Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
Compatible with Fusion version: 4.0.0 through 5.2.2
Configure a Box.com datasource
Configure a Box.com datasource
The Box connector retrieves data from a Box.com cloud-based data repository.This topic applies to the Box.com V1 and Box.com V2 connectors. The Box.com V1 connector is available in Fusion 5.2 and earlier. The Box.com V2 connector is available in Fusion 5.3 and later.Following is an overview of the steps required to set up Box and Fusion, and to crawl a Box data repository.
Configuration overview
These steps are for a multi-user Box.com data repository. For limited testing using a single user account, you can create a Box app that uses Standard OAuth 2.0 authentication.
- Sign up for a Box developer account.
- Enable 2-step verification.
- Create a Box app that Fusion can use to crawl the Box files.
- Configure your app to use a Box service account.
- Install Fusion’s Box Connector.
- Create datasources in Fusion that use the Box connector.
- Crawl the Fusion datasources.
Set Up Box
Set up Box so that Fusion can crawl Box data repositories.Step 1: Sign Up for a Box Developer Account
If you already have an account, proceed to Step 2: Enable 2-Step Verification.- Open the Box Developers Console.
- In the top right corner, click Sign Up.
- Select an appropriate Platform Developer plan.
- Enter the requested information and click Submit.
- Open the confirmation email and click Verify Email.
- Log in to your Box account.
Step 2: Enable 2-Step Verification
- Log in to your Box developer account.
- Open the Box Developers Console.
- Log in as the admin.
- Create the Box account that you want to use for crawling.
- Open the Users page in the Box admin console.
- Click +Users to create a new user account.
- Enter the Name and Email for the user, and then click Add user.
- Click the user you just created to enter its user settings.
-
Make this user a Co-Admin by selecting Co-Admin checkbox. Once clicked, a pane titled “User is granted the following administrative privileges” appears. Select all of the following:
- Manage users
- Manage groups
- View users’ content
- Log in to users’ accounts
-
Run new reports and access existing reports
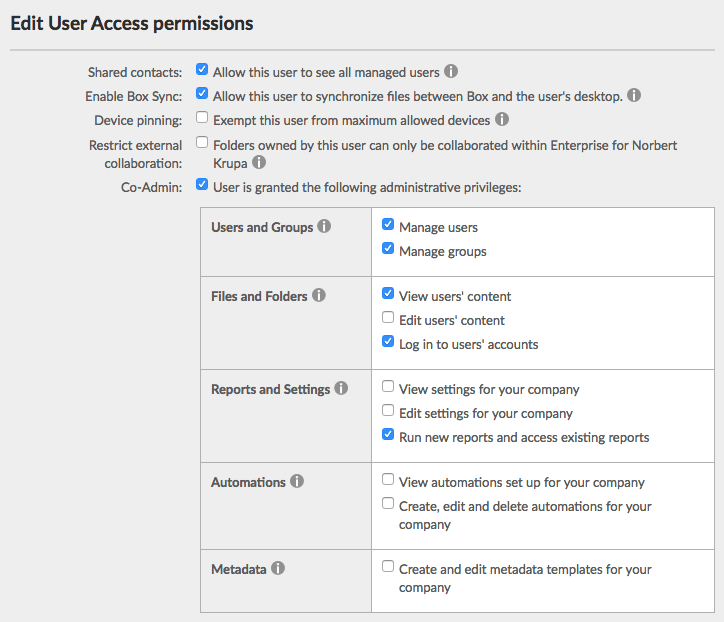
- Click Save.
- Close the Admin Console browser tab.
- Enable 2-step verification for unrecognized logins:
- Open the Account Settings page. (You can reach this page from the drop-down menu under your initials.)
- On the Account tab, under Authentication, select Require 2-step verification for unrecognized logins.
- Choose your Country and enter a Mobile Phone Number, and then click Continue.
- Enter the verification code you receive, and then click Continue.
- If you are using a new mobile device, Box will send you a second code. Enter it, and then click Submit.
- Click Save Changes.
Step 3: Create a Box App that Fusion Can Use to Crawl the Box files
Create a Box app that uses OAuth 2.0 with JWT server authentication.If you already have an app, proceed to Step 4: Configure Your App to Use a Box Service Account.- Open the Box Developers Console.
- Click Create New App.
- Select Custom App, and then click Next.
- Click OAuth 2.0 with JWT (Server Authentication), and then click Next.
- Name your app, and then click Create App. The name must be globally unique across all apps created by all Box users.
- Click View Your App.
Step 4: Configure Your App to Use a Box Service Account
-
Use OpenSSL to create a private/public key pair:
- Install OpenSSL if you need to. Windows instructions are here.
-
Open a Command Prompt window and run these commands to generate a private/public key pair:
Enter a password for the private key when prompted.In the current directory of the Command Prompt, you now have private and public key files,
private_key.pemandpublic_key.pemrespectively.
- Open the Box Developers Console, log in as Admin if you are asked to log in, and click your app.
- In the left navigation menu, click Configuration.
-
Configure scopes and advanced features:
- Under Application Access, select Enterprise.
- Under Application Scopes, deselect Manage groups.
- Under Advanced Features, enable Generate User Access Tokens and Perform Actions as Users.
- Click Save Changes.
-
In the Add and Manage Public Keys area, click Add a Public Key and paste the contents of the
public_key.pemfile (generated from Step 4: Configure Your App to Use a Box Service Account) into the text box.- Make a note of the new Public Key ID that you just created.
- Under OAuth 2.0 Credentials, click COPY for the Client ID.
-
Authorize your app:
- Open the Box Admin Console.
- In the left navigation menu, click Settings > Enterprise Settings (or Business Settings) > Apps.
- Under Custom Applications, click Authorize New App.
- In the API Key box, paste the Client ID credential you copied in Step 6, and then click Next.
- Read the App Authorization dialog and click Authorize.
- Close the Admin Console browser tab.
If you change your app’s configuration later, you must repeat this step to re-authorize your app. - Close the Dev Console browser tab.
Set Up Fusion
Set up Fusion to crawl Box data repositories.Step 5: Install Fusion’s Box Connector
- Navigate to the Fusion 4.x Connector Downloads
- Select the Box connector link for the release to download. The .zip file is downloaded.
- Do not unzip the file.
- Open the Fusion UI and click System > Blobs.
- Click Add.
- Select Connector Plugin.
- Click Choose File, select the file, and then click Open.
- Click Upload.
Step 6: Create Datasources
Create datasources that use the Box connector to access the Box data repository.For each datasource:- In the Fusion UI, Navigate to Indexing > Datasources.
- Click Add.
- Select Box.com.
-
Fill in the form. Note the following regarding configuration settings to use:
Setting Notes Start Links Each start link defined for the datasource must consist of a numeric Box file ID or directory ID. The root directory of any Box account has ID 0 (zero). To crawl your entire Box repository, enter ‘0’. These images indicate with underlines where you can get a folder ID or file ID. Select a folder or file at Box.com. Folder ID:  Enter the start link
Enter the start link 34192617287. File ID: Enter the start link
Enter the start link 204871656422:API Key In the Box Developers Console, select the app. On the Configuration tab under OAuth 2.0 Credentials, use the Client ID. API Secret In the Box Developers Console, select the app. On the Configuration tab under OAuth 2.0 Credentials, use the Client Secret. JWT App User ID Email address that you use to sign in to your Box co-admin account. Use the Co-admin account you created in Step 4. JWT Public Key Id In the Box Developers Console, select the app. On the Configuration tab, under Add and Manage Public Keys, use the ID for a public key. JWT Private Key Base64-encoded contents of the private-key file that matches your JWT Public Key Id. Base64 encode the entire contents of the file, including the first and last lines. (Fusion 5.0+ only.) JWT Private Key File Full path to the private-key file you created that matches your JWT Public Key Id. (Prior to Fusion 5.0 only.) JWT Private Key Password Passphrase for the private key (from the private-key file you created in Step 4). Distributed crawl collection name Collection that contains the pre-fetch index. Box.com children responses per page Use the default value of 1000. Nested folder depth limit Generally, you want a number that will crawl all documents, so keep the default value. For testing, you could reduce the number substantially to speed up the crawl. Number of partition buckets Divide the number of files by 5000. Use that number or 10000, whichever is smaller. Number distributed crawl datasources Use 1 to 27. Number of pre-fetch index creator threads A number between 2 and 5. Use 2 for small datasources and 5 for huge datasources (over 10 million files). - Click Save.
Crawl a Box Data Repository
Crawl a Box data repository.Step 7: Crawl the Fusion Datasources
Crawl the datasources, which use Fusion’s Box connector to access the Box data repository. Fusion’s Box connector uses the pre-fetch index to fetch the contents of each file from Box.com, get metadata from both the distributed index and Box.com, and index the documents through Fusion’s index pipeline.You can:-
Run the crawl now.
- From the Fusion launcher, click Search > Home > Datasources.
- Click the datasource.
- Click Start Crawl.
-
Schedule the crawl (For Fusion 4.2 through 5.5):
- From the Fusion launcher, click Devops > Home > Scheduler.
- Click the row for the job that corresponds to the datasource.
- Specify schedule information, and then click Save.
Configure Box.com tokens
Configure Box.com tokens
This topic explains how to configure Box.com authorization, access, and refresh tokens. The information applies to the Box.com V1 and Box.com V2 connectors. The Box.com V1 connector is available in Fusion 5.2 and earlier. The Box.com V2 connector is available in Fusion 5.3 and later.Fusion supports two methods of authentication with the Box API:
- JSON Web Token (JWT)
- OAuth2
Box App Users Using JWT
Box.com has rather recently released a Box Developer Edition. The Box Developer Edition lets a user access an application without having to create their own Box account.App Auth uses the JSON Web Token (JWT) authentication architecture to establish a trusted connection with Box, allowing an application to provision and manage a Box account while minimizing the number of logins for a user and authentication services to manage.For this option, Fusion needs the inputs below to crawl your Box data.Required options are highlighted.| UI Label, API Name | Description |
JWT App User IDf.fs.appUserId | The Developer Edition API App User ID that you want to crawl as. |
JWT Public Key IDf.fs.publicKeyId | The public key prefix registered in Box Auth that you want to use to authenticate with. |
JWT Private Keyf.fs.privateKeyBase64 | Base64-encoded JWT private key for the app user you want to authenticate as. (Fusion 5.0+ only.) |
JWT Private Key File Pathf.fs.privateKeyFile | Path to the JWT private key file for the app user you want to authenticate as. (Prior to Fusion 5.0 only.) |
JWT Private Key File Passwordf.fs.privateKeyPassword | The password that secures the public key. |
Authentication Using OAuth 2.0
For limited testing using a single user account, you can create a Box app that uses Standard OAuth 2.0 authentication.- Log in to your Box developer account as the Admin.
- Open the Box Developers web portal.
- In the top right corner, click Log In.
- Open the page for creating a new app and click Create New App.
- Click Custom App, and then click Next.
- Click Standard OAuth 2.0 (User Authentication), and then click Next.
- Name your app, and then click Create App. The name must be globally unique across all apps created by all Box users.
- Click View Your App.
- On the Configuration page:
- Click the Authentication Method Standard OAuth 2.0 (User Authentication).
- Set the Redirect URI to
http://localhostorhttp://0.0.0.0. This address is not used by Fusion, but cannot be left blank. - Click Save Changes.
Deprecation and removal noticeThis connector is deprecated as of Fusion 5.2 and is removed or expected to be removed as of Fusion 5.3. Use the Box V2 connector instead.For more information about deprecations and removals, including possible alternatives, see Deprecations and Removals.
How the Box Connector Works
This section is only relevant to Fusion 5.1 and earlier.
-
Build a pre-fetch index. The Box connector crawls file metadata user-by-user. It creates a distributed pre-fetch index that describes the structure of files in the repository. The pre-fetch index contains basic file metadata—file IDs and the directory relationships. Fusion stores the pre-fetch index in Solr as a system collection called
system_box_distributed_crawl, which is shared by all Box.com datasources. The pre-fetch index lets the Box connector crawl files randomly, file-by-file; instead of user-by-user. This gets around Box rate limits. - Build the file index. The Box connector crawls files file-by-file. It uses the pre-fetch index to fetch the contents of files and metadata. It indexes the documents through Fusion’s index pipeline.
-
Clear the
system_box_distributed_crawlcollection manually:- Navigate to Collections > Collections Manager.
- Hover over
system_box_distributed_crawl, and then click the Configure icon. - Click Clear Collection.
-
Create a new distributed crawl collection for the datasource by editing the Distributed crawl collection name field (
f.fs.distributedCrawlCollectionName) in your datasource configuration.
Request batching deprecation
Starting in Fusion 5.2, request batching is deprecated with the Box 2.39.0 release.Start links
While crawling with folders as start links on the Box connector, the crawling user (JWT App User ID) must either:- Be the owner of folders
- Have access to the start links folders
startLinks defined for the datasource must include the numeric Box file and directory IDs. The root directory of any Box account has an ID of 0 (zero). If you want to crawl your entire Box repository, you should enter ‘0’.