Connectors SDK
Fusion comes with a wide variety of connectors, but you can also develop custom Fusion connectors using the Connectors SDK.
To get started, clone the public repository at
The metadata defined by where To run the client with remote debugging enabled:where To run the client with remote debugging enabled:where To run the client with remote debugging enabled:
After the checkpoint is emitted, Fusion will handle this message as follows:
https://github.com/lucidworks/connectors-sdk-resources/.
- See Java Connector Development to learn about developing a Java-based connector.
- See Develop a Custom Connector for step-by-step instructions.
Develop a Custom Connector
Develop a Custom Connector
Java SDK configuration
To build a valid connector configuration, you must:- Define an interface.
- Extend
ConnectorConfig. - Apply a few annotations.
- Define connector methods and annotations.
@Property are considered to be configuration properties.
For example, @Property() String name(); results in a String property called name.
This property would then be present in the generated schema.Here is an example of the most basic configuration, along with required annotations:@RootSchema is used by Fusion when showing the list of available connectors.
The ConnectorConfig base interface represents common, top-level settings required by all connectors.
The type parameter of the ConnectorConfig class indicates the interface to use for custom properties.Once a connector configuration has been defined, it can be associated with the ConnectorPlugin class.
From that point, the framework takes care of providing the configuration instances to your connector.
It also generates the schema, and sends it along to Fusion when it connects to Fusion.Schema metadata can be applied to properties using additional annotations. For example, applying limits to the min/max length of a string, or describing the types of items in an array.Nested schema metadata can also be applied to a single field by using “stacked” schema based annotations:Plugin client
The Fusion connector plugin client provides a wrapper for the Fusion Java plugin-sdk so that plugins do not need to directly talk with gRPC code. Instead, they can use high-level interfaces and base classes, like Connector and Fetcher.The plugin client also provides a standalone “runner” that can host a plugin that was built from the Fusion Java Connector SDK. It does this by loading the plugin zip file, then calling on the wrapper to provide the framework interactions.Standalone Connector Plugin Application
The second goal of the plugin-client is to allow Java SDK plugins to run remotely. The instructions for deploying a connector using this method are provided below.Locating the UberJar
The uberjar is located in this location in the Fusion file system:$FUSION_HOME is your Fusion installation directory and <version> is your Fusion version number.Starting the Host
To start the host app, you need a Fusion SDK-based connector, built into the standard packaging format as a.zip file. This zip must contain only one connector plugin.Here is an example of how to start up using the web connector:Java SDK security
Fusion Connector Plugin Client
The Fusion connector plugin client provides a wrapper for the Fusion Java plugin-sdk so that plugins do not need to directly talk with gRPC code. Instead, they can use high-level interfaces and base classes, like Connector and Fetcher.The plugin client also provides a standalone “runner” that can host a plugin that was built from the Fusion Java Connector SDK. It does this by loading the plugin zip file, then calling on the wrapper to provide the framework interactions.Standalone Connector Plugin Application
The second goal of the plugin-client is to allow Java SDK plugins to run remotely. The instructions for deploying a connector using this method are provided below.Locating the UberJar
The uberjar is located in this location in the Fusion file system:$FUSION_HOME is your Fusion installation directory and <version> is your Fusion version number.Starting the Host
To start the host app, you need a Fusion SDK-based connector, built into the standard packaging format as a.zip file. This zip must contain only one connector plugin.Here is an example of how to start up using the web connector:Simple Connector
Fusion Connector Plugin Client
The Fusion connector plugin client provides a wrapper for the Fusion Java plugin-sdk so that plugins do not need to directly talk with gRPC code. Instead, they can use high-level interfaces and base classes, like Connector and Fetcher.The plugin client also provides a standalone “runner” that can host a plugin that was built from the Fusion Java Connector SDK. It does this by loading the plugin zip file, then calling on the wrapper to provide the framework interactions.Standalone Connector Plugin Application
The second goal of the plugin-client is to allow Java SDK plugins to run remotely. The instructions for deploying a connector using this method are provided below.Locating the UberJar
The uberjar is located in this location in the Fusion file system:$FUSION_HOME is your Fusion installation directory and <version> is your Fusion version number.Starting the Host
To start the host app, you need a Fusion SDK-based connector, built into the standard packaging format as a.zip file. This zip must contain only one connector plugin.Here is an example of how to start up using the web connector:ImportantIf you are using Fusion 5.9 or later, the Connectors SDK was upgraded to use Java 11. New connectors built for Fusion 5.9 or later should be compiled on Java 11. Existing connectors built on older versions of the Connectors SDK may still be compiled on Java 8.
Public Connectors SDK Resources
The connectors SDK public Github repository provides resources to help developers build their own Fusion SDK connectors. Some of the resources include documentation and getting started guides, as well as example connectors. The repository includes a Gradle project, which wraps each known plugin with a common set of tasks and dependencies. See the Simple Connector example for instructions on how to build, deploy and run.Fusion SDK Connectors Overview
The connectors architecture in Fusion 4 and later is designed to be scalable. Depending on the connector, jobs can be scaled by adding instances of just the connector. The fetching process for these types also supports distributed fetching, so that many instances can contribute to the same job. Connectors can be hosted within Fusion, or can run remotely. In the hosted case, these connectors are cluster aware. This means that when a new instance of Fusion starts up, the connectors on other Fusion nodes become aware of the new connectors, and vice versa. This simplifies scaling connectors jobs. In the remote case, connectors become clients of Fusion. These clients run a lightweight process and communicate to Fusion using an efficient messaging format. This option makes it possible to put the connector wherever the data lives. In some cases, this might be required for performance or security and access reasons. The communication of messages between Fusion and a remote connector or hosted connector are identical; Fusion sees them as the same kind of connector. This means you can implement a connector locally, connect to a remote Fusion for initial testing, and when done, upload the exact same artifact (a zip file) into Fusion, so Fusion can host it for you. The ability to run the connector remotely makes the development process much quicker.Connectors SDK support matrix
| Fusion release | SDK version |
| 5.11.x - 5.12.x | 4.2.1 |
| 5.9.x - 5.10.x | 4.2.0 |
| 5.8.0 - 5.8.x | 4.1.4 |
| 5.6.x - 5.7.x | 4.1.3 |
| 5.5.1-1 - 5.5.1-x | 4.1.2 |
| 5.5.1 - 5.5.x | 4.1.2 |
| 5.5.0 | 4.1.1 |
| 5.4.4 - 5.4.x | 4.1.0 |
| 5.4.0 - 5.4.3 | 4.0.0 |
| 5.3.0 - 5.3.x | 3.0.0 |
| 5.2.1 - 5.2.x | 2.0.3 |
| 5.2.0 | 2.0.2 |
| 5.1.2 - 5.1.x | 2.0.1 |
| 5.1.0 - 5.1.1 | 2.0.0 |
| 5.0.2 | 2.0.0-pre-release |
| 4.2.6 | 1.5.0 |
| 4.2.4 - 4.2.5 | 1.4.0 |
| 4.2.2 - 4.2.3 | 1.3.0 |
| 4.2.1 | 1.2.0 |
| 4.2.0 | 1.1.0 |
Java SDK
The Java SDK provides components for making it simple to build a connector in Java. Whether the plugin is a true crawler or a simple iterative fetcher, the SDK supports both. The Java SDK includes a set of base classes and interfaces. It also provides the Gradle build utilities for packaging up a connector, and a connector client application that can run your connector remotely. Many of the base features needed for a connector are provided by Fusion itself. When a connector first connects to Fusion, it sends along its name, type, schema, and other metadata. This connection then stays open, and the two systems can communicate bi-directionally as needed. This makes it possible for Fusion to manage configuration data, the job state, scheduling, and encryption for example. The Fusion Admin UI also takes care of the view or presentation, by making use of the connector’s schema. This client-based approach decouples connectors from Fusion, which allows hot deployment of connectors through a simple connect call.Distributed Data Store
The data persisted by the connectors framework is distributed across the Fusion cluster. Each node holds its primary partition of the data, as well as backups of other partitions. If a node goes down during a crawl, the data store remains intact and usable. Connector implementations do not need to be concerned with this layer, because it is all handled by Fusion.Server Side Processing
An important point to consider when building a connector is that the server does not guarantee ordering of emitted items such as Candidates, Documents, Deletes, etc., when processing. Therefore, any connector logic that depends on precise ordering of processing (including index-pipeline and Solr commits) may produce incorrect results. For example, when a document replace is immediately followed by a delete-by-query, and the delete-by-query depends on the document replace to be fully processed and committed. If the document commit has not yet occurred, then the delete-by-query may result in the wrong items being deleted.CrawlDB fields
- Core fields required for any connector include: id and state_s.
- Connector specific values include the “fields” and “metadata” properties, which result in Solr document prefixed fields: field_ and meta_, respectively.
| Field Name | Field Description | Example value |
| id | Unique candidate indentifier | content:/app |
| jobId_s | Unique job identifier. All items processed in the new job will have a different jobId. | KTPbmHYTqm |
| blockId_s | A BlockId identifies a series of 1 or more Jobs, and the lifetime of a BlockId spans from the start of a crawl to the crawls completion.When a Job starts and the previous Job did not complete (failed or stopped), the previous Job’s BlockId is reused. The same BlockId will be reused until the crawl successfully completes.BlockIds are used to quickly identify items in the CrawlDb which may not have been fully processed (complete). | KwhuWW7wya |
| state_s | State transition. Possible values (FetchInput, Document, Skip, Error, Checkpoint, ACI(AccessControItem), Delete, FetchResult). | Document |
| targetPhase_s | Name of the phase this item is emitted to. | content |
| sourcePhase_s | Name of the phase an item was emitted from. | content |
| isTransient_b | Flag to indicate that the item should be removed from CrawDB after it has been processed. | false |
| isLeafNode_b | This flag is used to prioritize the processing leaf node instead of nested nodes to avoid emitting of too many Candidates. | false |
| createdAt_l | Item created timestamp. | 1566508663611 |
| createdAt_tdt | Item created ISO date. | 2019-08-22T21:17:43.611Z |
| modifiedAt_l | Timestamp value which is updated when item changes its state. Also, if purge stray items feature is enabled in the connector plugin, this field is used to determine whether the item is stray or not, then the item is deleted if it’s a stray item. | 1566508665709 |
| modifiedAt_tdt | ISO date value which is updated when item changes its state. It serves same purpose as modifiedAt_l. | 2019-08-22T21:17:45.709Z |
| fetchInput_id_s | FetchInput Id. | /app |
For information about Fusion 4.2.x, see Fusion 4.2.x Connectors SDK.
Checkpoints in the Connectors SDK
Use Cases
Incremental Re-crawl
Incremental re-crawl can be supported when a Changes API is available (e.g., Jive, Salesforce, OneDrive). When a Changes API is available, it’s necessary to provide an input parameter to be tracked, such as a date, link, page token, or other. The input parameter is generated (retrieved) while running the first job. During the next job, that parameter will be used to query the Changes API and retrieve new, modified, and deleted objects. The SDK provides a way to store the input parameters, establishing checkpoints, and use them in the subsequent jobs.Checkpoint Design
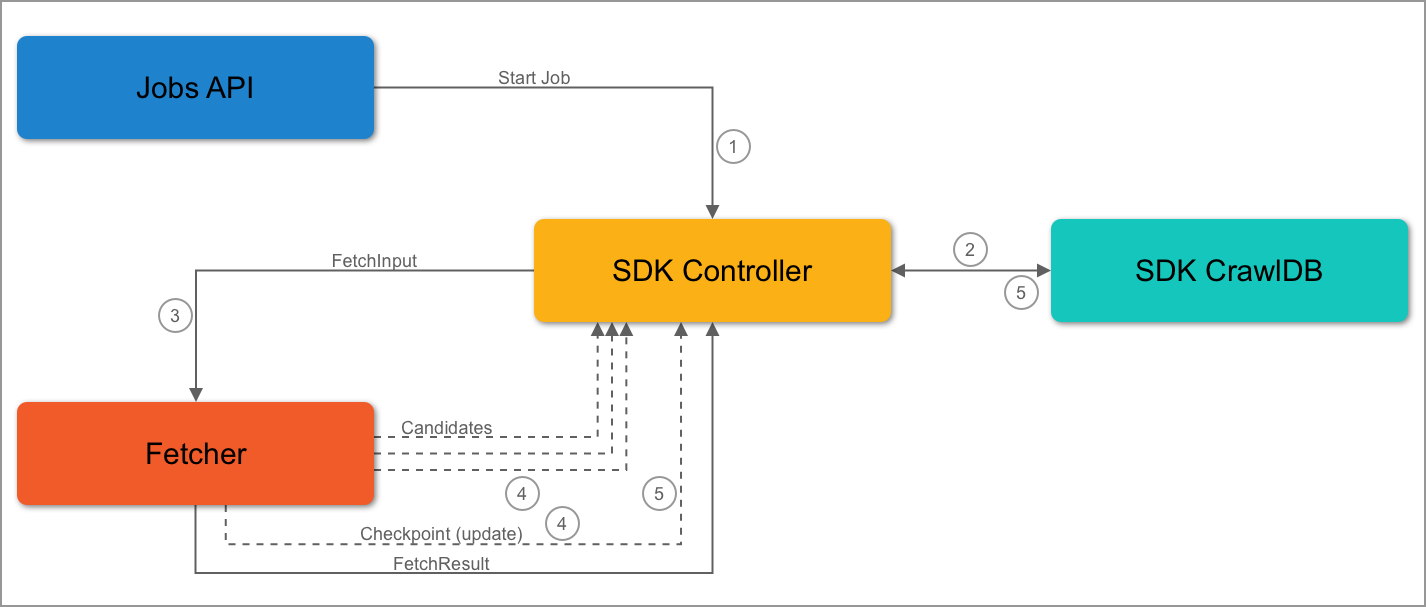
Fetcher implementations can emit checkpoint messages by calling:- The checkpoint will be stored in the CrawlDB with the appropriate status.
- The checkpoint will not be used in the current job.
ImportantIn order to update a checkpoint, it must be emitted using its original ID. The ID is the only way the SDK controller can identify and update a checkpoint.
First Job Flow
- During the job, the fetcher receives a FetchInput.
- The fetcher can then emit candidates and/or checkpoints.
-
When the SDK controller receives a checkpoint message, the checkpoint is stored or updated in CrawlDB. It will also process the other items it has received.
- The SDK controller will not send the checkpoint to the fetcher in the same job.
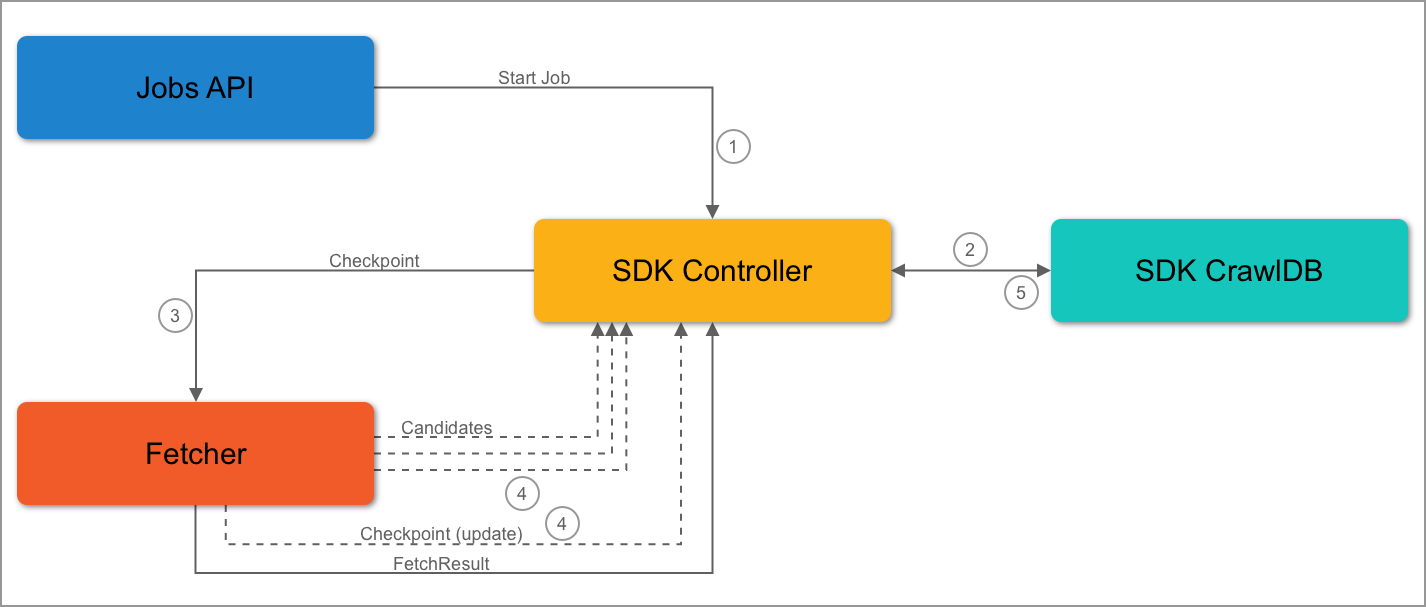
Second Job Flow
- If the checkpoint data matches current data, the fetcher will emit the same checkpoint.
- The SDK controller will process the candidates and update the checkpoint data in the SDK CrawlDB.
Stopping a Running Job
When a job is stopped, the current state of the job is stored so that it can be completed when the job is resumed.Stop Handling Design
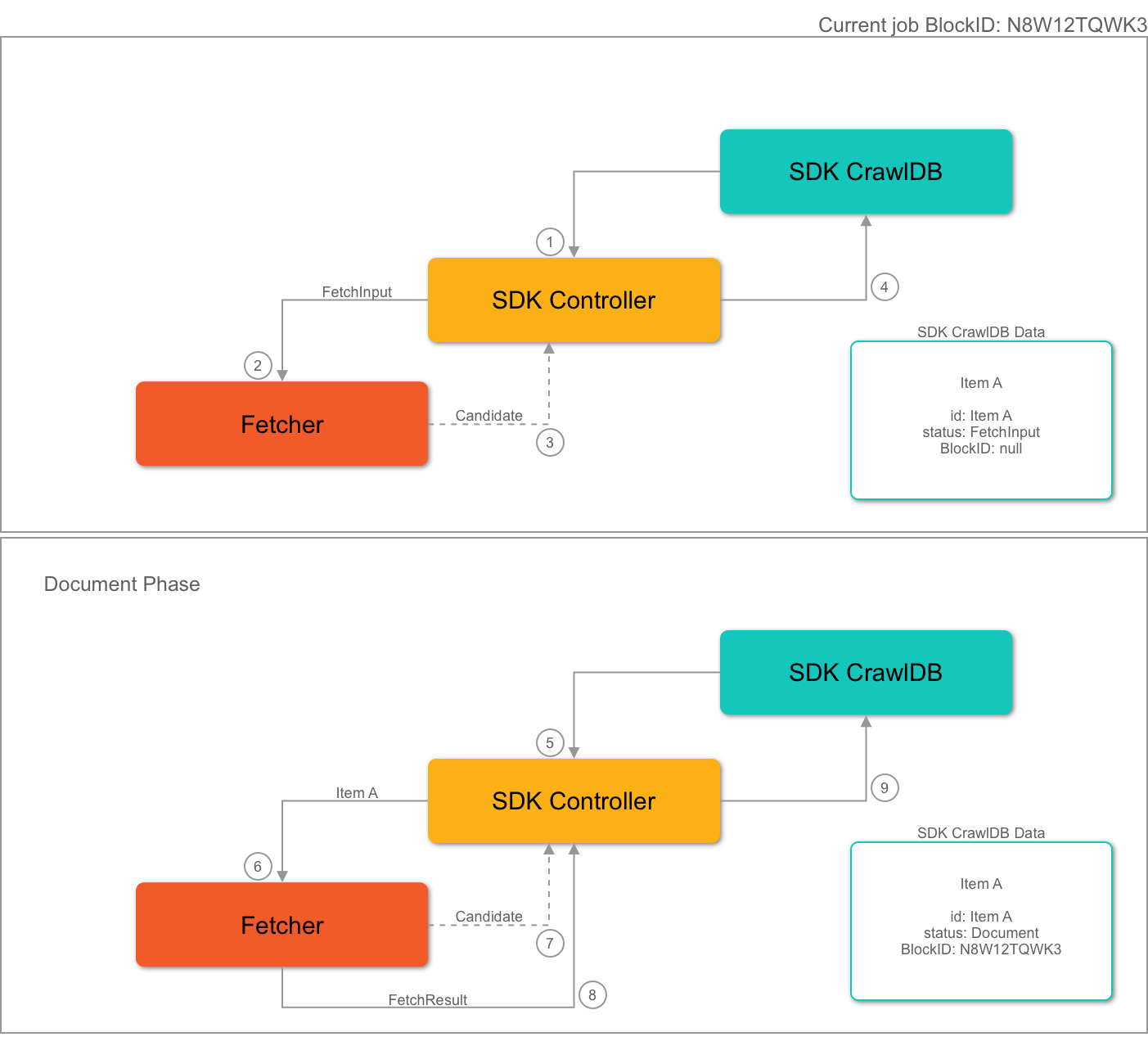
The SDK controller will keep track of the incomplete/complete items during a job. An incomplete item is an item that was emitted as a candidate but has not been sent to the fetcher to be processed. Alternatively, the fetch implementation may not have emitted the FetchResult message for that item. The incomplete item is stored in the SDK CrawlDB and marked as incomplete. A completed item is one that was emitted first as a candidate and also sent to the fetcher to be processed. The fetcher completes the process by sending back a FetchResult. This item is then marked as complete by the SDK controller by setting theblockID field in the item metadata to match the blockID of the current job.
A blockId is used to quickly identify items in the CrawlDB which may not have been fully processed, or completed. A completed job is one that naturally stops due to source data being fully processed, as opposed to jobs that are manually stopped or fail.
blockId’s identify a series of one or more jobs. The lifetime of a blockIdspans from either the start of the initial crawl (or immediately after a completed one), all the way to completion. The SDK controller will generate and use a newblockId` when:
- The current job is the first job.
- The previous job’s state is
FINISHED.
STOPPED. In this case, the previous job’s blockId is reused. The same blockId will be reused until the crawl successfully completes. The SDK controller will continue checking the CrawlDB for incomplete items, which are identified by having a blockID that doesn’t match the previous job blockID. This approach ensures all items within the job are completed before the next job beings, even if the job was stopped multiple times before completion.
When an item is considered a new candidate, the item’s blockId does not change. Later, when the item is fully processed by the fetcher, the blockId is added to the item metadata and stored in the SDK CrawlDB. The item is then considered complete but will only be sent to fetchers when a new blockId is generated.
When all items are complete, the SDK will check for checkpoints, as detailed in Checkpoint Design.
ImportantIf there are incomplete items from the previous job stored in the SDK CrawlDB, only those items will be processed during the next job.
Item Completion Flow
he fetcher.
2. The fetcher receives the FetchInput.
3. The fetcher emits a candidate: Item A.
4. The controller receives the candidate and stores it in the SDK CrawlDB. Mandatory fields are set to the item metadata, but the blockId field is not set.
5. Later, in the same job, the candidate Item A is selected by the SDK controller, which sends it to a fetcher.
6. The fetcher receives the candidate and processes it.
7. The fetcher emits a Document from the candidate.
8. The fetcher emits a FetchResult to the SDK controller.
9. The SDK controller receives both the Document and the FetchResult.
- If processing the Document, the item status is updated to Document in SDK CrawlDB.
- If processing the FetchResult, the item’s blockId is set to the current job’s blockId.
Transient candidates
Some connector plugins require that a new job start from the latest checkpoints and not attempt to reprocess incomplete candidates. For that purpose, emit those candidates withTransient=true. The IncrementalContentFetcher is an example.