There are many ways to monitor Java Virtual Machines, Unix file systems, networks, and applications like Solr and Fusion. This includes the use of a UI, command-line utilities, or REST APIs and JMX Managed Beans (MBeans). A full-fledged monitoring tool such as Datadog, Nagios, Zabbix, New Relic, SolarWinds, or other comparable tool might be helpful. These tools assist in the analysis of the raw JMX values, which tend to be more informative than the numbers alone. This topic focuses on generally available options, including: command-line utilities such asDocumentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
top, du -h, and df; REST APIs; and JMX MBean metrics.
Lucidworks does not explicitly recommend any particular monitoring product, nor do we imply suitability or compatibility with Lucidworks Fusion. The aforementioned products are not detailed or reviewed in this topic.
Monitoring via Solr
The Solr Admin console lists information for one Solr node. This can be obtained via HTTP as needed.GET JVM metrics for a Solr node
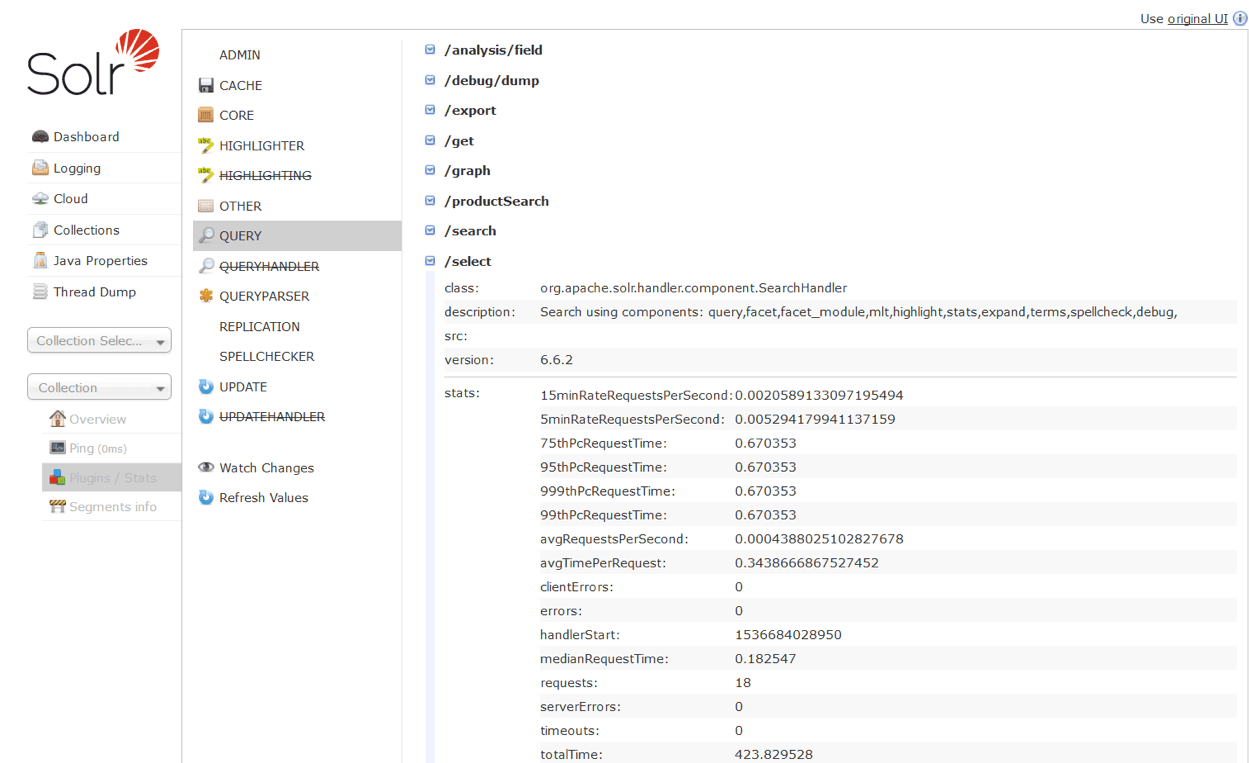
ENABLE_REMOTE_JMX_OPTS=true. Refer to Apache’s Solr reference guide for configuring JMX for more information.
Finding shard leaders in Solr
In Solr admin console
The Solr admin console’s Cloud > Graph view can show the Shards and replicas for all Solr collections in a cluster. The nodes on the right-hand side with the filled in dot are the current shard leaders. Query operations are distributed across both leaders and followers but index operations require extra resources from leaders.
With the API
The Solr API allows you to fetch the cluster status, including collections, shards, replicas, configuration name, collection aliases, and cluster properties. Requests are made with the following URL endpoint:/admin/{parameter}?action=CLUSTERSTATUS.
| Parameter | Description |
|---|---|
| collection | The collection or alias name for which information is requested. If omitted, information on all collections in the cluster will be returned. If an alias is supplied, information on the collections in the alias will be returned. |
| shard | The shard(s) for which information is requested. Multiple shard names can be specified as a comma-separated list. |
route | This can be used if you need the details of the shard where a particular document belongs to and you don’t know which shard it falls under. |
http://localhost:8983/solr/admin/collections?action=CLUSTERSTATUS
Output
Monitoring Fusion
The Fusion UI in Fusion 4.2 through 5.5 includes monitoring, troubleshooting, and incident investigation tools in the DevOps Center. The DevOps Center provides a set of dashboards and an interactive log viewer, providing views into this Fusion cluster’s hosts and services using metrics and events. You can monitor general system state and status via HTTP in several ways:Check the System State
Check the System State
Fusion runs several components as separate JVMs running on different ports. Each of the components is capable of reporting its status. The proxy component reports status for all of the other components.The response should look similar to the following. If ‘ping’ is true for each service, all of the system components are running.The response will be a JSON response, similar to the following:The As an alternative check, you can also query the The response looks like something like this:As an alternative check, you can also query the The response looks like something like this:
Status Check for Zookeeper and connectors-classic
To see whether each component has been started, a simple API call to the proxy (running on port 8764 by default) will return the status of each component of the system.Solr Health Check
The Fusion UI and API services are not accessible if ZooKeeper and Solr are not in healthy state. A Solr health check can be performed with a ping request, for example:status should be OK if Solr is able to return results for queries.REST API Services Health Check
All of the Fusion API backend services (except Connectors and the UI) are started at port 8765 when the run.sh script is executed. The Fusion UI depends on all these services.If all the services are started without any issues, then the below ping request should return the responseok.system/status endpoint, which returns the status.Connectors Classic Health Check
You can perform a health check of the Connectors Classic Service by sending a ping request to port 8984. Similar to the previous ping request, the returned response isok if the service started successfully.system/status endpoint, which returns the status.- Fusion 5.x.x DevOps Center
Fusion 5.x.x includes Grafana, which provides enhanced metrics collection and querying. Kubernetes containers may make some access methods more difficult. For example, JMX beans on a container. - Fusion 4.2.x DevOps Center
Fusion 4.x.x publishes a wide variety of metrics, including stage-by-stage performance for pipelines via the Fusion Metrics API. The Fusion metrics provide valuable insight into stage development, hot-spot identification, and overall throughput numbers. See Use System Metrics for more information.
Use System Metrics
Use System Metrics
Enable metrics indexing in the Fusion UI
- Navigate to System > System > Metrics.
- Enable Record System Metrics Over Time.
Enable metrics indexing using the REST API
/system/metrics endpoint of the System API lists all the metrics that the system is currently collecting. Metrics are returned for the current instance only; Fusion instances do not aggregate metrics between nodes.Adjust the system metrics retention period
- Navigate to Collections > Jobs.
-
Select the
delete-old-system-metricsjob. -
In the job configuration pane, scroll down to REQUEST ENTITY (AS STRING).
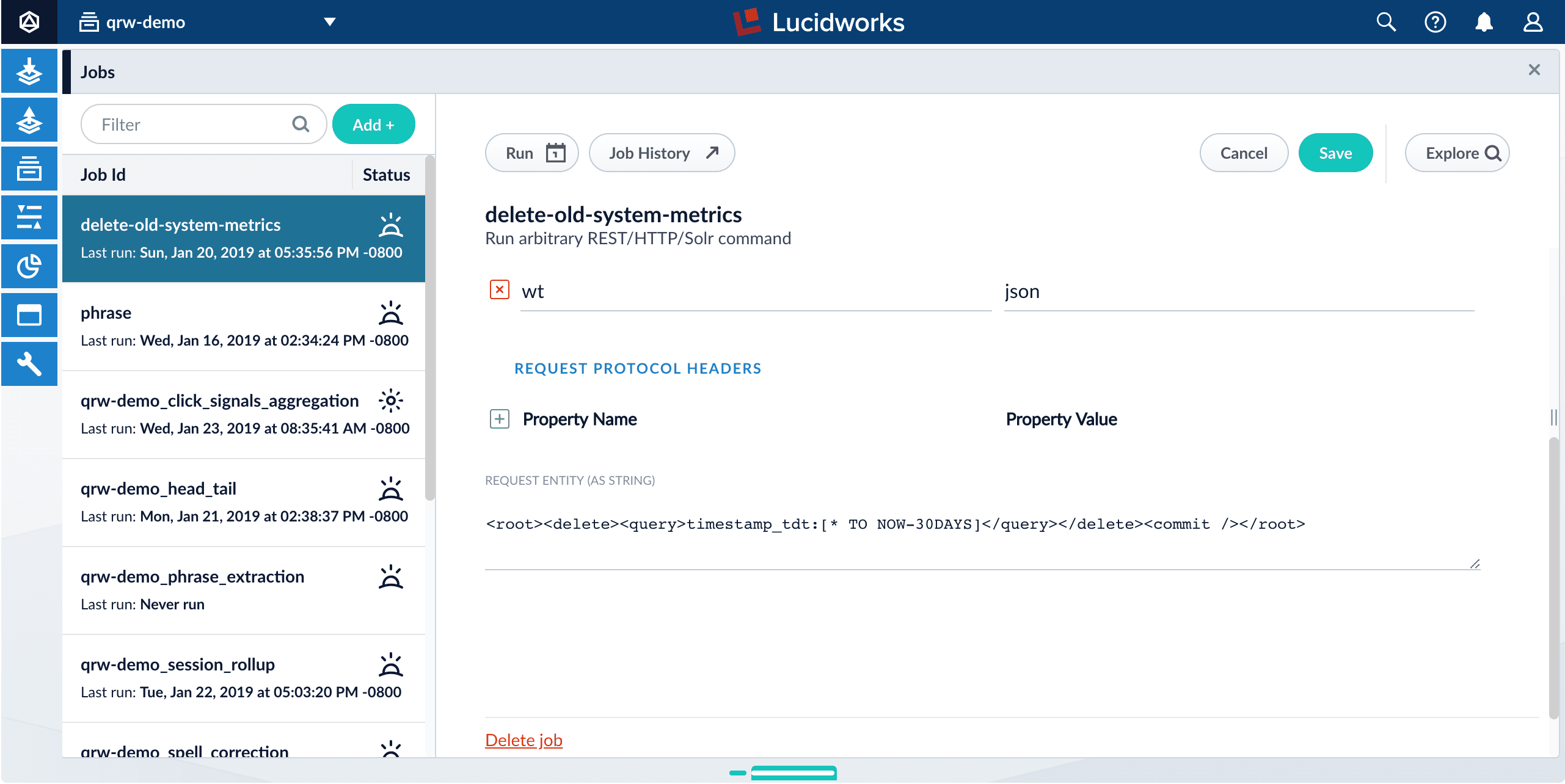
-
Change
30DAYSto the desired period of time to retain system metrics.
Change Metric Collection Frequency
The default frequency to collect metrics is 60 seconds. Since the metrics are stored in a system collection (and a Solr instance), the data can grow to be quite large over time. If you do not need metrics collection to happen as frequently (perhaps during initial implementation), you can change the frequency by modifying thecom.lucidworks.apollo.metrics.poll.seconds configuration parameter with the Configurations API.For example:com.lucidworks.apollo.metrics.poll.seconds parameter to ‘-1’.Check which Fusion services are running
Check the cluster-wide status for a service
Monitor the logs collection
In addition to the on-disk log files, most of the key Fusion logging events are written to the Logs collection. You can monitor these logging events with the Logging Dashboard.The log creation process can be altered in the
fusion.cors (fusion.properties in Fusion 4.x) file located in /fusion/latest.x/conf/. If log files are not being created and stored in the logs collection, check the configurations in this file.
See what scheduled jobs are running
The Fusion UI’s Datasources and Jobs pages show the most recent status for data ingestion jobs and other jobs that can be scheduled.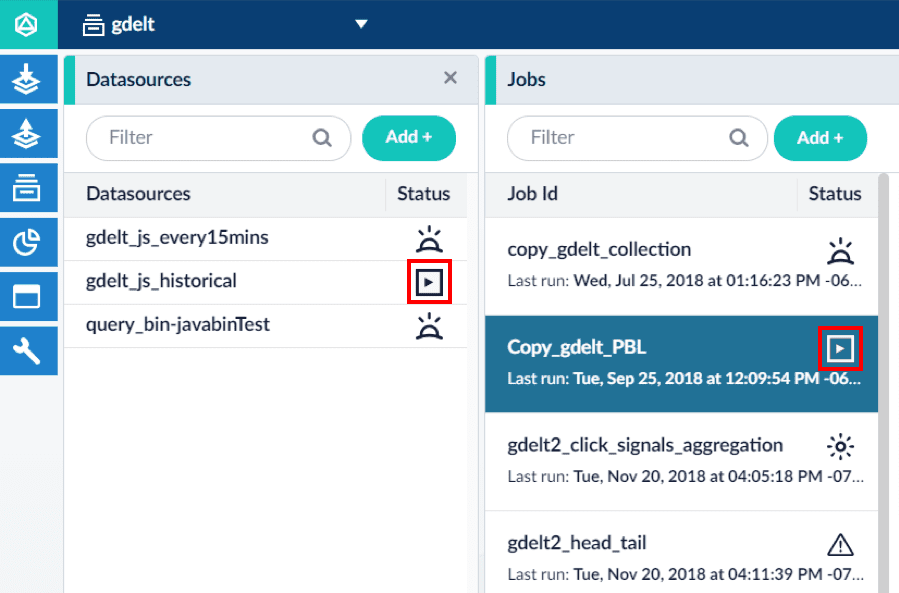
What to monitor
Several levels of information should be monitored, including hardware resources, performance benchmarks, the Java virtual machine, Lucene/Solr, and others. The point at which a monitored metric should trigger a warning or alarm condition is highly dependent on user-specific factors, such as the target audience, time tolerance thresholds, and real-time needs.Hardware and resources
This is just knowing what is going on with the overall system resources.| CPU Idle | This value helps determine whether a system is running out of CPU resources. Establishing average values, such as avg(1 min), helps determine if the CPU Idle value is too high. Establishing these averages for each individual CPU core helps you avoid confusion if, for example, everything is paused on a single CPU core. |
| Load Average | This value indicates whether processes are being loaded into a queue to be processed. If this value is higher than the number of CPU cores on a system, the machine is failing to load processes. The Load Average value might not indicate a specific problem, but might rather indicate that a problem exists somewhere. |
| Swap | Most operating systems can extend the capabilities of their RAM by paging portions out to disk before moving it back into RAM as needed. This process is called “swap”. |
| Page In/Out | This value indicates the use of swap space. There might be a small amount of swap space used and little page in/out activity. However, the use of swap space generally indicates the need for more memory. |
| Free Memory | This value indicates the amount of free memory available to the system. A system with low amounts of free memory can no longer increase disk caching as queries are run. Because of this, index accesses must wait for permanent disk storage, which is much slower. Take note of the amount of free memory and the disk cache in comparison to the overall index size. Ideally, the disk cache should be able to hold all of the index, although this is not as important when using newer SSD technologies. |
| I/O Wait | A high I/O Wait value indicates system processes are waiting on disk access, resulting in a slow system. |
| Free Disk Space | It is critical to monitor the amount of free disk space, because running out of free disk space can cause corruption in indexes. Avoid this by creating a mitigation plan to reallocate indexes, purge less important data, or add disk space. Create warning and alarm alerting for disk partitions containing application or log data. |
Performance benchmarks
These benchmarks are available via JMX MBeans when using JConsole. They are found under the namespacesolr/<corename>. Some of these metrics can also be obtained via the fields below.
| Average Response Times | Monitoring tools can complete very useful calculations by measuring deltas between incremental values. For example, a user might want to calculate the average response time over the last five minutes. Use the Runtime JMX MBean as the divisor to get performance over time periods. The JMX MBean for the standard request handler is found at: solr/<corename>:type=standard,id=org.apache.solr.handler.StandardRequestHandler, totalTime, requests] This can be obtained for every Solr requestHandler being used. |
| nth Percentile Response Times | This value allows a user to see the response time for 75thPercentile, 95thPercentile, 99thPercentile, and 999thPercentiles. This value is a poor performance benchmark during short spikes in query times, but in other applications, it can show slow degradation problems and baseline behavior. JMX MBean example: "solr/collection1:type=standard,id=org.apache.solr.handler.component.SearchHandler", 75thPcRequestTime The same format is used for all percentiles. |
| Average QPS | Tracking peak QPS over several-minute intervals can show how well Fusion and Solr are handling queries and can be vital in benchmarking plausible load. JMX MBean is found at: "solr/collection1:type=standard,id=org.apache.solr.handler.StandardRequestHandler", requests divided by JMX Runtime java.lang:Runtime. |
| Average Cache/Hit Ratios | This value can indicate potential problems in how Solr is warming searcher caches. A ratio below 1:2 should be considered problematic, as this may affect resource management when warming caches. Again, this value can be used with the Runtime JMX MBean to find changes over a time period. JMX MBeans are found at: "solr/<corename>:type=<cachetype>id=org.apache.solr.search.<cache impl>", hitratio/cumulative hitratio |
| External Query “HTTP Ping” | An external query HTTP ping lets you monitor the performance of the system by sending a request for a basic status response from the system. Because this request does not perform a query of data, the response is fast and consistent. The average response time can be used as a metric for measuring system load. Under light to moderate loads, the response to the HTTP ping request is returned quickly. Under heavy loads, the response lags. If the response lags considerably, this might be a sign that the service is close to breaking. External query HTTP pings can be configured to target query pipelines, which in turn query Solr. Using this method, you can monitor the uptime of the system by verifying Solr, API nodes, and the proxy service are taking requests. Every important collection should be monitored, as the performance of one collection may differ from another. There are many vendors which provide these services. This includes Datadog, New Relic, StatusCake, and Pingdom. |
Java Virtual Machine
The Java Virtual Machine is found via JMX MBeans. Many are also available via REST API calls. See System API for details.JMX runtime
The JMX runtime value is an important piece of data that helps determine time frames and gather statistics, such as performance over the last five minutes. A user can use the delta of the runtime value over the last time period as a divisor in other statistics. This metric can be used to determine how long a server has been running. This JMX MBean is found at: ““java.lang:Runtime”,Uptime`.| Last Full Garbage Collection | Monitoring the total time taken for full garbage collection cycles is important, because full GC activities typically pause processing for a whole application. Acceptable pause times vary, as they relate to how responsive your queries must be in a worst-case scenario. Generally, anything over a few seconds might indicate a problem. JMX MBean: "java.lang:type=GarbageCollector,name=<GC Name>", LastGcInfo.duration Most fusion log directories also have detailed GC logs. |
| Full GC as % of Runtime | This value indicates the amount of time spent in full garbage collections. Large amounts of time spent in full GC cycles can indicate the amount of space given to the heap is too little. |
| Total GC Time as % of Runtime | An indexing server typically spends considerably more time in GC. This is due to all of the new data coming in. When tuning heap and generation sizes, it is important to know how much time is being spent in GC. If too little time is spent, GC triggers more frequently. If too much time is spent, pause frequency increases. |
| Total Threads | This is an important value to track because each thread takes up memory space, and too many threads can overload a system. In some cases, out of memory (OOM) errors are not indicative of the need for more memory, but rather that a system is overloaded with threads. If a system has too many threads opening, it might indicate a performance bottleneck or a lack of hardware resources. JMX MBean: "java.lang:type=Threading,ThreadCount. |
Lucene/Solr
This can be found via JMX as well.| Autowarming Times | This value indicates how long new searchers or caches take to initialize and load. The value applies to both searchers and caches. However, the warmupTime for the searcher is separate from that of caches. There is always a tradeoff between autowarming times and having prewarmed caches ready for search. If autowarming times are set to be longer than the interval for initializing new searchers, problems may arise. Searcher JMX MBean: "solr/collection1:type=searcher,id=org.apache.solr.search.SolrIndexSearcher", warmupTime. "solr/collection1:type=documentCache,id=org.apache.solr.search.LRUCache" "solr/collection1:type=fieldValueCache,id=org.apache.solr.search.FastLRUCache" "solr/collection1:type=filterCache,id=org.apache.solr.search.FastLRUCache" "solr/collection1:type=queryResultCache,id=org.apache.solr.search.LRUCache" |
Learn more
View and Analyze Logs in Fusion 4.2
View and Analyze Logs in Fusion 4.2
Fusion has several features that make analysis of log files easier:
-
View log file dashboards.
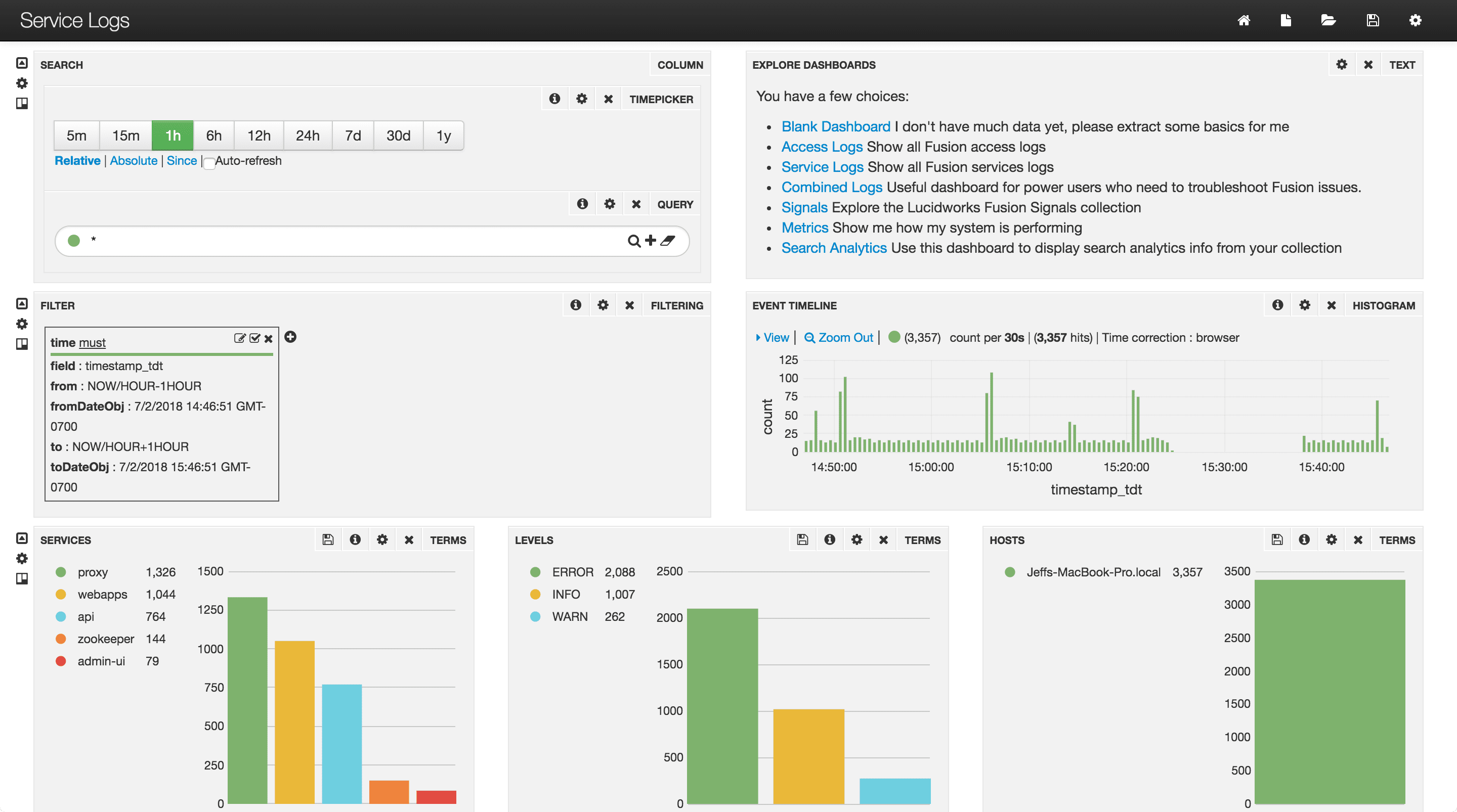
To open the default dashboard from the Fusion workspace, click Analytics > **Dashboards** or System  > Log Viewer.
> Log Viewer.
- Assign Fusion request IDs. To make it easier to follow requests through the Fusion system, you can assign Fusion request IDs. If you do not, Fusion assigns request IDs automatically.
-
Filter log file dashboards by the Fusion request ID. In the log file dashboards, you can filter by Fusion request ID.
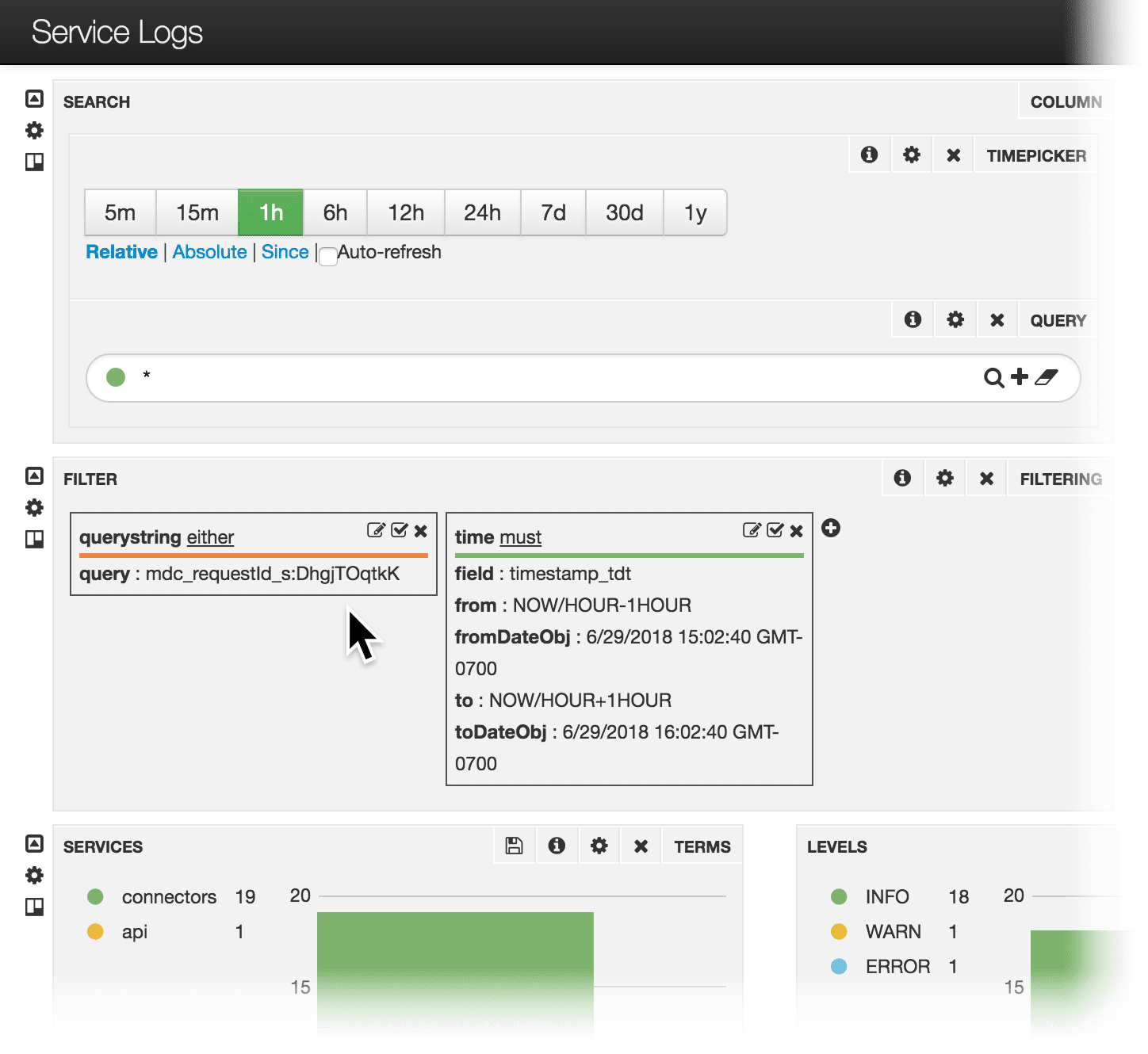
- Click through from API errors in the Fusion UI to the Service Logs dashboard filtered by the Fusion request ID of the request that resulted in the error.