B2C
Imagine your business has 1 million products distributed through 5,000 stores, and each store’s pricing varies.
That’s 5 billion pricing permutations you need to access on demand.By storing those permutations in Dynamic Index, you keep your main index lean and fast, so customers get accurate pricing instantly on every product in every store.
B2B
Imagine your company sells industrial components to 50,000 accounts, each with custom pricing and contract terms.
That’s 50,000 distinct permutations of product data.By storing those variations in Dynamic Index, you keep your product index streamlined while ensuring that every customer sees accurate pricing based on their unique account.
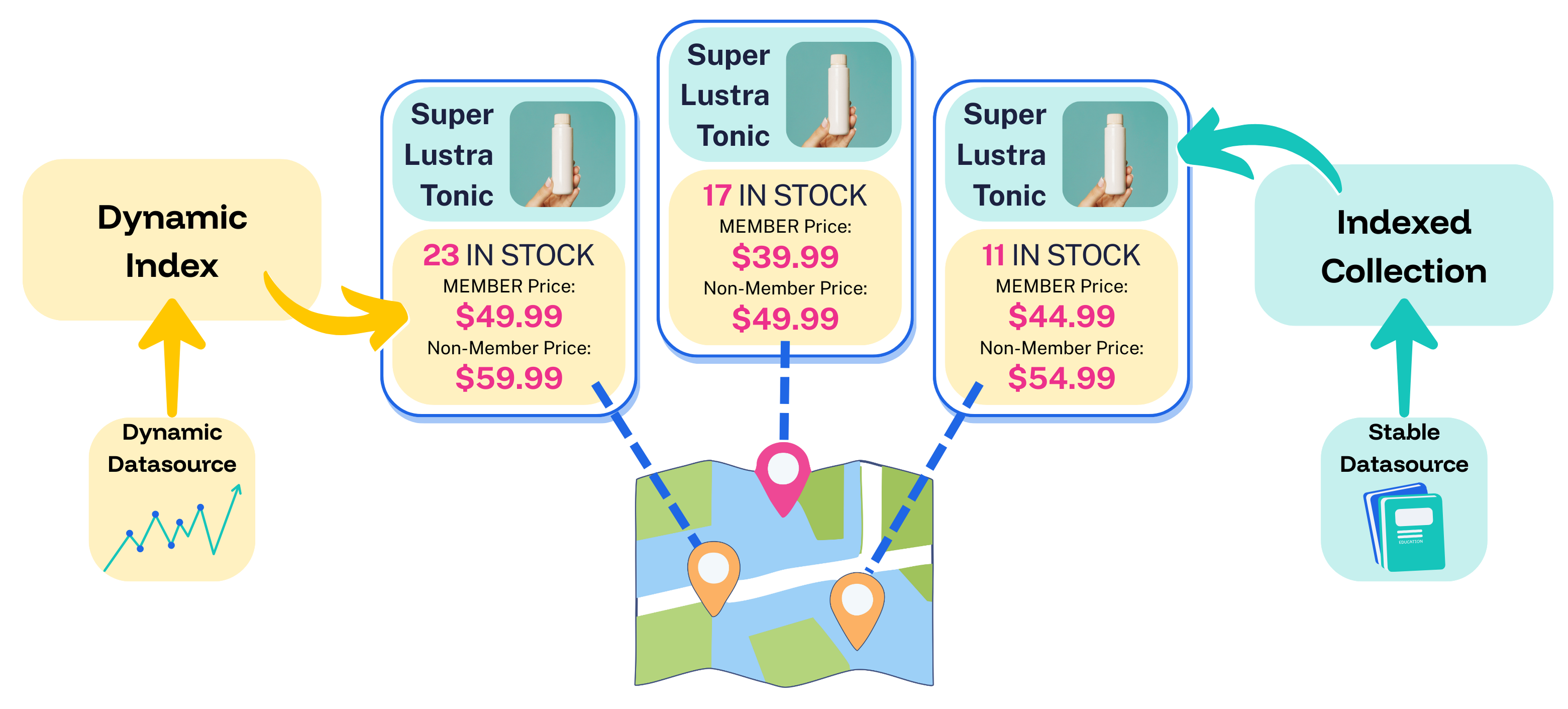
- Data that changes rapidly comes from Dynamic Index, including the number of items in stock and the latest prices for members and non-members at each store location.
- Data that seldom changes comes from an indexed collection, including the product name, photo, description, and so on.
- Both types of data are united to compose an individual product listing that includes up-to-the-moment pricing and inventory data, without impacting response times.
Benefits
For end users
- Users see up-to-the-moment pricing and inventory every time.
- Bespoke experiences that reflect each user’s specific entitlements, location, customer segment, and more.
- Even complex permutations are delivered with no impact on query response times.
For your team
- Bespoke experiences drive higher conversions.
- More control over data visibility.
- Faster performance due to less index bloat.
- Dynamic data is easier and less expensive to scale.
How it works
Dynamic Index supports millions of dynamic permutations of attributes and entitlements, all scaled to suit your evolving data and traffic. With Dynamic Index enabled, the query flow works like this:A user submits a query
- Fusion looks up the user’s profile, contract, store, segment, or other context.
- Dynamic Index identifies the correct prices, inventory, or entitlements for the user’s attributes.
Lucidworks composes the response
- Fusion fetches relevant search results from an indexed collection.
- Dynamic Index attaches the correct prices, inventory, or entitlements to the results.
When to use Dynamic Index
Dynamic Index works well for rapidly updating these types of data:
- Different prices for different accounts, locations, or contract terms
- Different inventory for each store, warehouse, or distribution center
- Different entitlements for users, groups, or segments
- Frequent updates across thousands or millions of SKUs
Dynamic Index is not recommended for these scenarios:
- Multi-list joins at query time
- Multi-currency in a single price list
- Self-hosted environments
- Non-GCS implementations
- Infrequently-updated data
Requirements
- Lucidworks Search
- Google Cloud Storage (GCS)
- A prebuilt JAR, provided by Lucidworks, that includes the required utility that syncs your local external files to cloud storage
Enable Dynamic Index
To enable Dynamic Index, you need to prepare your data, create the directory structure, then upload the data to GCS. The Lucidworks team then initiates synchronization and your Dynamic Index goes live.Enable Dynamic Index in Lucidworks Search
Enable Dynamic Index in Lucidworks Search
Prepare your data
Your data must be formatted as
.txt files using one of these formats:-
With ID and float values (one per line):
-
For sharded collections, use ID, route key, and float:
Create the directory structure
Dynamic Index stores raw ingestion data in a hierarchical, structured directory layout that can include optional subfiles, which then organizes that external data into multi-level partitions and versioned hierarchies. This improvement simplifies the management of complex document structures and removes the previous reliance on manifest files for replication.
- Directory structure
- Example
Each subfile is its own basename directory with its own
versions folder. A subfile can also contain its own subfiles folder.PARENT_BASENAME
versions
VERSION_NUMBER
PARENT_BASENAME.txt
subfiles
CHILD_BASENAME
versions
VERSION_NUMBER
CHILD_BASENAME.txt
subfiles
GRANDCHILD_BASENAME
versions
VERSION_NUMBER
GRANDCHILD_BASENAME.txt
Benefits of Dynamic Index hierarchical support
Click the use case to review the benefits of Dynamic Index hierarchical support for your organization.- B2B
- B2C
- Knowledge management
Hierarchical support enables organizations to structure complex business information such as accounts, subsidiaries, and contracts in versioned, parent-child-grandchild directories, which results in more accurate search and data insights. Updates and versioning at each level reduces reprocessing overhead and simplifies the management of large, interconnected datasets.
Upload to GCS
Copy the entire directory structure to GCS using the following command:You can also use the following command for remote sync (rsync) to upload new or changed files, which is more efficient for updates:
-m enables parallel uploads for faster performance.-r recursively copies the entire directory structure.SOURCE_PATH should contain files organized using the external file structure, where each file may contain its own versions directory and optional nested subfiles.DESTINATION_BUCKET is the GCS target location where you want your files uploaded.For example:Lucidworks enables Dynamic Index
When your data is ready, open a ticket to request Dynamic Index enablement.Your Lucidworks representative will work with you to determine the correct replica multiplier to achieve high availability and performance.
Update your dynamic data
Updates take effect instantly so users see the latest values in real time.Full replacement
Full replacement
Use this method when you’re doing a complete replacement of all of the values for a file.
Create a new directory inside the file’s
versions folder with a higher version number than the previous one, and place the new file in this folder.Upload only the new version folder using the following command:You can also sync the entire directory using the following command:Example workflow:Upload the initial structure using the following command:For subsequent updates, you can use the following command for remote sync (rsync) to upload new or changed files, which is more efficient for updates:
-m enables parallel uploads for faster performance.-r recursively copies the entire directory structure.-d can also be used to delete files from the destination that don’t exist in the source.SOURCE_PATH should contain files organized using the external file structure, where each file may contain its own versions directory and optional nested subfiles.DESTINATION_BUCKET is the GCS target location where you want your files uploaded.Lucidworks Search uses the latest available version based on the highest numeric version in the versions directory.