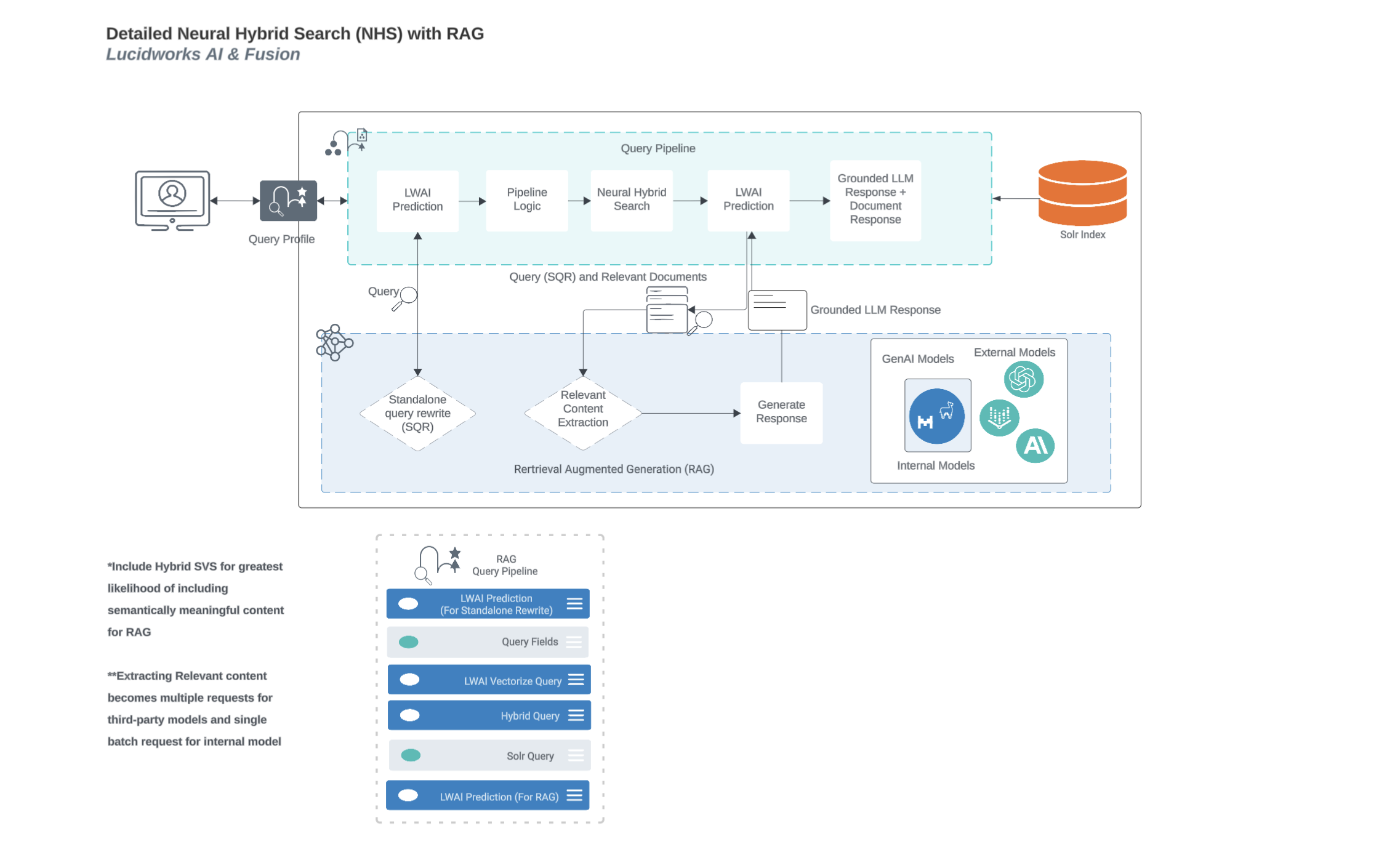
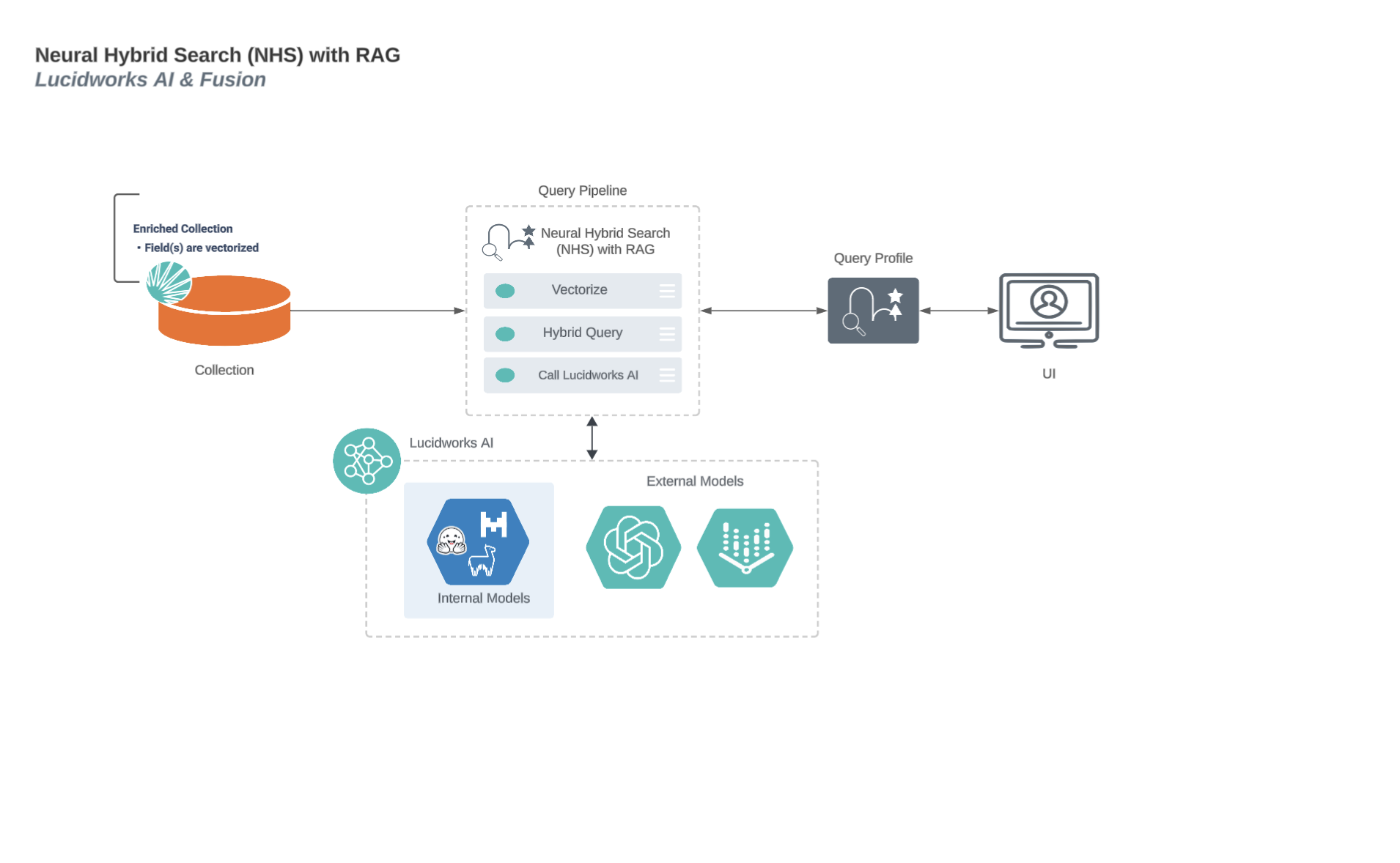
The Retrieval-augmented generation (RAG) use case of the Lucidworks AI Async Prediction API uses candidate documents that are inserted into a LLM’s context to ground the generated response to those documents instead of generating an answer from details stored in the LLM’s trained weights. This helps prevent frequency of LLM hallucinative responses. This type of search adds guardrails so the LLM can search private data collections. The RAG search can perform queries against external documents passed in as part of the request. This use case can be used:Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
- To generate answers based on the context of the responses collected (corpus)
- To generate a response based on the context from responses to a previous request
-
POST request - submits a prediction task for a specific
useCaseandmodelId. The API responds with the following information:predictionId. A unique UUID for the submitted prediction task that can be used later to retrieve the results.status. The current state of the prediction task.
-
GET request - uses the
predictionIdyou submit from a previously-submitted POST request and returns the results associated with that previous request.
For detailed API specifications in Swagger/OpenAPI format, see Platform APIs.
Prerequisites
To use this API, you need:- The unique
APPLICATION_IDfor your Lucidworks AI application. For more information, see credentials to use APIs. - A bearer token generated with a scope value of
machinelearning.predict. For more information, see Authentication API. - The
USE_CASEandMODEL_IDfields in the/async-predictionfor the POST request. The path is/ai/async-prediction/USE_CASE/MODEL_ID. A list of supported modes is returned in the Lucidworks AI Use Case API. For more information about supported models, see Generative AI models.
Common POST request parameters and fields
Some parameters in the/ai/async-prediction/USE_CASE/MODEL_ID POST request are common to all of the generative AI (Gen-AI) use cases, such as the modelConfig parameter.
Also referred to as hyperparameters, these fields set certain controls on the response.
Refer to the API spec for more information.
Unique values for the external documents RAG use case
Some parameter values available in theexternal documents RAG use case are unique to this use case, including values for the documents and useCaseConfig parameters.
Refer to the API spec for more information.
Example request
The following is an example request. This example does not include:modelConfigparameters, but you can submit requests that include parameters described in Common parameters and fields.useCaseConfigparameters, but you can submit requests that include parameters described in Unique values for the external documents RAG use case.
Example GET request
- Generated answer
SOURCESline of text that contains the URL of the documents used to generate the answer- Metadata about the response:
memoryUuidthat can be used to retrieve the LLM’s chat history- Count of tokens used to complete the query
useCaseConfig parameters in the request:
Example GET request
Unique values for the chat history RAG use case
Some parameter values available in theexternal documents RAG use case are unique to this use case, including values for the documents and useCaseConfig parameters.
Refer to the API spec for more information.
Example POST request using chat history
When using the RAG search, the LLM service stores the query and its response in a cache. In addition to the response, it also returns a UUID value in thememoryUuid field. If the UUID is passed back in a subsequent request, the LLM uses the cached query and response as part of its context. This lets the LLM be used as a chatbot, where previous queries and responses are used to generate the next response.
The following is an example request. This example does not include:
modelConfigparameters, but you can submit requests that include parameters described in the API spec.useCaseConfigparameters, but you can submit requests that include parameters described in Unique values for the chat history RAG use case.
Example GET request
Neural Hybrid Search process flow with Retrieval-Augmented Generation (RAG)
This diagram displays the process flow between neural hybrid search and RAG use cases.