- Cold Start Part 1
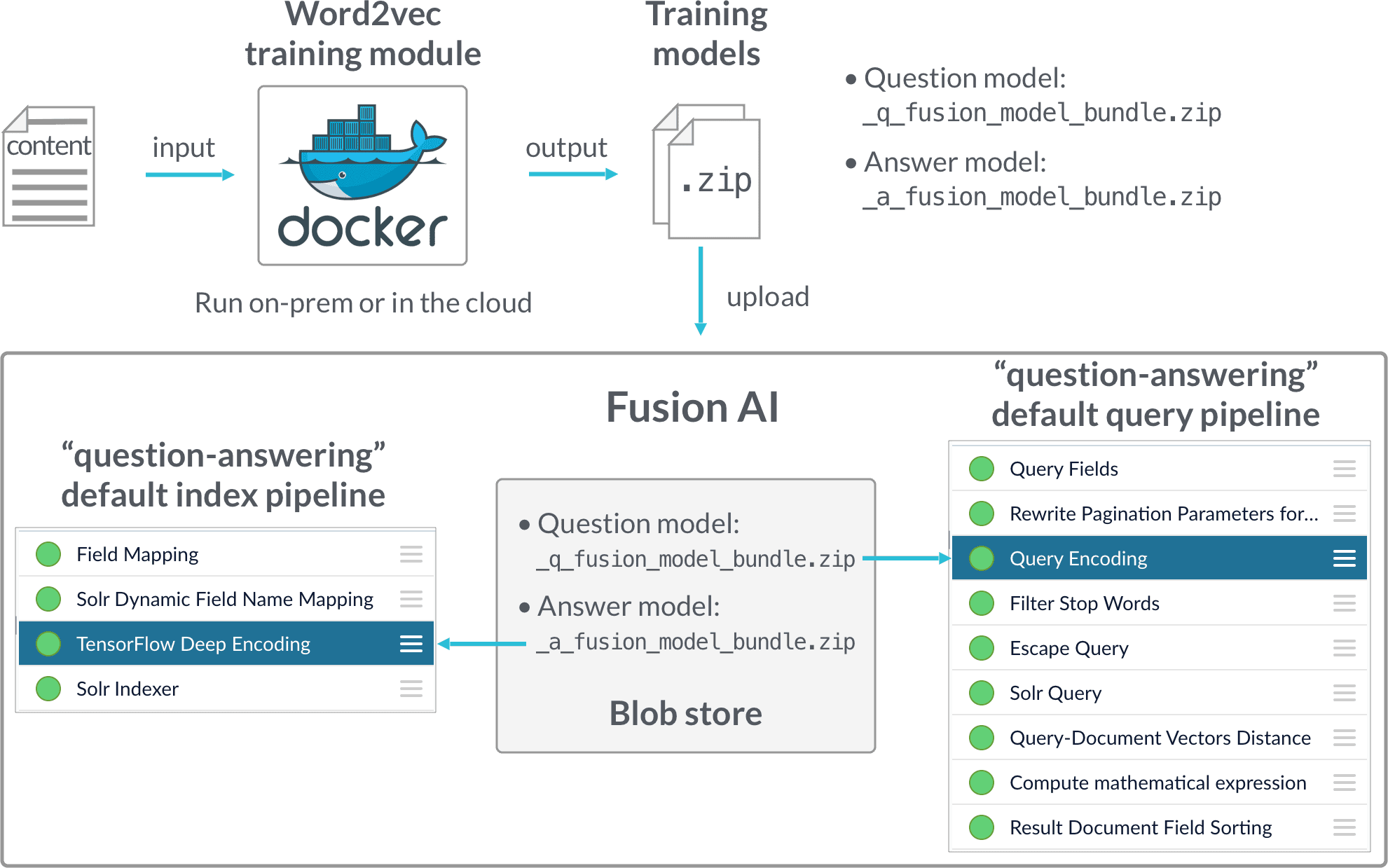
Model training is performed in a Docker image, which can be downloaded from the Lucidworks Docker hub. The deep learning/word vector training modules and configuration UI are installed in the Docker image, and it can be used on-prem or in the cloud.
After training is finished, a.zipfile is generated which includes the model and associated files. The model transforms documents into digital vectors which can be used to measure similarities. - Smart Answers Cold Start Part 2
Deployment is performed in Fusion. To deploy, you just upload the generated zip file to Fusion and use our provided query pipeline to conduct run-time neural search.
Cold Start Part 1
Cold Start Part 1
The cold start solution for Smart Answers in Fusion 4.2 begins with training a model using your existing content and the Word2vec training module in the Docker container. Once you have trained a model, you can deploy it using the information in the Smart Answers Cold Start Part 2 topic.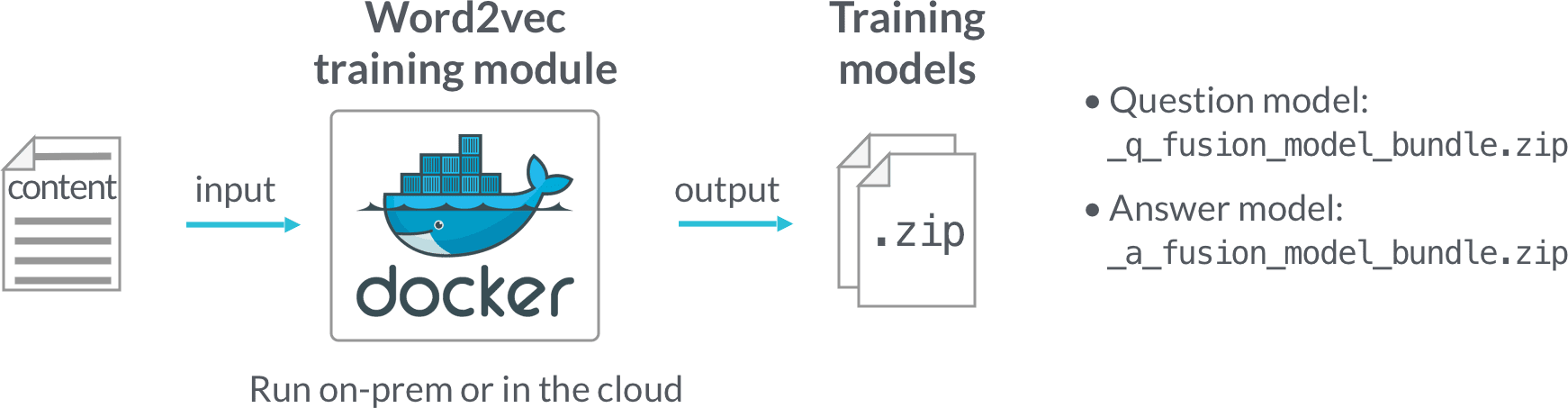
Prerequisites
You need a Docker Hub account with access to thelucidworks/ai-lab repository. Contact Lucidworks AI Labs with your Docker Hub account name to gain access to this repository.Hardware requirements and instance setup
The Docker training module can run on either a CPU or a GPU.CPU is sufficient for most use cases.GPU is 2-8 times faster. GPU is recommended if want to try our model auto-tune feature on a large dataset (e.g. over 20k QA pairs) or if the training data size is over 1 million entries for any of the training scenarios.You can run the Docker image either on-prem or in the cloud. We recommend a minimum of 32GB RAM and 32 cores for a CPU server or a cloud instance. If you choose a GPU machine, one GPU with 11GB memory is sufficient for most training use cases.Below are examples of the AWS instance types that we recommend:CPU:- AMI: Ubuntu Server 18.04 LTS (HVM), SSD Volume Type
- Instance Type: c5.9xlarge (36 vCPUs, 72 GB RAM)
- Recommended storage volume: Suggested 150GB plus 2.5 times the total input data size
- Networking
- Allow inbound port 4440
- Allow inbound port 5550
- AMI: Deep Learning AMI (Ubuntu) Version 22.0
- Instance Type: p2.xlarge (11.75 ECUs, 4 vCPUs, 61 GB RAM, EBS only)
- Recommended storage volume: Suggested 150GB plus 2.5 times of total input data size.
- Networking
- Allow inbound port 4440
- Allow inbound port 5550
- Deep Learning Virtual Machine
- Linux OS
- VM Size: 1x Standard NC6 (6 vcpus, 56 GB memory)
- Recommended OS Disk Size: Suggested 150GB plus 2.5 times the total input data size
- Networking
- Allow inbound port 4440
- Allow inbound port 5550
Docker image setup
- Determine the instance’s external hostname. Refer to your cloud provider’s documentation for instructions on how to do this.
-
Create a directory, such as
/opt/faq_training, and ensure it meets disk space requirements. Also ensure that it is writable by thedockerLinux user account. The training Docker container requires this directory to read input files, write temporary files, and write the output (deep learning models). -
Run
docker loginand enter your account credentials. -
Pull the
lucidworks/ai-lab:latestimage: -
Run the Docker image:
For GPU instance:For CPU-only instance:This starts the Docker container in the background. -
Wait about one minute for the container to initialize.
In your working directory, you should see these directories:
-
The
inputdirectory is where all training data and input files should be placed. -
The
outputdirectory contains the models that result from the training. - All other directories are used by the model training container to save persistent files or temporary files.
-
The
-
Point your browser to
http://<external hostname>:4440. This redirects you to a Rundeck login screen. - Log in with your username and password.
Running Jobs
We use https://www.rundeck.com/open source[Rundeck^] to control job runs.-
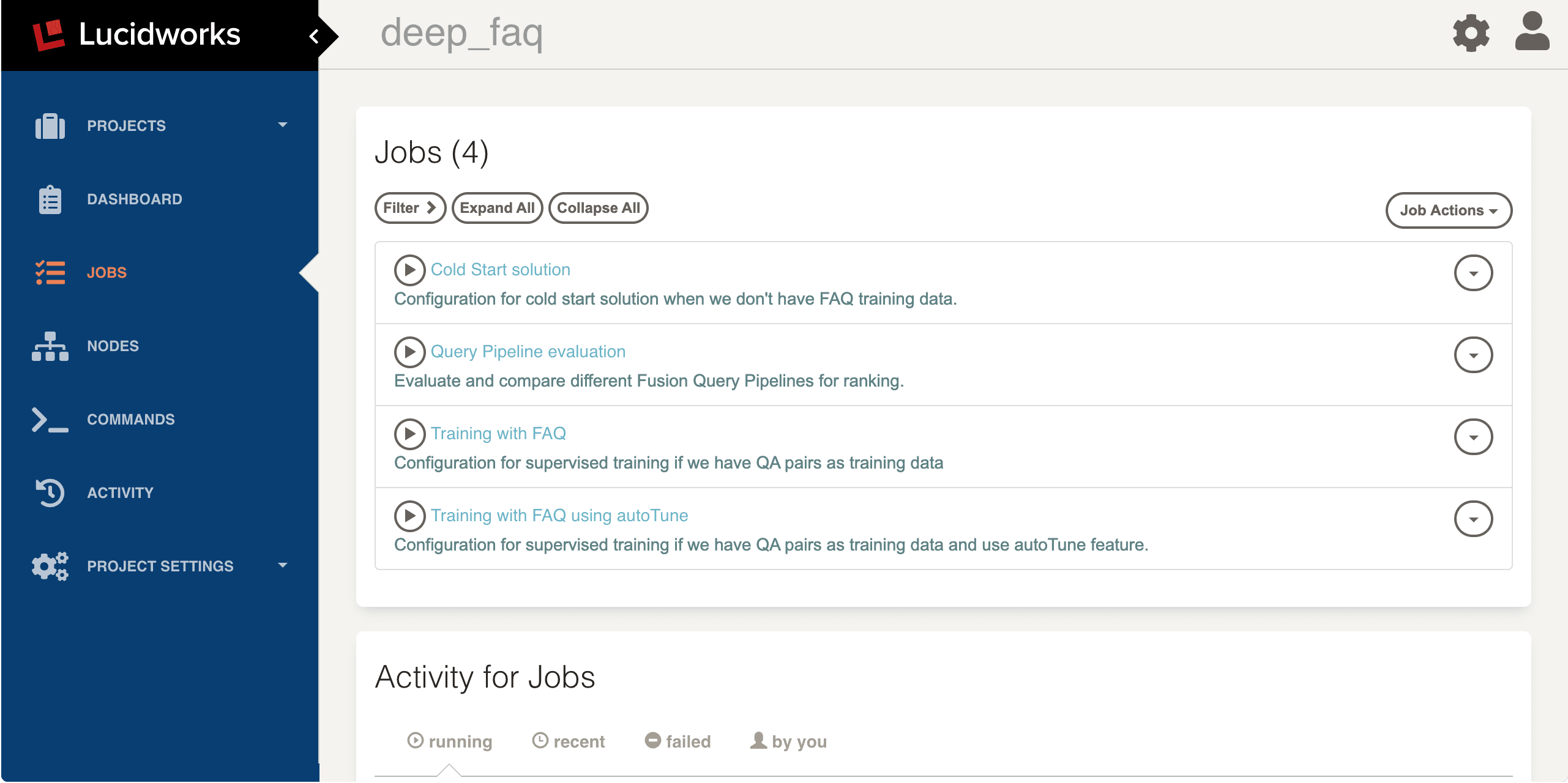
When Rundeck has started, click on the
deep_faqproject. This opens the JOBS panel, where you will see three jobs for different training scenarios and one job for query pipeline evaluation.- Click on a job to configure job parameters.
- Click Run Job Now to start the job.
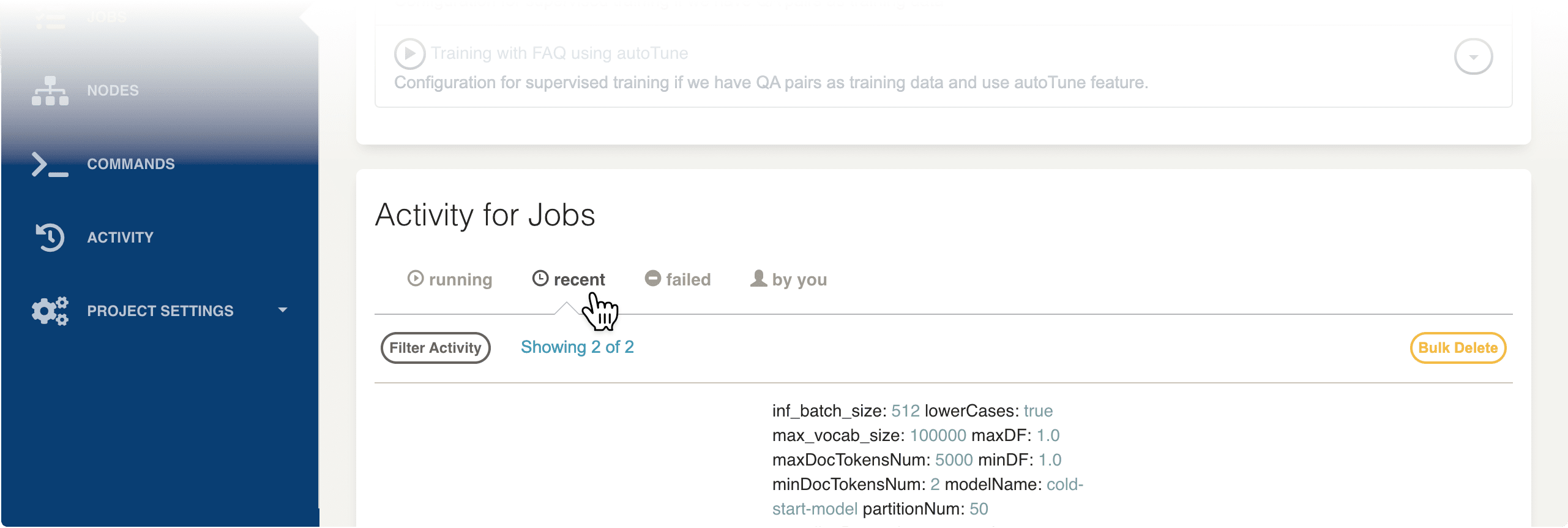
- You can monitor the progress of a job by clicking on the running button under the Activity for Jobs section as shown in the screenshot below.
If similar jobs have run before, then Rundeck estimates the total run time and displays a progress bar.
Training scenarios and configuration
Click on the Cold Start solution job.This job can learn about the vocabulary that you want to search against through Word2vec. And we can combine Solr with Word2vec at query time using our query pipeline.Input data parameters
For cold start solution input, these parameters are required:- Content documents file name
- Field which contains the content documents
- You can use the pre-trained word embeddings included with our training module. In cold start mode, it gets the Word2vec vectors from the pre-trained file directly. The pre-trained word embeddings are built on a large corpus from the Internet, covering common words we use daily.
- If there are many domain-specific words or special tokens in your documents, we recommend training Word2vec using your own data. Set the Generate customized embeddings parameter to “true” to train from your own data. This uses the data and field specified in Content documents file name and Field which contains the content documents to train Word2vec vectors.
You must provide a Model name for model tracking and version control purposes. If you use the same model name across different runs, the new model will replace the old model with the same name.
Result models
Track the running steps in the log, which provides information on data pre-processing, training steps, evaluations, and model generation in the end.After training is finished, the final models and their associated files are saved in zip file format, which can be downloaded fromhttp://<external hostname>:5550/{modelName}.Download the two zipfiles ending with _a_fusion_model_bundle.zip and _q_fusion_model_bundle.zip to be used in the Smart Answers Cold Start Part 2 phase.Smart Answers Cold Start Part 2
Smart Answers Cold Start Part 2
The Smart Answers deployment procedure for the FAQ solution and the cold start solution is the same:
See Configure the index pipeline below.Default query pipelines
See Configure the query pipeline below.
- Upload the question and answer models to the blob store.
-
Configure the
question-answeringindex pipeline so that it uses the answer model. -
Configure the
question-answeringquery pipeline so that it uses the question model.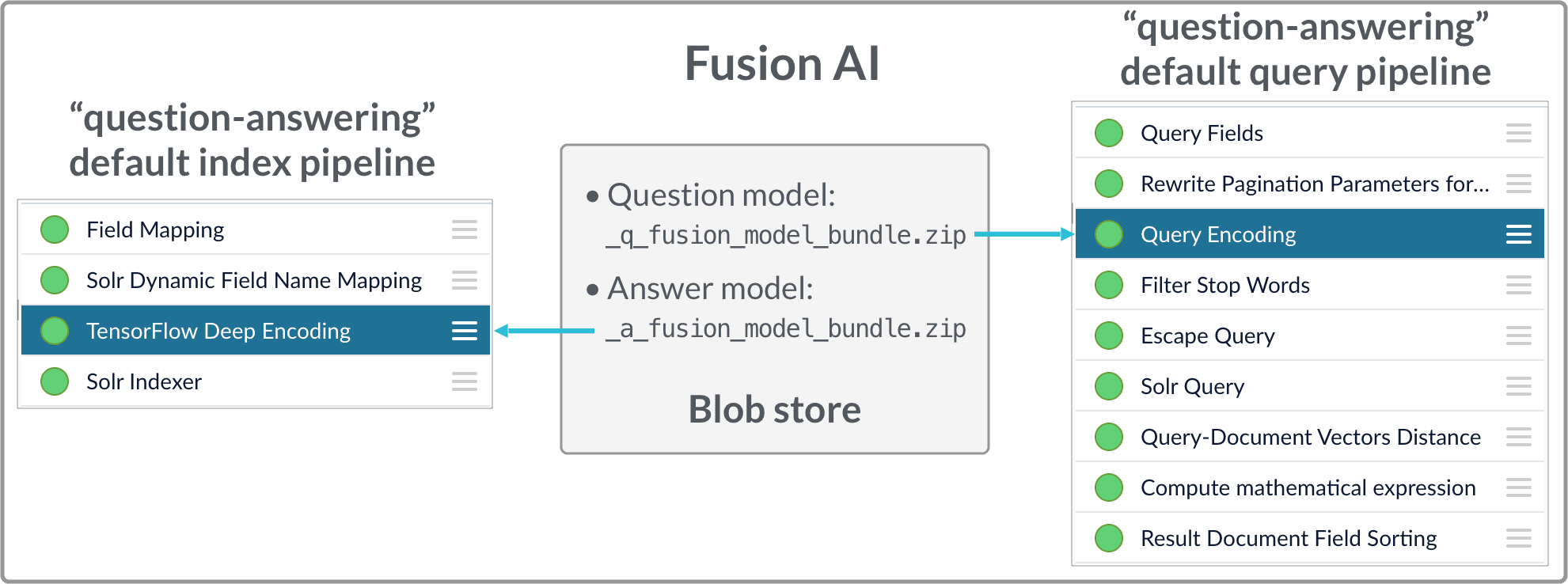
How to upload the models to the blob store
Two model files are generated by the FAQ Solution Part 1 Docker job:x_a_fusion_model_bundle.zip- The answer model.x_q_fusion_model_bundle.zip- The question model.
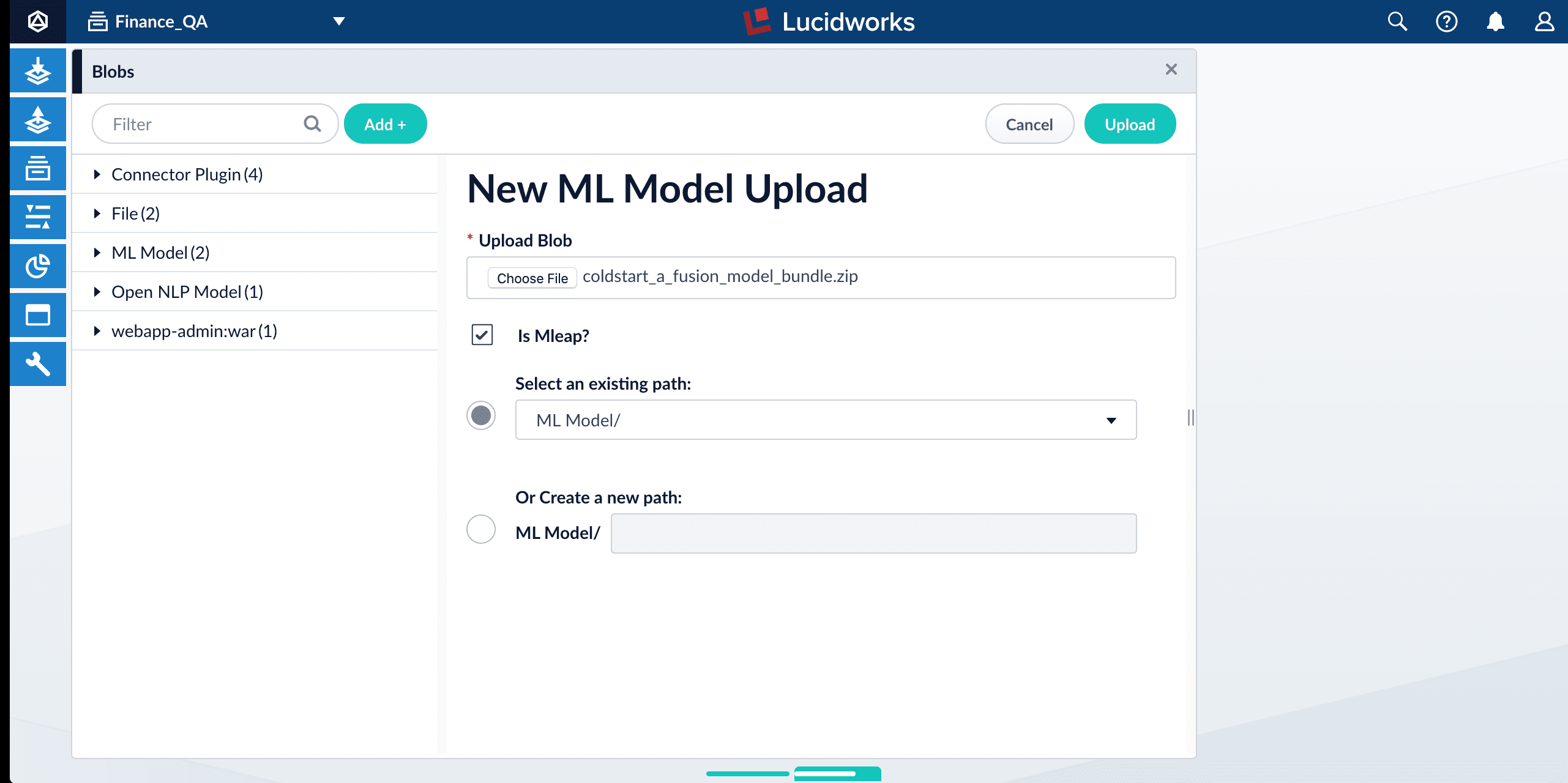
- In the Fusion UI, navigate to System > Blobs.
- Click Add > ML Model.
- Click Choose File and select one of the model files.
-
Make sure the Is Mleap? checkbox is selected.
-
Click Upload.
- Repeat steps 2-5 for the other model file.
Fusion configuration overview
-
Fusion index pipeline
The index pipeline uses the trained model in
x_a_fusion_model_bundle.zipto generate dense vectors for the documents to be indexed. -
Fusion query pipeline
The query pipeline uses the trained model in
x_q_fusion_model_bundle.zipto generate dense vectors for incoming questions on the fly, then compare those with the indexed dense vectors for answers to find answers, or with the indexed dense vectors for historical questions to find similar questions.
How to configure the default pipelines
If you have an AI license, then the following default index and query pipelines are included in any newly-created Fusion app:Default index pipelines| Default pipeline | Notes |
|---|---|
question-answering | For encoding one field. |
question-answering-dual-fields | For encoding two fields (question and answer pairs, for example). |
| Default pipeline | Notes |
|---|---|
question-answering | Calculates vectors distances between an encoded query and one document vector field. Should be used together with question-answering index pipeline. |
question-answering-dual-fields | Calculates vectors distances between an encoded query and two document vector fields. After that, scores are ensembled. Should be used together with the question-answering-dual-fields index pipeline. |
Configure the index pipeline
- Open the Index Workbench.
- Load or create your datasource using the default question-answering index pipeline.
-
In the TensorFlow Deep Encoding stage, change the value of TensorFlow Deep Learning Encoder Model ID to the model ID of the
x_a_fusion_model_bundle.zipmodel that was uploaded to the blob store. - Change Document Feature Field to the document field name to be processed and encoded into dense vectors.
- Save the datasource.
- Index your data.
Configure the query pipeline
- Open the Query Workbench.
- Load or create your datasource using one of the default question-answering query pipelines.
-
In the Query Fields stage, update Return Fields to return additional fields that should be displayed with each answer, such as fields corresponding to title, text, or ID.
It is recommended that you remove the asterisk (
*) field and specify each individual field you want to return, as returning too many fields will affect runtime performance. Do not removecompressed_document_vector_s,document_clusters_ss, andscoreas these fields are necessary for later stages -
In the TensorFlow Deep Encoding stage, change TensorFlow Deep Learning Encoder Model ID value to the model ID of the
x_q_fusion_model_bundle.zipmodel that was uploaded to the blob store. - Save the query pipeline.
Pipeline Setup Examples
- Example 1 - Index and retrieve question and answer separately
- Example 2 - Index and retrieve question and answer together
Example 1 - Index and retrieve question and answer separately
Based on your search Web page design, you can put best-matched questions and answers in separate sections, or if you only want to retrieve answers and serve to chatbot app, please index them separately in different documents.For example, in the picture below, we construct the input file for the index pipeline such that the text part of the question/answer is stored intext_t, and we add an additional field type_s whose value is “question” or “answer” to separate the two types.In the TensorFlow Deep Encoding stage, we specify Document Feature Field as text_t so that compressed_document_vector_s is generated based on this field.At search time, we can apply a filter query on the type_s field to return either a question or an answer.You can achieve a similar result by using the default question-answering index and query pipelines.Example 2 - Index and retrieve question and answer together
If you prefer to show question and answer together in one document (that is, treat the question as the title and the answer as the description), you can index them together in the same document. It’s similar to thequestion-answering-dual-fields index and query pipelines default setup.For example, in the picture below, we added two TensorFlow Deep Encoding stages and named them Answers Encoding and Questions Encoding respectively. In the Questions Encoding stage, we specify Document Feature Field to be question_t, and changed the default values for Vector Field, Clusters Field and Distances Field to question_vector_ds, question_clusters_ss and question_distances_ds respectively. In the Answers Encoding stage, we specify Document Feature Field to be answer_t, and changed the default values for Vector Field, Clusters Field and Distances Field to answer_vector_ds, answer_clusters_ss and answer_distances_ds respectively. (Detailed information of the above field setup please refer to the “Appendix C: Detailed Pipeline Setup” section.)Since we have two dense vectors generated in the index (compressed_question_vector_s and compressed_answer_vector_s), at query time, we need to compute query to question distance and query to answer distance. This can be setup as the picture shown below. We added two Vectors distance per Query/Document stages and named them QQ Distance and QA Distance respectively. In the QQ Distance stage, we changed the default values for Document Vector Field and Document Vectors Distance Field to compressed_question_vector_s and qq_distance respectively. In the QA Distance stage, we changed the default values for Document Vector Field and Document Vectors Distance Field to compressed_answer_vector_s and qa_distance respectively. (Detailed information of the above field setup please refer to the “Appendix C: Detailed Pipeline Setup” section.)Now we have two distances (query to question distance and query to answer distance), we can ensemble them together with Solr score to get a final ranking score. This is recommended especially when you have limited FAQ dataset and want to utilize both question and answer information. This ensemble can be done in the Compute mathematical expression stage as shown below.Query pipeline evaluation
Stages and configurations of the query pipeline will impact ranking results. For example, we may need to make decisions about whether to use clustering option in the TensorFlow Deep Encoding stage, what should be the weights of each ranking score in the Compute mathematical expression stage, whether adding other Fusion stages (such as text tagger, ML stage) would help. Comparing two different query pipelines with different models and setups may be needed as well.The Query Pipeline evaluation job in the training docker image can help evaluate the rankings of Fusion returned results from different pipeline setups, additionally help search for the best set of weights in the ensemble score.In order to evaluate the rankings, we need to know the ground truth answers for some testing questions. For example, user can provide around 200 testing questions, and for each question, we need to know which indexed answers are the correct answers in Fusion, so that we can compute positions of correct answers in the current ranking. User needs to provide a file in CSV format which contains the testing questions (Testing query field parameter in the job) and correct answer text or id (Ground truth field parameter in the job), put this file in the mapped input folder where we put other training data files, then specify the file name in the Evaluation file name parameter. NOTE: if there are multiple matching answers for a question, please put question and answer pairs in different rows. In Fusion, there should be a returned field which contains values that match the answer text or id, please specify this field in the Answer or id field in Fusion parameter. NOTE: if use answer text, please make sure the formatting of answer text in the evaluation file is the same as the answer text in Fusion so that we can find matches. Several Fusion access parameters are also needed in order to grab results from Fusion in batch, such as login username, password, host ip, app name, collection and pipeline name.The job will provide a variety of metrics (controlled by **Metrics list parameter) at different positions (controlled by Metrics@k list parameter) in the logs for the chosen final ranking score (specified in Ranking score parameter). For example, if choose Ranking score as “ensemble_score”, the program will rank results by the ensemble score returned in Compute mathematical expression stage. If choose Ranking score as “score” (default field name for Solr score in Fusion), then the ranking evaluation will be based only on Solr score. In addition to the metrics in logs, a CSV results evaluation file will be generated. It will provide correct answer positions for each testing question as well as top returned results for each field specified in Return fields parameter. User can specify the file name for this results file in the Ranking results file name parameter, then download the file fromhttp://<external hostname>:5550/evaluation.Another function of this job is to help choose weights for different ranking scores such as Solr score, query to question distance, query to answer distance in Compute mathematical expression stage. If interested in performing this weights selection, please choose **Whether perform weights selection parameter to true, list the set of score names in List of ranking scores for ensemble parameter. Since we can use different scaling methods for Solr score in the stage, please choose which Solr scale function you used in the stage in Solr scale function parameter. Target metric to use for weight selection parameter allows to specify metric that should be optimized during weights selection, for example recall@3. Metric values at different positions for different weights combinations will be shown in the log, sorted descendingly based on metric specified above. NOTE: Weights selection can take a while to run for big evaluation datasets, thus if only interested in comparing pipelines, please turn this function off by specifying Whether perform weights selection parameter to false.There are a few additional advanced parameters that might be useful but not required to provide. Additional query parameters allows to provide extra query parameters like rowsFromSolrToRerank in a dictionary format. Sampling proportion and Sampling seed provides a possibility to run evaluation job only on a sample of data.Tip: Please make sure the Ranking score, answer text or id, and list of ranking scores for ensemble (if perform weights selection) are returned by Fusion by checking the fields returned in the Query Workbench. User can setup the returned fields in Return Fields section of Query Fields stage.