Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
Compatible with Fusion version: 4.2.4 through 4.2.6
Deprecation and removal noticeThis connector is deprecated as of Fusion 4.2 and is removed or expected to be removed as of Fusion 5.0. Use the SharePoint Optimized V2 connector instead.For more information about deprecations and removals, including possible alternatives, see Deprecations and Removals.
Learn more
Configure a SharePoint Online V1 Optimized Datasource
Configure a SharePoint Online V1 Optimized Datasource
The SharePoint Online V1 Optimized connector retrieves data from cloud-based SharePoint repositories. Authentication requires a Sharepoint user who has permissions to access Sharepoint via the SOAP API. This user must be registered with the Sharepoint Online authentication server; it is not necessarily the same as the user in Active Directory or LDAP.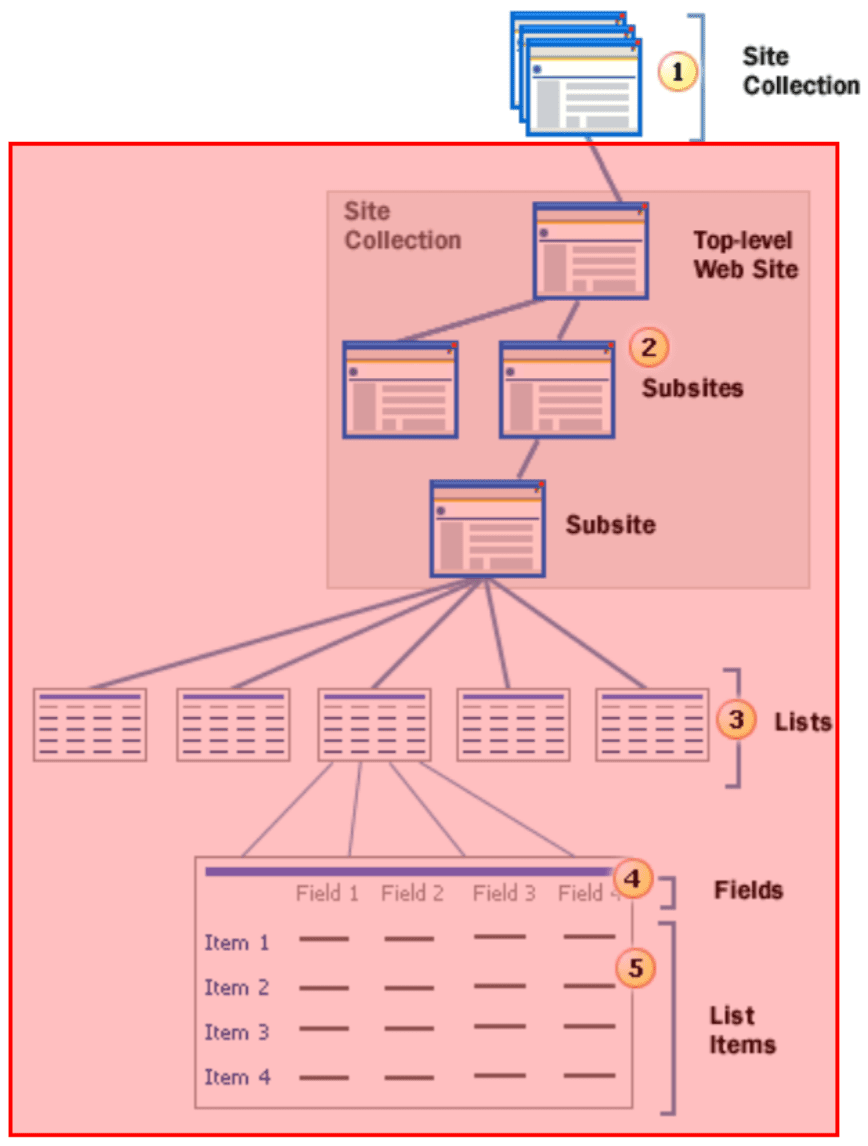
Decide what you need to crawl
The first and most important thing to do is determine what you are trying to crawl, and to pick your “Start Links” accordingly.Choose one of the following:- An entire SharePoint Web application (all site collections in a specific SharePoint URL).
- A subset of SharePoint site collections.
- A specific sub-site, list, or list item.
How to crawl an entire SharePoint Web application
- Leave the Limit Documents > Fetch all site collections option checked (as it is by default).
-
Specify the Web application URL as a site.
For example:
https://lucidworks.sharepoint.local/
Crawling an entire SharePoint Web application requires administrative access to SharePoint.
How to crawl a subset of SharePoint site collections
- Uncheck the Limit Documents > Fetch all site collections option.
-
Specify a “Start Link” for each site collection that you want to crawl.
Examples:
https://lucidworks.sharepoint.local/sites/site1,https://lucidworks.sharepoint.local/sites/site2,https://lucidworks.sharepoint.local/sites/site3
How to crawl a specific sub-site, list, or list item:
- Uncheck the Limit Documents > Fetch all site collections option.
- Specify a “Start Link” for each site collection that contains the item you want to fetch.
-
Specify a non-wildcard Inclusive Regular Expression for each parent.
For example, if you want to crawl
https://lucidworks.sharepoint.local/sites/mysitecol/myparentsite/somesitethen you must include inclusive regexes for all parents along the way:If you exclude a parent item of the site, the connector will not crawl the site because it will never spider down to it during the crawl process.
Choose an authentication method
With the SharePoint Online connector, you have several options for authenticating.-
SharePoint service account - This method is the equivalent of logging in under a user account. If the account is not an admin user, however, you need to grant the account access to each site collection you want to crawl.
Required parameters:
- Username
- Password
- Tenant
-
App-only authentication using Azure AD with a private key - Using this method requires the application key to have “Full Control” permissions. Otherwise, security authorization errors occur while crawling. This is the most commonly used method.
Required parameters:
- Client ID
- PFX key in Base64 format
- PFX key password
- Tenant
- Click API permissions in the left panel.
- Navigate to Application permissions > Sites.
- Select the Sites.FullControl.All check box.
- Click Add permissions to save the changes.
For detailed information about configuration, see Granting access via Azure AD App-Only.If the Sites.FullControl.All option is not selected, 403 errors are generated while crawling.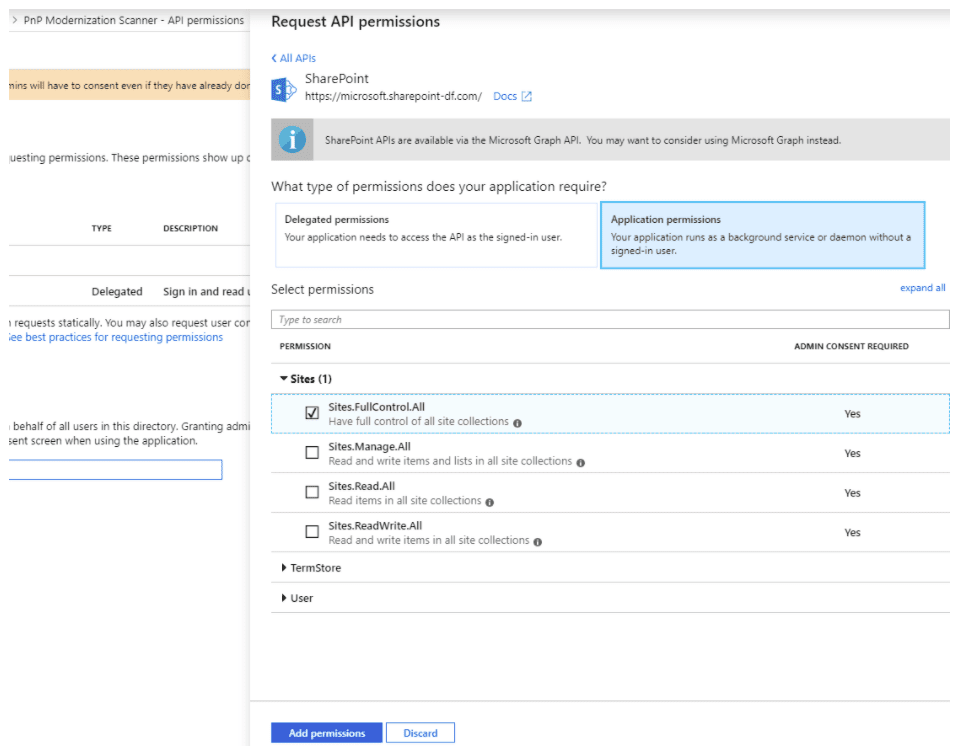
-
App-only authentication using Azure AD with OAuth - Using this method requires the application key to have “Full Control” permissions. Otherwise, security authorization errors occur while crawling. This is the least commonly used method.
Required parameters:
- Client ID
- Client secret
- Tenant
- Set up a crawl account with only as much permission as it needs.
If the Right field is not set to FullControl, 403 errors are generated while crawling.
How to set up a crawl account
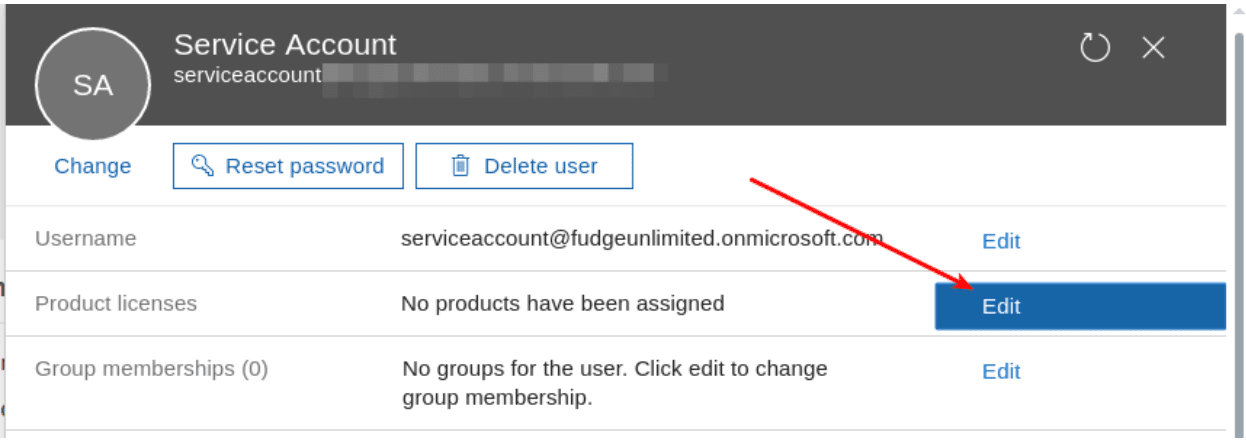
1. Create a service account and license the account (if needed)
If you are crawling SharePoint Online, you may need to create a license for the crawl account.Log in as a SharePoint administrator, and go to your admin center.-
If you are using an on-premise active directory synced to SharePoint Online, then you need to create an Active Directory account, and license the Active Directory account on SharePoint Online.
-
If you are using SharePoint Online user accounts, add a user as the “Lucidworks Fusion service account”.
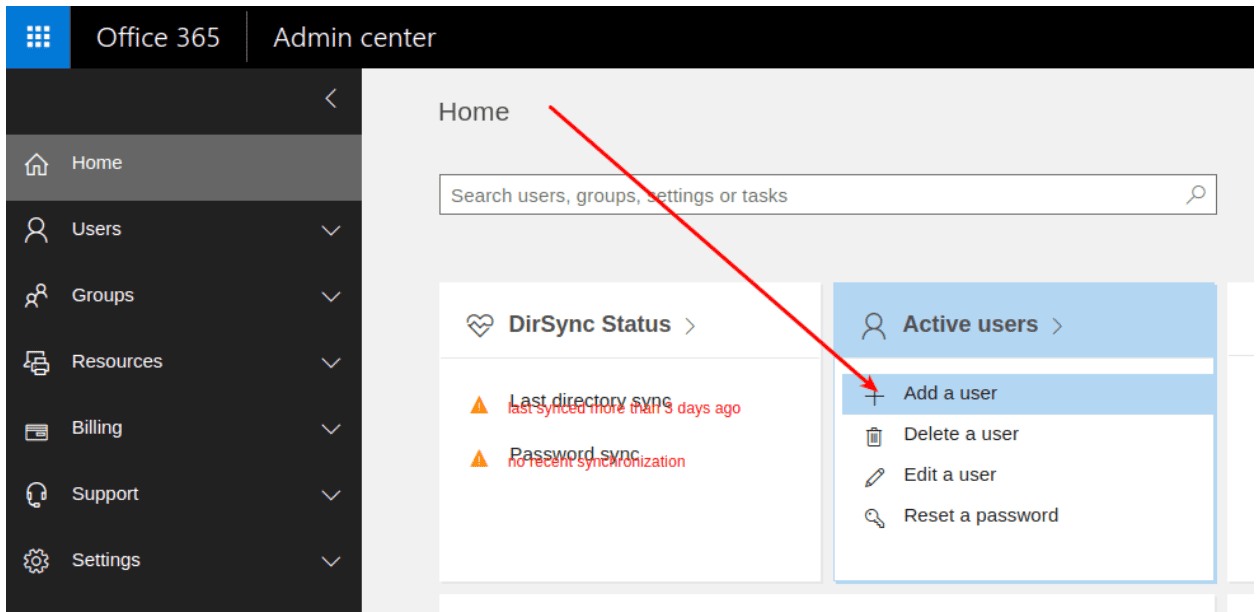
Add the user as “User (no administrator access)”.
2. Create a Lucidworks Fusion crawl permission
- Navigate to Azure Active Directory > Conditional Access > Policies.
- Click New Policy.
- Click New permission level. In this example, the permission level is named “LW Fusion”.
-
Grant the following permissions:
- View Items - View items in lists and documents in document libraries.
- Open Items - View the source of documents with server-side file handlers.
- View Versions - View past versions of a list item or document.
- View Application Pages - View forms, views, and application pages. Enumerate lists.
- Browse Directories - Enumerate files and folders in a Web site using SharePoint Designer and Web DAV interfaces.
- View Pages - View pages in a Web site.
- Enumerate Permissions - Enumerate permissions on the Web site, list, folder, document, or list item.
- Browse User Information - View information about users of the Web site.
- Use Remote Interfaces - Use SOAP, Web DAV, the Client Object Model or SharePoint Designer interfaces to access the Web site.
- Open - Allows users to open a Web site, list, or folder in order to access items inside that container.
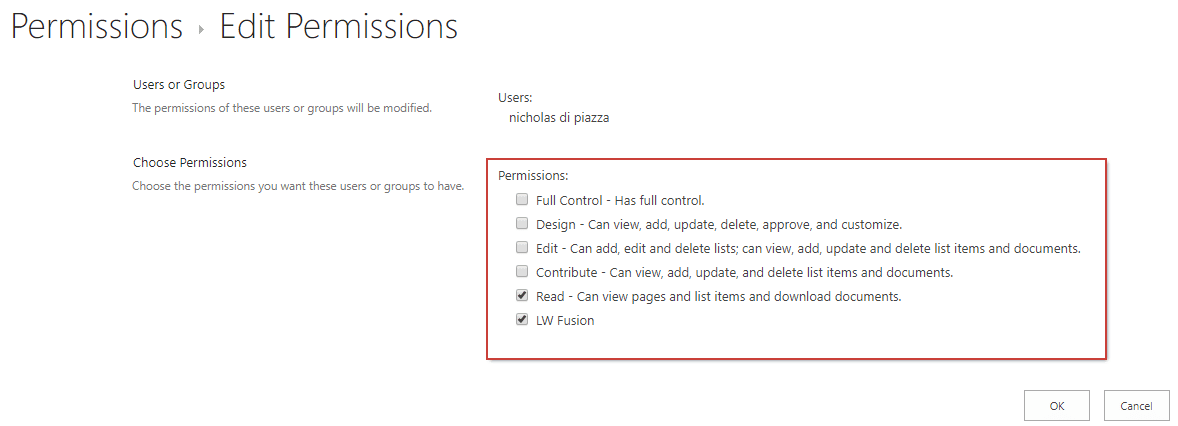
3. Grant user permission to the user policy
- Navigate to Site settings > Site permissions > Advanced Permissions Settings > Grant permissions.
- Enter the desired user.
-
Grant Read and your custom Fusion permissions, “LW Fusion”, for this user:
Limitations of a crawling SharePoint Online with a non-administrative account
There is one important drawback of crawling SharePoint Online with a non-administrative account: Only SharePoint Online Administrators are allowed to list site collections from SharePoint Online.So if you want to crawl multiple site collections from your SharePoint Online tenant, you must either- list them in the Start Links explicitly, or
- provide a SharePoint administrator account when crawling SharePoint Online.
https://lucidworks.sharepoint.com/sites/sitecol, such as
https://lucidworks.sharepoint.com/sites/sitecol/subsite1,
https://lucidworks.sharepoint.com/sites/sitecol/subsite2,
and so on.But only an admin can list the Site Collections in https://lucidworks.sharepoint.com.How to provide admin access to crawl
You have several options for giving administrative access to Fusion to crawl your accounts, including:- You can create a service account with admin access (not recommended).
- You can create an app-only authentication key. If you choose this approach, you can either use OAuth or the JWT private key option.