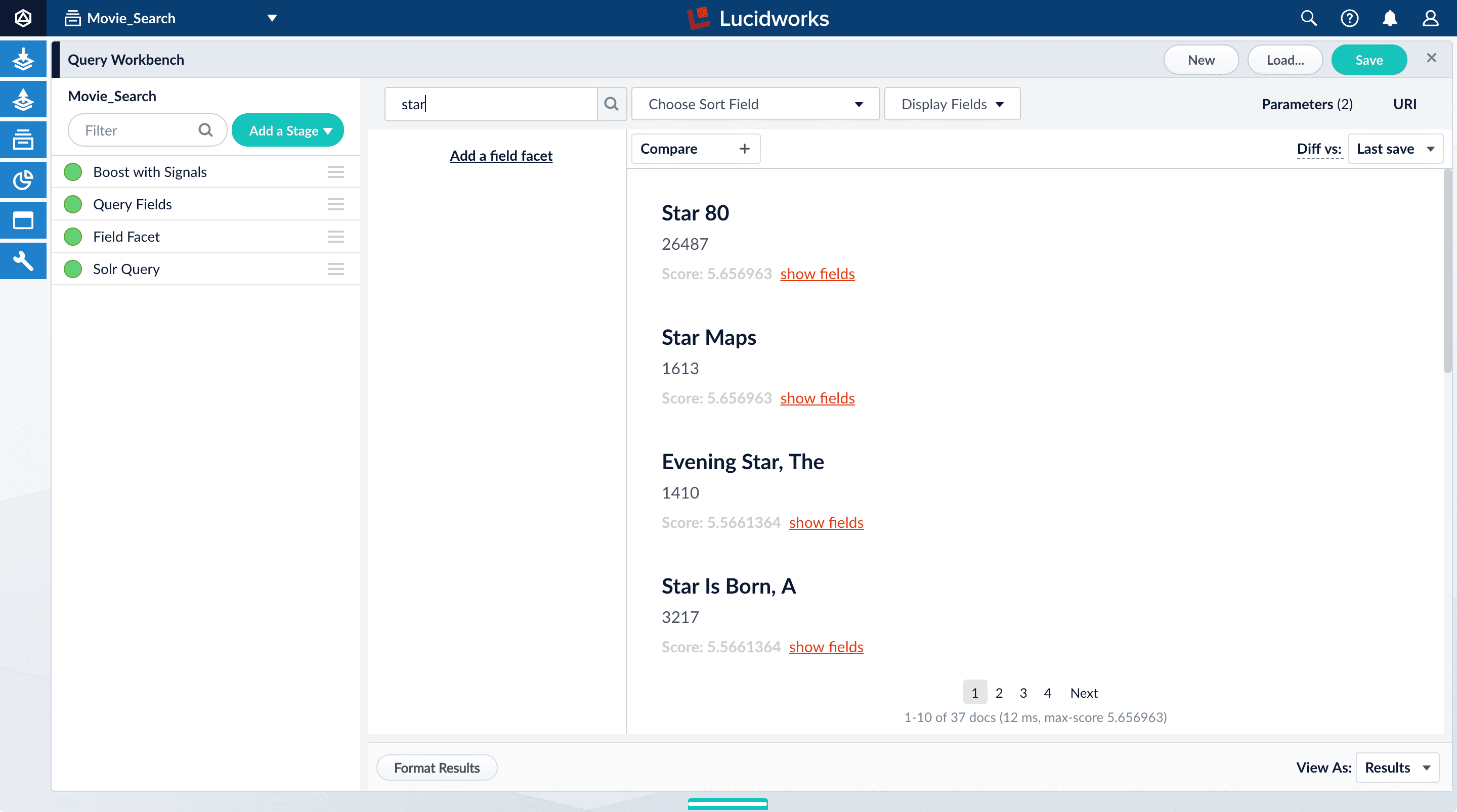
The default search is the wildcard search (\*:*), which returns all documents in the collection. You will enter a different search query to get started with facet configuration.-
In the search box, enter the query string
star, and then press Enter or click Search .
This search returns all movies that have the word “star” in the title.
.
This search returns all movies that have the word “star” in the title.
movie-search.
To see more of the default output, you can perform other searches if you like.- In the search box, enter the query string
\*:*to return all documents, and then press Enter or click Search .
Explore the role of query pipeline stages
A default query pipeline consists of the stages below.In Fusion 4.2+, some of these support Fusion AI features for advanced relevancy tuning, which you can read about separately.In this tutorial, we will configure a couple of the basic stages:- Boost with Signals. Use signals data to boost relevant documents.
- Query Fields. Specify the set of fields over which to search. We will configure this stage later in this tutorial.
- Field Facet. Specify the fields to use for faceting. We will configure this stage, too, for basic faceting and range faceting.
- Text Tagger. Look for known phrases, synonyms, misspellings, and so on, that can be used to improve the query with query rewriting.
- Apply Rules. Modify the query using business rules, if any are triggered.
- Solr Query. Perform the query and return the results. This is the only stage that is always required to perform a query and receive results.
- Modify Response with Rules. Modify Solr’s response using business rules, if any are triggered.
-
Turn off the Solr Query stage by clicking on the green circle on the left. The circle will change to white and Solr Query will dim to indicate the Solr Query stage is off.
-
Turn on the Solr Query stage and turn all other stages off.
- Turn all stages on.
Configure faceting
Facets are the ubiquitous, dynamic lists of categories or features offered as filters within a search results page. Facets provide a simple way for users to explore and filter their search results without having to construct complicated queries. You configure facets as a part of configuring a query pipeline.The data you indexed in Part 1 has two fields that are natural choices for faceting:genres_ss and year_i. For example, a user could search for science fiction of the 1950s in just a few clicks.Configure basic faceting for genres
Thegenres_ss field is ready for faceting as-is.-
Click Add a field facet and select the
genres_ssfield.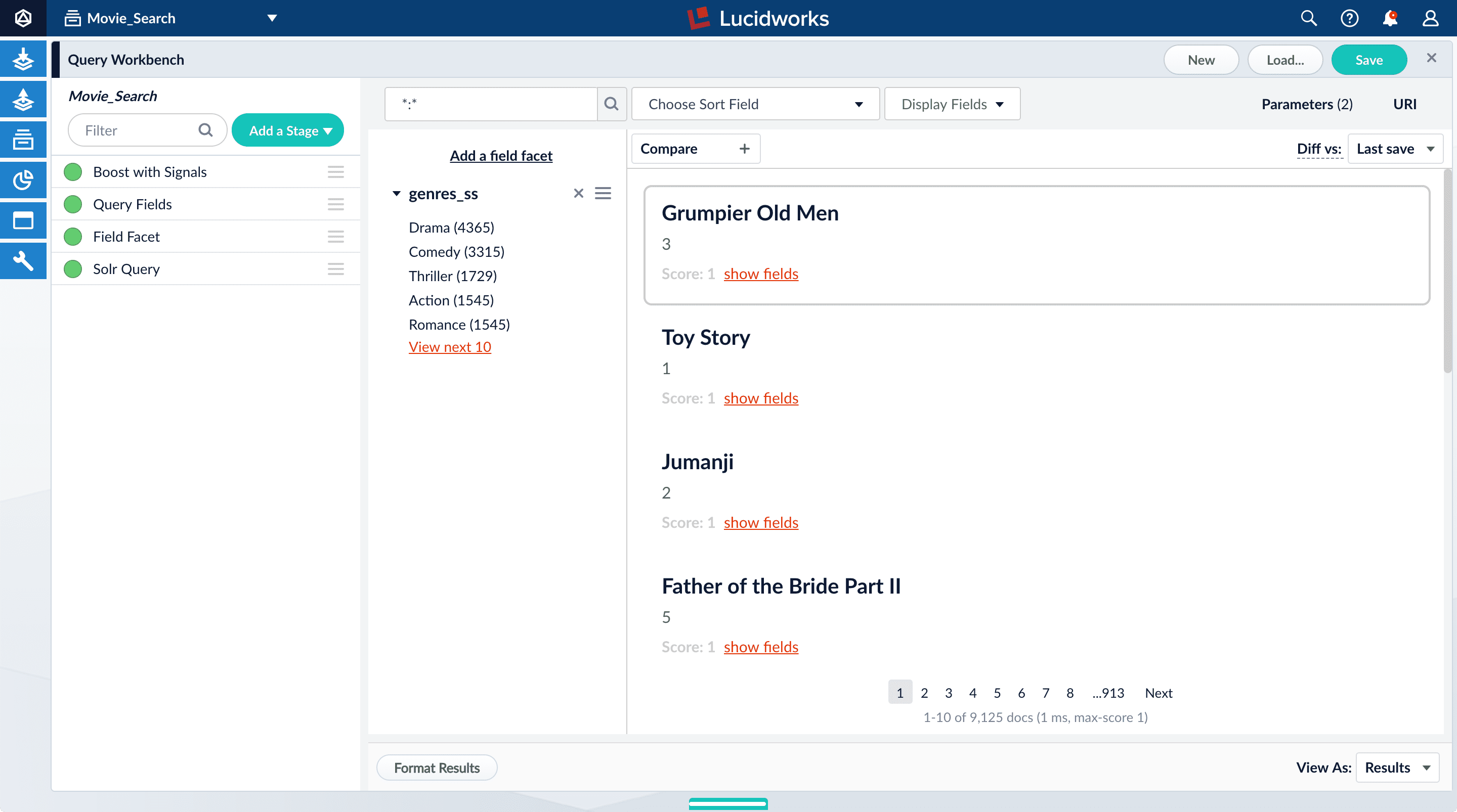
-
Click Sci-Fi to select movies that have the value
Sci-Fiforgenres_ss: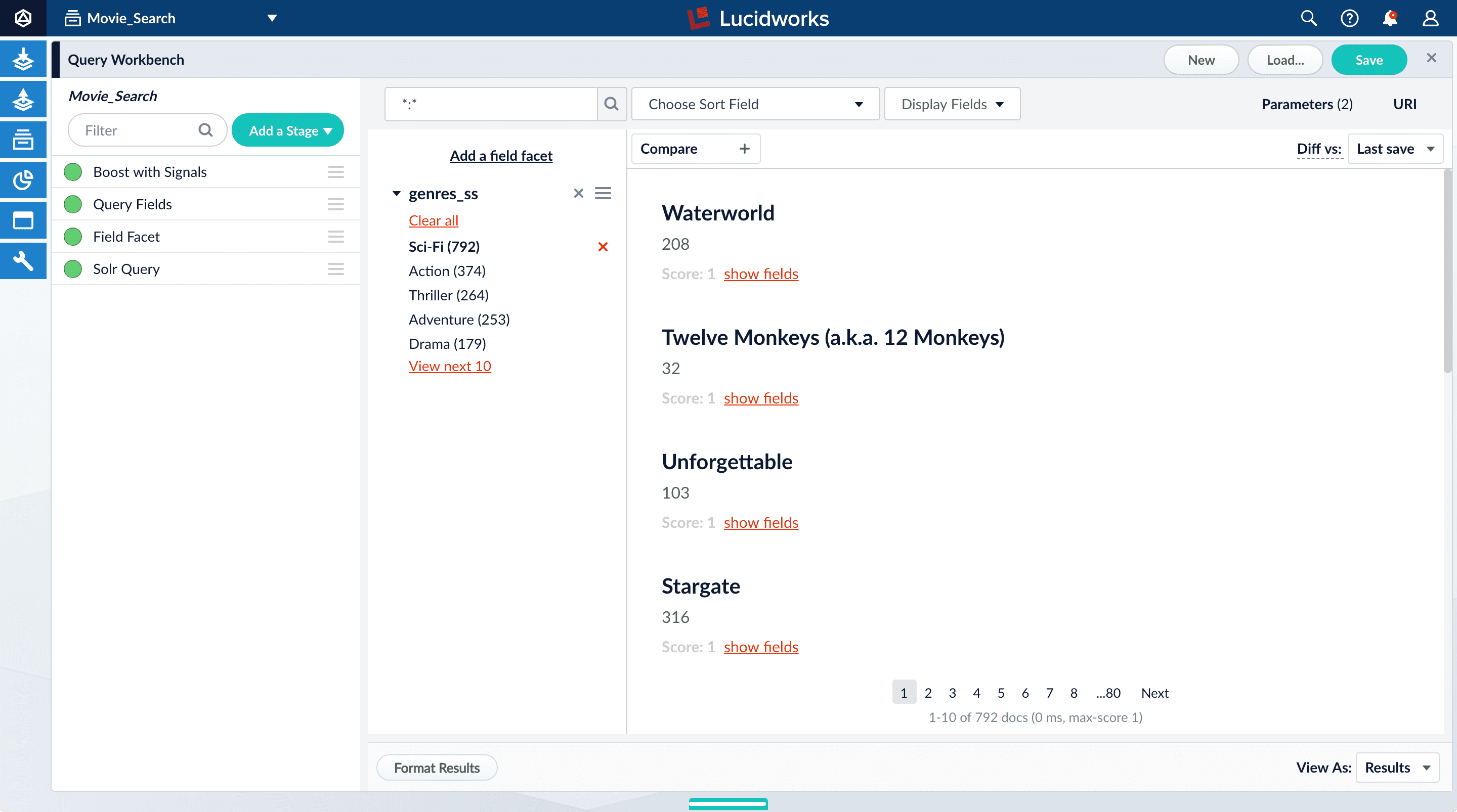
- Under the field facet genres_ss, click Clear all.
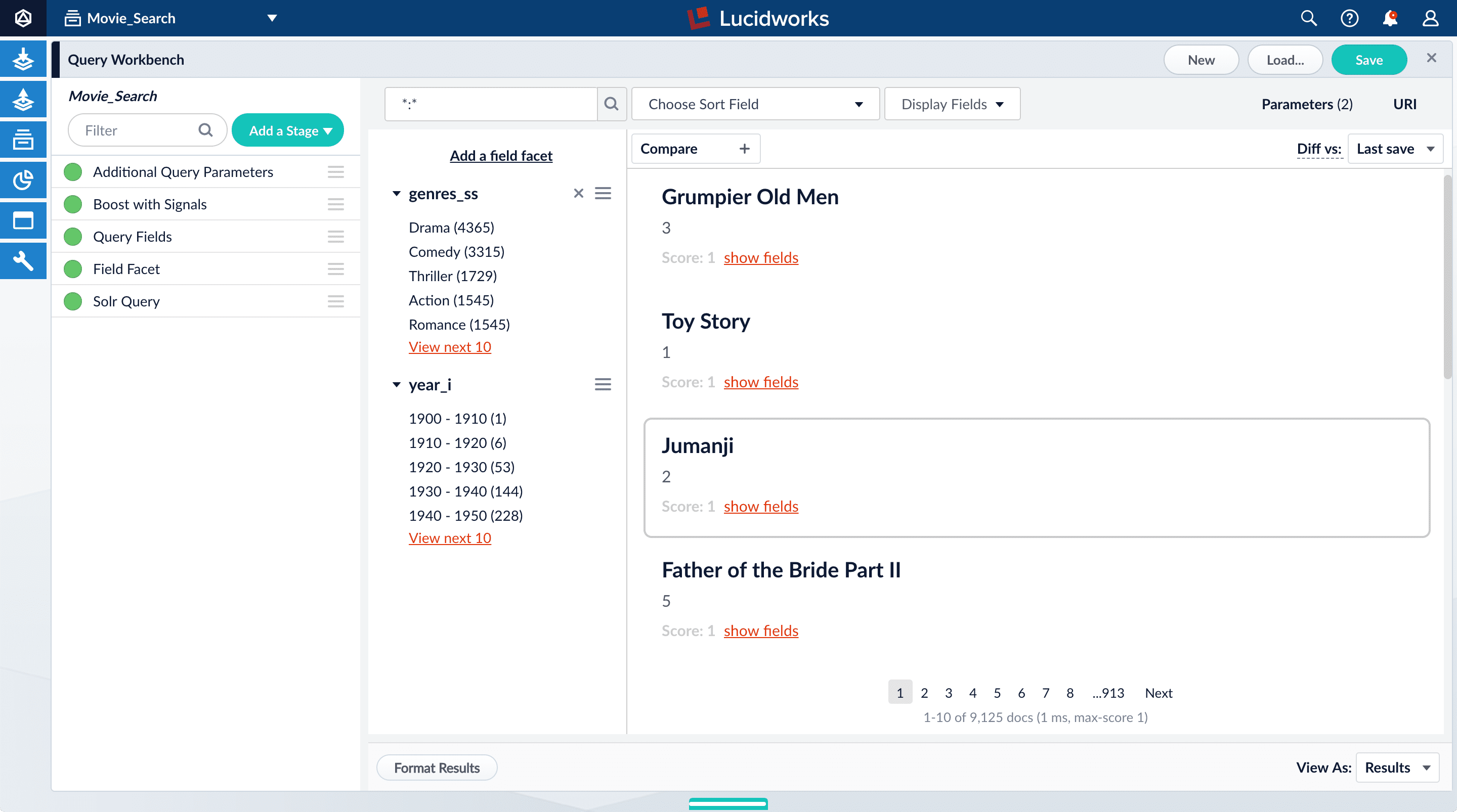
Configure range faceting for years
If you were to just configure faceting for theyear_i field as you did above for the genres_ss field, you would get one facet per year, which is not very useful.But the year_i field will be more usable if you configure range faceting. Range faceting is a way of grouping values together so that the user can select a value range instead of one specific value. For example, range facets are commonly used with pricing (100) or ratings (4 stars or higher). Here, we group years by decade.Range faceting requires sending an additional query parameter to Fusion’s Solr core. You can configure this with the Additional Query Parameters stage. In this case, you will use several of Solr’s range facet query parameters.Use the Additional Query Parameters stage to configure range faceting for the year_i field:- Click Add a stage.
-
Scroll down under Advanced and select Additional Query Parameters.
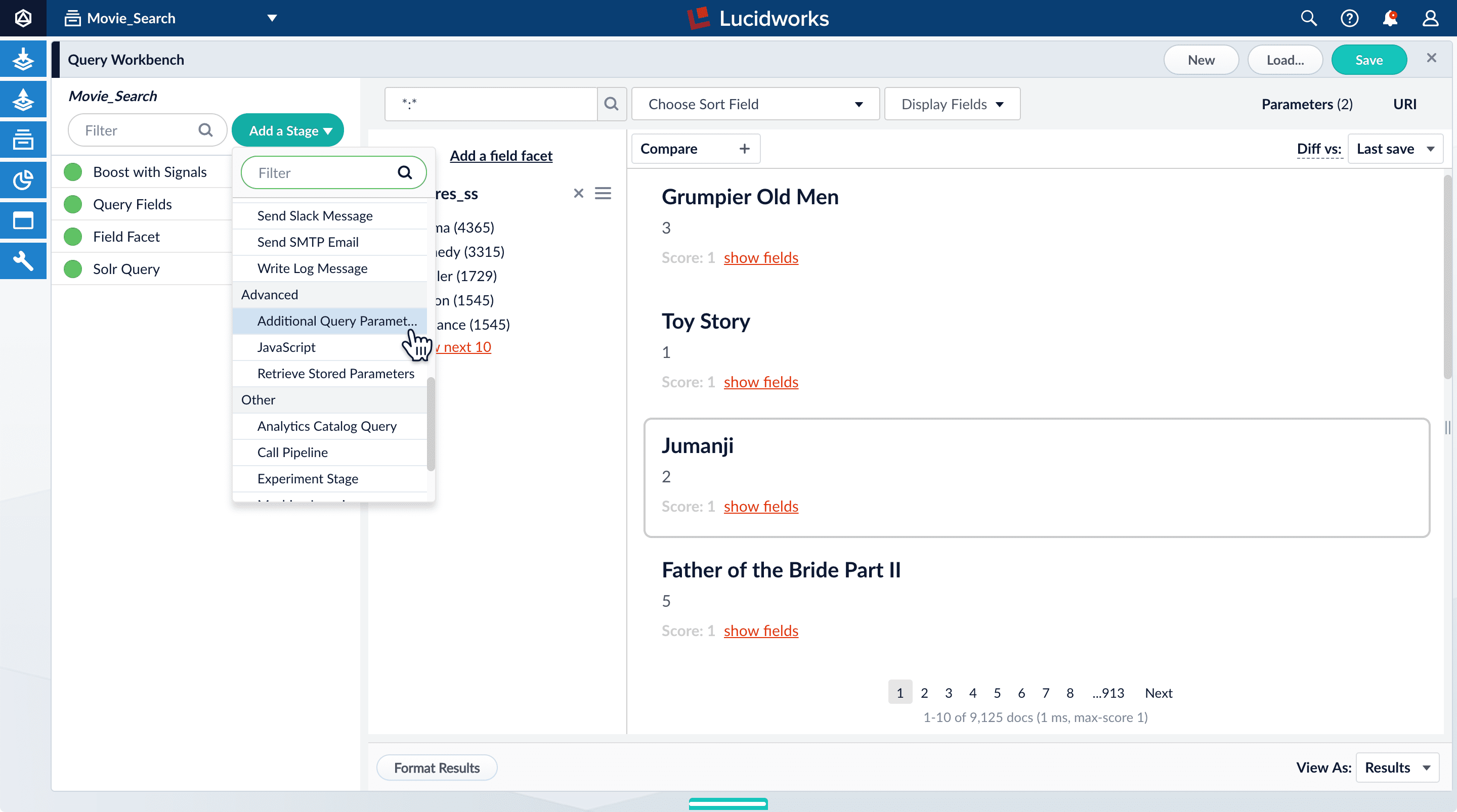
-
Under Parameters and Values, add the following parameter names and values:
In this case, you do not need to modify the Update Policy field; the default value of
Parameter Name Parameter Value facet.rangeyear_ifacet.range.start1900facet.range.end2020facet.range.gap10facet.range.includeouterappendis fine. -
Click Apply, and then Cancel (which just closes the configuration panel for the Additional Query Parameters stage).
The year facets are now grouped by decade:
Configure query fields
In this section, you will see why it is useful to specify which fields Fusion should use to match a query.-
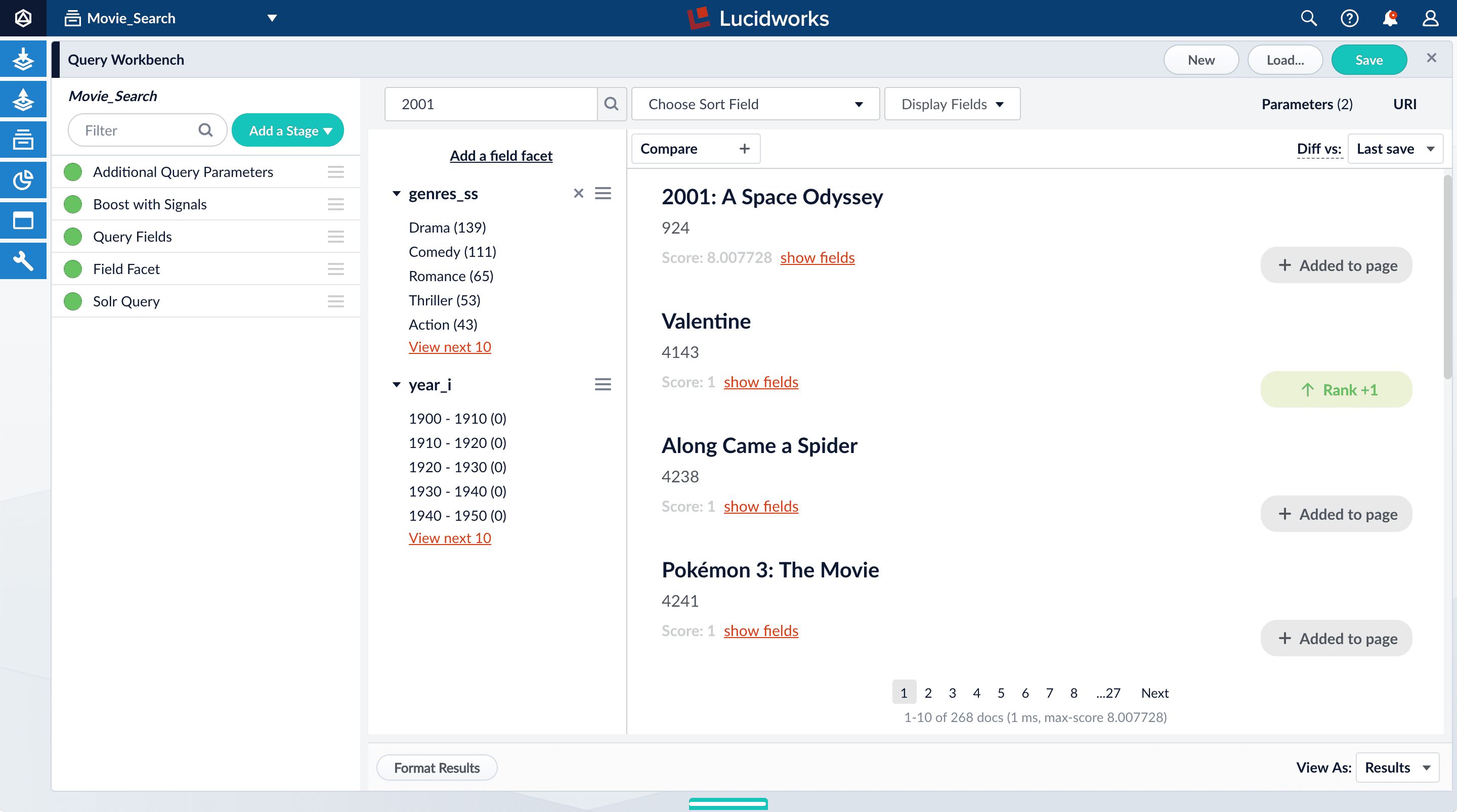
Search for “2001”.
The results are not what an end user might expect:
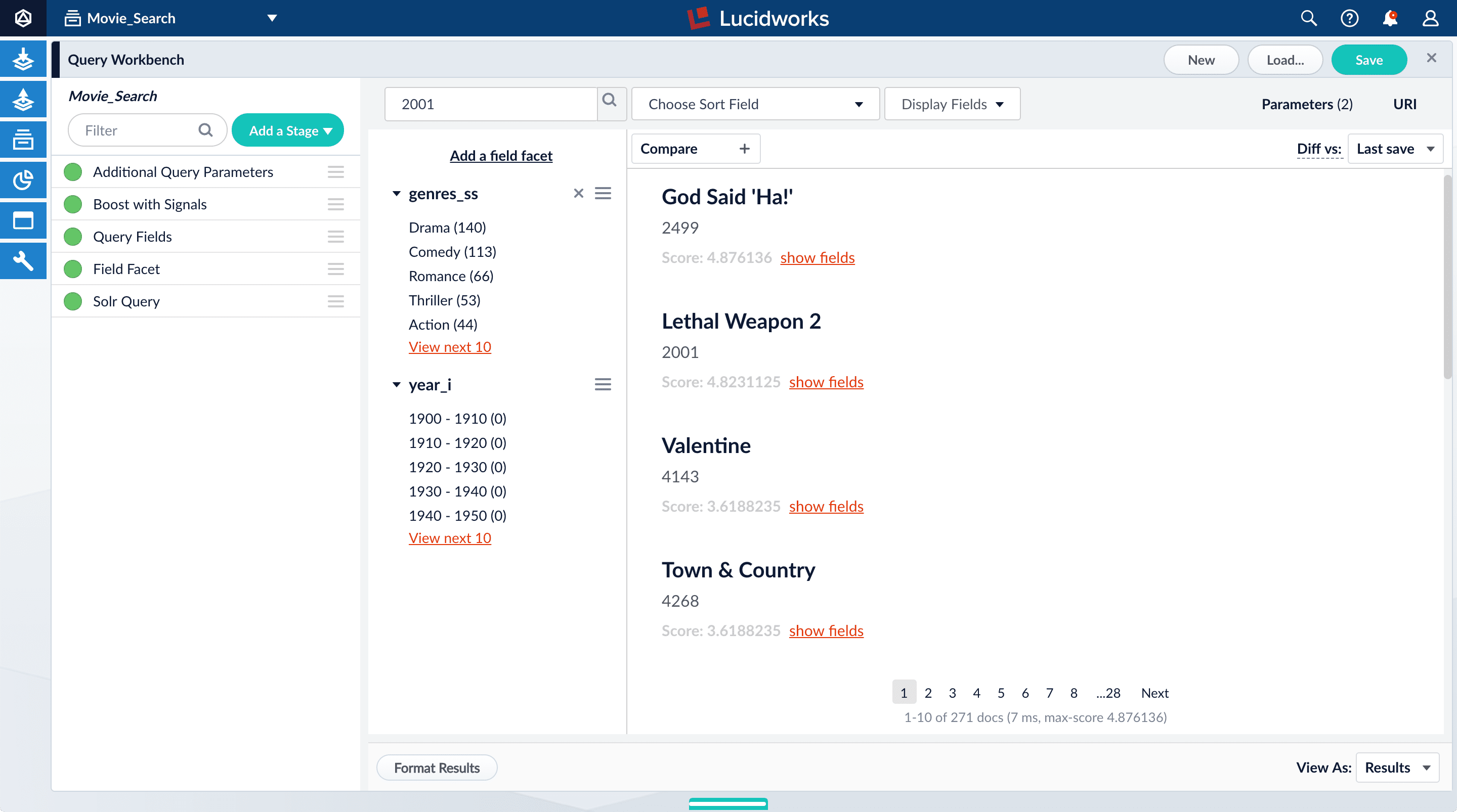
-
Under one of the movies listed, click show fields.
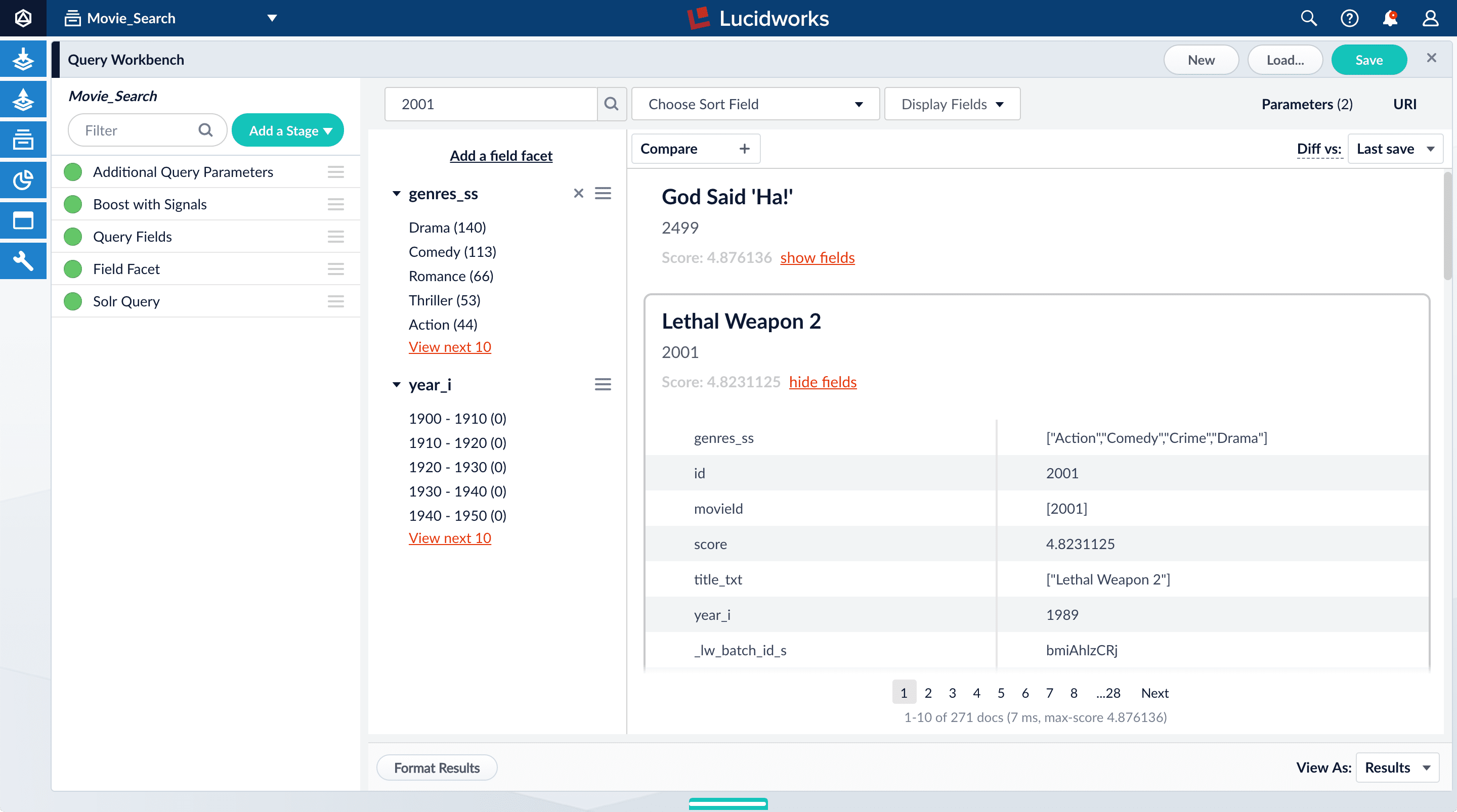
idfield, but users do not care about this field. You will use the Query Fields stage to specify the fields that users really care about. - Below the name for the movie you selected, click hide fields.
- Click the Query Fields stage of the query pipeline. The Query Fields configuration panel appears.
-
Under Search Fields, click Add
 .
.
-
Enter
title_txt. -
Click Add again.
-
Enter
year_i. -
Click Apply, and then Cancel (which just closes the configuration panel for the Query Fields stage).
Now movies with ‘2001’ in their title rise to the top of your search results, followed by films made in the year 2001:
Save the query pipeline configuration
- In the upper right, click Save. The Save Pipeline window appears. By default, you will overwrite the default query pipeline for this datasource.
- Click Save pipeline.
Getting Started with Fusion Server
Getting Started with Fusion Server
Signals are events that can be aggregated and used for automatic boosting or recommendations, which are ways of making search results more relevant.As an example of boosting, the most popular search results for certain queries can be boosted so that they appear first (or at least nearer the top) when other users make similar queries.Similarly for recommendations, click events or purchase events can be collected as signals and used to display “Customers who viewed this also viewed” or “Best-selling holiday items”.In a production environment, users’ actions generate signals. For the purposes of this tutorial, you will use Query Workbench to generate click signals.
Refining Search Results
The learning path for Refining Search Results focuses on the Fusion features that help you maximize the relevancy of your search results.
Before you begin
If the Fusion UI is not already open, then open it.-
In a browser window, open
localhost:8764. -
Enter the password for the user
admin, and then click Login. The Fusion launcher appears. - Click the Movie Search app. The Fusion workspace appears.
Format display fields
To help you understand the continuity in the next steps, first make sure that some relevant fields are displayed.-
Open Query Workbench.
Navigate to Querying > Query Workbench.
- At the top right of the page, select Display Fields.
- In the Name field, click the row to reveal a dropdown of possible values.
-
Select
title_txt. You can filter the list of possible values to help you. -
In the Description field, select
id. -
Close the Display Fields window.
- Click Display Fields to close the Display Fields window.
Enable synthetic signals
You need some signal data beyond the few signals you generated while completing Part 3. Because this is a prototype app, users are not generating signals. Instead, you will enable synthetic signals in Query Workbench.- At the bottom of the Query Workbench page, click Format Results.
-
Select Show signal generators and Send click signals.

- Click Save.
-
Hover over one of the search results.
Now when you hover over a search result, Query Workbench displays controls that include a Simulate button next to a field that lets you specify the number of signals to simulate:

Generate signals
With synthetic signals enabled, you will generate a simple set of signal data that you can use to generate meaningful recommendations.For this tutorial, you will generate signals that you can use to boost your favorite sci-fi titles so that they appear first.-
Search for
star wars. The top results are not your favorite titles: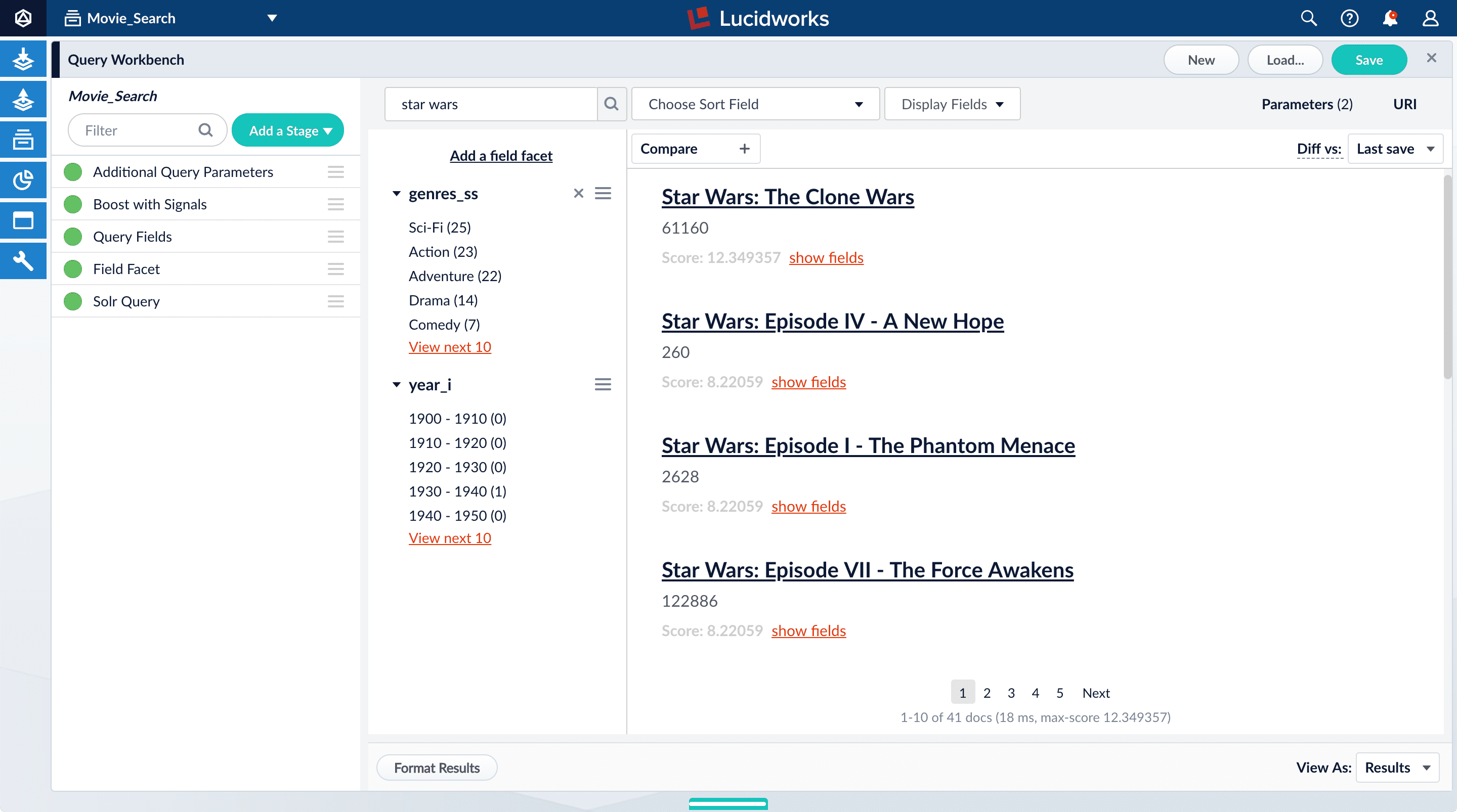
-
In Format Results, Set results per page to 20. This should allow you to scroll for this next part instead of explicitly searching for the titles.
Next you will generate signals that you can use to boost certain titles. Signals are tied to the search query, so your boosted titles will appear first in the search results only when users search for
star wars. - Hover over “Star Wars: Episode IV - A New Hope”.
- Set the number of signals to 4000 and click Simulate.
- Hover over “Star Wars: Episode V - The Empire Strikes Back”.
- Set the number of signals to 3000 and click Simulate.
- Hover over “Star Wars: Episode VI - Return of the Jedi”.
- Set the number of signals to 2000 and click Simulate.
-
In the upper right, click Save.
The Save Pipeline window appears. By default, you will overwrite the existing query pipeline for the selected collection (in this case,
Movie_Search_signals). - Click Save pipeline.
Explore the raw signals
Whenever you create a collection, two corresponding collections are also created automatically:COLLECTION_NAME_signals for raw signals and COLLECTION_NAME_signals_aggr for aggregated signals (in this case, Movie_Search_signals and Movie_Search_signals_aggr). Just as you did with your primary collection, you can use Query Workbench to explore the data in the _signals collection.- In the collection picker in the upper left, select Movie_Search_signals.
-
Open Query Workbench. Navigate to Querying > Query Workbench.
Your signal data appears.
-
Search for
type:click. -
For any of the results, click show fields.
- The
count_ifield shows the number of click signals you generated for this event. For example, given the correspondingdoc_idfor Star Wars: Episode IV - A New Hope, thecount_iequals 4000.
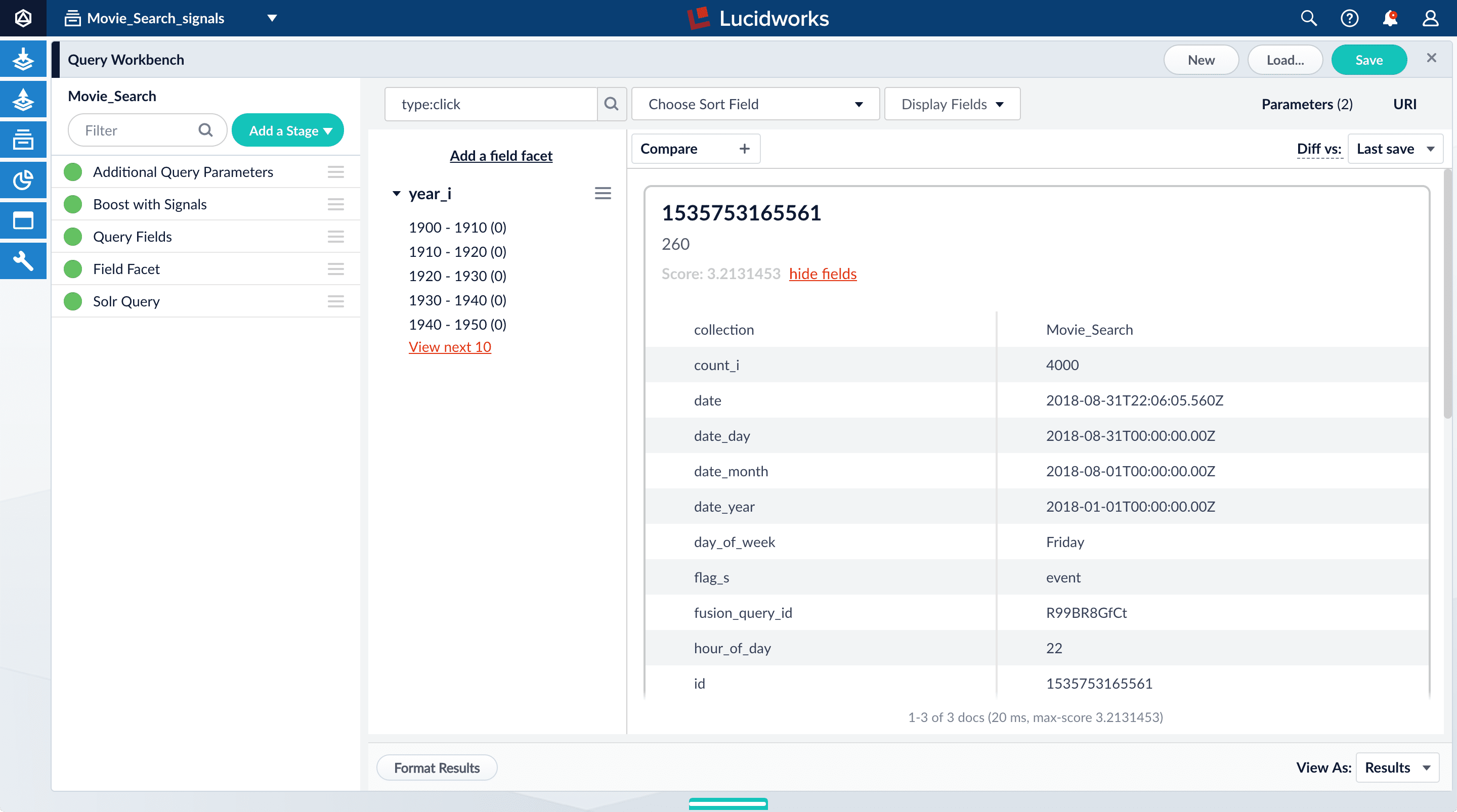
doc_id_sfield in theMovie_Search_signalscollection is the same as the contents of theidfield in yourMovies_Searchcollection, that is, the ID of the document that you clicked in Query Workbench, or for which you specified a number of clicks, and then clicked Simulate*. ** Thequery_orig_sfield in theMovie_Search_signalscollection contains the original query string that produced this search result. - The
- Click hide fields.
Optional: Format signals fields
You can configure your search view to display fields that are meaningful for your investigation. For example, you can display the document ID and the number of click signals.- Click Display Fields.
-
For the Name field, select
doc_id. -
For the Description field, select
count_i.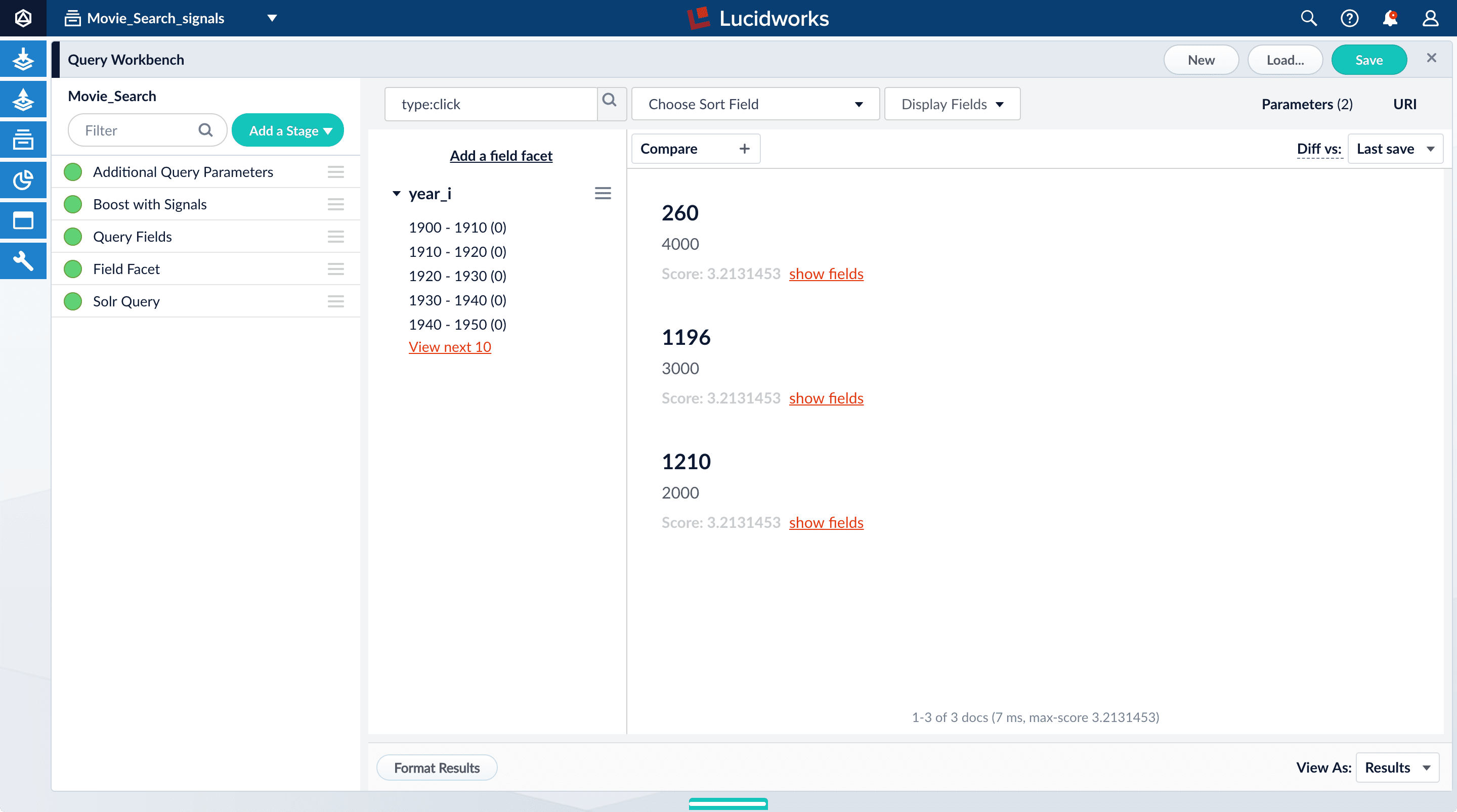
Explore the aggregated signal data
Aggregation jobs are created automatically when you create an app. However, you need to run the aggregation job manually:- Navigate to Collections
 > Jobs.
> Jobs. - Select
Movie_Search_click_signals_aggregationfrom the job list. - Click Run.
- Click Start.
Movie_Search_signals_aggr collection.- In the collections picker in the upper left, select Movie_Search_signals_aggr.
-
Open Query Workbench. Navigate to Querying > Query Workbench.
Your aggregated signal data should appear. If not, wait a minute and then reload your browser, or click Search in Query Workbench.
- Click Display Fields.
-
For the Name field, select
doc_id. -
For the Description field, select
aggr_count_i. -
For the result 1210, click show fields.
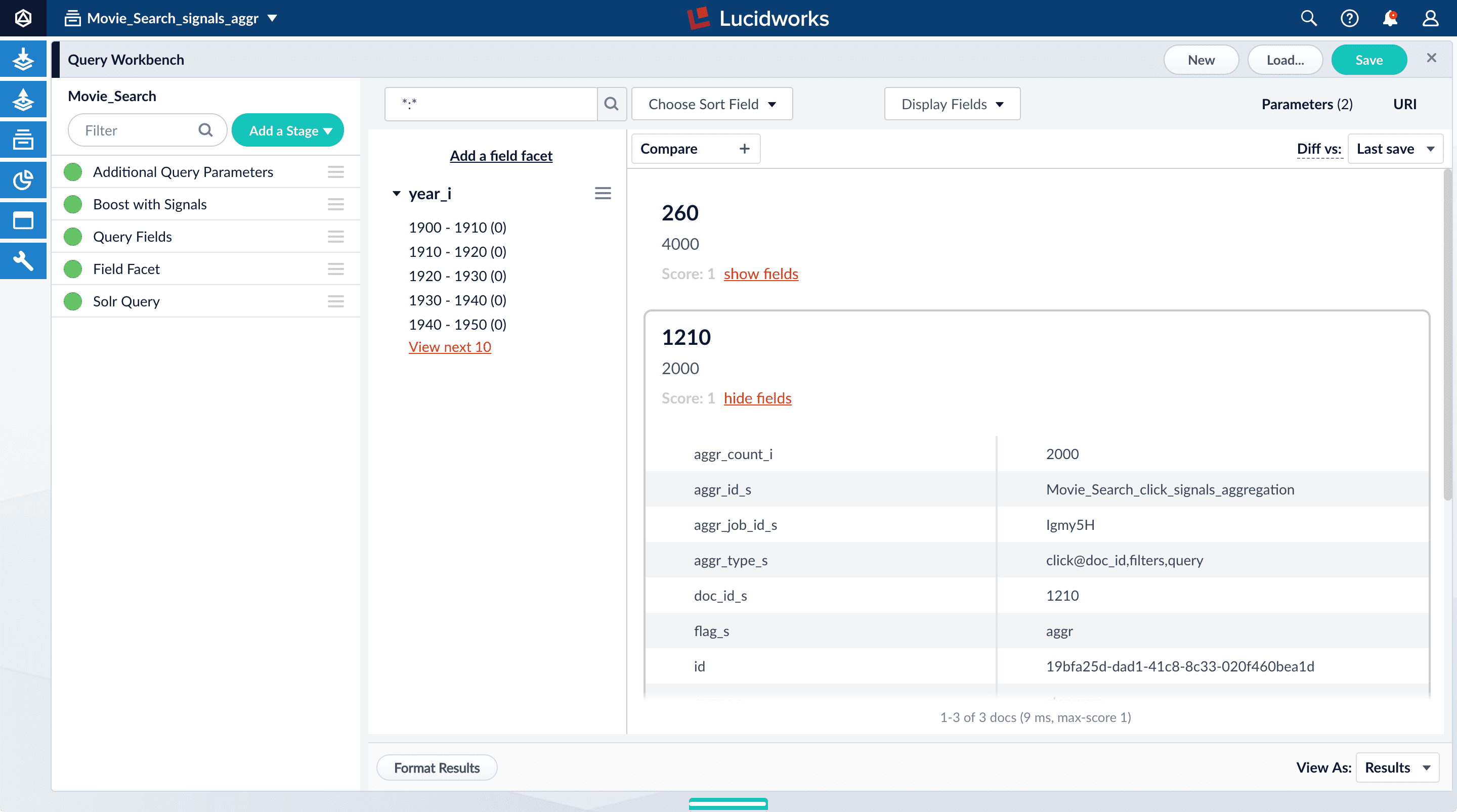
aggr_count_i. Number of signals that have been aggregated (in this case, 3000)aggr_id_s. Name of the aggregation jobaggr_job_id_s. Job IDaggr_type_s. Aggregation type
-
In the upper right, click Save.
The Save Pipeline window appears. By default, you will overwrite the existing query pipeline for the selected collection (in this case,
Movie_Search). - Click Save pipeline.
View the search results with and without default boosting
- In the collections picker in the upper left, select Movie_Search.
-
Open Query Workbench. Navigate to Querying > Query Workbench.
-
Search for
star wars. Now, “Star Wars: Episode IV - A New Hope” is the first search result, followed by Episode V and then VI. These search results are automatically boosted by the default configuration of the Boost with Signals query pipeline stage, which boosts on theidfield.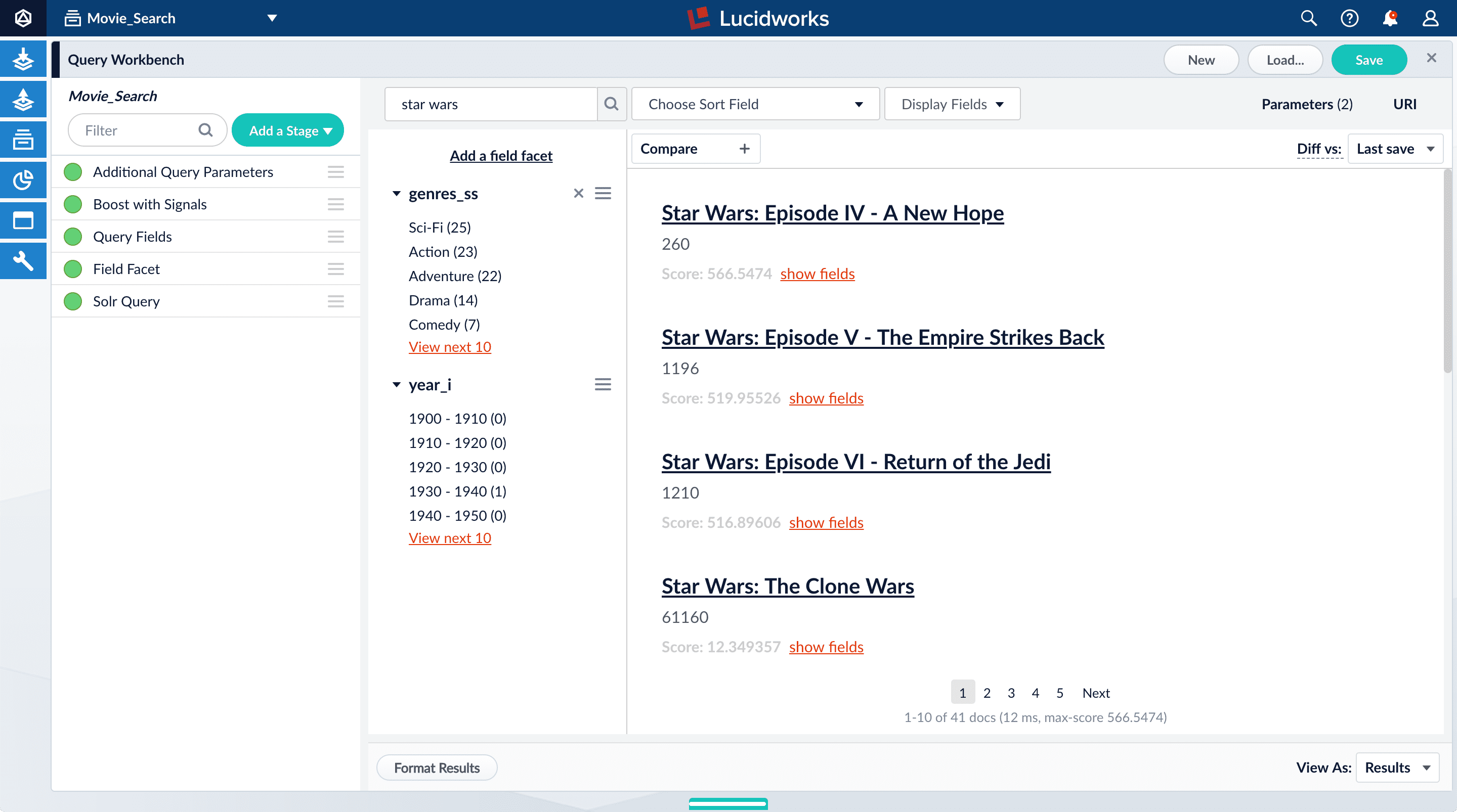 The Boost with Signals stage requires a Fusion AI license. Your Fusion Server trial license enables Fusion AI features.
The Boost with Signals stage requires a Fusion AI license. Your Fusion Server trial license enables Fusion AI features. -
Click Compare. Another preview panel opens. Now the working pipeline is on the right and a static snapshot of that same pipeline is on the left.
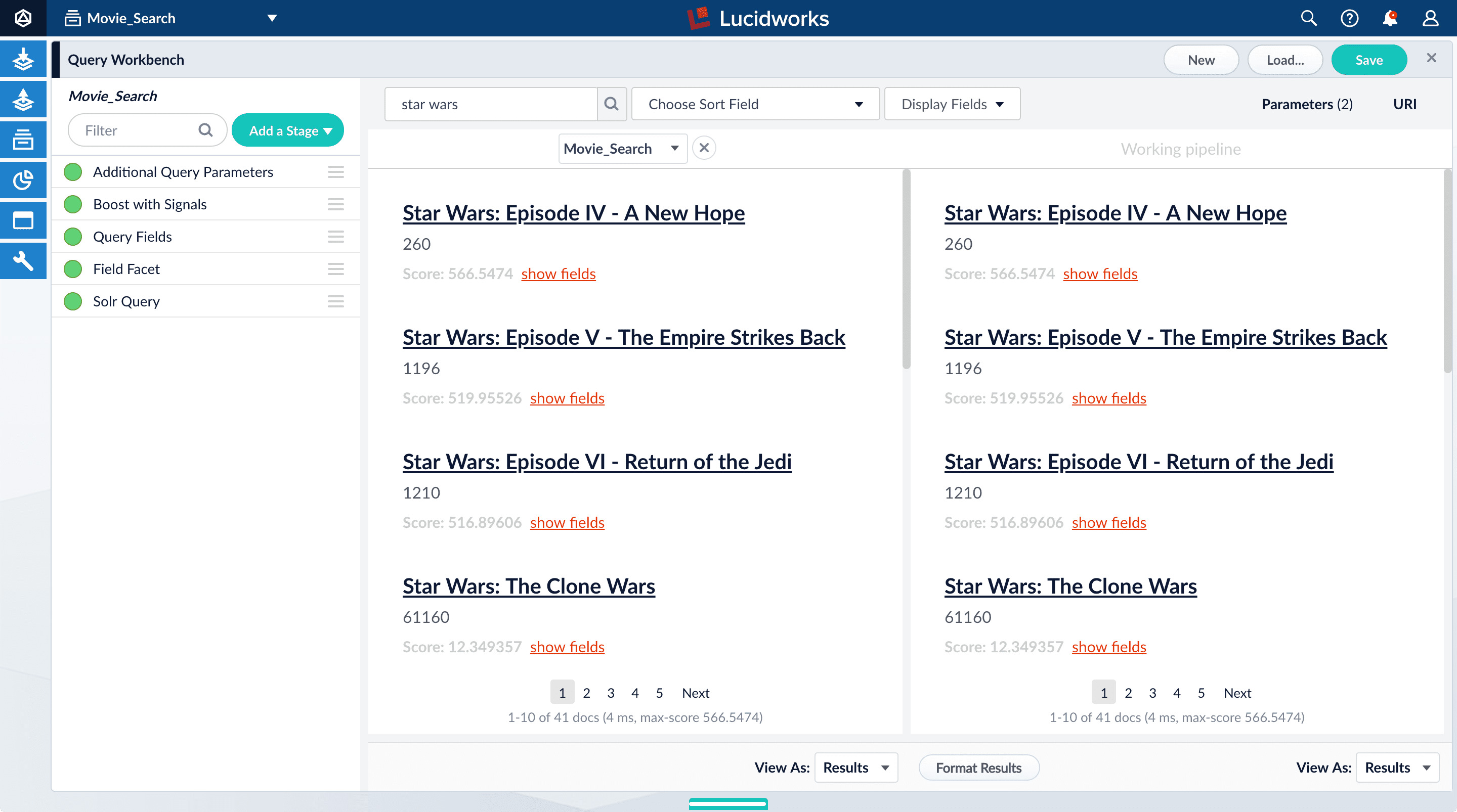
Movie_Search) with and without the Boost with Signals stage enabled. -
Turn off the Boost with Signals stage.
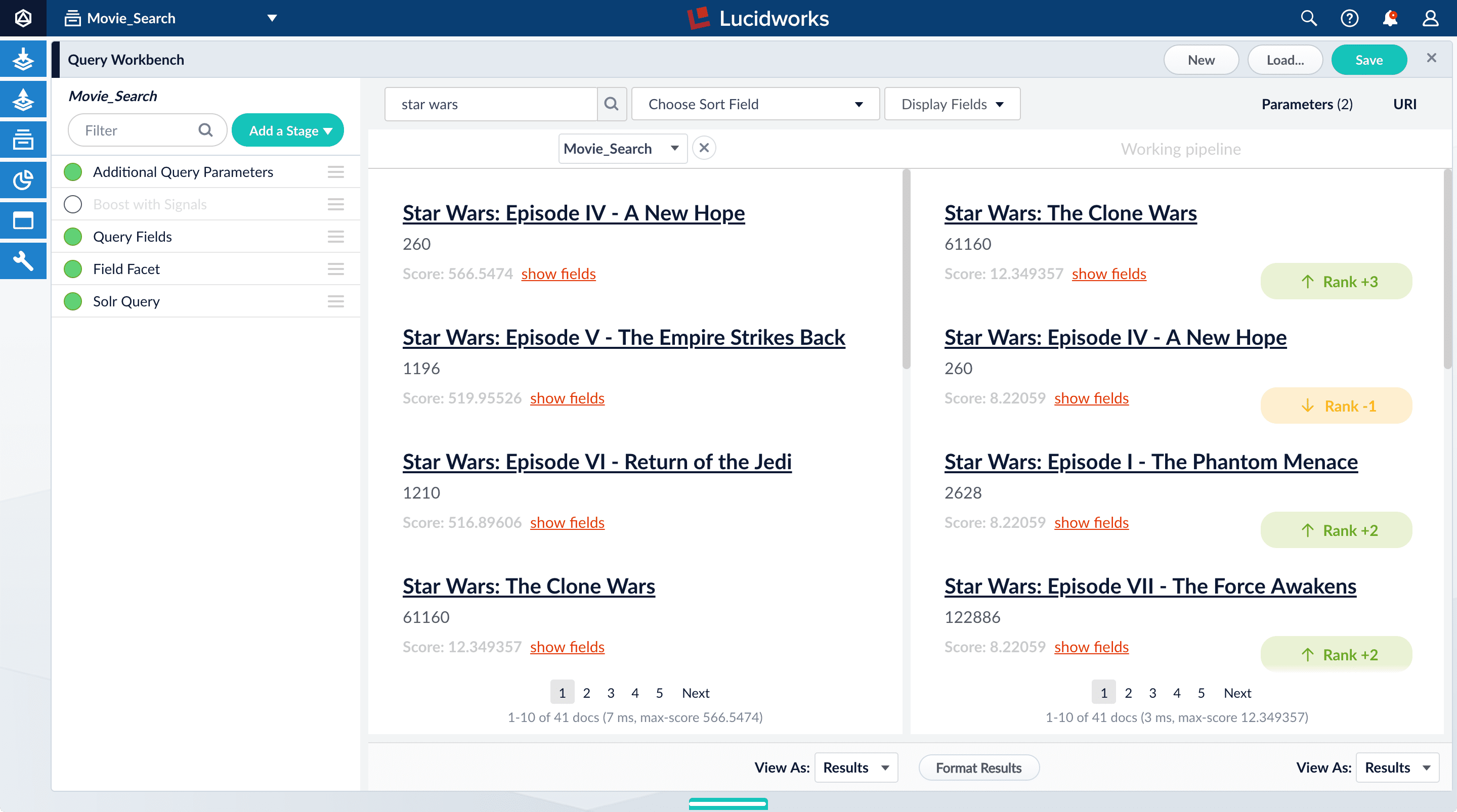
- Turn on the Boost with Signals stage again to restore the boosted results.
-
Close the comparison preview panel by clicking the close
 icon.
icon.