Fusion 5.12.0
Released on March 28, 2024, this rapid release includes several new features, including the asynchronous parsing service and the JSON viewer, as well as key improvements to the datasource job history.
To learn more, skip to the release notes.
Platform Support and Component Versions
Kubernetes platform support
Lucidworks has tested and validated support for the following Kubernetes platforms and versions:
-
Google Kubernetes Engine (GKE): 1.28, 1.27, and 1.26
-
Microsoft Azure Kubernetes Service (AKS): 1.28, 1.27, and 1.26
-
Amazon Elastic Kubernetes Service (EKS): 1.28, 1.27, and 1.26
Support is also offered for Rancher Kubernetes Engine (RKE) and OpenShift 4 versions that are based on Kubernetes 1.28, 1.27, and 1.26. OpenStack and customized Kubernetes installations are not supported.
For more information on Kubernetes version support, see the Kubernetes support policy.
Component versions
The following table details the versions of key components that may be critical to deployments and upgrades.
| Component | Version |
|---|---|
Solr |
fusion-solr 5.12.0 |
ZooKeeper |
3.9.0 |
Spark |
3.4.1 |
Ingress Controllers |
Nginx, Ambassador (Envoy), and GKE Ingress Controller. Istio is not supported. |
For additional component information, see Docker Images by Fusion Version.
New Features
Fusion
JSON viewer for Fusion objects
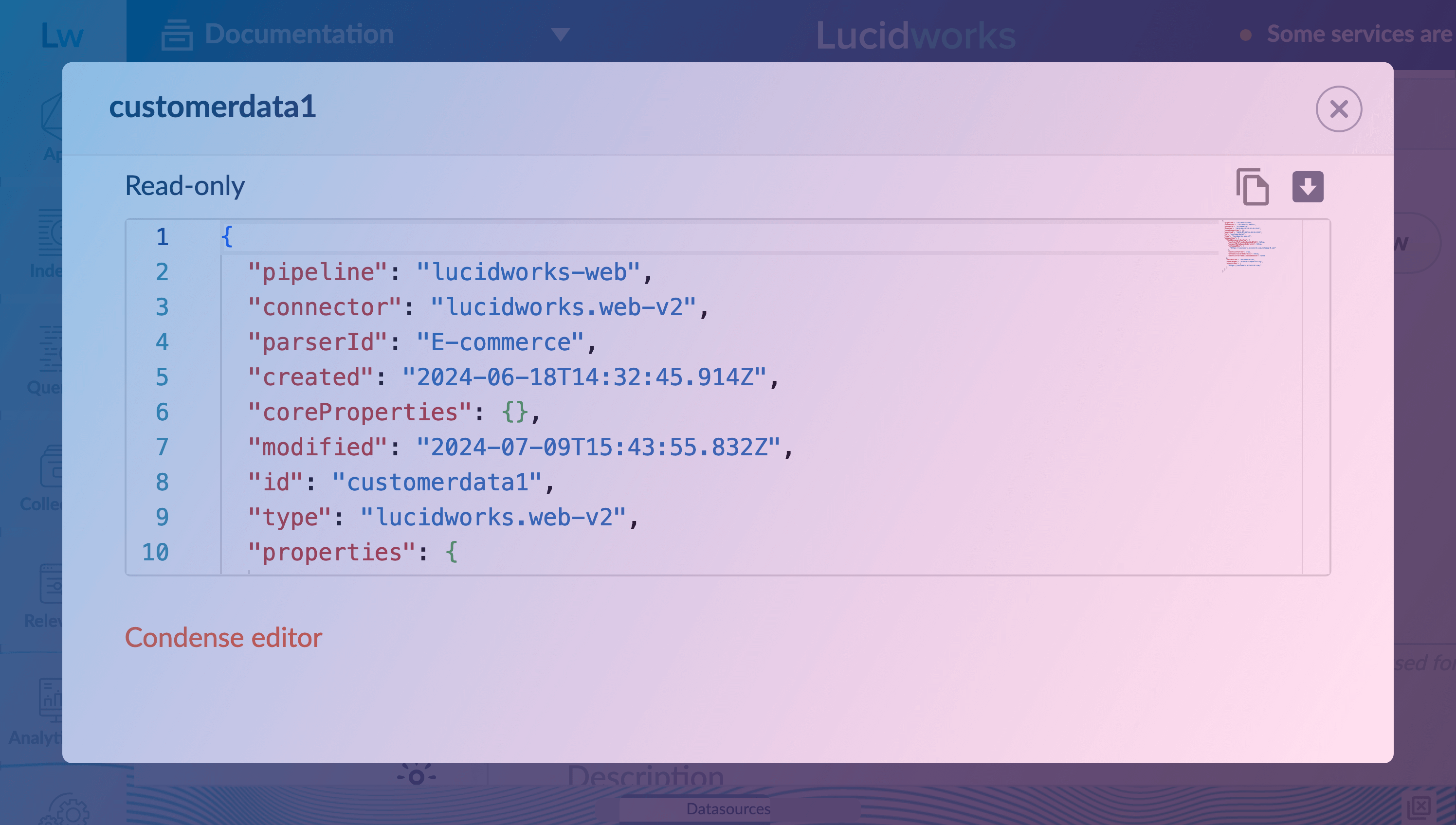
A new JSON viewer has been introduced in Fusion, providing a user-friendly interface to inspect the JSON configuration of key objects like index pipelines, query pipelines, jobs, and datasources. This viewer allows users to:
-
Visualize configuration: View the complete JSON representation of the selected object’s configuration in a clear and well-formatted manner. For example, a basic datasource configuration resembles the following:
{ "id": "mens-products", "created": "2024-02-12T15:08:29.332Z", "modified": "2024-02-12T15:08:29.332Z", "connector": "lucid.fileupload", "type": "fileupload", "pipeline": "Documentation", "parserId": "_system", "properties": { "collection": "Documentation", "fileId": "mens-products.csv", "mediaType": "application/octet-stream" } } -
Facilitate operations: Easily copy the displayed JSON for use in essential activities such as API calls.
-
Download for reference: Download the JSON configuration as a file for backup or collaboration.
To learn how to use the JSON viewer, see the following demonstration:
|
Lucidworks offers free training to help you get started. The Quick Learning for JSON Viewer focuses on how to incorporate the JSON viewer into your daily workflow:
Visit the LucidAcademy to see the full training catalog. |
Asynchronous parsing service
An asynchronous parsing service for connectors, Apache Tika Container, has been added. This stage is now required when using asynchronous parsing for connectors.
To use asynchronous parsing for connectors, be sure that the Async Parsing is checked in the datasource and the Apache Tika Container parser stage is enabled in the index pipeline.
| Other parsers, such as HTML and JSON, are now supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is used. |
To learn how to start using the new asynchronous parsing service, see the following demonstration:
Managed Fusion
Cloud signal storage for Managed Fusion
Managed Fusion now offers the flexibility to store signals data in Google Cloud Storage or Amazon S3, providing an alternative to the default Solr storage. Cloud signal storage minimizes the storage burden on your Solr cluster, potentially leading to improved performance and resource optimization.
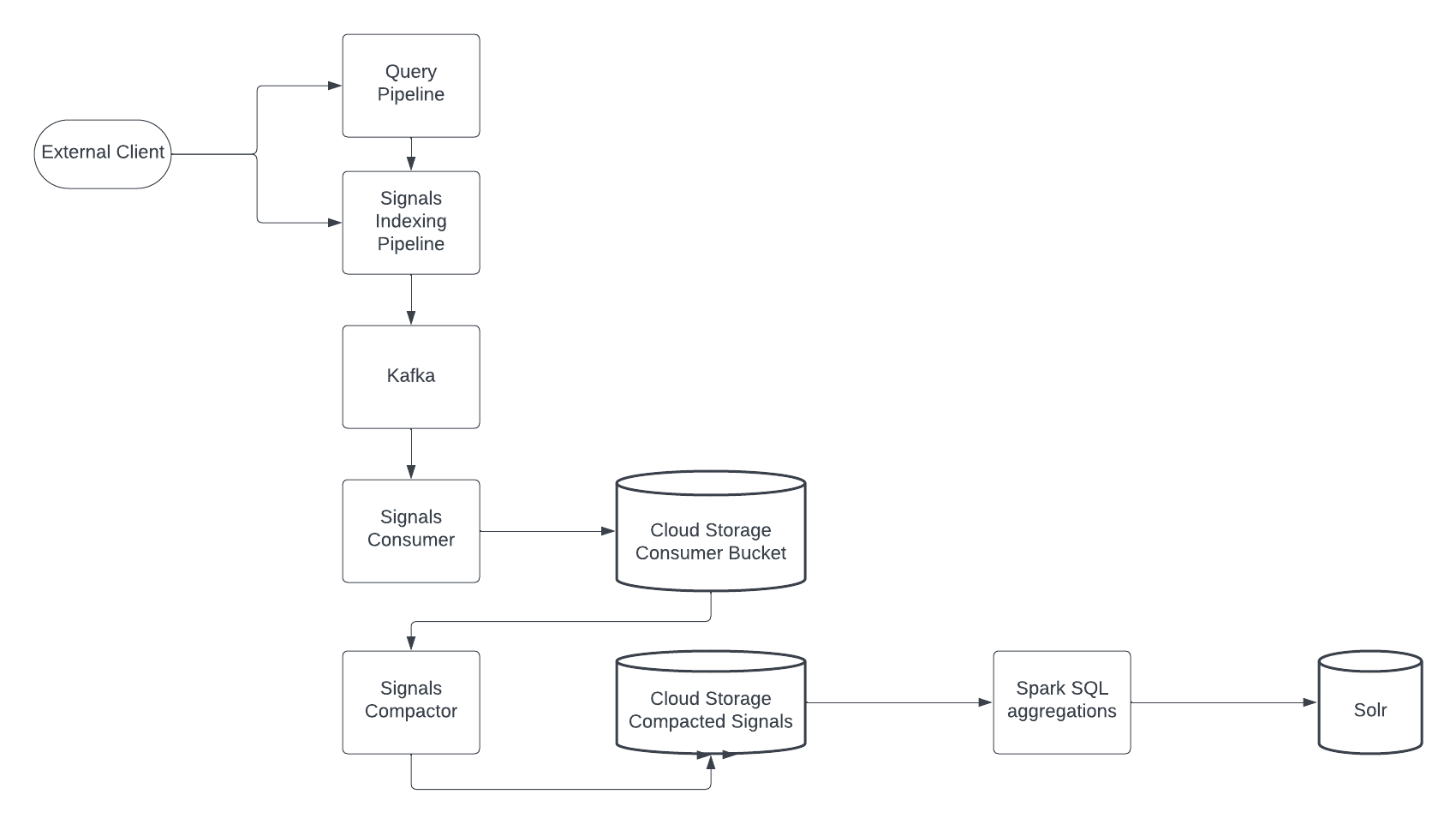
All signal types, including custom types, are fully supported for cloud storage. Additionally, customization of the default signal schema remains available. Signals data files are automatically compacted over time into larger files, resulting in significant storage space savings and simplified file management.
Cloud signal storage is enabled during initial deployment. For more information, see Cloud signal storage for Managed Fusion.
Improvements
-
Introduced significant improvements to job status reporting within Fusion. A dedicated job function microservice,
job-config, has been added to control job execution and store job history. This microservice requires no configuration from the client. In addition, to optimize communication efficiency, synchronous calls have been replaced with asynchronous communication through Kafka. As a result of these changes, job reports are now far more accurate and reliable than before.These changes do not impact Fusion API usage or user workflows.
-
Introduced a configurable timeout for datasource jobs, in case the connection to the backend job is lost. Previously, the job was stopped after a fixed duration of 100 seconds.
-
Previously query pipeline pods could restart due to scaling or other reasons, leading to 503 errors in the API gateway. This release introduces a configurable retry setting for the api-gateway service that will automatically attempt to reconnect to the query pipeline pods. This addresses the previously observed 503 errors under sustained query load.
-
Pre-packaged configurations for commonly used dimensionalities (64, 384, 512, and 768) in vector search operations within Solr are added to Fusion. These configurations leverage a naming convention that incorporates dimensionality into dynamic field names, simplifying setup and management for users. For example:
<fieldType class="solr.DenseVectorField" codecFormat="Lucene90HnswVectorsFormat" hnswBeamWidth="40" hnswMaxConnections="10" name="knn_512_vector" similarityFunction="cosine" vectorDimension="512" /> <dynamicField docValues="false" indexed="true" multiValued="false" name="*_512_v" required="false" stored="false" type="knn_512_vector" />
-
Introduced automated management of Kafka topic partitions for indexing subscriptions within Fusion. Fusion now intelligently determines the optimal number of partitions, creates the topics with appropriate configurations, and initiates the subscription process.
Bug Fixes
-
Fixed a bug that prevented remote connector datasources from indexing data after encountering a "No Plugin Activity" error. Previously, affected datasources required recreation with a different name despite maintaining identical specifications.
-
Fixed a bug that caused a Solr syntax error when attempting to delete an aclDocument using the SDK method
newDeleteGraphAccessControlItemif the ID of the document contained special characters.
-
Fixed a bug that sometimes resulted in a
ConcurrentModificationExceptionerror during high-load testing of query pipelines utilizing Solr Subquery and Merge Async Results stages.
-
Addressed a race condition impacting dynamic pricing functionality. Previously, concurrent user requests for the same external file could lead to the second request encountering an error. The fix ensures proper handling of concurrent requests, eliminating the potential for this error.
-
Fixed a bug that caused a
ConcurrentModificationExceptionerror during the.RawPullreplication process within Solr.
-
Fixed a bug in the UI login process where attempting to log in with an incorrect password after an expired session resulted in no error message being displayed on the UI.
Deprecations
For full details on deprecations, see Deprecations and Removals.
V1 Fusion connectors
Starting in Fusion 5.12.0, all V1 connectors are deprecated. This means they are no longer being actively developed and will be removed in the next LTS release, Fusion 5.13.0. Please note:
-
Some V1 connectors already have a direct replacement available. You can find the replacement connector on the Fusion Connectors Deprecations and Removals page.
-
For all other V1 connectors, a replacement is still under development. We will update the documentation when the replacement is available.
If you are using a V1 connector, you must migrate to the replacement connector or a supported alternative before upgrading to Fusion 5.13.0. We recommend migrating to the replacement connector as soon as possible to avoid any disruption to your workflows.
Banana dashboards
Banana, the open source browser visualization tool that previously powered Fusion’s Banana Dashboards, is deprecated for Fusion. It is scheduled for removal in Fusion 5.13.0. While Banana will no longer be included with Fusion, users who require continued use can leverage a separate Docker deployment option. This alternative deployment method will be available in Fusion 5.13.0.
If you would like to explore the open source project, see Banana on Github.
Other deprecations
-
App Insights and the insights microservice are deprecated and will be removed in a future release.
-
The Parsers CRUD API from the indexing service is deprecated and will be removed in a future release. Use
/async-parsing/instead.
-
The Train a Smart Answers cold start model job is deprecated and will be removed in a future release. Use one of the pre-trained models or the supervised training job instead.
-
The Data Augmentation job is deprecated and will be removed in a future release.
Known issues
-
New Kerberos security realms cannot be configured successfully in this version of Fusion.