- Aggregations
- SQL Aggregations
- Signals
- Signals Data Flow
- Default Signals Index Pipeline
- Deleting Old Signals
- Signals Types and Structures
Signals
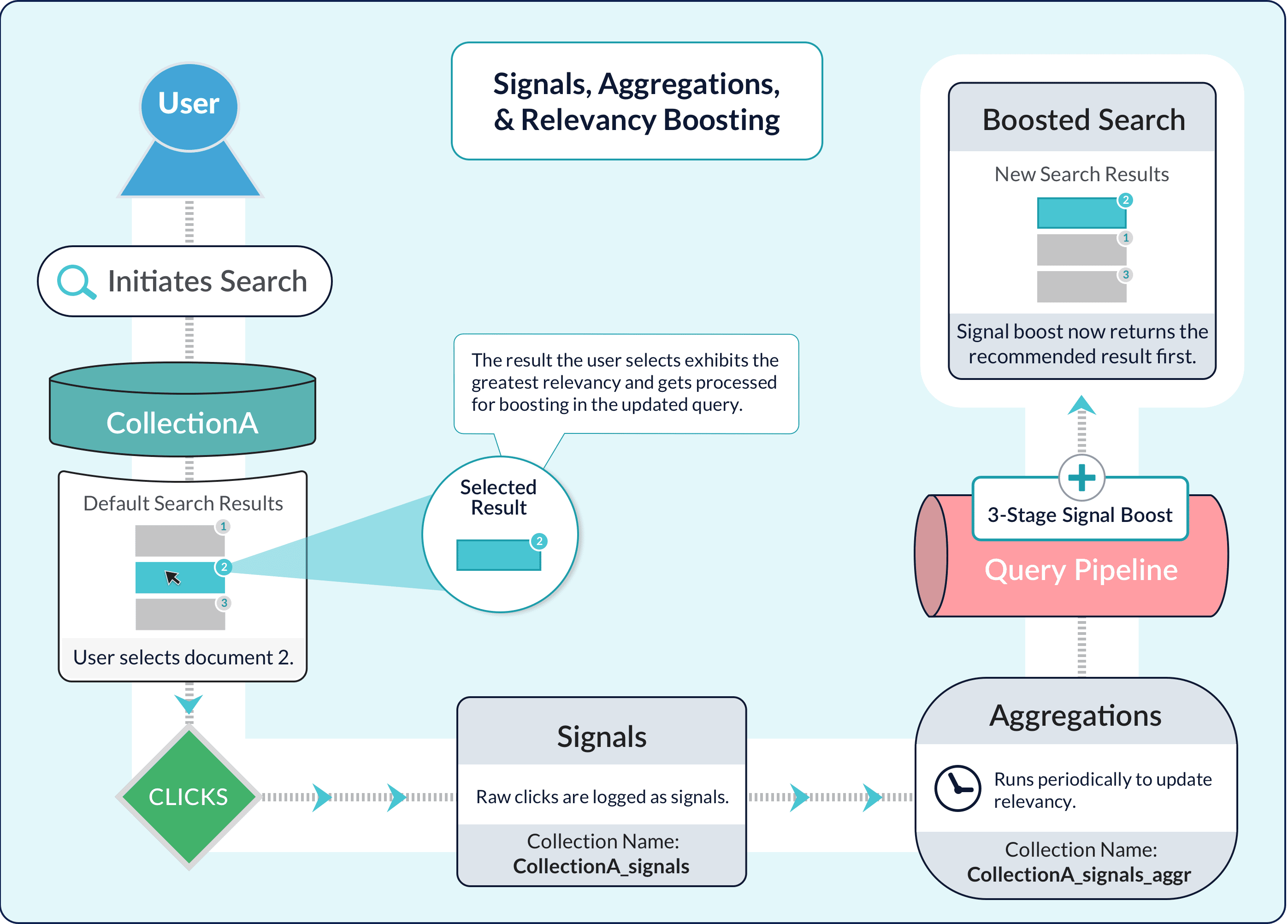
Signals are events that are collected for analysis or to enhance the search experience for end users. Common types of signal events include clicks, purchases, downloads, ratings, and so on. You can use App Insights to get visualizations and reports with which to analyze your signals data. App Insights mainly uses raw signals, but also uses some aggregated signals.Aggregations
Aggregations are processed signals. An aggregator reads the raw signals and returns interesting summaries, ranging from simple sums to sophisticated statistical functions. Crucially, it must be possible to relate the documents in an aggregated signals collection to documents in the primary collection, in order to use the aggregated signals for recommendations and/or boosting of searches over the primary collection.The cold start problem
The “cold start” problem means it is hard to personalize the search experience when insufficient signals have been aggregated. For example, it is hard to offer recommendations to users who have never visited before, or for queries that have never been issued before, or for items that have been recently introduced into the system. Fusion provides solutions for this problem using its query pipelines. A query pipeline that includes stages for blocking, boosting, or recommending based on signals can also include stages that provide fallbacks. In the case where there is not enough data to provide specialized blocking, boosting, or recommendations, the pipeline can return a simpler set of search results using Solr’s normal relevancy calculation. A common solution to the cold start problem is to sort or boost on a certain field to provide pseudo-recommendations when more specific recommendations are not available. For example, you can sort on thesales_rank field to recommend the most popular products, or boost on the date_added field to recommend the newest items.
Learn more
Configure a REST Call Job to Delete Old Signals
Configure a REST Call Job to Delete Old Signals
- Navigate to Collections > Jobs.
-
Click Add and select REST Call.
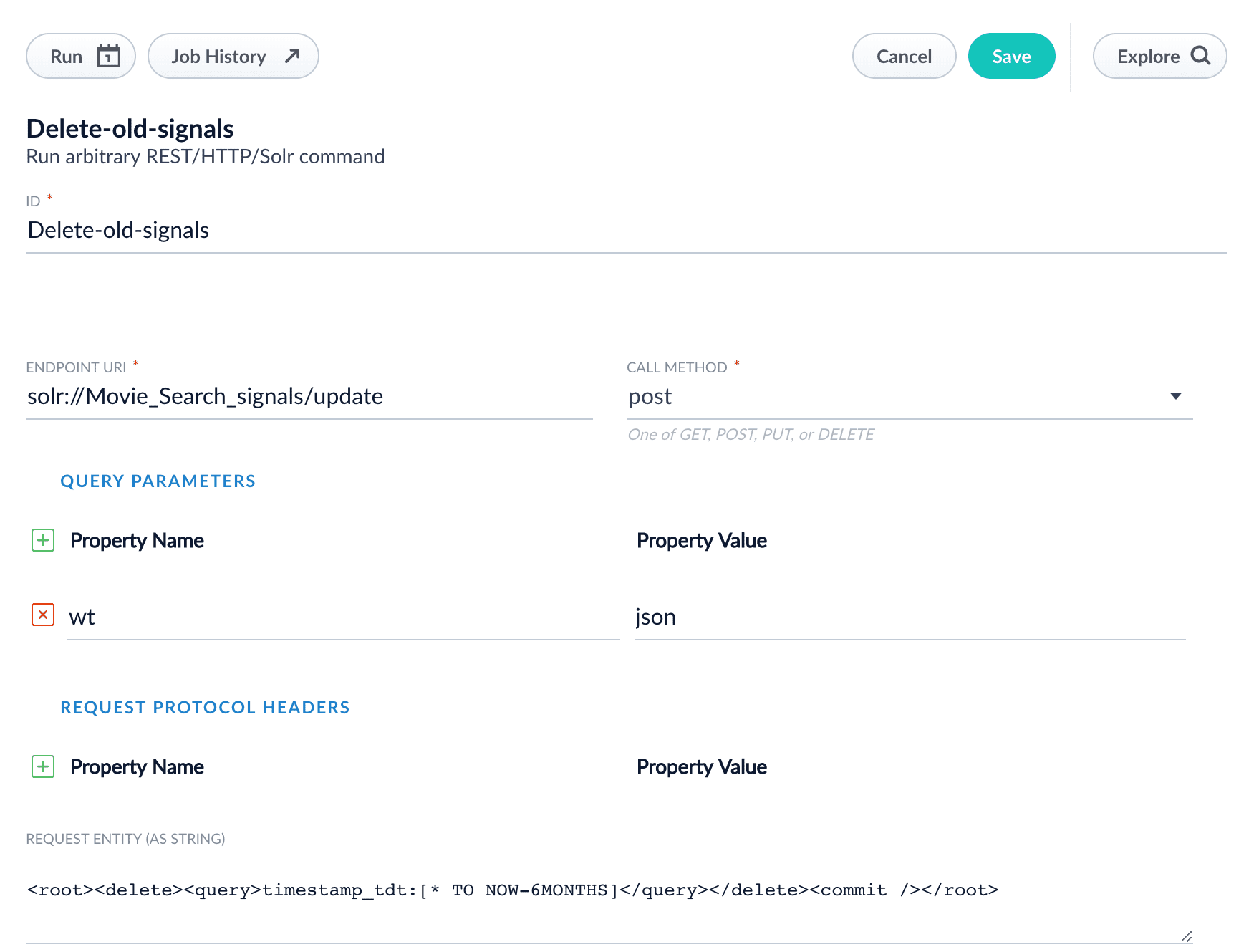
The REST Call job configuration panel appears. - Enter an arbitrary ID for this job, such as “Delete-old-signals”.
-
Enter the following endpoint URI, substituting the name of your signals collection for
signalsCollectionName: - In the Call Method field, select “post”.
- Under Query Parameters, enter the property name “wt” with the property value “json”.
-
In the Request entity (as string) field, enter the following:
See Working with Dates for details about date formatting. Your job configuration should look similar to this:
Join Signals with Item Metadata
Join Signals with Item Metadata
Fusion’s basic aggregation jobs aggregate using the document ID. You can also aggregate at a more coarse-grained level using other fields available for documents (item metadata), such as manufacturer or brand for products. Aggregating with item metadata is useful for building personalization boosts into your search application.The following PUT request creates additional aggregation jobs that join signals with the primary After performing the PUT request shown above, you will have two additional aggregation jobs in Fusion.
products collection to compute an aggregated weight for a manufacturer field:COLLECTION_NAME_user_METADATA_preferences_aggregation
This job computes an aggregated weight for each user/item metadata combination, e.g. user/manufacturer, found in the signals collection. Fusion computes the weight for each group using an exponential time-decay on signal count (30 day half-life) and a weighted sum based on the signal type. Use thesignalTypeWeights parameter to set the correct signal types and weights for your dataset. Use the primaryCollectionMetadataField parameter to set the name of a field from the primary collection to join into the results, e.g. manufacturer. You can use the results of this job to boost queries based on user preferences regarding item-specific metadata such as manufacturer (e.g. Ford vs. BMW) or brand (e.g. Ralph Lauren vs. Abercrombie & Fitch).COLLECTION_NAME_query_METADATA_preferences_aggregation
This job computes an aggregated weight for each query/item metadata combination, e.g. query/manufacturer, found in the signals collection. Fusion computes the weight for each group using an exponential time-decay on signal count (30 day half-life) and a weighted sum based on the signal type. Use thesignalTypeWeights parameter to set the correct signal types and weights for your dataset. Use the primaryCollectionMetadataField parameter to set the name of a field from the primary collection to join into the results.Retrieve a List of Signal Types
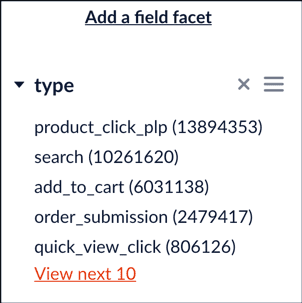
Retrieve a List of Signal Types
- In the Fusion UI, select your signals collection.
- Open the Query Workbench by navigating to Query > Query Workbench.
- Click Add a field facet.
- Select the
typefield.
The list of signal types appears in the facet panel: