Upgrade Fusion Server 4.1.x to 4.2.y
Upgrade Fusion Server 4.1.x to 4.2.y
Introduction
This article describes how to perform the following upgrade:- From version: Fusion
4.1.x - To version: Fusion
4.2.y
Only specific version-to-version upgrade sequences are supported. Some upgrades require multiple steps.
/opt/lucidworks/fusion/4.1.x/var/upgrade directory (on Unix or MacOS) or the C:\lucidworks\fusion\4.1.*x\var\upgrade\ directory (on Windows). The file names reference the versions you are upgrading from and to. For example:- To upgrade
4.1.3to4.2.5, the migrator uses the4.1.x-4.2.x.propertiesfile.
The newer Fusion instance must be newly untarred and never started.
About the upgrade
This section describes how connectors, object migrations, and signals are migrated during an upgrade.Connectors
In Fusion 3.1.0 and later, only a subset of connectors are included by default.The migrator detects which connectors were used in the older version of Fusion, and installs them automatically in Fusion4.0.y. This step requires an Internet connection. If no connection is available, then download the connectors from Fusion 4.x Connector Downloads and install them as bootstrap plugins.If a connector to be upgraded was not available during the upgrade, then a message in /opt/lucidworks/fusion/3.1.x/var/upgrade/tmp/migrator.log (on Unix) or C:\lucidworks\fusion\3.1.*x\var\upgrade\tmp\migrator.log (on Windows) indicates this.Only datasources for connectors that are supported in the new Fusion version are upgraded. Datasources for custom connectors are not upgraded.If no Internet connection is available
If no Internet connection is available during an upgrade, the migrator cannot automatically download the connectors it needs. Using the Fusion UI or API later to install the connectors also might not be an option.In this case, download the connectors from Fusion 4.x Connector Downloads for all existing connectors and place them inapps/connectors/bootstrap-plugins for the new deployment (on all Fusion nodes). Do so at the time indicated in the procedures that follow.Adding connectors during an upgrade
You can add connectors during an upgrade (that is, add connectors that are not in the old deployment).Download the connectors from Fusion 4.x Connector Downloads and place them inapps/connectors/bootstrap-plugins for the new version (on all Fusion nodes).Object migrations and transformations
The migrator automatically migrates these Fusion 4.1 object types, transforming them as needed:- Collections
- Index pipelines
- Query pipelines
- Search cluster configurations
- Datasources
- Parsing configurations
- Object groups
- Links
- Tasks
- Jobs
- Spark objects
- Apps
- Appkit apps
- Index profiles
- Query profiles
- Blobs
In Fusion Server 4.0 and later, most objects exist in the context of apps. When you upgrade from Fusion Server 4.1.x to 4.2.y, the migrator upgrades app objects, all objects in or linked to objects in apps, and objects that are not linked to apps. You can explore the objects in Object Explorer.
Access control migration
The migrator upgrades all access control configurations:- Security realms
- Roles
- Users
Association of blobs with apps
The association of blobs with apps becomes stronger in Fusion Server 4.1.1. Newly created blobs are only linked to the app to which they are uploaded, and are only shared with other apps when the blobs are directly linked to those apps (added to the apps in Object Explorer or linked using the Links API).When migrating from pre-4.1.1 versions to 4.1.1 or later, the resulting apps might not contain all of the blobs that they contained prior to migration.It is important to stress that this change does not break the apps.
Review known issues
Before upgrading, review the known issues to see whether any of them apply to the circumstances of your upgrade. Some known issues might require actions before upgrading.That article also contains instructions regarding what to do if an upgrade step fails.Upgrade on Unix
Use this procedure to upgrade Fusion on a single Unix node or on multiple Unix nodes.Perform the steps in this procedure on the indicated nodes on which Fusion is running (“Fusion nodes”). To perform an upgrade, Fusion nodes must have at least these services running:- API service (
api) - Proxy service (
proxy)
For every step on multiple nodes, ensure that the step completes on all Fusion nodes before going to the next step. There is the notion of a “main node” during the migration process. This node will be used for certain centralized migration activities that do not need to be done on every node, such as downloading connectors that are then uploaded to blob storage that is shared by all, etc. Just pick one of your Fusion nodes to be the “main node”; there is no special requirement as to which one you pick.
Ensure that your current version of Fusion has a valid license
Ensure that your current version of Fusion has a valid permanent Fusion license before proceeding with the upgrade. Place a validlicense.properties file in the /opt/lucidworks/fusion/4.1.x/conf directory.Install the Java JDK
Before upgrading to Fusion Server 4.2 or later, you must install the Java JDK on all nodes that will run Fusion Server. Prior versions of Fusion Server could use either the JRE or the JDK.For more information, see Java requirements.Download and install the newer version of Fusion
Perform these tasks on all Fusion nodes:- Select the Fusion release to which you are upgrading from Fusion Server 4.x File Download Links.
- Extract the newer version of Fusion:
For example, if Fusion is currently installed in
/opt/lucidworks/fusion/4.1.x, then change your working directory to/opt/lucidworks/and extract the file there. do not run the new version of Fusion yet. - Ensure that the new version of Fusion has a valid permanent Fusion license before proceeding with the upgrade. Place a valid
license.propertiesfile in the/opt/lucidworks/fusion/4.2.y/confdirectory. - (If there are custom
jarfiles) If your deployment has customjarfiles, add them to the new Fusion deployment. - (If you are performing an upgrade without Internet access) Without Internet access, the migrator cannot download new versions of connectors automatically. Download the new versions of connector zip files for your current connectors from Fusion 4.x Connector Downloads and place them in
apps/connectors/bootstrap-pluginsfor the new deployment. - (If you are adding new connectors) If you want your new deployment to use connectors that are not in the current deployment, you can add them now. Download the connector zip files from Fusion 4.x Connector Downloads and place them in
apps/connectors/bootstrap-pluginsfor the new deployment. - Verify that there is sufficient disk space for a second copy of the Solr index directory,
fusion/4.1.x/data/solr. If there is not sufficient disc space, free up space before proceeding.
Download and install the Fusion migrator
Perform these tasks on all Fusion nodes:- Download the latest migrator zip file for Unix. (Do this now, even if you have downloaded the migrator before, to ensure that you have the latest version.)
- Create
FUSION_OLDandFUSION_NEWenvironment variables that point to the old and new Fusion installation directories respectively (using the full path).For example, when upgrading from Fusion 4.1.3 to 4.2.6: - Create this directory:
- Install the migrator:
Run the migrator
Perform these tasks on the indicated nodes:-
(On all Fusion nodes) Start all Fusion services for the old version of Fusion:
-
(Only on the main Fusion node) Run the migrator to export the configuration data from the old version of Fusion:
This message indicates that the step finished successfully:
-
(On all Fusion nodes) Stop the old versions of Fusion services and Solr; but not ZooKeeper:
If Spark and SQL services are running, also stop those:
-
(Only on secondary Fusion nodes) Prepare secondary nodes:
This message indicates that the step finished successfully:
-
(On all Fusion nodes) Stop ZooKeeper for the old version of Fusion (unless you are using an external ZooKeeper instance, in which case you can ignore this step):
-
(Only on the main Fusion node) Transform configuration data on the main Fusion node:
This message indicates that the step finished successfully:Depending on the size of your Solr index, this step can take a long time (for example, multiple tens of minutes).
-
(On all Fusion nodes) Start ZooKeeper for the new version of Fusion (unless you are using an external ZooKeeper instance, in which case you can ignore this step):
-
(Only on the main Fusion node) Import the first part of configuration data into the new version of Fusion:
This message indicates that the step finished successfully:
-
(On all Fusion nodes) Start all Fusion services for the new version of Fusion:
-
(Only on the main Fusion node) Import the second part of configuration data into the new version of Fusion:
This message indicates that the step finished successfully:
Validate the new version of Fusion
How to validate the new version of Fusion- (Only on the main Fusion node) Restart the new version of Fusion (all services defined in
fusion.properties): - Log into the Fusion UI (your
adminpassword is the same as for the old installation), and confirm the release number of the new version of Fusion:- Clear your browser’s cache.
Otherwise, you might inadvertently access a cached version of the old Fusion UI and see inconsistent behavior. - In a browser, open the Fusion UI at
http://localhost:8764/(replacelocalhostwith your server name or IP address if necessary). - Log in.
- Navigate to Admin > About Fusion.
The About Fusion panel should display the newer Fusion release number.
- Clear your browser’s cache.
- Ensure that all connectors were installed automatically during the upgrade.
- For Fusion 4.x from the Fusion launcher, click the tile for a migrated app. Click System > Blobs. If any connectors are missing from the list, click Add > Connector Plugin and install them manually.
- For Fusion 3.x from the Fusion launcher, click Devops > Home
 > Blobs.
If any connectors are missing from the list, click Add > Connector Plugin and install them manually.
> Blobs.
If any connectors are missing from the list, click Add > Connector Plugin and install them manually.
- Ensure that all customizations you made in the former version of Fusion are present in the new one.
- If you migrated from version 4.1.0 to version 4.2.0 or later, confirm associations between blobs and apps and make adjustments if necessary.
- When you are satisfied with the migration and you have backed up the
fusion/4.1.x/directory, you canrm -fr fusion/4.1.*x/to remove the older version of Fusion (on all Fusion nodes).
Add support for business rules to existing apps
Fusion AI 4.2 introduces functionality for using business rules, that is, manually created formulas for rewriting queries and responses.You can add support for business rules to apps that were created in versions of Fusion AI prior to version 4.2. To do so, perform the steps in this section.Theadd-rule-objects-xyz.zip file (where xyz is a version number) specifies the objects to add to an app. It is supplied in the Fusion migrator zip file at the top level. After installing the migrator, the location is $FUSION_OLD/var/upgrade/import-files.Adding support for business rules has a costs. Additional collections and objects are created. Only add support for business rules to apps in which you plan to use them.
Fusion UI
For each app in which you plan to use business rules, import the objects in theadd-rule-objects-xyz.zip file into the app.How to import business rule objects- In the Fusion launcher, click the app into which you want to import objects. The Fusion workspace appears.
- In the upper left, click System
 > Import Fusion Objects.
The Import Fusion Objects window opens.
> Import Fusion Objects.
The Import Fusion Objects window opens. - For the data file, select
add-rule-objects-xyz.zipfrom your local filesystem. The location in the extracted migrator files is$FUSION_OLD/var/upgrade/import-files. - Click Import.
- Edit the
Application IDparameter value to use the app name. If the app name contains spaces, replace those with underscore characters. For example,Lucene Revolutionwould becomeLucene_Revolution. - Click Import.
- If there are conflicts, Fusion prompts you to specify an import policy. Click Merge to skip all conflicting objects and import only the non-conflicting objects. Fusion confirms that the import was successful.
- Click Close to close the Import Fusion Objects window.
Fusion API
For each app in which you plan to use business rules, import the objects in theadd-rule-objects-xyz.zip file into the app.How to import business rule objects- Create an
app-name.txtfile with the following content:For example, for the appLucene Revolution:Here, we assume that you create the files in your home directory, for which the$HOMEenvironment variable is defined. - Import the business rule objects:
For example:
Upgrade on Windows
Use this procedure to upgrade Fusion on a single Windows node or multiple Windows nodes.Perform the steps in this procedure on the indicated nodes on which Fusion is running (“Fusion nodes”). To perform an upgrade, Fusion nodes must have at least these services running:- API service (
api) - Proxy service (
proxy)
If you are upgrading Fusion on multiple nodes, then, for every step on multiple nodes, ensure that the step completes on all Fusion nodes before going to the next step. There is the notion of a “main node” during the migration process. This node will be used for certain centralized migration activities that do not need to be done on every node, such as downloading connectors that are then uploaded to blob storage that is shared by all, etc. Just pick one of your Fusion nodes to be the “main node”; there is no special requirement as to which one you pick.
Ensure that your current version of Fusion has a valid license
Ensure that your current version of Fusion has a valid permanent Fusion license before proceeding with the upgrade. Place a validlicense.properties file in the C:\lucidworks\fusion\4.1.x\conf directory.Install the Java JDK
Before upgrading to Fusion Server 4.2 or later, you must install the Java JDK on all nodes that will run Fusion Server. Prior versions of Fusion Server could use either the JRE or the JDK.For more information, see Java requirements.Download and install the newer version of Fusion
Perform these tasks on all Fusion nodes:- Select the Fusion release to which you are upgrading from Fusion Server 4.x File Download Links.
- Move the
fusion-4.2.y.zipfile to the directory that contains thefusion\directory. For example, if Fusion is installed inC:\lucidworks\fusion\4.1.x, then move the file toC:\lucidworks. - Unzip the
fusion-4.2.y.zipfile. do not run the new version of Fusion yet. - For Fusion 4.x, ensure that the new version of Fusion has a valid permanent Fusion license before proceeding with the upgrade. Place a valid
license.propertiesfile in theC:\lucidworks\fusion\4.2.y\confdirectory. - (If there are custom
jarfiles) If your deployment has customjarfiles, add them to the new Fusion deployment. - (If you are performing an upgrade without Internet access) Without Internet access, the migrator cannot download new versions of connectors automatically. Download the new versions of connector zip files for your current connectors from Fusion 4.x Connector Downloads and place them in
apps\connectors\bootstrap-pluginsfor the new deployment. - (If you are adding new connectors) If you want your new deployment to use connectors that are not in the current deployment, you can add them now. Download the connector zip files from Fusion 4.x Connector Downloads and place them in
apps\connectors\bootstrap-pluginsfor the new deployment. - Verify that there is sufficient disk space for a second copy of the Solr index directory,
fusion\4.1.x\data\solr. If there is not sufficient disc space, free up space before proceeding.
Download and install the Fusion migrator
Perform these tasks on all Fusion nodes:- Download the latest migrator zip file for Windows. (Do this now, even if you have downloaded the migrator before, to ensure that you have the latest version.)
- Open a Command Prompt window and create
FUSION_OLDandFUSION_NEWenvironment variables that point to the old and new Fusion installation directories respectively. For example: - Create a
fusion\4.1.x\var\upgradedirectory. - Unzip the migrator zip file, and move the contents of the extracted folder to
+fusion\+4.1.x\var\upgrade.
Run the migrator
Perform these tasks on the indicated nodes:- (On all Fusion nodes) Start all Fusion services for the old version of Fusion:
- (Only on the main Fusion node) Run the migrator to export the configuration data from the old version of Fusion:
This message indicates that the step finished successfully:
- (On all Fusion nodes) Stop the old versions of Fusion services and Solr; but not ZooKeeper:
If Spark and SQL services are running, also stop those:
- (Only on secondary Fusion nodes) Prepare secondary nodes:
This message indicates that the step finished successfully:
- (On all Fusion nodes) Stop ZooKeeper for the old version of Fusion (unless you are using an external ZooKeeper instance, in which case you can ignore this step):
- (Only on the main Fusion node) Transform configuration data on the main Fusion node:
This message indicates that the step finished successfully:Depending on the size of your Solr index, this step can take a long time (for example, multiple tens of minutes).
- (On all Fusion nodes) Start ZooKeeper for the new version of Fusion (unless you are only using an external ZooKeeper instance, in which case you can ignore this step):
- (Only on the main Fusion node) Import the first part of configuration data into the new version of Fusion:
This message indicates that the step finished successfully:
- (On all Fusion nodes) Start Solr for the new Fusion version:
- (Only on the main Fusion node) Run a script to remove all old plugins from the blob store. Replace
solr-addressandsolr-portas appropriate (as shown in the example):For example:This message indicates that plugins were deleted successfully: - (On all Fusion nodes) Start all Fusion services for the new version of Fusion:
- (Only on the main Fusion node) Import the second part of configuration data into the new version of Fusion:
This message indicates that the step finished successfully:
Validate the new version of Fusion
How to validate the new version of Fusion- (On all Fusion nodes) Restart all Fusion services for the new version of Fusion:
- Log into the Fusion UI (your
adminpassword is the same as for the old installation), and confirm the release number of the new version of Fusion:- Clear your browser’s cache.
Otherwise, you might inadvertently access a cached version of the old Fusion UI and see inconsistent behavior. - In a browser, open the Fusion UI at
http://localhost:8764/(replacelocalhostwith your server name or IP address if necessary). - Log in.
- Navigate to Admin > About Fusion.
The About Fusion panel should display the newer Fusion release number.
- Clear your browser’s cache.
- Ensure that all connectors were installed automatically during the upgrade.
- For Fusion 4.x from the Fusion launcher, click the tile for a migrated app. Click System > Blobs. If any connectors are missing from the list, click Add > Connector Plugin and install them manually.
- For Fusion 3.x from the Fusion launcher, click Devops > Home > Blobs.
If any connectors are missing from the list, click Add > Connector Plugin and install them manually.
- Ensure that all customizations you made in the former version of Fusion are present in the new one.
- If you migrated from version 4.1.0 to version 4.2.0 or later, confirm associations between blobs and apps and make adjustments if necessary.
- When you are satisfied with the migration and you have backed up the
+fusion\+4.1.xdirectory, you can remove the older version of Fusion by removing that directory (on all Fusion nodes).
Add support for business rules to existing apps
Fusion AI 4.2 introduces functionality for using business rules, that is, manually created formulas for rewriting queries and responses.You can add support for business rules to apps that were created in versions of Fusion AI prior to version 4.2. To do so, perform the steps in this section.Theadd-rule-objects-xyz.zip file (where xyz is a version number) specifies the objects to add to an app. It is supplied in the Fusion migrator zip file at the top level. After installing the migrator, the location is %FUSION_OLD%\var\upgrade\import-files\.You have a choice. You can update each app using the Fusion UI or the Fusion API.Fusion UI
For each app in which you plan to use business rules, import the objects in theadd-rule-objects-xyz.zip file into the app.How to import business rule objects- In the Fusion launcher, click the app into which you want to import objects. The Fusion workspace appears.
- In the upper left, click System > Import Fusion Objects.
The Import Fusion Objects window opens.
- For the data file, select
add-rule-objects-xyz.zipfrom your local filesystem. The location in the extracted migrator files is%FUSION_OLD%\var\upgrade\import-files\. - Click Import.
- Edit the
Application IDparameter value to use the app name. If the app name contains spaces, replace those with underscore characters. For example,Lucene Revolutionwould becomeLucene_Revolution. - Click Import.
- If there are conflicts, Fusion prompts you to specify an import policy. Click Merge to skip all conflicting objects and import only the non-conflicting objects. Fusion confirms that the import was successful.
- Click Close to close the Import Fusion Objects window.
Fusion API
For each app in which you plan to use business rules, import the objects in theadd-rule-objects-xyz.zip file into the app.How to import business rule objects- Create an
app-name.txtfile with the following content:For example, for the appLucene Revolution:Here, we assume that you create the files in your home directory, for which the%HOMEPATH%environment variable is defined. - Import the business rule objects:
For example:
- Business Rules
- Misspelling Detection
- Phrase Detection
- Simulator
- Synonym Detection
- Underperforming Queries
Query rewriting strategies
Fusion AI provides a variety of query rewriting strategies to improve relevancy:- Business rules
- Underperforming query rewriting
- Misspelling detection
- Phrase detection
- Synonym detection
- Business rules
If a query triggers a business rule, then the business rule overrides any query rewriting strategies that conflict with it. - Underperforming query rewriting
If a query triggers an underperforming query rewrite, then this strategy overrides all subsequent query rewriting strategies. - Synonym detection
- Misspelling detection and phrase detection
The query rewriting results from both of these strategies are applied together. To use only the strategy with the longest surface form, you can configure the Text Tagger query stage with Overlapping Tag Policy set to “LONGEST_DOMINANT_RIGHT”.
Business rules
Business rules are manually-created formulas for rewriting queries. This is the most versatile strategy for creating custom query rewrites. It supports a variety of conditions and actions to address a wide range of use cases. When you need a very specific query rewrite, this is the best strategy. Business rules are applied in the Apply Rules stage of the query pipeline. See Business Rules to learn how to create, edit, and publish business rules.Underperforming query rewriting
The Underperforming Query Rewriting feature:- Uses signals data to identify underperforming queries
- Suggests improved queries that could produce better conversion rates
Misspelling detection
The Misspelling Detection feature maps misspellings to their corrected spellings. When Fusion receives a query containing a known misspelling, it rewrites the query using the corrected spelling in order to return relevant results instead of an empty or irrelevant results set. Spelling corrections are applied in the Text Tagger stage of the query pipeline. See Misspelling Detection to learn how to review, edit, create, and publish spelling corrections.Phrase detection
Phrase detection identifies phrases in your signals so that results with matching phrases can be boosted. This helps compensate for queries where phrases are not distinguished with quotation marks. For example, the queryipad case is rewritten as “ipad case”~10^2, meaning if ipad and case appear within 10 terms (whitespace-delimited tokens) of each other, then boost the result by a factor of 2.
Phrases are applied in the Text Tagger stage of the query pipeline.
See Phrase Detection to learn how to review, edit, create, and publish phrases.
Synonym detection
The Synonym Detection feature generates pairs of synonyms and pairs of similar queries. Two words are considered potential synonyms when they are used in a similar context in similar queries. When synonym detection is enabled, a query that contains a matching term is expanded to include all of its synonyms, with the original term boosted by a factor of two. Synonyms are applied in the Text Tagger stage of the query pipeline. See Synonym Detection to learn how to review, edit, create, and publish pairs of synonyms and similar queries.The Query Rewriting UI
To open the query rewriting interface, navigate to Relevance > Rules > Query Rewriting.
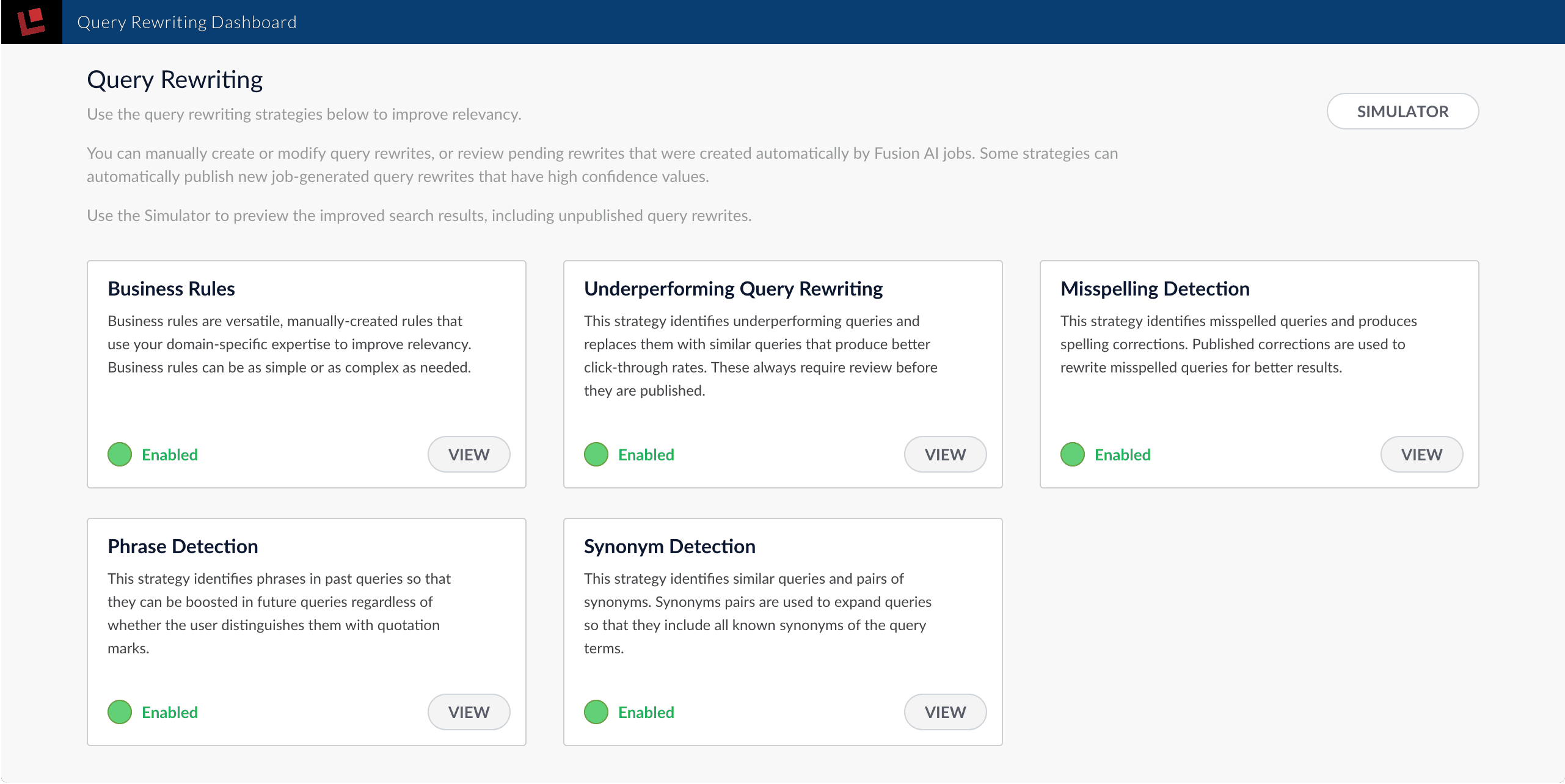
- Business Rules
- Underperforming Query Rewriting
- Misspelling Detection
- Phrase Detection
- Synonym Detection
Enabling and disabling strategies in the Query Rewriting UI does not enable or disable their corresponding Spark jobs.
Query rewrite collections
Manage Collections in the Fusion UI
Manage Collections in the Fusion UI
Collections can be created or removed using the Fusion UI or the REST API.For information about using the REST API to manage collections, see Collections API in the REST API Reference:You can map a Fusion collection to multiple Solr collections, known here as partitions, where each partition contains data from a specific time range.To configure time-based partitioning, under Time Series Partitioning click Enable.See Time-Based Partitioning for more information.To stop a datasource immediately, choose Abort instead of Stop.There is also a REST API for datasources:
- Fusion 5.x. Collections API
- Fusion 4.x. Collections API
Creating a Collection
When you create an app, by default Fusion Server creates a collection and associated objects.To create a new collection in the Fusion UI:- From within an app, click Collections > Collections Manager.
- At the upper right of the panel, click New.
- Enter a Collection name. This name cannot be changed later.
- To create the collection in the default Solr cluster and with other default settings, click Save Collection.
Creating a Collection with Advanced Options
To access advanced options for creating a collection in the Fusion UI:- From within an app, click Collections > Collections Manager.
- At the upper right of the panel, click New.
- Enter a Collection name. This name cannot be changed later.
- Click Advanced.
- Configure advanced options. The options are described below.
- Click Save Collection.
Solr Cluster
By default, a new collection is associated with the Solr instance that is associated with thedefault Solr cluster.If Fusion has multiple Solr clusters, choose from the list which cluster you want to associate your collection with.
The cluster must exist first.Solr Cluster Layout
The next section lets you define a Replication Factor and Number of Shards. Define these options only if you are creating a new collection in the Solr cluster. If you are linking Fusion to an existing Solr collection, you can skip these settings.Solr Collection Import
Import a Solr collection to associate the new Fusion collection with an existing Solr collection. Enter a Solr Collection Name to associate the collection with an existing Solr collection. Then, enter a Solr Config Set to tell ZooKeeper to use the configurations from an existing collection in Solr when creating this collection.Time Series Partitioning
Available in 4.x only.
Configuring Collections
The Collections menu lets you configure your existing collection, including datasources, fields, jobs, stopwords, and synonyms.In the Fusion UI, from any app, the Collections icon displays on the left side of the screen.Some tasks related to managing a collection are available in other menus:- Configure a profile in Indexing > Indexing Profiles or Querying > Query Profiles.
- View reports about your collection’s activity in Analytics > Dashboards.
Collections Manager
The Collections Manager page displays details about the collection, such as how many datasources are configured, how many documents are in the index, and how much disk space the index consumes.This page also lets you create a new collection, disable search logs or signals, enable recommendations, issue a commit command to Solr, or clear a collection.Disable search logs
When you first create a collection, the search logs are created by default. The search logs populate the panels in Analytics > Dashboards.- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Disable Search Logs.
- On the confirmation screen, click Disable Search Logs.
- Fusion 5.x. Dashboards
- Fusion 4.x. Dashboards
Disable signals
When you first create a collection, the signals and aggregated signals collections are created by default.- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Disable Signals.
- On the confirmation screen, click Disable Signals.
Hard commit a collection
- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Hard Commit Collection.
- On the confirmation screen, click Hard Commit Collection.
Datasources
To access the Datasources page, click Indexing > Datasources. By default, there are no datasources configured right after installation.To add a new datasource, click New at the upper right of the panel.See the Connectors and Datasources Reference for details on how to configure a datasource. Options vary depending on the repository you would like to index.After you configure a datasource, it appears in a list on this screen. Click the name of a datasource to edit its properties. Click Start to start the datasource. Click Stop to stop the datasource before it completes. To the right, view information on the last completed job, including the date and time started and stopped, and the number of documents found as new, skipped, or failed.When you stop a datasource, Fusion attempts to safely close connector threads, finishing processing documents through the pipeline and indexing documents to Solr. Some connectors take longer to complete these processes than others, so might stay in a “stopping” state for several minutes.
- Fusion 5.x. Connector Datasources API
- Fusion 4.x. Connector Datasources API
Stopwords
The Stopwords page lets you edit a stopwords list for your collection.To add or delete stop words:- Click the name of the text file you wish to edit.
- Add a new word on a new line.
- When you are done with your changes, click Save.
- Click System > Import Fusion Objects.
- Choose the file to upload.
- Click Import >>.
Synonyms
Fusion has the same synonym functionality that Solr supports. This includes a list of words that are synonyms (where the synonym list expands on the terms entered by the user), as well as a full mapping of words, where a word is substituted for what the user has entered (that is, the term the user has entered is replaced by a term in the synonym list).See more about synonyms:You can edit the synonyms list for your collection.To access the Synonyms page in the Fusion UI, in any app, click Collections > Synonyms.Filter the list of synonym definitions by typing in the Filter… box.To import a synonyms list:- From the Synonyms page, click Import and Save. A dialog box opens.
- Choose the file to import.
- Enter new synonym definitions one per line.
- To enter a string of terms that expand on the terms the user entered, enter the terms separated by commas, like
Television, TV. - To enter a term that should be mapped to another term, enter the terms separated by an equal sign then a right angle bracket,
=>, likei-pod=>ipod.
- To enter a string of terms that expand on the terms the user entered, enter the terms separated by commas, like
- Remove a line by clicking the x at the end of the line.
- Once you are finished with edits, click Save.
Profiles
Profiles allow you to create an alias for an index or query pipeline. This allows you to send documents or queries to a consistent endpoint and change the underlying pipeline or collection as needed.Read about profiles in Index Profiles and Query Profiles:- Fusion 5.x.
- Fusion 4.x.
Learn more
Collections Menu Tour
The quick learning for Collections Menu Tour focuses on the Collections Menu features and functionality along with a brief description of each screen available in the menu.
_query_rewrite_stagingAs of Fusion 4.2, certain Spark jobs send their output to this collection. Rules are also written to this collection initially.
Some of the content in this collection requires manual review before it can be migrated to the_query_rewrite, where query pipelines can read it. See below for details._query_rewriteThis collection is optimized for high-volume traffic. Query pipelines can read from this collection to find rules, synonyms, spelling corrections, and more with which to rewrite queries and responses.
query_rewrite_staging to the _query_rewrite collection only when they are approved (either automatically on the basis of their confidence scores or manually by a human reviewer) _and a Fusion user clicks Publish. The review field value indicates whether a document will be published when the user clicks Publish:
review=auto | A job-generated document has a sufficiently high confidence score and is automatically approved for publication. |
review=pending | A job-generated document has an ambiguous confidence score and must be reviewed by a Fusion user. |
review=approved | A Fusion user has reviewed the document and approved it for publication. |
review=denied | A job-generated document has a low confidence score, or a Fusion user has reviewed and denied it for publication. |
Rules Simulator query profile
The Rules Simulator allows product owners to experiment with rules and other query rewrites in the_query_rewrite_staging collection before deploying them to the _query_rewrite collection.
Each app has a _rules_simulator query profile, configured to use the _query_rewrite_staging collection for query rewrites instead of the _query_rewrite collection. This profile is created automatically whenever a new app is created.
Query pipeline stages for query rewriting
These query rewriting stages are part of any default query pipeline:- Apply Rules query stage
This stage looks up rules that have been deployed to the response rewriting are applied by the Modify Response with Rules stage later in the pipeline. - Text Tagger query pipeline stage
This stage uses the SolrTextTagger handler to identify known entities in the query by searching either of the following: _query_rewritecollection. See Manage Collections in the Fusion UI for more information._query_rewrite_stagingcollection in the case of the Fusion AI query rewriting Simulator._query_rewritecollection. See Manage Collections in the Fusion UI for more information.
Manage Collections in the Fusion UI
Manage Collections in the Fusion UI
Collections can be created or removed using the Fusion UI or the REST API.For information about using the REST API to manage collections, see Collections API in the REST API Reference:You can map a Fusion collection to multiple Solr collections, known here as partitions, where each partition contains data from a specific time range.To configure time-based partitioning, under Time Series Partitioning click Enable.See Time-Based Partitioning for more information.To stop a datasource immediately, choose Abort instead of Stop.There is also a REST API for datasources:
- Fusion 5.x. Collections API
- Fusion 4.x. Collections API
Creating a Collection
When you create an app, by default Fusion Server creates a collection and associated objects.To create a new collection in the Fusion UI:- From within an app, click Collections > Collections Manager.
- At the upper right of the panel, click New.
- Enter a Collection name. This name cannot be changed later.
- To create the collection in the default Solr cluster and with other default settings, click Save Collection.
Creating a Collection with Advanced Options
To access advanced options for creating a collection in the Fusion UI:- From within an app, click Collections > Collections Manager.
- At the upper right of the panel, click New.
- Enter a Collection name. This name cannot be changed later.
- Click Advanced.
- Configure advanced options. The options are described below.
- Click Save Collection.
Solr Cluster
By default, a new collection is associated with the Solr instance that is associated with thedefault Solr cluster.If Fusion has multiple Solr clusters, choose from the list which cluster you want to associate your collection with.
The cluster must exist first.Solr Cluster Layout
The next section lets you define a Replication Factor and Number of Shards. Define these options only if you are creating a new collection in the Solr cluster. If you are linking Fusion to an existing Solr collection, you can skip these settings.Solr Collection Import
Import a Solr collection to associate the new Fusion collection with an existing Solr collection. Enter a Solr Collection Name to associate the collection with an existing Solr collection. Then, enter a Solr Config Set to tell ZooKeeper to use the configurations from an existing collection in Solr when creating this collection.Time Series Partitioning
Available in 4.x only.
Configuring Collections
The Collections menu lets you configure your existing collection, including datasources, fields, jobs, stopwords, and synonyms.In the Fusion UI, from any app, the Collections icon displays on the left side of the screen.Some tasks related to managing a collection are available in other menus:- Configure a profile in Indexing > Indexing Profiles or Querying > Query Profiles.
- View reports about your collection’s activity in Analytics > Dashboards.
Collections Manager
The Collections Manager page displays details about the collection, such as how many datasources are configured, how many documents are in the index, and how much disk space the index consumes.This page also lets you create a new collection, disable search logs or signals, enable recommendations, issue a commit command to Solr, or clear a collection.Disable search logs
When you first create a collection, the search logs are created by default. The search logs populate the panels in Analytics > Dashboards.- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Disable Search Logs.
- On the confirmation screen, click Disable Search Logs.
- Fusion 5.x. Dashboards
- Fusion 4.x. Dashboards
Disable signals
When you first create a collection, the signals and aggregated signals collections are created by default.- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Disable Signals.
- On the confirmation screen, click Disable Signals.
Hard commit a collection
- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Hard Commit Collection.
- On the confirmation screen, click Hard Commit Collection.
Datasources
To access the Datasources page, click Indexing > Datasources. By default, there are no datasources configured right after installation.To add a new datasource, click New at the upper right of the panel.See the Connectors and Datasources Reference for details on how to configure a datasource. Options vary depending on the repository you would like to index.After you configure a datasource, it appears in a list on this screen. Click the name of a datasource to edit its properties. Click Start to start the datasource. Click Stop to stop the datasource before it completes. To the right, view information on the last completed job, including the date and time started and stopped, and the number of documents found as new, skipped, or failed.When you stop a datasource, Fusion attempts to safely close connector threads, finishing processing documents through the pipeline and indexing documents to Solr. Some connectors take longer to complete these processes than others, so might stay in a “stopping” state for several minutes.
- Fusion 5.x. Connector Datasources API
- Fusion 4.x. Connector Datasources API
Stopwords
The Stopwords page lets you edit a stopwords list for your collection.To add or delete stop words:- Click the name of the text file you wish to edit.
- Add a new word on a new line.
- When you are done with your changes, click Save.
- Click System > Import Fusion Objects.
- Choose the file to upload.
- Click Import >>.
Synonyms
Fusion has the same synonym functionality that Solr supports. This includes a list of words that are synonyms (where the synonym list expands on the terms entered by the user), as well as a full mapping of words, where a word is substituted for what the user has entered (that is, the term the user has entered is replaced by a term in the synonym list).See more about synonyms:You can edit the synonyms list for your collection.To access the Synonyms page in the Fusion UI, in any app, click Collections > Synonyms.Filter the list of synonym definitions by typing in the Filter… box.To import a synonyms list:- From the Synonyms page, click Import and Save. A dialog box opens.
- Choose the file to import.
- Enter new synonym definitions one per line.
- To enter a string of terms that expand on the terms the user entered, enter the terms separated by commas, like
Television, TV. - To enter a term that should be mapped to another term, enter the terms separated by an equal sign then a right angle bracket,
=>, likei-pod=>ipod.
- To enter a string of terms that expand on the terms the user entered, enter the terms separated by commas, like
- Remove a line by clicking the x at the end of the line.
- Once you are finished with edits, click Save.
Profiles
Profiles allow you to create an alias for an index or query pipeline. This allows you to send documents or queries to a consistent endpoint and change the underlying pipeline or collection as needed.Read about profiles in Index Profiles and Query Profiles:- Fusion 5.x.
- Fusion 4.x.
Learn more
Collections Menu Tour
The quick learning for Collections Menu Tour focuses on the Collections Menu features and functionality along with a brief description of each screen available in the menu.
Spark jobs for query rewriting
This section describes how Spark jobs support query rewriting. These jobs read from the signals collection and write their output to the_query_rewrite_staging collection. High-confidence results are automatically migrated from there to the _query_rewrite collection, while ambiguous results remain in the staging collection until they are reviewed and approved. You can review job results in the Query Rewriting UI.
- Daily query rewriting jobs are created and scheduled automatically when you create a new app.
- Additional query rewriting jobs can be created manually.
Daily query rewriting jobs
When a new app is created, the jobs below are also created and scheduled to run daily, beginning 15 minutes after app creation, in the following order:-
Token and Phrase Spell Correction job
Detect misspellings in queries or documents using the numbers of occurrences of words and phrases. -
Phrase Extraction job
Identify multi-word phrases in signals. -
Synonym and Similar Queries Detection job
Use this job to generate pairs of synonyms and pairs of similar queries. Two words are considered potential synonyms when they are used in a similar context in similar queries.
The first and second jobs can provide input to improve the Synonym job’s output:- Token and Phrase Spell Correction job results can be used to avoid finding mainly misspellings, or mixing synonyms with misspellings.
- Phrase Extraction job results can be used to find pairs of synonyms with multiple tokens, such as “lithium ion”/“ion battery”.
Additional query rewriting jobs
These jobs also produce results that are used for query rewriting, but must be created manually:- Head/Tail Analysis job
Perform head/tail analysis of queries from collections of raw or aggregated signals, to identify underperforming queries and the reasons. This information is valuable for improving overall conversions, Solr configurations, auto-suggest, product catalogs, and SEO/SEM strategies, in order to improve conversion rates. - Ground Truth job
Estimate ground truth queries using click signals and query signals, with document relevance per query determined using a click/skip formula.
”rules” role for query rewriting users
The “rules” role provides permissions to access query rewriting features for all Fusion apps. A Fusion admin can create a user account with this role to give a business user access to the Query Rewriting UI.Query rewrite jobs post-processing cleanup
To perform more extensive cleanup of query rewrites, complete the procedures in Query Rewrite Jobs Post-processing Cleanup.Query Rewrite Jobs Post-processing Cleanup
Query Rewrite Jobs Post-processing Cleanup
The Synonym Detection job uses the output of the Misspelling Detection job and Phrase Extraction job. Therefore, post processing must occur in the order specified in this topic for the Synonym detection job cleanup, Phrase extraction job cleanup, and Misspelling detection job cleanup procedures. The Head-Tail Analysis job cleanup can occur in any order.
Synonym detection job cleanup
Use this job to remove low confidence synonyms.Prerequisites
Complete this:- AFTER the Misspelling Detection and Phrase Extraction jobs have successfully completed.
- BEFORE removing low confidence synonym suggestions generated in the post processing phrase extraction cleanup and misspelling detection cleanup procedures detailed later in this topic.
Remove low confidence synonym suggestions
Use either a Synonym cleanup method 1 - API call or the Synonym cleanup method 2 - Fusion Admin UI to remove low confidence synonym suggestions.Synonym cleanup method 1 - API call
-
Open the
delete_lowConf_synonyms.jsonfile.REQUEST ENTITY specifies the threshold for low confidence synonyms. Edit the upper range from 0.0005 to increase or decrease the threshold based on your data. -
Enter
<your query_rewrite_staging collection name/update>in the uri field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. -
Change the
idfield if applicable. -
Specify the upper confidence level in the entity field.
The entity field specifies the threshold for low confidence synonyms. Edit the upper range to increase or decrease the threshold based on your data.
Synonym cleanup method 2 - Fusion Admin UI
- Log in to Fusion and select Collections > Jobs.
- Select Add+ > Custom and Other Jobs > REST Call.
- Enter delete-low-confidence-synonyms in the ID field.
-
Enter
<your query_rewrite_staging collection name/update>in the ENDPOINT URI field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. - Enter POST in the CALL METHOD field.
- In the QUERY PARAMETERS section, select + to add a property.
- Enter wt in the Property Name field.
- Enter json in the Property Value field.
- In the REQUEST PROTOCOL HEADERS section, select + to add a property.
-
Enter the following as a REQUEST ENTITY (AS STRING)
<root><delete><query>type:synonym AND confidence: [0 TO 0.0005]</query></delete><commit/></root>REQUEST ENTITY specifies the threshold for low confidence synonyms. Edit the upper range from 0.0005 to increase or decrease the threshold based on your data.
Delete all synonym suggestions
To delete all of the synonym suggestions, enter the following in the REQUEST ENTITY section:<root><delete><query>type:synonym</query></delete><commit/></root>This entry may be helpful when tuning the synonym detection job and testing different configuration parameters.
Phrase extraction job cleanup
Use this job to remove low confidence phrase suggestions.Prerequisites
Complete this:- AFTER you complete Synonym detection job cleanup
Remove low confidence phrase suggestions
Use either a Phrase cleanup method 1 - API call or the Phrase cleanup method 2 - Fusion Admin UI to remove low confidence phrase suggestions.Phrase cleanup method 1 - API call
-
Open the
delete_lowConf_phrases.jsonfile. -
Enter
<your query_rewrite_staging collection name/update>in the uri field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. - Change the id field if applicable.
-
Specify the upper confidence level in the entity field.
The entity field specifies the threshold for low confidence phrases. Edit the upper range to increase or decrease the threshold based on your data.
Phrase cleanup method 2 - Fusion Admin UI
- Log in to Fusion and select Collections > Jobs.
- Select Add+ > Custom and Other Jobs > REST Call.
- Enter remove-low-confidence-phrases in the ID field.
-
Enter
<your query_rewrite_staging collection name/update>in the ENDPOINT URI field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. - Enter POST in the CALL METHOD field.
- In the QUERY PARAMETERS section, select + to add a property.
- Enter wt in the Property Name field.
- Enter json in the Property Value field.
- In the REQUEST PROTOCOL HEADERS section, select + to add a property.
-
Enter the following as a REQUEST ENTITY (AS STRING)
<root><delete><query>type:phrase AND confidence: [0 TO <insert value>]</query></delete><commit/></root>REQUEST ENTITY specifies the threshold for low confidence phrases. Edit the upper range to increase or decrease the threshold based on your data.
Delete all phrase suggestions
To delete all of the phrase suggestions, enter the following in the REQUEST ENTITY section:<root><delete><query>type:phrase</query></delete><commit/></root>This entry may be helpful when tuning the phrase extraction job and testing different configuration parameters.
Misspelling detection job cleanup
Use this job to remove low confidence spellings (also referred to as misspellings).Prerequisites
Complete this:- AFTER you complete Synonym detection job cleanup and Phrase extraction job cleanup
Remove misspelling suggestions
Use either a Misspelling cleanup method 1 - API call or the Misspelling cleanup method 2 - Fusion Admin UI to remove misspelling suggestions.Misspelling cleanup method 1 - API call
-
Open the
delete_lowConf_misspellings.jsonfile. -
Enter
<your query_rewrite_staging collection name/update>in the uri field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. - Change the id field if applicable.
-
Specify the upper confidence level in the entity field.
The entity field specifies the threshold for low confidence spellings. Edit the upper range to increase or decrease the threshold based on your data.
Misspelling cleanup method 2 - Fusion Admin UI
- Log in to Fusion and select Collections > Jobs.
- Select Add+ > Custom and Other Jobs > REST Call.
- Enter remove-low-confidence-spellings in the ID field.
-
Enter
<your query_rewrite_staging collection name/update>in the ENDPOINT URI field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. - Enter POST in the CALL METHOD field.
- In the QUERY PARAMETERS section, select + to add a property.
- Enter wt in the Property Name field.
- Enter json in the Property Value field.
- In the REQUEST PROTOCOL HEADERS section, select + to add a property.
-
Enter the following as a REQUEST ENTITY (AS STRING)
<root><delete><query>type:spell AND confidence: [0 TO 0.5]</query></delete><commit/></root>REQUEST ENTITY specifies the threshold for low confidence spellings. Edit the upper range from 0.5 to increase or decrease the threshold based on your data.
Delete all misspelling suggestions
To delete all of the misspelling suggestions, enter the following in the REQUEST ENTITY section:<root><delete><query>type:spell</query></delete><commit/></root>This entry may be helpful when tuning the misspelling detection job and testing different configuration parameters.
Head-tail analysis job cleanup
The head-tail analysis job puts tail queries into one of multiple reason categories. For example, a tail query that includes a number might be assigned to the ‘numbers’ reason category. If the output in a particular category is not useful, you can remove it from the results. The examples in this section remove the numbers category.Prerequisites
The head-tail analysis job cleanup does not have to occur in a specific order.Remove head-tail analysis query suggestions
Use either a Head-tail analysis cleanup method 1 - API call or the Head-tail analysis cleanup method 2 - Fusion Admin UI to remove query category suggestions.Head-tail analysis cleanup method 1 - API call
- Open the
delete_lowConf_headTail.jsonfile. - Enter
<your query_rewrite_staging collection name/update>in the uri field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. - Change the id field if applicable.
Head-tail analysis cleanup method 2 - Fusion Admin UI
- Log in to Fusion and select Collections > Jobs.
- Select Add+ > Custom and Other Jobs > REST Call.
- Enter remove-low-confidence-head-tail in the ID field.
- Enter
<your query_rewrite_staging collection name/update>in the ENDPOINT URI field. An example URI value for an app calledDC_Largewould beDC_Large_query_rewrite_staging/update. - Enter POST in the CALL METHOD field.
- In the QUERY PARAMETERS section, select + to add a property.
- Enter wt in the Property Name field.
- Enter json in the Property Value field.
- In the REQUEST PROTOCOL HEADERS section, select + to add a property.
- Enter the following as a REQUEST ENTITY (AS STRING)
Delete all head-tail suggestions
To delete all of the head-tail suggestions, enter the following in the REQUEST ENTITY section:<root><delete><query>type:tail</query></delete><commit/></root>This entry may be helpful when tuning the head-tail job and testing different configuration parameters.