To further illustrate key concepts about the Fusion 5 architecture, this section describes how query execution works and the microservices involved. Note some important details: import from ‘/snippets/LwTemplate.jsx’;Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
- There are many microservices involved in query execution. This illustrates the value and importance of having a robust orchestration layer like Kubernetes.
- Fusion comes pre-configured. You don’t need to configure all details depicted below.
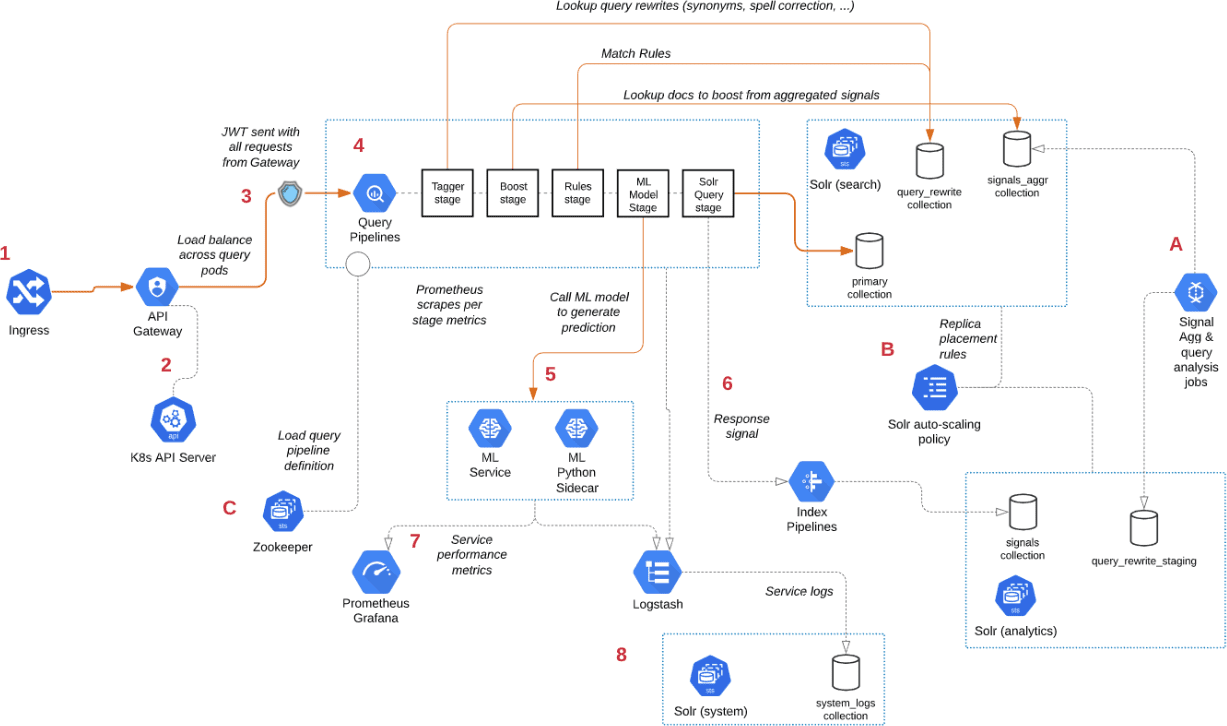
- Point A - Background Spark jobs aggregate signals—which powers the signal boosting stage—and analyzes signals for query rewriting operations. This includes head/tail, synonym detection, and misspelling detection.
- Point B - Fusion uses a Solr auto-scaling policy in conjunction with Kubernetes node pools to govern replica placement for various Fusion collections. For example, to support high performance query traffic, place the primary collection with sidecar collections for query rewriting, signal boosting, and rules matching. Solr pods supporting high volume, low-latency reads are backed by an HPA linked to CPU or custom metrics in Prometheus. Fusion services store configurations, such as query pipeline definitions, in ZooKeeper (Point C).
- Point 1 - A query request comes into the cluster from a Kubernetes Ingress. The Ingress routes requests to the Fusion API Gateway service. The gateway performs authentication and authorization to ensure the user has the correct permissions to execute the query. The Fusion API Gateway load-balances requests across multiple query pipeline services using native Kubernetes service discovery (Point 2).
- Point 3 - The gateway issues a JWT, which is sent to downstream services. An internal JWT has identifying information about a user, including their roles and permissions, to allow Fusion services to perform fine-grained authorization. The JWT is returned as a Set-Cookie header to improve performance of later requests. Alternatively, API requests can use the
/oauth2/tokenendpoint in the gateway to retrieve the JWT using OAuth2 semantics. - Point 4 - The query service executes the pipeline stages to enrich the query, before sending it to the primary collection. Typically, this involves multiple lookups to sidecar collections—such as the
APP_NAME_query_rewritecollection—to perform spell correction, synonym expansion, and rules matching. The query pipeline may also call out to the Fusion ML Model service to generate predictions, such as deciding query intent. The ML Model service may also use an HPA tied to CPU, to scale out and support the desired queries per second (Point 5). - Point 6 - After executing the query in the primary collection, Fusion generates a response signal to track query request parameters and Solr response metrics, such as
numFoundandqTime. Fusion stores raw signals in the signals collection, which typically runs in the analytics partition to support high-volume writes. - Point 7 - Every Fusion microservice exposes detailed metrics. Prometheus scrapes the metrics using pod annotations. The query microservice exposes stage-specific metrics to help you understand query performance.
- Point 8 - Every Fusion microservice sends logs to Logstash. You can configure Logstash to index log messages into the
system_logscollection in Solr or to an external service like Elastic.
Autoscaling in Fusion
The course for Autoscaling in Fusion focuses on understanding how autoscaling works in Fusion.