There are many methods for getting data into Fusion, depending on the type of data:Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
- Your searchable content, signals, and logs are all ingested by indexing them in Solr.
- Connectors, machine learning models, JDBC drivers, analytics catalogs, and Banana dashboards can be uploaded to the blob store.
- The Parallel Bulk Loader (PBL) can perform distributed reads on any data source that implements the SparkSQL (2.2.1 or later) Data Sources API.
- In some cases, you might find that it’s best to use other ingestion methods, such as Import Data with Hive, Import Data with Pig, or pushing data to a Import Data with the REST API endpoint.
Upload a JDBC Driver to Fusion
Upload a JDBC Driver to Fusion
The JDBC V2 connector is supported, and fetches documents from a relational database via SQL queries. Under the hood, this connector implements the Solr DataImportHandler (DIH) plugin.Fusion stores JDBC drivers in the blob store. You can upload a driver using the Fusion UI or the Blob Store API.
How to upload a JDBC driver using the Fusion UI
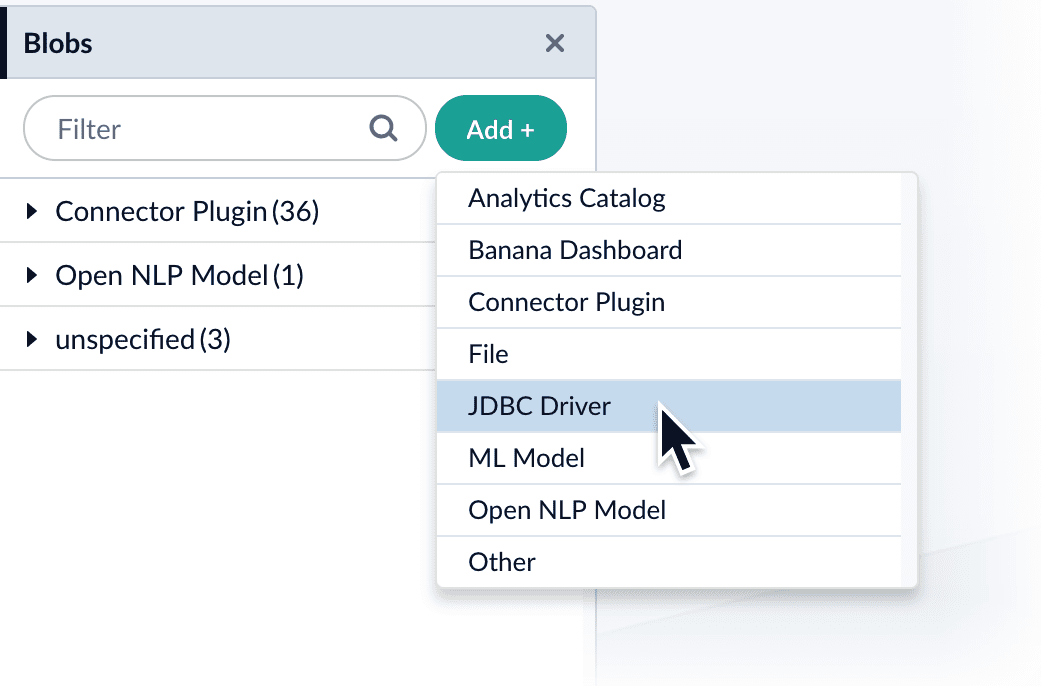
- In the Fusion UI, navigate to System > Blobs.
- Click Add.
-
Select JDBC Driver.
The “New ‘JDBC Driver’ Upload” panel appears.
-
Click Choose File and select the .jar file from your file system.
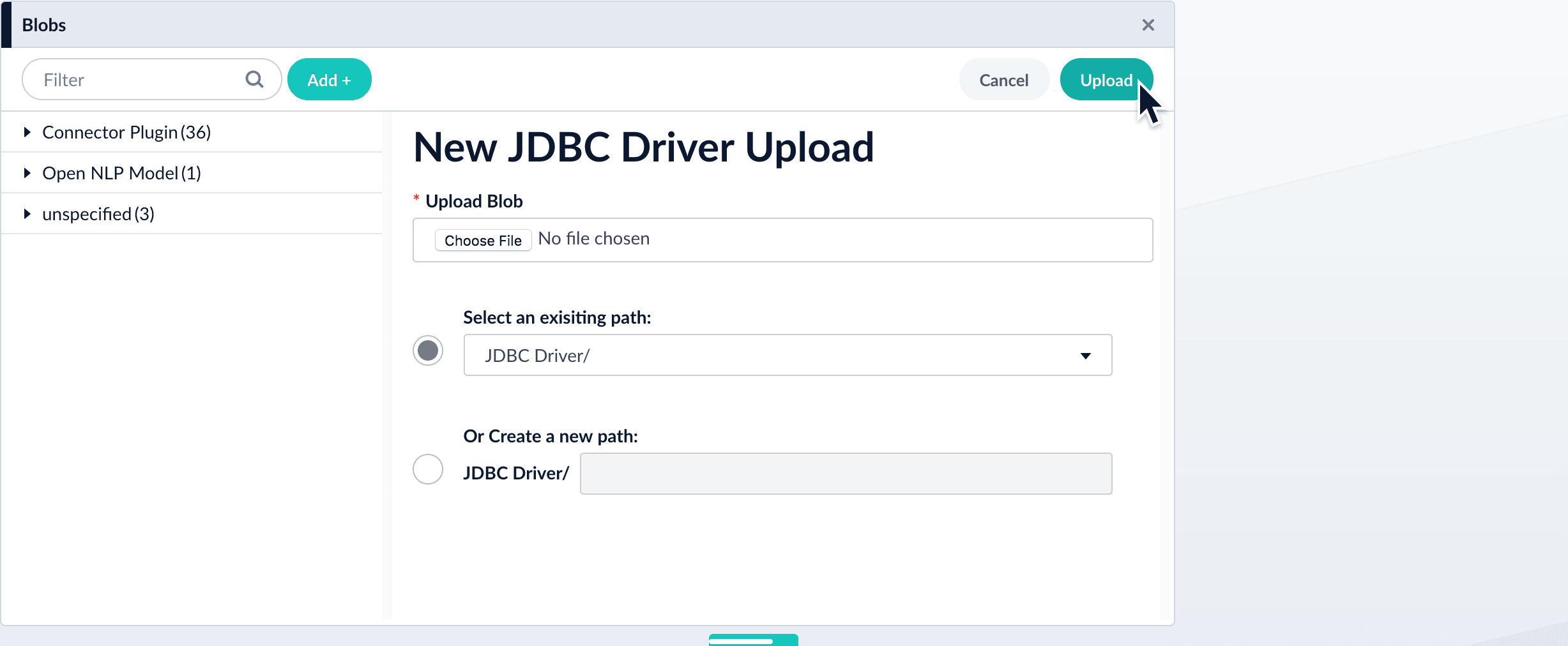
-
Click Upload.
The new driver’s blob manifest appears.
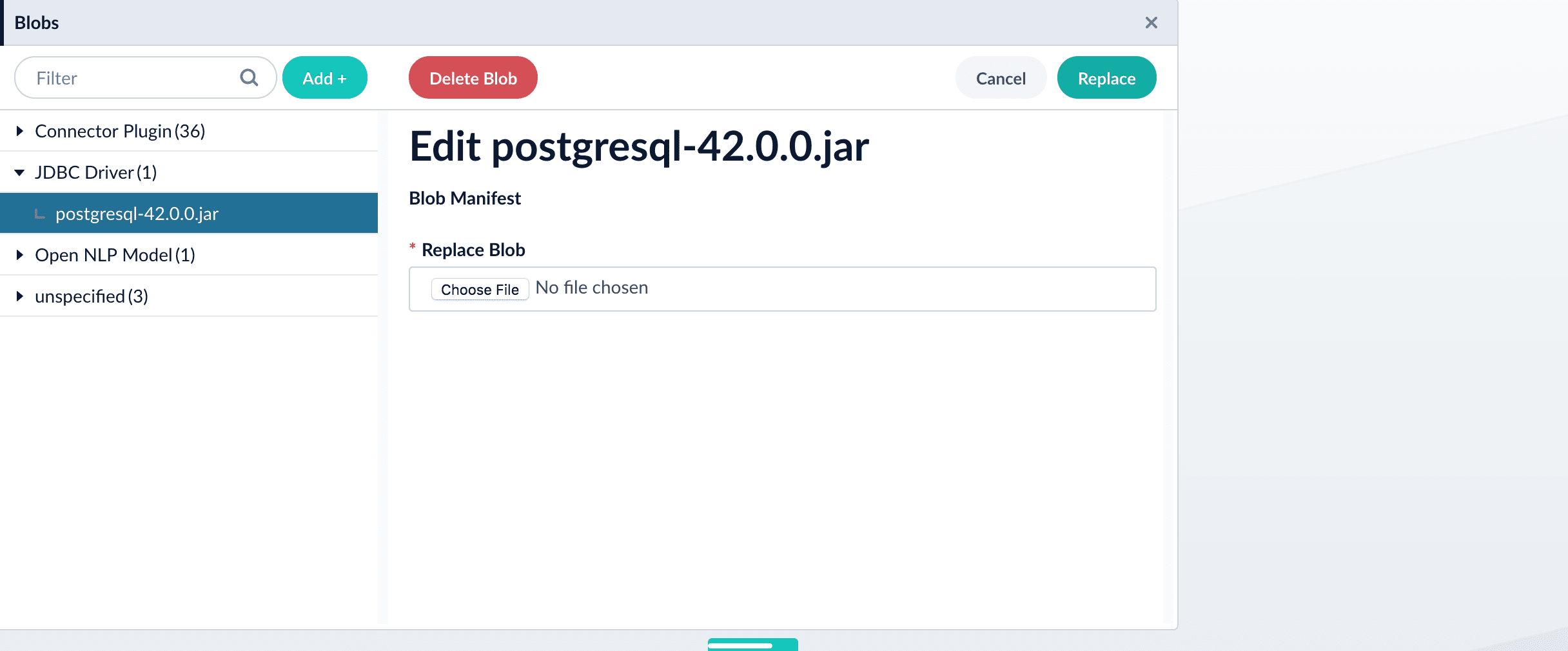
How to install a JDBC driver using the API
-
Upload the JAR file to Fusion’s blob store using the
/blobs/{id}endpoint. Specify an arbitrary blob ID, and aresourceTypevalue ofplugin:connector, as in this example:Success response:Fusion automatically publishes the event to the cluster, and the listeners perform the driver installation process on each node. -
To verify the uploaded driver, run:
Where the
BLOB_IDis the name specified during upload, such as “mydriver” above. A success response looks like this:
Import Data with Hive
Import Data with Hive
Fusion ships with a Serializer/Deserializer (SerDe) for Hive, included in the distribution as If you use Hive with Ambari (as with the Hortonworks HDP distribution), go to menu:Hive[Configs > Advanced], and scroll down to menu:Advanced hive-env[hive-env template]. Find the section where the If you are not using Ambari or a similar cluster management tool, you can add the jar location to Another option is to launch Hive with the path defined with the In this example, we have created an external table named “fusion”, and defined a custom storage handler (Replace the table name as appropriate to use this example with your data.To join data from tables, you can make a request such as:And finally, to insert data to a table, simply use the Solr table as the target for the Hive INSERT statement, such as:
lucidworks-hive-serde-v2.2.6.jar in $FUSION_HOME/apps/connectors/resources/lucid.hadoop/jobs.For Fusion 4.1.x and 4.2.x, the preferred method of importing data with Hive is to use the Parallel Bulk Loader. The import procedure does not apply to Fusion 5.x.
Features
- Index Hive table data to Solr.
- Read Solr index data to a Hive table.
- Kerberos support for securing communication between Hive and Solr.
- As of v2.2.4 of the SerDe, integration with Fusion is supported. *Fusion’s index pipelines can be used to index data to Fusion. *Fusion’s query pipelines can be used to query Fusion’s Solr instance for data to insert into a Hive table.
Add the SerDe Jar to Hive Classpath
In order for the Hive SerDe to work with Solr, the SerDe jar must be added to Hive’s classpath using thehive.aux.jars.path capability. There are several options for this, described below.It’s considered a best practice to use a single directory for all auxiliary jars you may want to add to Hive so you only need to define a single path. However, you must then copy any jars you want to use to that path.The following options all assume you have created such a directory at
/usr/hive/auxlib; if you use another path, update the path in the examples accordingly.HIVE_AUX_JARS_PATH is defined, and add the path to each line which starts with export. What you want will end up looking like:hive/conf/hive-site.xml:auxpath variable:
hive —auxpath /usr/hive/auxlibThere are also other approaches that could be used. Keep in mind, though, that the jar must be loaded into the classpath, adding it with the ADD JAR function is not sufficient.Indexing Data to Fusion
If you use Lucidworks Fusion, you can index data from Hive to Solr via Fusion’s index pipelines. These pipelines allow you several options for further transforming your data.This is an example Hive command to create an external table to index documents in Fusion and to query the table later.STORED BY 'com.lucidworks.hadoop.hive.FusionStorageHandler') that a class included with the Hive SerDe jar designed for use with Fusion.Note that all of the same caveats about field types discussed in the section <<Defining Fields for Solr>> apply to Fusion as well. In Fusion, however, you have the option of using an index pipeline to perform specific field mapping instead of using dynamic fields.The LOCATION indicates the location in HDFS where the table data will be stored. In this example, we have chosen to use /tmp/fusion.In the section TBLPROPERTIES, we define several properties for Fusion so the data can be indexed to the right Fusion installation and collection:fusion.endpoints: The full URL to the index pipeline in Fusion. The URL should include the pipeline name and the collection data will be indexed to.fusion.fail.on.error: Iftrue, when an error is encountered, such as if a row could not be parsed, indexing will stop. This isfalseby default.fusion.buffer.timeoutms: The amount of time, in milliseconds, to buffer documents before sending them to Fusion. The default is 1000. Documents will be sent to Fusion when either this value orfusion.batchSizeis met.fusion.batchSize: The number of documents to batch before sending the batch to Fusion. The default is 500. Documents will be sent to Fusion when either this value orfusion.buffer.timeoutmsis met.fusion.realm: This is used withfusion.userandfusion.passwordto authenticate to Fusion for indexing data. Two options are supported,KERBEROSorNATIVE. Kerberos authentication is supported with the additional definition of a JAAS file. The propertiesjava.security.auth.login.configandfusion.jaas.appnameare used to define the location of the JAAS file and the section of the file to use. Native authentication uses a Fusion-defined username and password. This user must exist in Fusion, and have the proper permissions to index documents.fusion.user: The Fusion username or Kerberos principal to use for authentication to Fusion. If a Fusion username is used ('fusion.realm' = 'NATIVE'), thefusion.passwordmust also be supplied.fusion.password: This property is not shown in the example above. The password for thefusion.userwhen thefusion.realmisNATIVE.java.security.auth.login.config: This property defines the path to a JAAS file that contains a service principal and keytab location for a user who is authorized to read from and write to Fusion and Hive. The JAAS configuration file must be copied to the same path on every node where a Node Manager is running (i.e., every node where map/reduce tasks are executed). Here is a sample section of a JAAS file:<1>The name of this section of the JAAS file. This name will be used with thefusion.jaas.appnameparameter.<2>The location of the keytab file.<3>The service principal name. This should be a different principal than the one used for Fusion, but must have access to both Fusion and Hive. This name is used with thefusion.userparameter described above.
fusion.jaas.appname: Used only when indexing to or reading from Fusion when it is secured with Kerberos. This property provides the name of the section in the JAAS file that includes the correct service principal and keytab path.fusion.query.endpoints: The full URL to a query pipeline in Fusion. The URL should include the pipeline name and the collection data will be read from. You should also specify the request handler to be used. If you do not intend to query your Fusion data from Hive, you can skip this parameter.fusion.query: The query to run in Fusion to select records to be read into Hive. This is\*:*by default, which selects all records in the index. If you do not intend to query your Fusion data from Hive, you can skip this parameter.
Query and Insert Data to Hive
Once the table is configured, any syntactically correct Hive query will be able to query the index.For example, to select three fields named “id”, “field1_s”, and “field2_i” from the “solr” table, you would use a query such as:Example Indexing Hive to Solr
Solr includes a small number of sample documents for use when getting started. One of these is a CSV file containing book metadata. This file is found in your Solr installation, at$SOLR_HOME/example/exampledocs/books.csv.Using the sample books.csv file, we can see a detailed example of creating a table, loading data to it, and indexing that data to Solr.<1>Define the tablebooks, and provide the field names and field types that will make up the table.<2>Load the data from thebooks.csvfile.<3>Create an external table namedsolr, and provide the field names and field types that will make up the table. These will be the same field names as in your local Hive table, so we can index all of the same data to Solr.<4>Define the custom storage handler provided by thelucidworks-hive-serde-v2.2.6.jar.<5>Define storage location in HDFS.<6>The query to run in Solr to read records from Solr for use in Hive.<7>Define the location of Solr (or ZooKeeper if using SolrCloud), the collection in Solr to index the data to, and the query to use when reading the table. This example also refers to a JAAS configuration file that will be used to authenticate to the Kerberized Solr cluster.
Import Data with Pig
Import Data with Pig
You can use Pig to import data into Fusion, using the This relatively simple script is doing several things that help to understand how the Solr Pig functions work.The parameters to pass are:
lucidworks-pig-functions-v2.2.6.jar file found in $FUSION_HOME/apps/connectors/resources/lucid.hadoop/jobs.Available Functions
The Pig functions included in the{packageUser}-pig-functions-{connectorVersion}.jar are three UserDefined Functions (UDF) and two Store functions. These functions are:com/lucidworks/hadoop/pig/SolrStoreFunc.classcom/lucidworks/hadoop/pig/FusionIndexPipelinesStoreFunc.classcom/lucidworks/hadoop/pig/EpochToCalendar.classcom/lucidworks/hadoop/pig/Extract.classcom/lucidworks/hadoop/pig/Histogram.class
Using the Functions
Register the Functions
There are two approaches to using functions in Pig:REGISTER them in the script, or load them with your Pig command line request.If using REGISTER, the Pig function jars must be put in HDFS in order to be used by your Pig script. It can be located anywhere in HDFS; you can either supply the path in your script or use a variable and define the variable with -p property definition.The example below uses the second approach, loading the jars with the -Dpig.additional.jars system property when launching the script. With this approach, the jars can be located anywhere on the machine where the script will be run.Indexing Data to Fusion
When indexing data to Fusion, there are several parameters to pass with your script in order to output data to Fusion for indexing.These parameters can be made into variables in the script, with the proper values passed on the command line when the script is initiated. The example script below shows how to do this for Solr. The theory is the same for Fusion, only the parameter names would change as appropriate:fusion.endpoints: The full URL to the index pipeline in Fusion. The URL should include the pipeline name and the collection data will be indexed to.fusion.fail.on.error: Iftrue, when an error is encountered, such as if a row could not be parsed, indexing will stop. This isfalseby default.fusion.buffer.timeoutms: The amount of time, in milliseconds, to buffer documents before sending them to Fusion. The default is 1000. Documents will be sent to Fusion when either this value orfusion.batchSizeis met.fusion.batchSize: The number of documents to batch before sending the batch to Fusion. The default is 500. Documents will be sent to Fusion when either this value orfusion.buffer.timeoutmsis met.fusion.realm: This is used withfusion.userandfusion.passwordto authenticate to Fusion for indexing data. Two options are supported,KERBEROSorNATIVE. Kerberos authentication is supported with the additional definition of a JAAS file. The propertiesjava.security.auth.login.configandfusion.jaas.appnameare used to define the location of the JAAS file and the section of the file to use. These are described in more detail below. Native authentication uses a Fusion-defined username and password. This user must exist in Fusion, and have the proper permissions to index documents.fusion.user: The Fusion username or Kerberos principal to use for authentication to Fusion. If a Fusion username is used ('fusion.realm' = 'NATIVE'), thefusion.passwordmust also be supplied.fusion.pass: This property is not shown in the example above. The password for thefusion.userwhen thefusion.realmisNATIVE.
Indexing to a Kerberized Fusion Installation
When Fusion is secured with Kerberos, Pig scripts must include the full path to a JAAS file that includes the service principal and the path to a keytab file that will be used to index the output of the script to Fusion.Additionally, a Kerberos ticket must be obtained on the server for the principal usingkinit.java.security.auth.login.config: This property defines the path to a JAAS file that contains a service principal and keytab location for a user who is authorized to write to Fusion. The JAAS configuration file must be copied to the same path on every node where a Node Manager is running (i.e., every node where map/reduce tasks are executed). Here is a sample section of a JAAS file:<1>The name of this section of the JAAS file. This name will be used with thefusion.jaas.appnameparameter.<2>The location of the keytab file.<3>The service principal name. This should be a different principal than the one used for Fusion, but must have access to both Fusion and Pig. This name is used with thefusion.userparameter described above.
fusion.jaas.appname: Used only when indexing to or reading from Fusion when it is secured with Kerberos. This property provides the name of the section in the JAAS file that includes the correct service principal and keytab path.
Sample CSV Script
The following Pig script will take a simple CSV file and index it to Solr.<1>This and the line above define parameters that are needed bySolrStoreFuncto know where Solr is.SolrStoreFuncneeds the propertiessolr.zkhostandsolr.collection, and these lines are mapping thezkhostandcollectionparameters we will pass when invoking Pig to the required properties.<2>Load the CSV file, the path and name we will pass with thecsvparameter. We also define the field names for each column in CSV file, and their types.<3>For each item in the CSV file, generate a document id from the first field ($0) and then define each field name and value inname, valuepairs.<4>Load the documents into Solr, using theSolrStoreFunc. While we don’t need to define the location of Solr here, the function will use thezkhostandcollectionproperties that we will pass when we invoke our Pig script.
-p option, such as in this command:csv: The path and name of the CSV file we want to process.zkhost: The ZooKeeper connection string for a SolrCloud cluster, in the form ofzkhost1:port,zkhost2:port,zkhost3:port/chroot. In the script, we mapped this to thesolr.zkhostproperty, which is required by theSolrStoreFuncto know where to send the output documents.collection: The Solr collection to index into. In the script, we mapped this to thesolr.collectionproperty, which is required by theSolrStoreFuncto know the Solr collection the documents should be indexed to.
Import Data with the REST API
Import Data with the REST API
It is often possible to get documents into Fusion by configuring a datasource with the appropriate connector.But if there are obstacles to using connectors, it can be simpler to index documents with a REST API call to an index profile or pipeline.These requests are sent as a POST request. The request header specifies the format of the contents of the request body. Create an index profile in the Fusion UI.To send a streaming list of JSON documents, you can send the JSON file that holds these objects to the API listed above with To prevent the terminal from displaying all the data and metadata it indexes—useful if you are indexing a large file—you can optionally append In Fusion 5, documents can be created on the fly using the PipelineDocument JSON notation.You can use
Push documents to Fusion using index profiles
Index profiles allow you to send documents to a consistent endpoint (the profile alias) and change the backend index pipeline as needed. The profile is also a simple way to use one pipeline for multiple collections without any one collection “owning” the pipeline.You can send documents directly to an index using the Index Profiles REST API. The request path is:application/json as the content type. If your JSON file is a list or array of many items, the endpoint operates in a streaming way and indexes the docs as necessary.Send data to an index profile that is part of an app
Accessing an index profile through an app lets a Fusion admin secure and manage all objects on a per-app basis. Security is then determined by whether a user can access an app. This is the recommended way to manage permissions in Fusion.The syntax for sending documents to an index profile that is part of an app is as follows:Spaces in an app name become underscores. Spaces in an index profile name become hyphens.
?echo=false to the URL.Be sure to set the content type header properly for the content being sent. Some frequently used content types are:- Text:
application/json,application/xml - PDF documents:
application/pdf - MS Office:
- DOCX:
application/vnd.openxmlformats-officedocument.wordprocessingml.document - XLSX:
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet - PPTX:
application/vnd.vnd.openxmlformats-officedocument.presentationml.presentation - More types: http://filext.com/faq/office_mime_types.php
- DOCX:
Example: Send JSON data to an index profile under an app
In$FUSION_HOME/apps/solr-dist/example/exampledocs you can find a few sample documents. This example uses one of these, books.json.To push JSON data to an index profile under an app:- Create an index profile. In the Fusion UI, click Indexing > Index Profiles and follow the prompts.
- From the directory containing
books.json, enter the following, substituting your values for username, password, and index profile name: - Test that your data has made it into Fusion:
- Log into the Fusion UI.
- Navigate to the app where you sent your data.
- Navigate to the Query Workbench.
- Search for
*:*. - Select relevant Display Fields, for example
authorandname.
Example: Send JSON data without defining an app
In most cases it is best to delegate permissions on a per-app basis. But if your use case requires it, you can push data to Fusion without defining an app.To send JSON data without app security, issue the following curl command:Example: Send XML data to an index profile with an app
To send XML data to an app, use the following:Remove documents
Example 1
The following example removes content:Example 2
A more specific example removes data frombooks.json. To delete “The Lightning Thief” and “The Sea of Monsters” from the index, use their id values in the JSON file.The del-json-data.json file to delete the two books:?echo=false to turn off the response to the terminal.Example 3
Another example to delete items using the Push API is:Send documents to an index pipeline
Although sending documents to an index profile is recommended, if your use case requires it, you can send documents directly to an index pipeline.For more information about index pipeline REST API reference documentation, see Fusion 5.x Index Pipelines API.Specify a parser
When you push data to a pipeline, you can specify the name of the parser by adding a parserId querystring parameter to the URL. For example:https://FUSION_HOST:FUSION_PORT/api/index-pipelines/INDEX_PIPELINE/collections/COLLECTION_NAME/index?parserId=PARSER.If you do not specify a parser, and you are indexing outside of an app (https://FUSION_HOST:FUSION_PORT/api/index-pipelines/...), then the _system parser is used.If you do not specify a parser, and you are indexing in an app context (https://FUSION_HOST:FUSION_PORT/api/apps/APP_NAME/index-pipelines/...), then the parser with the same name as the app is used.Indexing CSV Files
In the usual case, to index a CSV or TSV file, the file is split into records, one per row, and each row is indexed as a separate document.Ingesting Data
The course for Ingesting Data focuses on understanding connectors and how to configure datasources, parsers, and index pipelines.