Use this job to generate pairs of synonyms and pairs of similar queries. Two words are considered potential synonyms when they are used in a similar context in similar queries.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
This job is deprecated in Fusion 5.9.15 and will be removed in a future release.
Lucidworks recommends migrating to Neural Hybrid Search, which achieves superior relevance compared to legacy machine learning methods.
Resolving Underperforming Queries
The course for Resolving Underperforming Queries focuses on tips for tuning, running, and cleaning up Fusion’s query rewrite jobs.
| Default job name | COLLECTION_NAME_synonym_detection |
| Input | ● Aggregated signals (the COLLECTION_NAME_signals_aggr collection by default)● Spell Correction job output (the COLLECTION_NAME_query_rewrite_staging collection by default)● Phrase Extraction job output (the COLLECTION_NAME_query_rewrite_staging collection by default) |
| Output | Synonyms (the COLLECTION_NAME_query_rewrite_staging collection by default) |
| query | count_i | type | timestamp_tdt | user_id | doc_id | session_id | fusion_query_id | |
|---|---|---|---|---|---|---|---|---|
| Required signals fields: | ✅ | ✅ | ✅ | ✅ |
For best job speed and to avoid memory issues, use aggregated signals instead of raw signals as input for this job.
- Review, edit, deploy, or delete output from this job, see Query Rewriting UI
- Review, edit, or add synonyms, see Use Synonym Detection
Use Synonym Detection
Use Synonym Detection
Based on the release, synonyms are automatically created based on your AI-generated data. When you navigate to Relevance > Rules > Rewrite and select the Synonym tab, the application displays the Synonym Detection screen. For more information, see: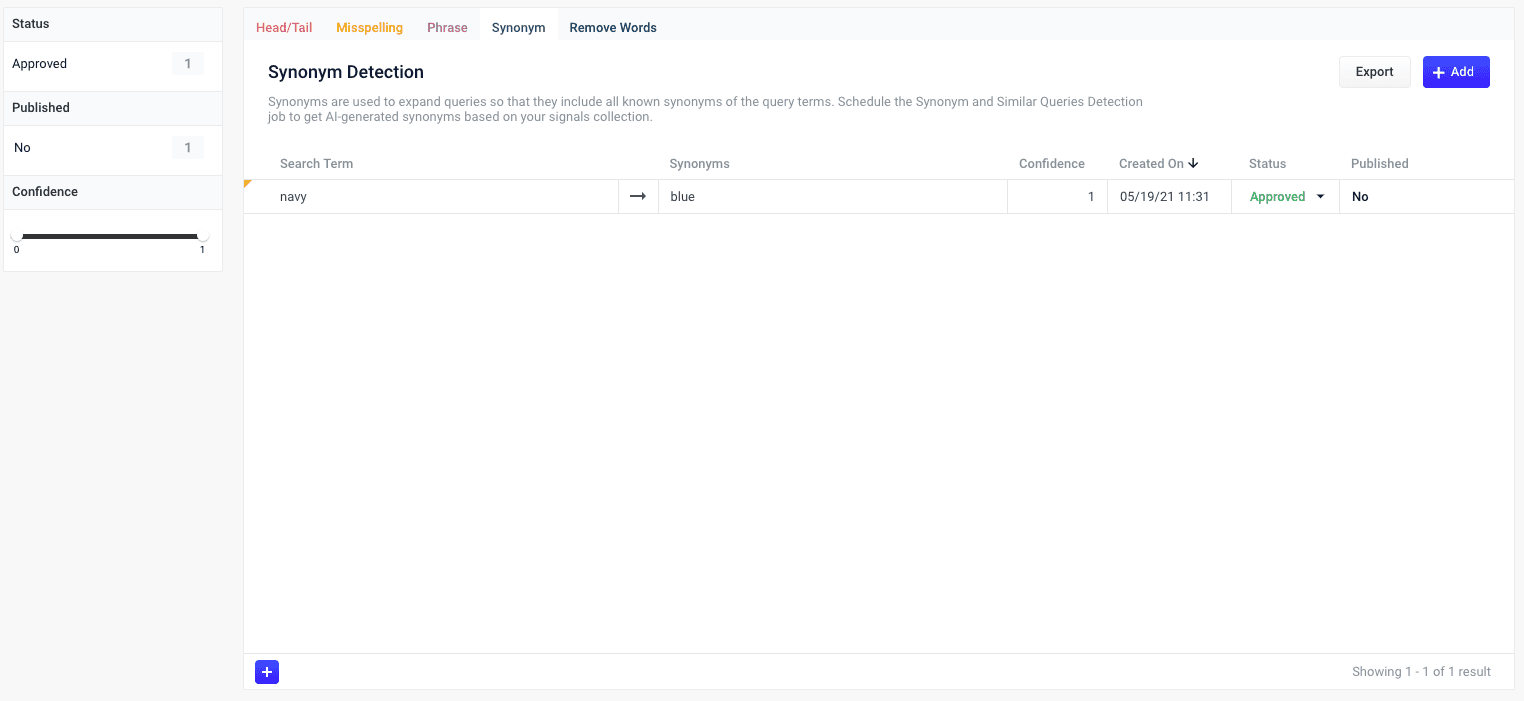
Query Analytics
The course for Query Analytics focuses on how Fusion provides query analytics to detect and improve underperforming queries.
Reviewing auto-generated synonym pairs
Synonyms that are automatically generated by the Fusion 5.2.x and later Synonym Detection job are assigned the following status value:-
Pending
The confidence level is ambiguous, and the result must be reviewed by a user before it can be deployed. It will only be moved from the
_query_rewrite_stagingcollection to the_query_rewritecollection when its status has changed to “Approved” and it has been published.By default, all results from a synonym job are set to “Pending”, since there are usually a limited number of synonyms, and synonym expansion can have high impact on relevancy.
How to review a pending synonym pair result
- Navigate to Relevance > Rules > Rewrite.
- Select Synonym tab. The application displays the Synonym Detection screen.
- Click the icon next to the synonym pair.
- In the Status column, select either “Approved” or “Denied”. Where alternative synonyms were detected, you can click Suggestions to view and select them as replacements for the displayed synonym pair.
-
Click the Close icon next to the updated synonym pair:
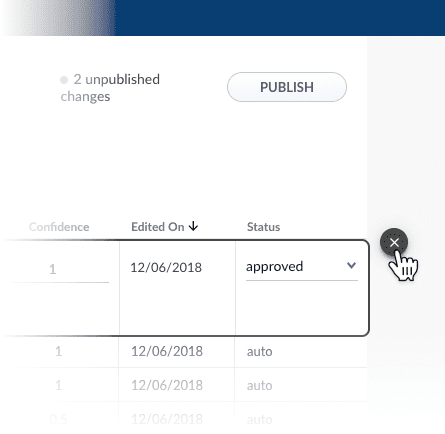
Approving a synonym pair does not automatically deploy it to the
_query_rewrite collection. When you have finished your review, you must click Publish to deploy your changes.Adding new synonym pairs
You can manually add synonym pairs in addition to any generated by your Fusion release:How to add a synonym pair
- Navigate to Relevance > Rules > Rewrite.
- Select Synonym tab. The application displays the Synonym Detection screen.
- At the bottom of the rules list, click the icon. A new synonym pair appears at the top of the list.
- Enter the query term.
- Select the synonym pair’s status, depending on whether you want to deploy it the next time you publish your changes (“Approved”) or save it for further review (“Pending”).
- Click the check mark to save the new synonym pair.
Publishing your changes
How to publish updated synonym pairs
- In the Synonym Detection screen, click the PUBLISH button. Fusion prompts you to confirm that you want to publish your changes.
- Click PUBLISH.
Input
This job takes one or more of the following as input:- Signal data (required)
- Misspelling job results
- Phrase detection job results
- Keywords
- Custom synonyms
Signal data
This input is required; additional input is optional. Signal data can be either raw or aggregated. The job runs faster using aggregated signals. When raw signals are used as input, this job performs the aggregation. Use thetrainingCollection/Input Collection parameter to specify the collection that contains the signal data.
Misspelling job results
Token and Phrase Spell Correction job results can be used to avoid finding mainly misspellings, or mixing synonyms with misspellings. Use themisspellingCollection/Misspelling Job Result Collection parameter to specify the collection that contains these results.
Phrase detection job results
Phrase Extraction job results can be used to find synonyms with multiple tokens, such as “lithium ion” and “ion battery”. Use thekeyPhraseCollection/Phrase Extraction Job Result Collection parameter to specify the collection that contains these results.
Keywords
A keywords list in the blob store can serve as a blacklist to prevent common attributes from being identified as potential synonyms. The list can include common attributes such as color, brand, material, and so on. For example, by including color attributes you can prevent “red” and “blue” from being identified as synonyms due to their appearance in similar queries such as “red bike” and “blue bike”. The keywords file is in CSV format with two fields:keyword and type. You can add your custom keywords list here with the type value “stopwords”. An example file is shown below:
keywordsBlobName/Keywords Blob Store parameter to specify the name of the blob that contains this list.
Custom Synonyms
For some deployments, there might be a need to use existing synonym definitions. You can import existing synonyms into the Synonym Detection Jobs as a text file. Upload your synonyms text file to the blob store and reference that file when creating the job.Output
The output collection contains two tables distinguished by thedoc_type field.
The similar queries table
Ifquery leads to clicks on documents 1, 2, 3, and 4, and similar_query leads to clicks on documents 2, 3, 4, and 5, then there is sufficient overlap between the two queries to consider them similar.
A statistic is constructed to compute similarities based on overlap counts and query counts. The resulting table consists of documents whose doc_type value is “query_rewrite” and type value is “simq”.
The similar queries table contains similar query pairs with these fields:
query | The first half of the two-query pair. |
similar_query | The second half of the two-query pair. |
similarity | A score between 0 and 1 indicating how similar the two queries are. All similarity values are greater than or equal to the configured Query Similarity Threshold to ensure that only high-similarity queries are kept and used as input to find synonyms. |
query_count | The number of clicks received by the query_count query. To save computation time, only queries with at least as many clicks as the configured Query Clicks Threshold parameter are kept and used as input to find synonyms. |
similar_query_count | The number of clicks received by the similar_query_count query. |
The synonyms table
The synonyms table consists of documents whosedoc_type value is “query_rewrite” and type value is “synonym”:
surface_form | The first half of the two-synonym pair. |
synonym | The second half of the two-synonym pair. |
context | If there are more than two words or phrases with the same meaning, such as “macbook, apple mac, mac”, then this field shows the group to which this pair belongs. |
similarity | A similarity score to measure confidence. |
count | The number of different contexts in which this synonym pair appears. |
suggestion | The algorithm automatically selects context, synonym words or phrases, or the synonym_group, and puts it in this field. |
category | Whether the synonym is actually a misspelling. |