This topic provides tips for training your Smart Answers deep learning model.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
Model Base
There are several types of model bases that can be used for training and fine-tuning:- word_en_300d_2M are general pre-trained word embeddings. It is a good default choice to start with for English language.
- bpe_{language}_{dim_size}_{vocab_size} are general pre-trained BPE embeddings that are available for different languages, including CJK languages and multilingual. Also useful in scenarios when vocabulary is very big or when the data might have a lot of misspellings.
- word_custom or bpe_custom specifies that custom embeddings should be trained on users data via Word2Vec algorithm. It might be useful when your domain has a very unusual specific vocabulary.
- transformer based models such as distilbert_{language} and biobert. Much bigger and expensive models that might provide even better quality for FAQ, Chatbot and virtual Assistance use-cases. Also useful when the training data is limited.
We recommend to use Transformer-based models only if you can allocate GPU for the training job as these models are very computationally expensive.
Auto hyperparameter tuning
By default, training module tries to select the most optimal parameter values (for those left as blank) based on the training data statistics. Auto-tune can extend it by automatically finding even better training configuration through hyper-parameter search. If Perform auto hyperparameter tuning is enabled, multiple models will be trained across several stages. On each stage the most impactful parameters are tuned to find the best configuration. All other parameters are used with default values or those specified on UI. Although this is a resource-intensive operation, it can be useful to identify better RNN-based configuration. Transformer-based models are not used during auto hyperparameter tuning as they have a fixed architecture. They usually perform better on Q&A tasks yet they are much more expensive on both training and inference time.Input/Output parameters
Here you can specify the input data that should be used for training with possibility to filter or sample it.You can also configure this job to read from or write to cloud storage. See Configure An Argo-Based Job to Access GCS and Configure An Argo-Based Job to Access S3.
Configure An Argo-Based Job to Access GCS
Configure An Argo-Based Job to Access GCS
Some jobs can be configured to read from or write to Google Cloud Storage (GCS).You can configure a combination of Solr and cloud-based input or output, that is, you can read from GCS and then write to Solr or vice versa.
However, you cannot configure multiple storage sources for input or multiple storage targets for output; only one can be configured for each.
Supported jobs
This procedure applies to these Argo jobs:- Content based Recommender
- BPR Recommender
- Classification
- Evaluate QnA Pipeline
- QnA Coldstart Training
- QnA Supervised Training
How to configure a job to access GCS
- Gather the access key for your GCS account.
See the GCS documentation. - Create a Kubernetes secret:
- In the job’s Cloud storage secret name field, enter the name of the secret for the GCS target as mounted in the Kubernetes namespace.
This is the name you specified in the previous step. In the example above, the secret name ismy-gcs-serviceaccount-key. - In the job’s Additional Parameters, add this parameter:
- Parameter name:
google.cloud.auth.service.account.json.keyfile - Parameter value:
<name of the keyfile that is available when the GCS secret is mounted to the pod>The file name may be different than the secret name. You can check usingkubectl get secret -n <fusion-namespace> <secretname> -o yaml.
- Parameter name:
Configure An Argo-Based Job to Access S3
Configure An Argo-Based Job to Access S3
Some jobs can be configured to read from or write to Amazon S3 (S3).You can configure a combination of Solr and cloud-based input or output, that is, you can read from S3 and then write to Solr or vice versa.
However, you cannot configure multiple storage sources for input or multiple storage targets for output; only one can be configured for each.
Supported jobs
This procedure applies to these Argo jobs:- Content based Recommender
- BPR Recommender
- Classification
- Evaluate QnA Pipeline
- QnA Coldstart Training
- QnA Supervised Training
How to configure a job to access S3
- Gather the access key and secret key for your S3 account.
See the AWS documentation. - Create a Kubernetes secret:
- In the job’s Cloud storage secret name field, enter the name of the secret for the S3 target as mounted in the Kubernetes namespace.
This is the name you specified in the previous step. In the example above, the secret name isaws-secret. - In the job’s Additional Parameters, add these two parameters:
- Param name:
fs.s3a.access.keyPath
Param value:<name of the file containing the access key that is available when the S3 secret is mounted to the pod> - Param name:
fs.s3a.secret.keyPath
Param value:<name of the file containing the access secret that is available when the S3 secret is mounted to the pod>The file name may be different than the secret name. You can check usingkubectl get secret -n <fusion-namespace> <secretname> -o yaml.
- Param name:
Weight Field will not be used if Use Labelling Resolution is set on. These parameters are mutually exclusive.
Data pre-processing parameters
Labeling Resolution allows to find missing query/response pairs in the training data which helps in the training. When set on, a graph of all pairs connections is built. Then connected components are obtained to match missing query/response pairs. For example if there are three existing pairs:q1-a1, q2-a1 and q2-a2. Then Labelling Resolution will match q1-a2 as additional pair through q2-a1 connection.
This is useful in Q&A use-cases when there are not a lot of answers per unique question, otherwise too big connected components will be found. If you have data when for one query there might be a lot of different responses, like in eCommerce, it is better to leave it off.
If Use Labelling Resolution is set on, Weight Field is ignored. These parameters are mutually exclusive.
word_en_300d_2M, word_custom or bpe_custom model bases are used. Otherwise these parameters are ignored and model specific pre-processing is used. Default values should work in most cases, given enough RAM and time to train.
If you want to train custom embeddings for languages like CJK, disable Apply unidecode decoding.
Custom embeddings initialization parameters
If word_custom or bpe_custom model bases are chosen, then custom embeddings will be trained on the provided data. If you want to use addition dataset to train custom embeddings, please specify Texts Data Path and Text Fields in the Input/Output parameters. Additionally, commonly-used Word2vec training parameters are Word2Vec Training Epochs, Size of Word Vectors and Word2Vec Window Size. Default values should work in most cases.Evaluation parameters
Validation Sample Size controls how much unique queries should be hold-out and used for validation. It is a fraction if the value below 1.0 or specific number of queries if it is integer value higher than 1. During evaluation, all responses/answers are used. They form an index which is queried by unique validation queries. Eval ANN Index parameter controls should it be ANN index or brute-force search with auto value by default. If you notice that evaluation takes a lot of time, try to enable ANN index or reduce the number of evaluation queries. Generally, this evaluation setup is similar to how it will work in index and query pipelines, so the evaluation results should provide good approximation of the quality. To evaluate the configured pipelines on the test data, please use Evaluate a Smart Answers Query Pipeline.Evaluate a Smart Answers Query Pipeline
Evaluate a Smart Answers Query Pipeline
The Smart Answers Evaluate Pipeline job evaluates the rankings of results from any Smart Answers pipeline and finds the best set of weights in the ensemble score. This topic explains how to set up the job.Before beginning this procedure, prepare a machine learning model using either the Supervised method or the Cold start method, or by selecting one of the pre-trained cold start models, then Configure your pipelines.The input for this job is a set of test queries and the text or ID of the correct responses. At least 100 entries are needed to obtain useful results. The job compares the test data with Fusion’s actual results and computes variety of the ranking metrics to provide insights of how well the pipeline works. It is also useful to use to compare with other setups or pipelines.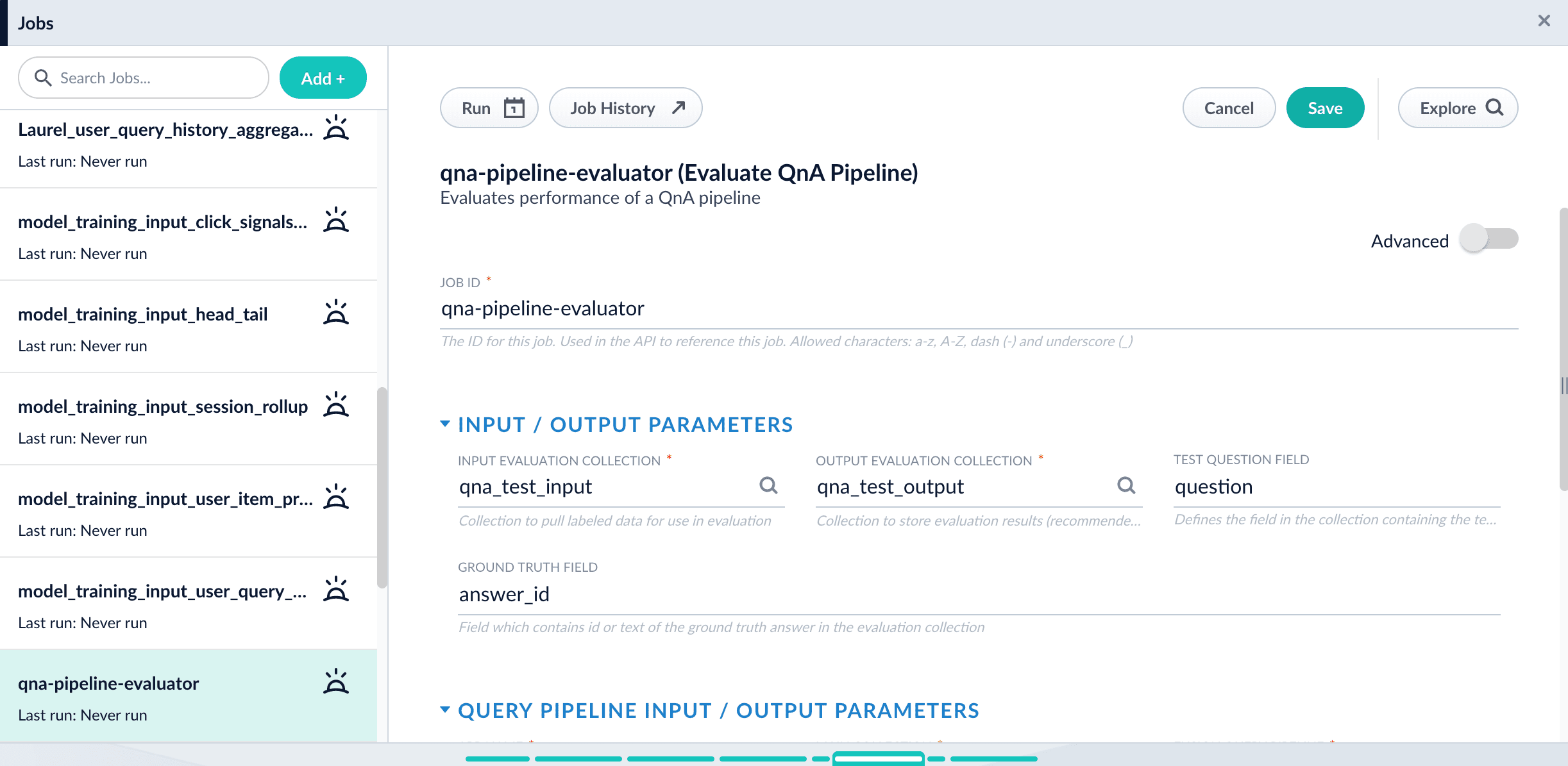

Prepare test data
-
Format your test data as query/response pairs, that is, a query and its corresponding answer in each row.
You can do this in any format that Fusion support, but parquet file would be preferable to reduce the amount of possible encoding issues.
The response value can be either the document ID of the correct answer in your Fusion index (preferable), or the text of the correct answer.
If there are multiple possible answers for a unique question, then repeat the questions and put the pair into different rows to make sure each row has exactly one query and one response.If you use answer text instead of an ID, make sure that the answer text in the evaluation file is formatted identically to the answer text in Fusion.
-
If you wish to index test data into Fusion, create a collection for your test data, such as
sa_test_inputand index the test data into that collection.
Configure the evaluation job
-
If you wish to save the job output in Fusion, create a collection for your evaluation data such as
sa_test_output. - Navigate to Collections > Jobs.
- Select New > Smart Answers Evaluate Pipeline (Evaluate QnA Pipeline in Fusion 5.1 and 5.2).
-
Enter a Job ID, such as
sa-pipeline-evaluator. -
Enter the name of your test data collection (such as
sa_test_input) in the Input Evaluation Collection field. -
Enter the name of your output collection (such as
sa_test_output) in the Output Evaluation Collection field.You can also configure this job to read from or write to cloud storage. - Enter the name of the Test Question Field in the input collection.
- Enter the name of the answer field as the Ground Truth Field.
- Enter the App Name of the Fusion app where the main Smart Answers content is indexed.
- In the Main Collection field, enter the name of the Fusion collection that contains your Smart Answers content.
- In the Fusion Query Pipeline field, enter the name of the Smart Answers query pipeline you want to evaluate.
- In the Answer Or ID Field In Fusion field, enter the name of the field that Fusion will return containing the answer text or answer ID.
- Optionally, you can configure the Return Fields to pass from Smart Answers collection into the evaluation output.
- Configure the Metrics parameters:
-
Solr Scale Function
Specify the function used in the Compute Mathematical Expression stage of the query pipeline, one of the following:
maxlog10pow0.5
- List of Ranking Scores For Ensemble To find the best weights for different ranking scores, list the names of the ranking score fields, separated by commas. Different ranking scores might include Solr score, query-to-question distance, or query-to-answer distance from the Compute Mathematical Expression pipeline stage.
-
Target Metric To Use For Weight Selection
The target ranking metric to optimize during weights selection. The default is
mrr@3.
- Optionally, read about the advanced parameters and consider whether to configure them as well.
- Click Save.
Examine the output
The job provides a variety of metrics (controlled by the Metrics list advanced parameter) at different positions (controlled by the Metrics@k list advanced parameter) for the chosen final ranking score (specified in Ranking score parameter).Example: Pipeline evaluation metrics- Mean Average Precision (MAP)
- Mean Reciprocal Rank (MRR)
- Recall
[1,3], with Metrics list [“map”,”mrr”,”recall”], then the metrics map@1, map@3, mrr@1, mrr@3, recall@1, and recall@3 will be logged for each training epoch and final model.
You can choose a particular metric at a particular k (controlled by the Monitoring metric parameter) to help decide when to stop training. Specifically, when there is no increase in the Monitoring metric value for a particular number of epochs (controlled by the Patience during monitoring parameter), then training stops.
During the training we evaluate the result using similar cold-start model (weighted average of word vectors) as a baseline. Look for the Cold-start encoder validation evaluation section of the logs, it is printed before first training epoch.
General Encoder parameters
Note that the following parameters are common across all model bases including RNN and Transformer architectures.- Fine-tune Token Embeddings will allow to fine-tune embeddings (word vectors) layer to be updated during the training alongside with all other layers. It is disabled by default as it is usually one of the biggest layer in the network and updating it might lead to overfitting. It is useful to enable if your data have a lot of specific or misspelled words.
- Max Length controls the maximum context window that model can process. Texts longer than this value will be trimmed. The default value is the max value between three times the STD of question lengths and two times the STD of answer lengths.
The longer the context the longer and harder it takes for model to process. This parameter is especially important for Transformer-based models as it affects training and inference time. Note that the maximum supported length for Transformer models is 512 tokens, so you can specify any value up to that. - Global Pool Type specifies how token vectors should be aggregated to obtain final content vector. The default mechanism is self-attention which provides the best quality in most cases.
- Number of clusters and Top K of clusters to return are deprecated since 5.3 and will be removed in the following releases. There is no practical need to use them after Milvus vectors similarity search integration.
RNN Encoder parameters
We use RNN-based deep learning architecture forword and bpe model bases, with the flexibility to choose between LSTM and GRU layers with more than one layer. We don’t recommend using more than three layers. The layers and layer sizes are controlled by the RNN function list and RNN function units list parameters.
Dropout ratio parameters provides regularization effect and is applied between embeddings layer and the first RNN layer.