When no training data exists to use the Supervised job, the cold start solution uses general pre-trained Deep Learning models or provides a possibility to train custom word embeddings for specific domains. Over time, we suggest capturing signals from document clicks, likes, and downloads. These signals can be used to construct training dataset. After cumulating at least 3000 pairs, that feedback can be used as training data for the Supervised solution. Like the Supervised solution, the Cold start solution has two parts:Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
1. Prepare a model
There are two ways to do this:- Smart Answers comes with two pre-trained cold-start models. These models can serve as a strong baseline if your data does not have too much domain-specific terms. See Set Up a Pre-Trained Cold Start Model for Smart Answers.
- You can train your own cold start model by configuring a job that analyzes your existing content. See Train a Smart Answers Cold Start Model.
Set Up a Pre-Trained Cold Start Model for Smart Answers
Set Up a Pre-Trained Cold Start Model for Smart Answers
Lucidworks provides these pre-trained cold start models for Smart Answers:
qna-coldstart-large- this is a large model trained on variety of corpuses and tasks.qna-coldstart-multilingual- covers 16 languages. List of supported languages: Arabic, Chinese-simplified, Chinese-traditional, English, French, German, Italian, Japanese, Korean, Dutch, Polish, Portuguese, Spanish, Thai, Turkish, Russian.
Deploy a pre-trained cold-start model into Fusion
The pre-trained cold-start models are deployed using a Fusion job called Create Seldon Core Model Deployment. This job downloads the selected pre-trained model and installs it in Fusion.- Navigate to Collections > Jobs.
- Select Add > Create Seldon Core Model Deployment.
- Enter a Job ID, such as
deploy-qna-coldstart-multilingualordeploy-qna-coldstart-large. - Enter the Model Name, one of the following:
qna-coldstart-multilingualqna-coldstart-large
- In the Docker Repository field, enter
lucidworks. - In the Image Name field, enter one of the following:
qna-coldstart-multilingual:v1.1qna-coldstart-large:v1.1
- Leave the Kubernetes Secret Name for Model Repo field empty.
- In the Output Column Names for Model field, enter one of the following:
qna-coldstart-multilingual:[vector]qna-coldstart-large:[vector, compressed_vector]
- Click Save.
- Click Run > Start to start the deployment job.
Next steps
Train a Smart Answers Cold Start Model
Train a Smart Answers Cold Start Model
The Smart Answers Cold Start Training job is deprecated in Fusion 5.12.
Configure the training job
- In Fusion, navigate to Collections > Jobs.
- Select Add > Smart Answer Coldstart Training.
-
In the Training Collection field, specify the collection that contains the content that can be used to answer questions.
You can also configure this job to read from or write to cloud storage.
- Enter the name of the Field which contains the content documents.
- Enter a Model Deployment Name. The new machine learning model will be saved in the blob store with this name. You will reference it later when you configure your pipelines.
-
Configure the Model base.
There are several pre-trained word and BPE embeddings for different languages, as well as a few pre-trained BERT models.
If you want to train custom embeddings, please select
word_customorbpe_custom. This trains Word2vec on the data and fields specified in Training collection and Field which contains the content documents. It might be useful in cases when your content includes unusual or domain-specific vocabulary. When you use the pre-trained embeddings, the log shows the percentage of processed vocabulary words. If this value is high, then try using custom embeddings. During the training job analyzes the content data to select weights for each of the words. The result model performs the weighted average of word embeddings to obtain final single dense vector for the content. -
Click Save.
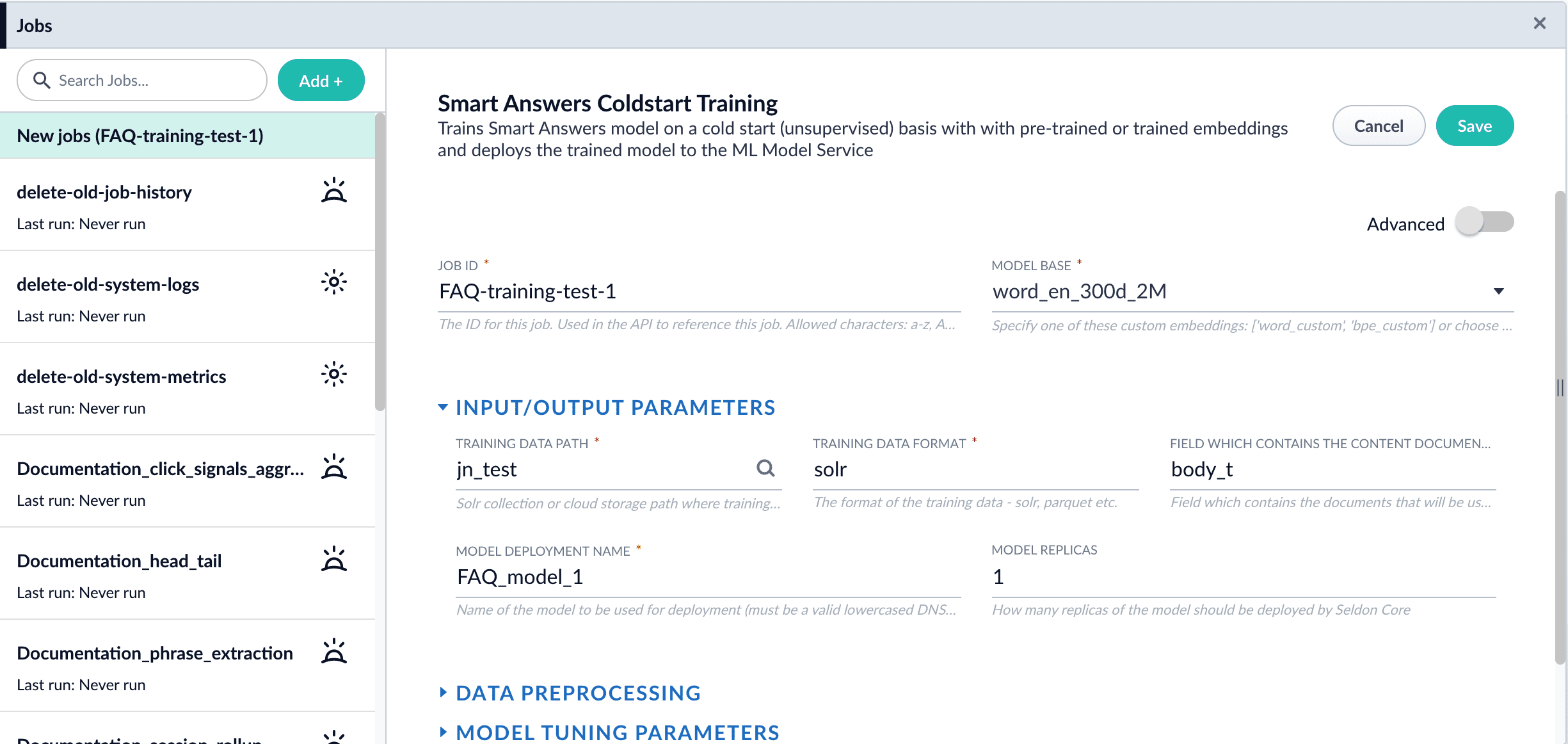 If using solr as the training data source ensure that the source collection contains the
If using solr as the training data source ensure that the source collection contains therandom_*dynamic field defined in itsmanaged-schema.xml. This field is required for sampling the data. If it is not present, add the following entry to themanaged-schema.xmlalongside other dynamic fields<dynamicField name="random_*" type="random"/>and<fieldType class="solr.RandomSortField" indexed="true" name="random"/>alongside other field types. - Click Run > Start.
Next steps
2. Create collections in Milvus
In order to use{app_name}-smart-answers pipelines, you need to create collections in Milvus. Please refer to the Milvus documentation page.
3. Configure the pipelines
The trained model should be used at both index and query time in order to perform dense vector search.- At index time, we provide the
{app_name}-smart-answersindex pipeline to help generate a dense vector representation of answers. - At query time, we provide a
{app_name}-smart-answersquery pipeline to conduct run-time neural search. This pipeline transforms the incoming query into a dense vector using the trained model, then compares it with indexed answer dense vectors by computing the cosine distance between them. You can also use a query stage to combine Solr and document vector similarity scores at query time.
Configure the Smart Answers Pipelines
Configure the Smart Answers Pipelines
Before beginning this procedure, train a machine learning model using either the FAQ method or the cold start method.Regardless of how you set up your model, the deployment procedure is the same: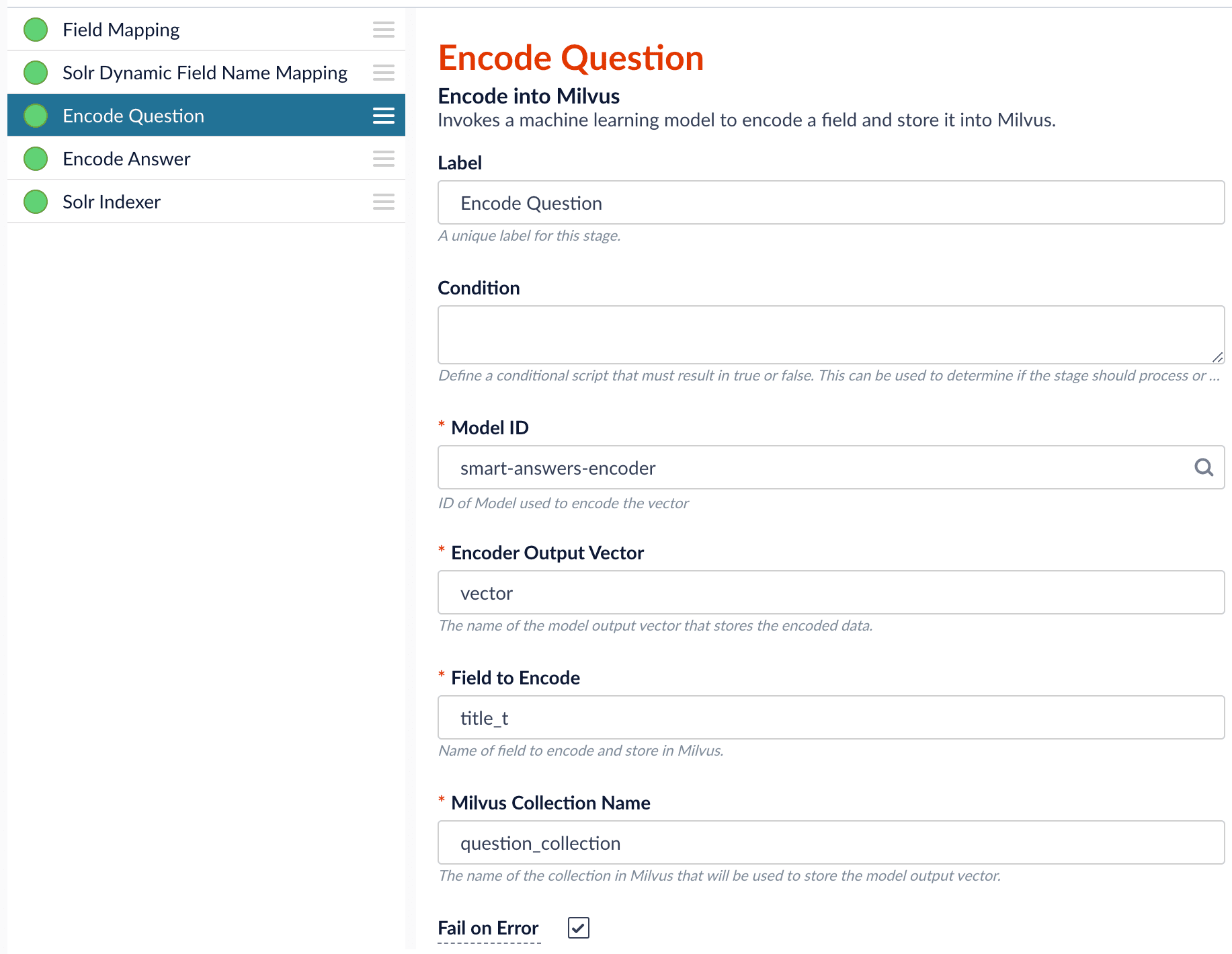

- Create the
Milvuscollection. - Configure the
smart-answersindex pipeline. - Configure the
smart-answersquery pipeline.
Create the Milvus collection
For complete details about job configuration options, see the Create Collections in Milvus job.- Navigate to Collections > Jobs > Add + and select Create Collections in Milvus.
-
Configure the job:
- Enter an ID for this job.
- Under Collections, click Add.
- Enter a collection name.
- In the Dimension field, enter the dimension size of vectors to store in this Milvus collection. The Dimension should match the size of the vectors returned by the encoding model. For example, the
Smart Answers Pre-trained Coldstartmodels outputs vectors of 512 dimension size. Dimensionality of encoders trained bySmart Answers Supervised Trainingjob depends on the provided parameters and printed in the training job logs.
-
Click Save.
The
Create Collections in Milvusjob can be used to create multiple collections at once. In this image, the first collection is used in the indexing and query steps. The other two collections are used in the example.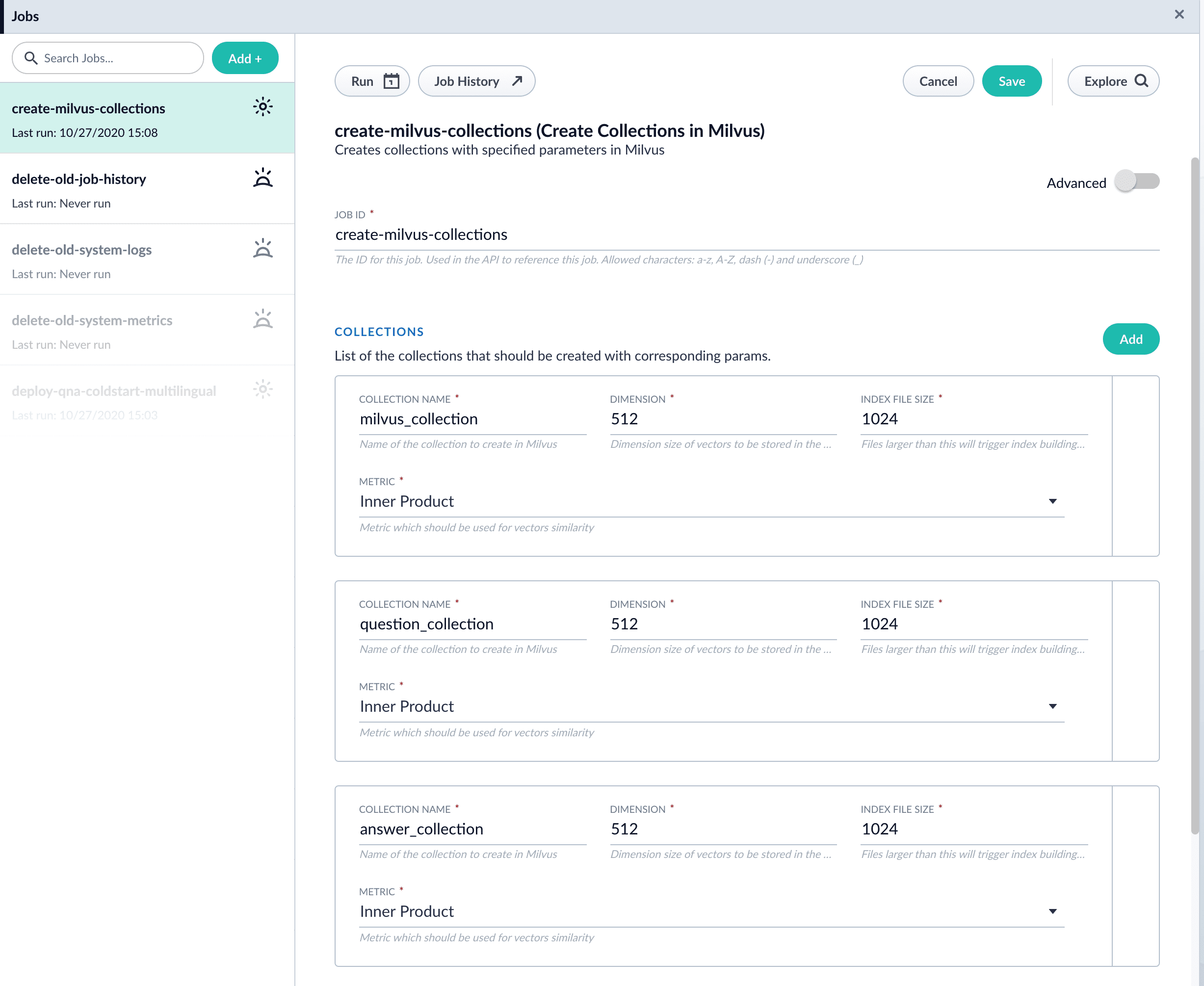
- Click Run > Start to run the job.
Configure the index pipeline
- Open the Index Workbench.
-
Load or create your datasource using the default smart-answers index pipeline.
-
Configure the
Encode into Milvus stage:
- change the value of Model ID to match the model deployment name you chose when you configured the model training job.
-
Change
Field to Encodeto the document field name to be processed and encoded into dense vectors. -
Ensure the
Encoder Output Vectormatches the output vector from the chosen model. -
Ensure the
Milvus Collection Namematches the collection name created via theCreate Milvus Collectionjob.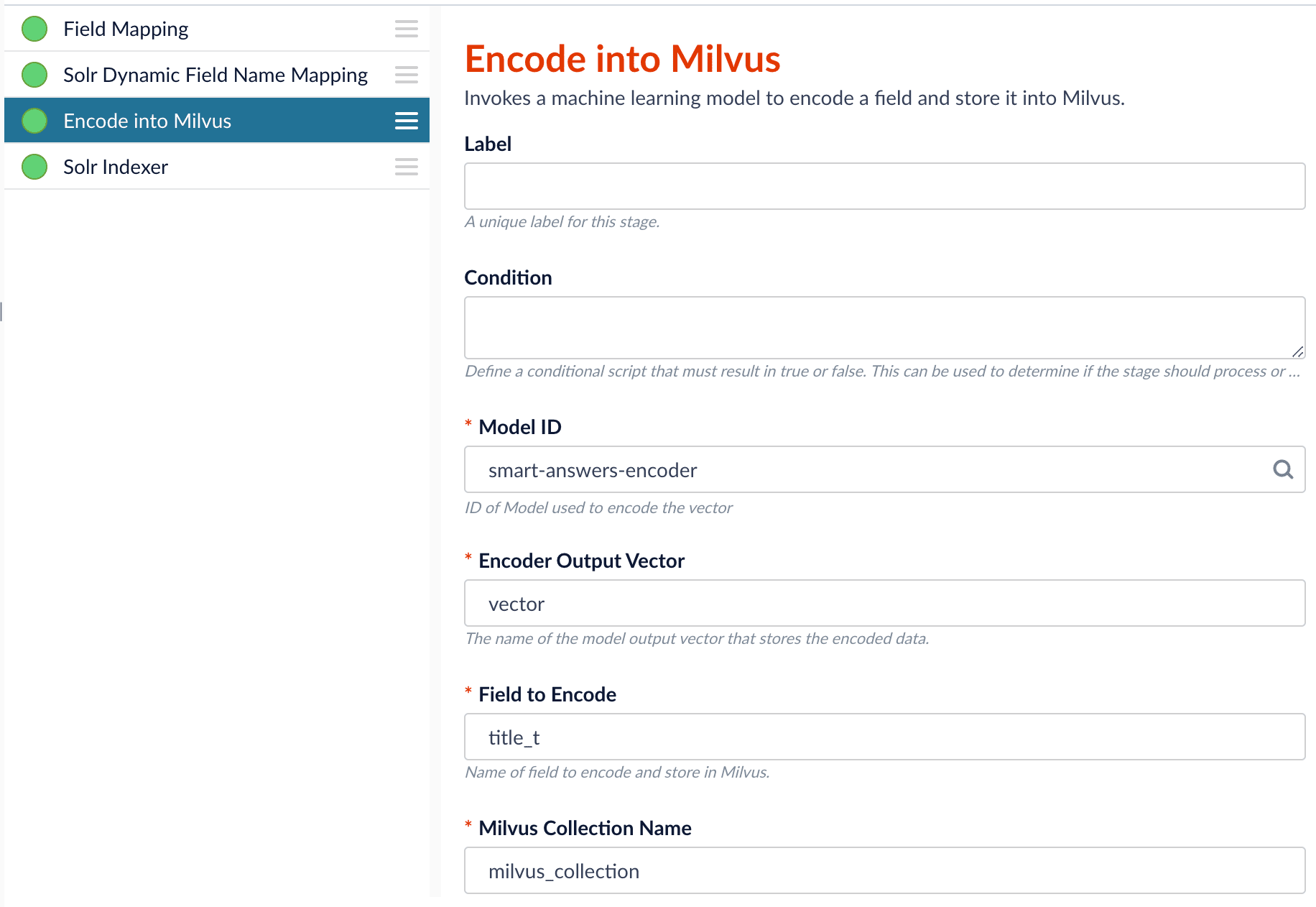
- Save the datasource.
- Index your data.
Configure the query pipeline
- Open the Query Workbench.
-
Load the default smart-answers query pipeline.
-
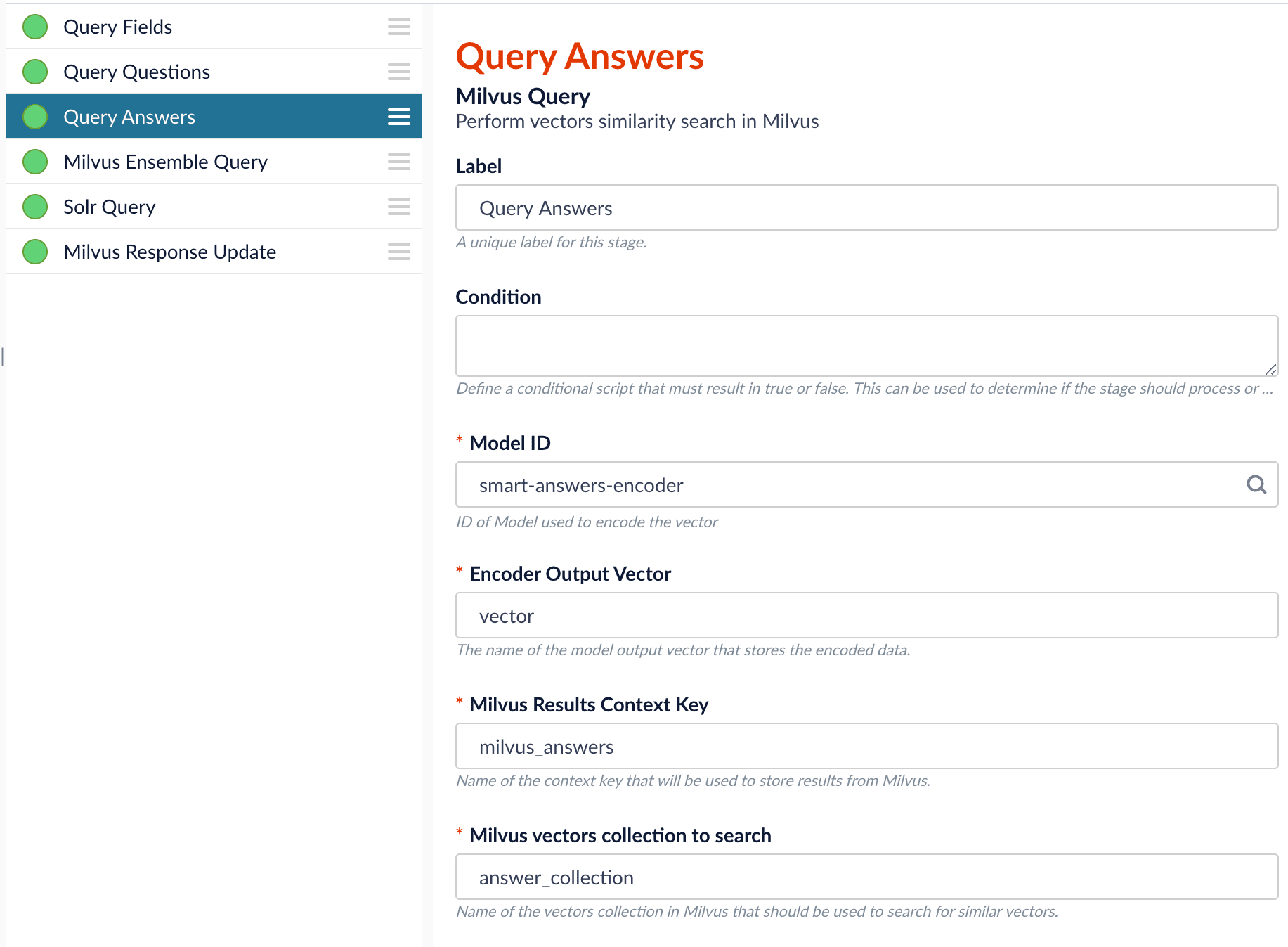
Configure the Milvus Query stage:
- Change the Model ID value to match the model deployment name you chose when you configured the model training job.
-
Ensure the
Encoder Output Vectormatches the output vector from the chosen model. -
Ensure the
Milvus Collection Namematches the collection name created via theCreate Milvus Collectionjob. -
Milvus Results Context Keycan be changed as needed. It will be used in the Milvus Ensemble Query Stage to calculate the query score.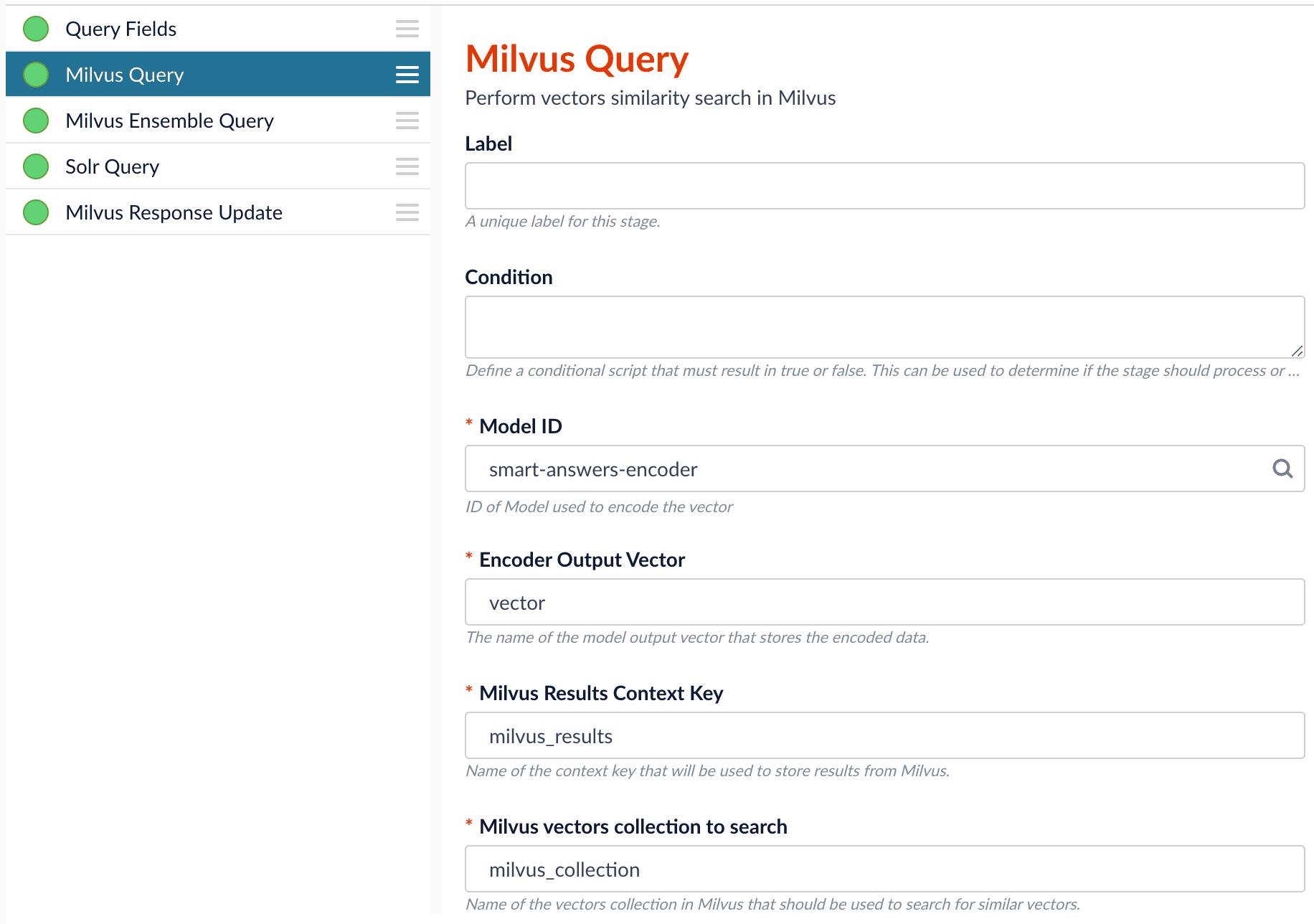
-
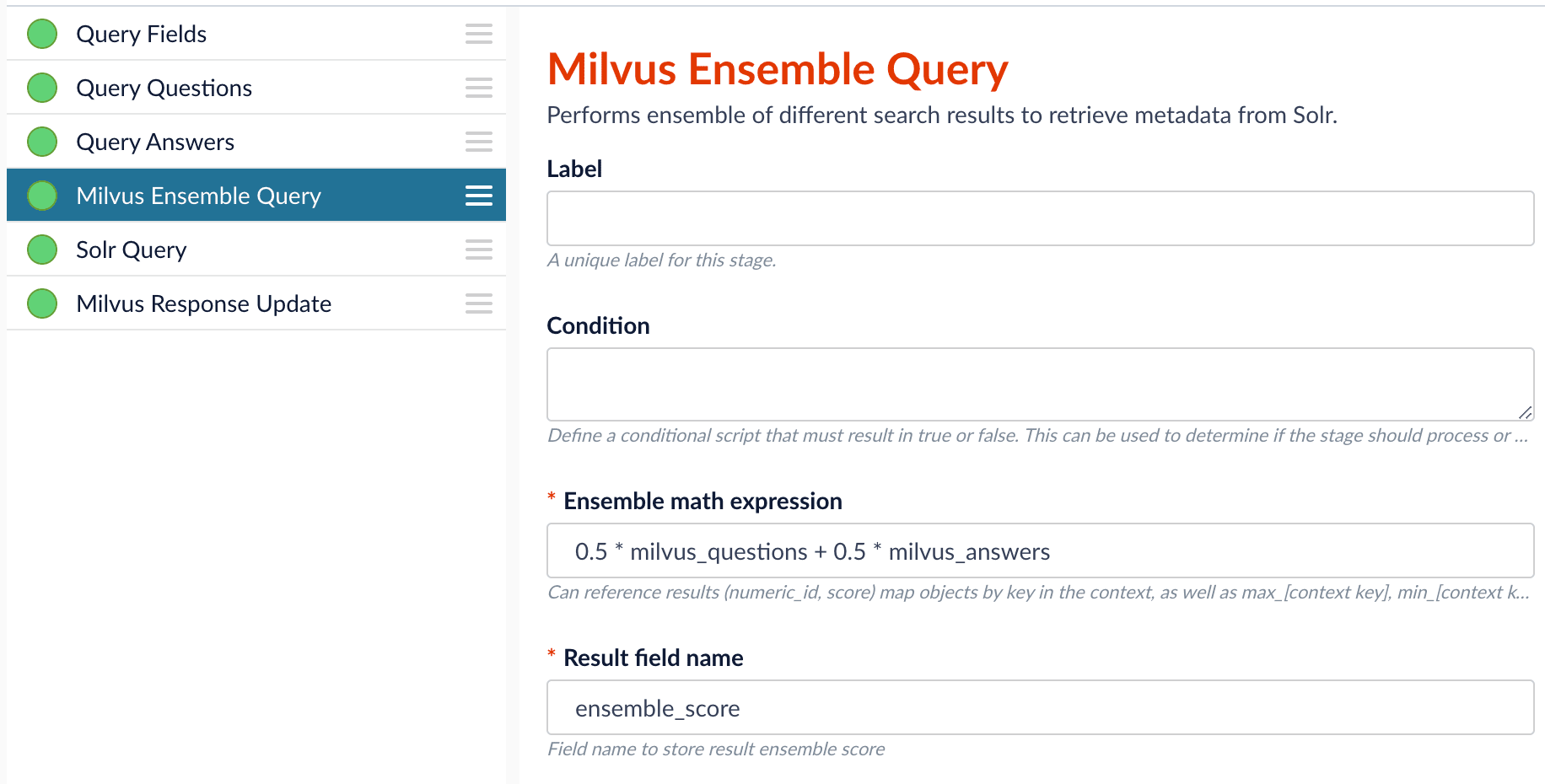
In the Milvus Ensemble Query stage, update the
Ensemble math expressionas needed based on your model and the name used in the prior stage for the storing the Milvus results. In versions 5.4 and later, you can also set theThresholdso that the Milvus Ensemble Query Stage will only return items with a score greater than or equal to the configured value.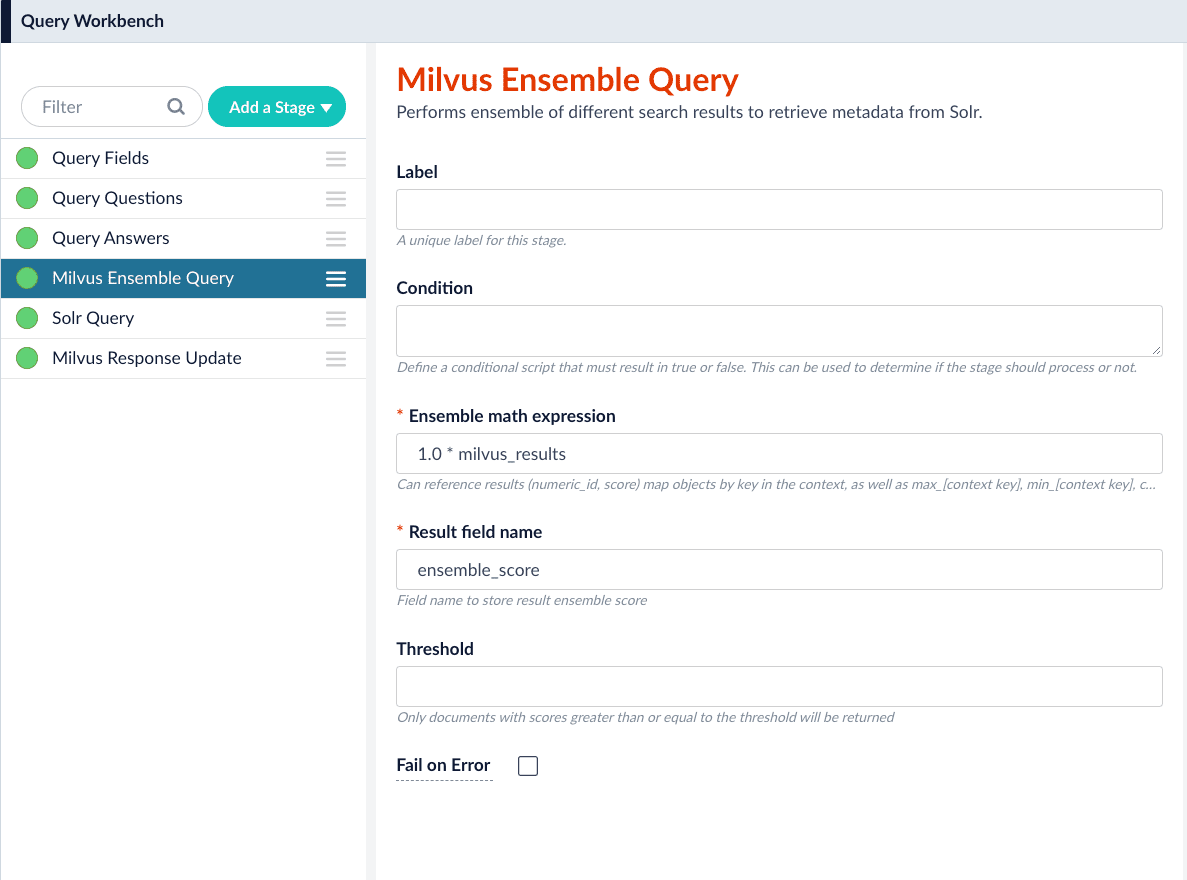
- Save the query pipeline.
Pipeline Setup Example
Index and retrieve the question and answer together
To show question and answer together in one document (that is, treat the question as the title and the answer as the description), you can index them together in the same document. You can still use the defaultsmart-answers index and query pipelines with a few additional changes.Prior to configuring the Smart Answers pipelines, use the Create Milvus Collection job to create two collections, question_collection and answer_collection, to store the encoded “questions” and the encoded “answers”, respectively.Index Pipeline
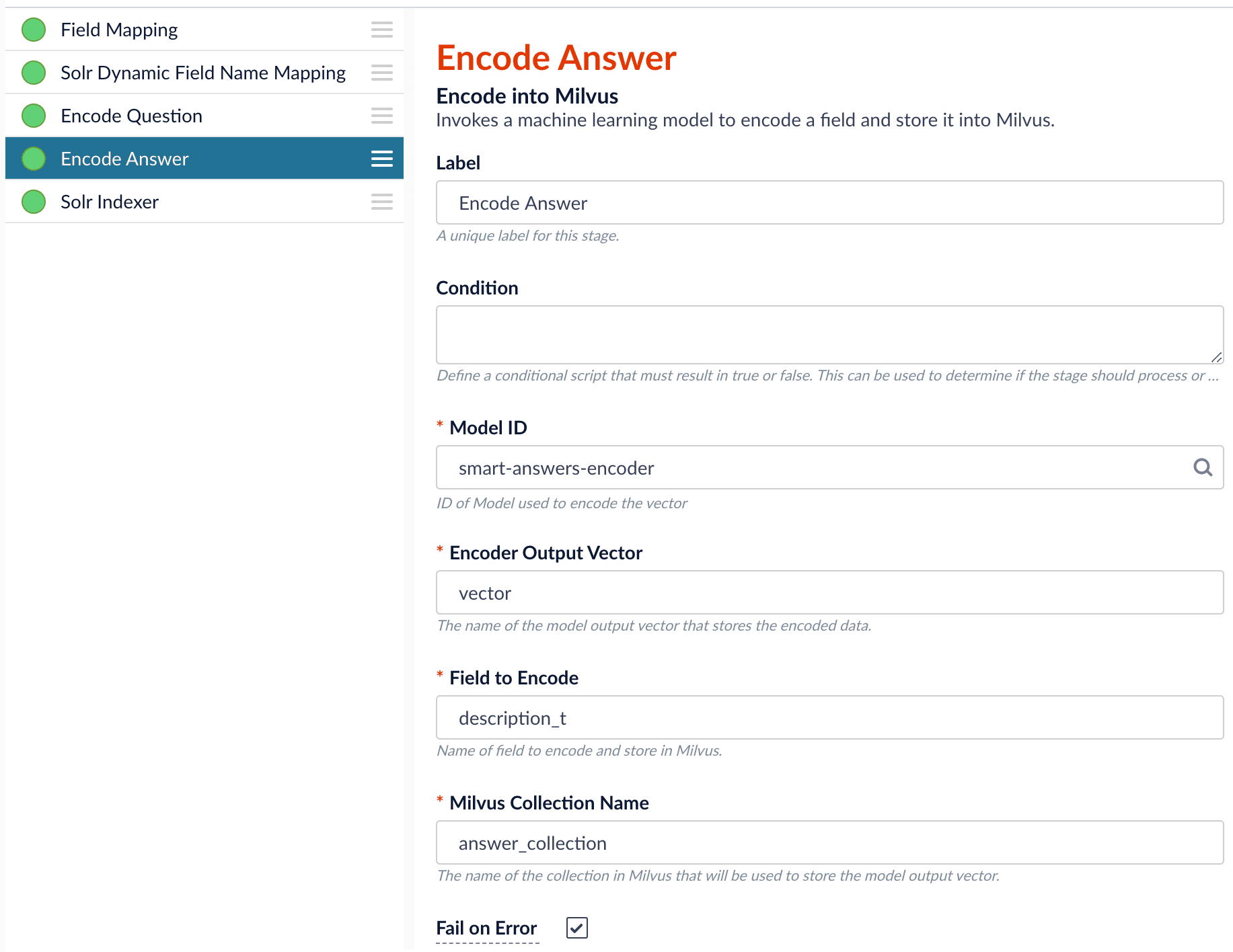
As shown in the pictures below, you will need two Encode into Milvus stages, named Encode Question and Encode Answer respectively.Encode Question (Encode Into Milvus) stageField to Encode to be title_t and change the Milvus Collection Name to match the new Milvus collection, question_collection.In the Encode Answer stage, specify Field to Encode to be description_t and change the Milvus Collection Name to match the new Milvus collection, answer_collection.Query Pipeline
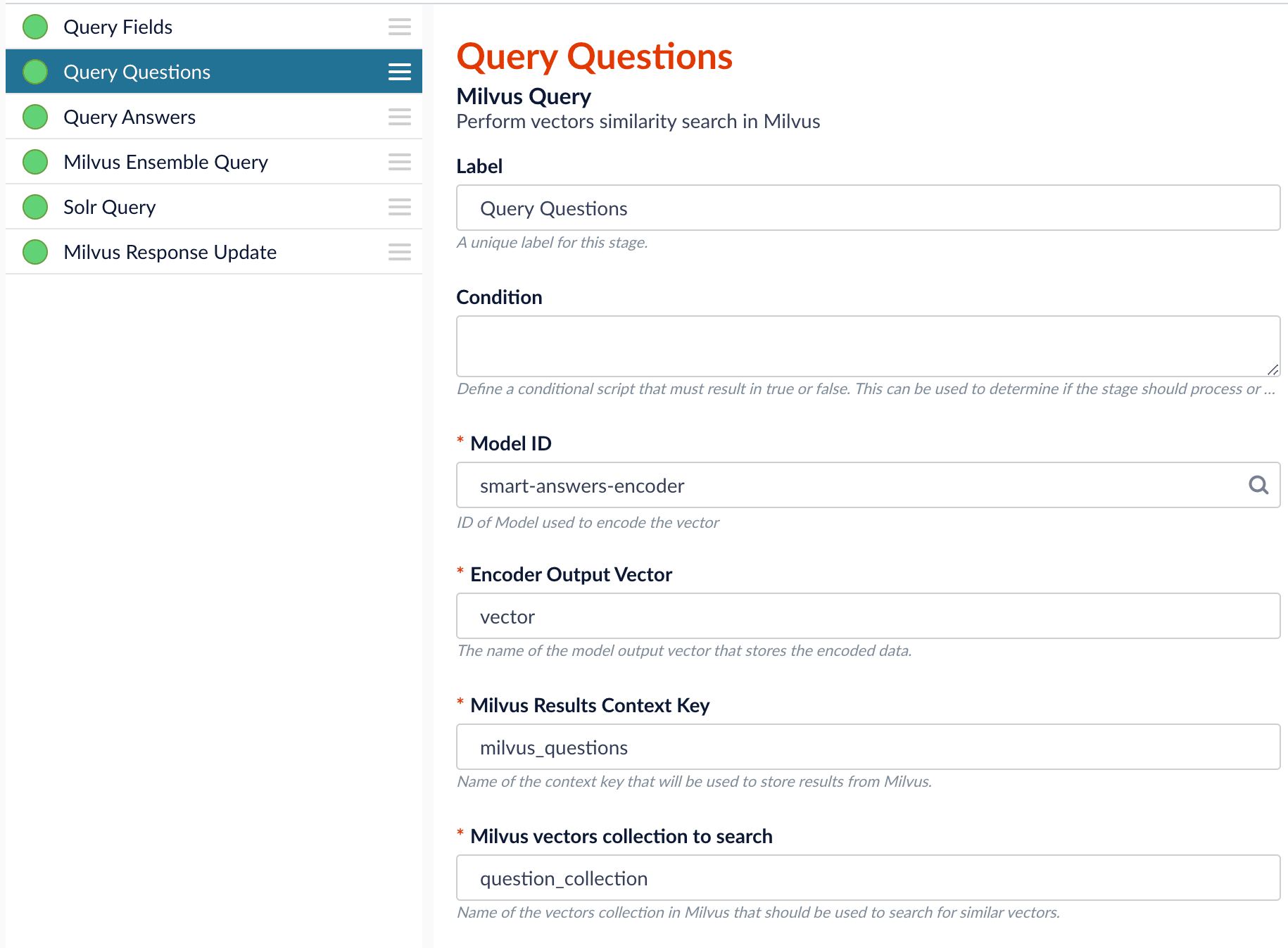
Since we have two dense vectors generated during indexing, at query time we need to compute both query to question distance and query to answer distance. This can be set up as the pictures shown below with two Milvus Query Stages, one for each of the two Milvus collections. To store those two distances separately, theMilvus Results Context Key needs to be different in each of these two stages.In the Query Questions stage, we set the Milvus Results Context Key to milvus_questions and the Milvus collection name to question_collection.Query Questions (Milvus Query) stage:Milvus Results Context Key to milvus_answers and the Milvus collection name to answer_collection.Query Answers (Milvus Query) stage:Ensemble math expression combining the results from the two query stages. If we want the question scores and answer scores weighted equally, we would use: 0.5 * milvus_questions + 0.5 * milvus_answers.
This is recommended especially when you have limited FAQ dataset and want to utilize both question and answer information.Milvus Ensemble Query stageEvaluate the query pipeline
The Evaluate QnA Pipeline job evaluates the rankings of results from any Smart Answers pipeline and finds the best set of weights in the ensemble score.Detailed pipeline setup
Typically, you can use the default pipelines included with Fusion AI. These pipelines now utilize Milvus to store encoded vectors and to calculate vector similarity. This topic provides information you can use to customize the Smart Answers pipelines.| ”smart-answers” index pipeline | | Encode into Milvus stage |
| ”smart-answers” query pipeline | |
Create the Milvus collection
Prior to indexing data, the Create Collections in Milvus job can be used to create the Milvus collection(s) used by the Smart Answers pipelines (see Milvus overview).Job ID. A unique identifier for the job.Collection Name. A name for the Milvus collection you are creating. This name is used in both the Smart Answer Index and the Smart Answer Query pipelines.Dimension. The dimension size of the vectors to store in this Milvus collection. The Dimension should match the size of the vectors returned by the encryption model. For example, if the model was created with either theSmart Answers Coldstart Trainingjob or theSmart Answers Supervised Trainingjob with the Model Baseword_en_300d_2M, then the dimension would be 300.Index file size. Files with more documents than this will cause Milvus to build an index on this collection.Metric. The type of metric used to calculate vector similarity scores.Inner Productis recommended. It produces values between 0 and 1, where a higher value means higher similarity.
Index pipeline setup
Stages in the default “smart-answers” index pipelineThe Encode into Milvus Index Stage
The Encode into Milvus index stage uses the specified model to encode theField to Encode and store it in Milvus in the given Milvus collection.
There are several required parameters:Model ID. The ID of the model.Encoder Output Vector. The name of the field that stores the compressed dense vectors output from the model. Default value:vector.Field to Encode. The text field to encode into a dense vector, such asanswer_torbody_t.Milvus Collection Name. The name of the collection you created via the Create Milvus Collection job, which will store the dense vectors. When creating the collection you specify the type of Metric to use to calculate vector similarity. This stage can be used multiple times to encode additional fields, each into a different Milvus collection.
Query pipeline setup
The Query Fields stage
The first stage is Query Fields. For more information see the Query Fields stage.The Milvus Query stage
The Milvus Query stage encodes the query into a vector using the specified model. It then performs a vector similarity search against the specified Milvus collection and returns a list of the best document matches.Model ID. The ID of the model used when configuring the model training job.Encoder Output Vector. The name of the output vector from the specified model, which will contain the query encoded as a vector. Defaults to vector.Milvus Collection Name. The name of the collection that you used in theEncode into Milvusindex stage to store the encoded vectors.Milvus Results Context Key. The name of the variable used to store the vector distances. It can be changed as needed. It will be used in the Milvus Ensemble Query Stage to calculate the query score for the document.Number of Results. The number of highest scoring results returned from Milvus. This stage would typically be used the same number of times that theEncode into Milvusindex stage is used, each with a different Milvus collection and a differentMilvus Results Context Key.
The Milvus Ensemble Query stage
The Milvus Ensemble Query takes the results of the Milvus Query stage(s) and calculates theensemble score, which is used to return the best matches.Ensemble math expression. The mathematical expression used to calculate theensemble score. It should reference the value(s) variable name specified in theMilvus Results Context Keyparameter in the Milvus Query stage.Result field name. The name of the field used to store theensemble score. It defaults toensemble_score.Threshold- A parameter that filters the stage results to remove items that fall below the configured score. Items with a score at, or above, the threshold will be returned.
The Threshold feature is only available in Fusion 5.4 and later.
The Milvus Response Update Query stage
The Milvus Response Update Query stage does not need to be configured and can be skipped if desired. It inserts the Milvus values, including theensemble_score, into each of the returned documents, which is particularly useful when there is more than one Milvus Query Stage. This stage needs to come after the Solr Query stage.Short answer extraction
By default, the question-answering query pipelines return complete documents that answer questions. Optionally, you can extract just a paragraph, a sentence, or a few words that answer the question.Evaluate a Smart Answers Query Pipeline
Evaluate a Smart Answers Query Pipeline
The Smart Answers Evaluate Pipeline job evaluates the rankings of results from any Smart Answers pipeline and finds the best set of weights in the ensemble score. This topic explains how to set up the job.Before beginning this procedure, prepare a machine learning model using either the Supervised method or the Cold start method, or by selecting one of the pre-trained cold start models, then Configure your pipelines.The input for this job is a set of test queries and the text or ID of the correct responses. At least 100 entries are needed to obtain useful results. The job compares the test data with Fusion’s actual results and computes variety of the ranking metrics to provide insights of how well the pipeline works. It is also useful to use to compare with other setups or pipelines.

Prepare test data
-
Format your test data as query/response pairs, that is, a query and its corresponding answer in each row.
You can do this in any format that Fusion support, but parquet file would be preferable to reduce the amount of possible encoding issues.
The response value can be either the document ID of the correct answer in your Fusion index (preferable), or the text of the correct answer.
If there are multiple possible answers for a unique question, then repeat the questions and put the pair into different rows to make sure each row has exactly one query and one response.If you use answer text instead of an ID, make sure that the answer text in the evaluation file is formatted identically to the answer text in Fusion.
-
If you wish to index test data into Fusion, create a collection for your test data, such as
sa_test_inputand index the test data into that collection.
Configure the evaluation job
-
If you wish to save the job output in Fusion, create a collection for your evaluation data such as
sa_test_output. - Navigate to Collections > Jobs.
- Select New > Smart Answers Evaluate Pipeline (Evaluate QnA Pipeline in Fusion 5.1 and 5.2).
-
Enter a Job ID, such as
sa-pipeline-evaluator. -
Enter the name of your test data collection (such as
sa_test_input) in the Input Evaluation Collection field. -
Enter the name of your output collection (such as
sa_test_output) in the Output Evaluation Collection field.You can also configure this job to read from or write to cloud storage. - Enter the name of the Test Question Field in the input collection.
- Enter the name of the answer field as the Ground Truth Field.
- Enter the App Name of the Fusion app where the main Smart Answers content is indexed.
- In the Main Collection field, enter the name of the Fusion collection that contains your Smart Answers content.
- In the Fusion Query Pipeline field, enter the name of the Smart Answers query pipeline you want to evaluate.
- In the Answer Or ID Field In Fusion field, enter the name of the field that Fusion will return containing the answer text or answer ID.
- Optionally, you can configure the Return Fields to pass from Smart Answers collection into the evaluation output.
- Configure the Metrics parameters:
-
Solr Scale Function
Specify the function used in the Compute Mathematical Expression stage of the query pipeline, one of the following:
maxlog10pow0.5
- List of Ranking Scores For Ensemble To find the best weights for different ranking scores, list the names of the ranking score fields, separated by commas. Different ranking scores might include Solr score, query-to-question distance, or query-to-answer distance from the Compute Mathematical Expression pipeline stage.
-
Target Metric To Use For Weight Selection
The target ranking metric to optimize during weights selection. The default is
mrr@3.
- Optionally, read about the advanced parameters and consider whether to configure them as well.
- Click Save.
Examine the output
The job provides a variety of metrics (controlled by the Metrics list advanced parameter) at different positions (controlled by the Metrics@k list advanced parameter) for the chosen final ranking score (specified in Ranking score parameter).Example: Pipeline evaluation metrics