Train a Smart Answers Cold Start Model
| The Smart Answers Cold Start Training job is deprecated in Fusion 5.12. |
The cold start solution for Smart Answers begins with training a model using your existing content. To do this, you run the Smart Answers Coldstart Training job (QnA Coldstart Training job in Fusion 5.1 and 5.2). This job uses variety of word embeddings, including custom via Word2Vec training, to learn about the vocabulary that you want to search against.
| Smart Answers comes with two pre-trained cold-start models. If your data does not have many domain-specific words, then consider using a pre-trained model. |
During a cold start, we suggest capturing user feedback such as document clicks, likes, and downloads on the Web site (App Studio can help you get started). After accumulating feedback data and at least 3,000 query/response pairs, the feedback can be used to train a model using the Supervised method.
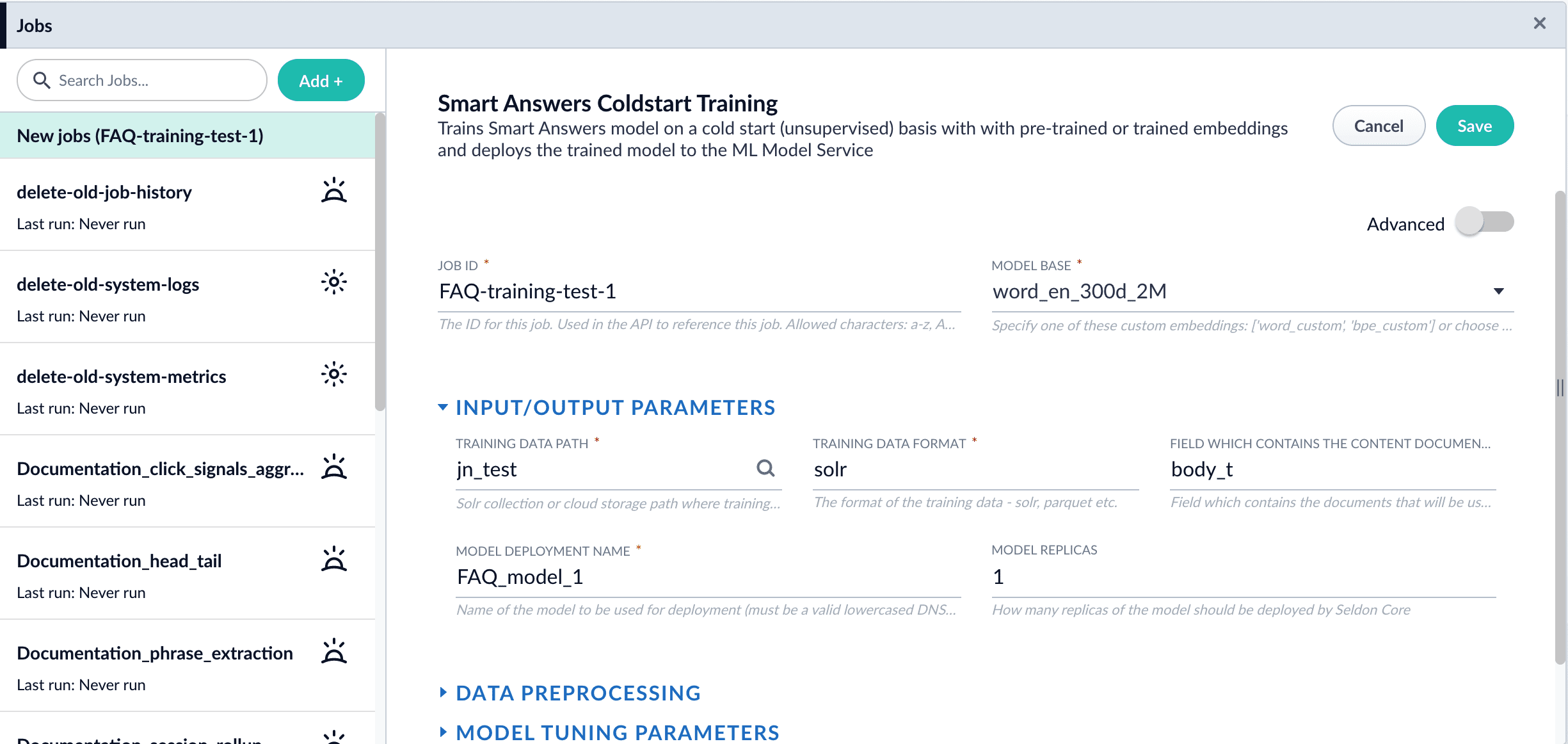
Configure the training job
-
In Fusion, navigate to Collections > Jobs.
-
Select Add > Smart Answer Coldstart Training.
-
In the Training Collection field, specify the collection that contains the content that can be used to answer questions.
In Fusion 5.3 and later, you can also configure this job to read from or write to cloud storage. See Configure An Argo-Based Job to Access GCS and Configure An Argo-Based Job to Access S3. -
Enter the name of the Field which contains the content documents.
-
Enter a Model Deployment Name.
The new machine learning model will be saved in the blob store with this name. You will reference it later when you configure your pipelines.
-
Fusion 5.3 and later: Configure the Model base.
There are several pre-trained word and BPE embeddings for different languages, as well as a few pre-trained BERT models.
If you want to train custom embeddings, please select
word_customorbpe_custom. This trains Word2vec on the data and fields specified in Training collection and Field which contains the content documents. It might be useful in cases when your content includes unusual or domain-specific vocabulary.When you use the pre-trained embeddings, the log shows the percentage of processed vocabulary words. If this value is high, then try using custom embeddings.
During the training job analyzes the content data to select weights for each of the words. The result model performs the weighted average of word embeddings to obtain final single dense vector for the content.
-
Click Save.
If using solr as the training data source ensure that the source collection contains the random_*dynamic field defined in its managed-schema. This field is required for sampling the data. If it is not present, add the following entry to the managed-schema alongside other dynamic fields<dynamicField name="random_*" type="random"/>and <fieldType class="solr.RandomSortField" indexed="true" name="random"/> alongside other field types. -
Click Run > Start.
After training is finished the model is deployed into the cluster and can be used in index and query pipelines.