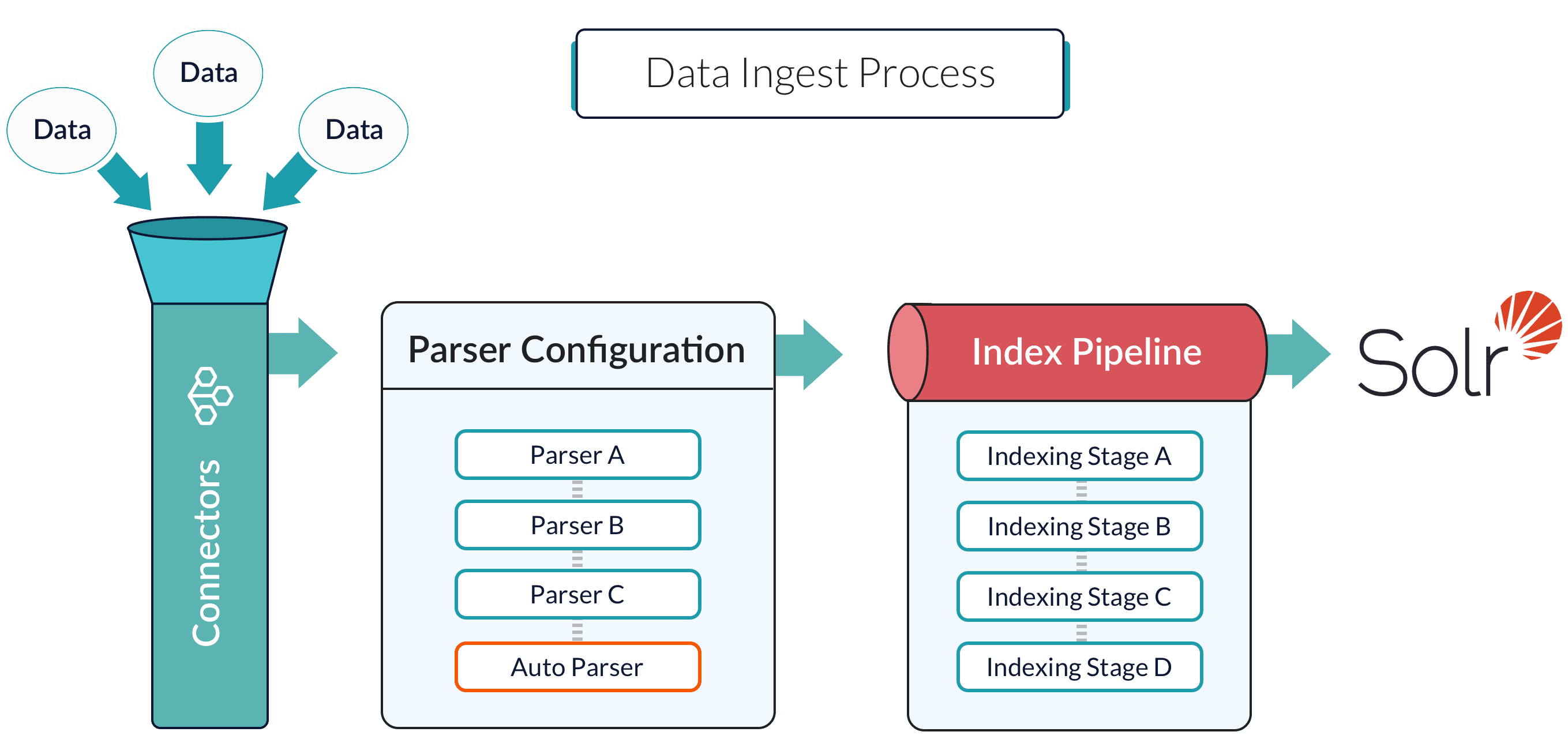
PipelineDocument objects for indexing by Fusion-managed Solr service.
An index pipeline consists of a series of configurable
index pipeline stages,
each performing a different transformation on the data before passing the result to the next stage in the pipeline.
The final stage is the
Solr Indexer stage,
which transforms the PipelineDocument into a Solr document and submits it to Solr for indexing in a specific
Collection.
Each configured datasource has an associated index pipeline and uses a
connector
to fetch data to parse and then input into the index pipeline.
Import Data with the REST API
Import Data with the REST API
It is often possible to get documents into Fusion by configuring a datasource with the appropriate connector.But if there are obstacles to using connectors, it can be simpler to index documents with a REST API call to an index profile or pipeline.These requests are sent as a POST request. The request header specifies the format of the contents of the request body. Create an index profile in the Fusion UI.To send a streaming list of JSON documents, you can send the JSON file that holds these objects to the API listed above with To prevent the terminal from displaying all the data and metadata it indexes—useful if you are indexing a large file—you can optionally append In Fusion 5, documents can be created on the fly using the PipelineDocument JSON notation.You can use
Push documents to Fusion using index profiles
Index profiles allow you to send documents to a consistent endpoint (the profile alias) and change the backend index pipeline as needed. The profile is also a simple way to use one pipeline for multiple collections without any one collection “owning” the pipeline.You can send documents directly to an index using the Index Profiles REST API. The request path is:application/json as the content type. If your JSON file is a list or array of many items, the endpoint operates in a streaming way and indexes the docs as necessary.Send data to an index profile that is part of an app
Accessing an index profile through an app lets a Fusion admin secure and manage all objects on a per-app basis. Security is then determined by whether a user can access an app. This is the recommended way to manage permissions in Fusion.The syntax for sending documents to an index profile that is part of an app is as follows:Spaces in an app name become underscores. Spaces in an index profile name become hyphens.
?echo=false to the URL.Be sure to set the content type header properly for the content being sent. Some frequently used content types are:- Text:
application/json,application/xml - PDF documents:
application/pdf - MS Office:
- DOCX:
application/vnd.openxmlformats-officedocument.wordprocessingml.document - XLSX:
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet - PPTX:
application/vnd.vnd.openxmlformats-officedocument.presentationml.presentation - More types: http://filext.com/faq/office_mime_types.php
- DOCX:
Example: Send JSON data to an index profile under an app
In$FUSION_HOME/apps/solr-dist/example/exampledocs you can find a few sample documents. This example uses one of these, books.json.To push JSON data to an index profile under an app:- Create an index profile. In the Fusion UI, click Indexing > Index Profiles and follow the prompts.
- From the directory containing
books.json, enter the following, substituting your values for username, password, and index profile name: - Test that your data has made it into Fusion:
- Log into the Fusion UI.
- Navigate to the app where you sent your data.
- Navigate to the Query Workbench.
- Search for
*:*. - Select relevant Display Fields, for example
authorandname.
Example: Send JSON data without defining an app
In most cases it is best to delegate permissions on a per-app basis. But if your use case requires it, you can push data to Fusion without defining an app.To send JSON data without app security, issue the following curl command:Example: Send XML data to an index profile with an app
To send XML data to an app, use the following:Remove documents
Example 1
The following example removes content:Example 2
A more specific example removes data frombooks.json. To delete “The Lightning Thief” and “The Sea of Monsters” from the index, use their id values in the JSON file.The del-json-data.json file to delete the two books:?echo=false to turn off the response to the terminal.Example 3
Another example to delete items using the Push API is:Send documents to an index pipeline
Although sending documents to an index profile is recommended, if your use case requires it, you can send documents directly to an index pipeline.For more information about index pipeline REST API reference documentation, see Fusion 5.x Index Pipelines API.Specify a parser
When you push data to a pipeline, you can specify the name of the parser by adding a parserId querystring parameter to the URL. For example:https://FUSION_HOST:FUSION_PORT/api/index-pipelines/INDEX_PIPELINE/collections/COLLECTION_NAME/index?parserId=PARSER.If you do not specify a parser, and you are indexing outside of an app (https://FUSION_HOST:FUSION_PORT/api/index-pipelines/...), then the _system parser is used.If you do not specify a parser, and you are indexing in an app context (https://FUSION_HOST:FUSION_PORT/api/apps/APP_NAME/index-pipelines/...), then the parser with the same name as the app is used.Indexing CSV Files
In the usual case, to index a CSV or TSV file, the file is split into records, one per row, and each row is indexed as a separate document.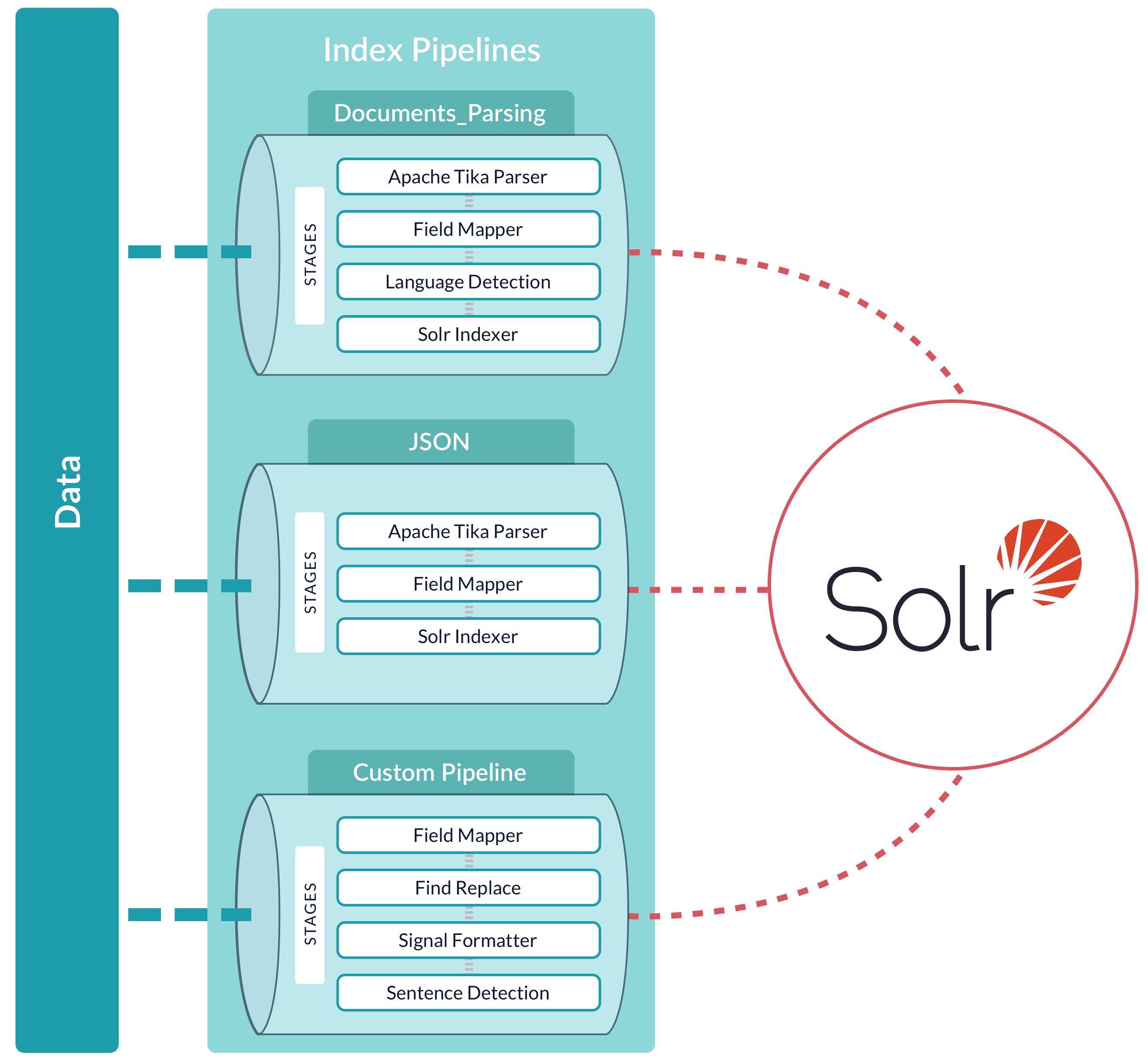
Debugging
If your pipeline is not producing the desired result, these debugging tips can help you identify the source of the issue and resolve it.View parameters
When debugging a pipeline, it helps to see the parameters that are being passed to or from each stage. There are several ways to exposed those parameters:Add a Logging stage to view parameters
Add a Logging stage to view parameters
Follow these steps to add a Logging stage to your pipeline:
- In Fusion UI, navigate to Indexing > Index Pipelines (for index pipelines) or Querying > Query Pipelines (for query pipelines).
- Click Add a new pipeline stage.
- Select Logging from the Troubleshooting section.
- In the Label field, enter a descriptive name (for example, “Debug After Vectorize”).
- Set the detailed property to
trueto print the full Request or PipelineDocument object. - Place the Logging stage after the stage you want to debug.
- Click Save.
- Run your pipeline and check the appropriate log file for your pipeline type:
- Query pipelines:
https://FUSION_HOST/var/log/api/api.log - Index pipelines:
https://FUSION_HOST/var/log/api/fusion-indexing.log
- Query pipelines:
Use JavaScript to inspect context variables
Use JavaScript to inspect context variables
Follow these steps to inspect context variables:
- Add a JavaScript stage to your pipeline.
- Use the
ctxvariable to inspect context data: - Check logs at
https://FUSION_HOST/var/log/api/api.log.
Use debug info in Query Workbench
Use debug info in Query Workbench
Follow these steps to debug using Query Workbench:
- Navigate to Querying > Query Workbench.
- Enter a test query and click Search.
- Click the Debug tab. The debug view displays the following information:
- Request parameters
- Pipeline stage execution details
- Response data including
responseHeaderanddebug.explain
- Switch to View As: JSON to see the full response structure.
Enable Fail on Error
The Fail on Error setting determines whether silent failures can occur in your pipeline. By enabling Fail on Error during development, testing, and troubleshooting, you ensure that configuration issues, authentication problems, or model errors are immediately visible rather than producing incomplete or incorrect data that can be difficult to troubleshoot later.Configure the Fail on Error setting in LWAI stages
Configure the Fail on Error setting in LWAI stages
The Fail on Error setting controls whether pipeline execution stops when an LWAI stage encounters an error. Follow these steps to configure this setting:
- In Fusion UI, navigate to your pipeline (Index or Query).
- Click the LWAI stage you want to configure (for example, LWAI Vectorize Field or LWAI Vectorize Query).
- Locate the Fail on Error checkbox at the bottom of the stage configuration.
- Select the checkbox to enable any of the following behaviors:
- Stop pipeline processing and throw an exception on errors
- Get immediate feedback when LWAI models fail or are misconfigured
- Guarantee data quality by preventing indexing of documents without vectors
In production environments, keep this feature disabled to ensure that service is not interrupted when errors occur.
- Click Save.
Test the Fail on Error configuration
Test the Fail on Error configuration
Follow these steps to verify your Fail on Error configuration:
- Trigger an intentional error (for example, use an invalid model name or account).
- Verify that the pipeline fails (when Fail on Error is enabled) or continues (when Fail on Error is disabled).
- Review logs at
https://FUSION_HOST/var/log/api/api.logfor error messages.