This stage uses the SolrTextTagger handler to identify known entities in the query by searching either of the following:Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
_query_rewrite_stagingcollection in the case of the Fusion AI query rewriting Simulator._query_rewritecollection. See Manage Collections in the Fusion UI for more information.
Manage Collections in the Fusion UI
Manage Collections in the Fusion UI
Collections can be created or removed using the Fusion UI or the REST API.For information about using the REST API to manage collections, see Collections API in the REST API Reference:You can map a Fusion collection to multiple Solr collections, known here as partitions, where each partition contains data from a specific time range.To configure time-based partitioning, under Time Series Partitioning click Enable.See Time-Based Partitioning for more information.To stop a datasource immediately, choose Abort instead of Stop.There is also a REST API for datasources:
- Fusion 5.x. Collections API
- Fusion 4.x. Collections API
Creating a Collection
When you create an app, by default Fusion Server creates a collection and associated objects.To create a new collection in the Fusion UI:- From within an app, click Collections > Collections Manager.
- At the upper right of the panel, click New.
- Enter a Collection name. This name cannot be changed later.
- To create the collection in the default Solr cluster and with other default settings, click Save Collection.
Creating a Collection with Advanced Options
To access advanced options for creating a collection in the Fusion UI:- From within an app, click Collections > Collections Manager.
- At the upper right of the panel, click New.
- Enter a Collection name. This name cannot be changed later.
- Click Advanced.
- Configure advanced options. The options are described below.
- Click Save Collection.
Solr Cluster
By default, a new collection is associated with the Solr instance that is associated with thedefault Solr cluster.If Fusion has multiple Solr clusters, choose from the list which cluster you want to associate your collection with.
The cluster must exist first.Solr Cluster Layout
The next section lets you define a Replication Factor and Number of Shards. Define these options only if you are creating a new collection in the Solr cluster. If you are linking Fusion to an existing Solr collection, you can skip these settings.Solr Collection Import
Import a Solr collection to associate the new Fusion collection with an existing Solr collection. Enter a Solr Collection Name to associate the collection with an existing Solr collection. Then, enter a Solr Config Set to tell ZooKeeper to use the configurations from an existing collection in Solr when creating this collection.Time Series Partitioning
Available in 4.x only.
Configuring Collections
The Collections menu lets you configure your existing collection, including datasources, fields, jobs, stopwords, and synonyms.In the Fusion UI, from any app, the Collections icon displays on the left side of the screen.Some tasks related to managing a collection are available in other menus:- Configure a profile in Indexing > Indexing Profiles or Querying > Query Profiles.
- View reports about your collection’s activity in Analytics > Dashboards.
Collections Manager
The Collections Manager page displays details about the collection, such as how many datasources are configured, how many documents are in the index, and how much disk space the index consumes.This page also lets you create a new collection, disable search logs or signals, enable recommendations, issue a commit command to Solr, or clear a collection.Disable search logs
When you first create a collection, the search logs are created by default. The search logs populate the panels in Analytics > Dashboards.- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Disable Search Logs.
- On the confirmation screen, click Disable Search Logs.
- Fusion 5.x. Dashboards
- Fusion 4.x. Dashboards
Disable signals
When you first create a collection, the signals and aggregated signals collections are created by default.- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Disable Signals.
- On the confirmation screen, click Disable Signals.
Hard commit a collection
- Hover over your collection name until the gear icon appears at the end of the line.
- Click the gear icon.
- Click Hard Commit Collection.
- On the confirmation screen, click Hard Commit Collection.
Datasources
To access the Datasources page, click Indexing > Datasources. By default, there are no datasources configured right after installation.To add a new datasource, click New at the upper right of the panel.See the Connectors and Datasources Reference for details on how to configure a datasource. Options vary depending on the repository you would like to index.After you configure a datasource, it appears in a list on this screen. Click the name of a datasource to edit its properties. Click Start to start the datasource. Click Stop to stop the datasource before it completes. To the right, view information on the last completed job, including the date and time started and stopped, and the number of documents found as new, skipped, or failed.When you stop a datasource, Fusion attempts to safely close connector threads, finishing processing documents through the pipeline and indexing documents to Solr. Some connectors take longer to complete these processes than others, so might stay in a “stopping” state for several minutes.
- Fusion 5.x. Connector Datasources API
- Fusion 4.x. Connector Datasources API
Stopwords
The Stopwords page lets you edit a stopwords list for your collection.To add or delete stop words:- Click the name of the text file you wish to edit.
- Add a new word on a new line.
- When you are done with your changes, click Save.
- Click System > Import Fusion Objects.
- Choose the file to upload.
- Click Import >>.
Synonyms
Fusion has the same synonym functionality that Solr supports. This includes a list of words that are synonyms (where the synonym list expands on the terms entered by the user), as well as a full mapping of words, where a word is substituted for what the user has entered (that is, the term the user has entered is replaced by a term in the synonym list).See more about synonyms:You can edit the synonyms list for your collection.To access the Synonyms page in the Fusion UI, in any app, click Collections > Synonyms.Filter the list of synonym definitions by typing in the Filter… box.To import a synonyms list:- From the Synonyms page, click Import and Save. A dialog box opens.
- Choose the file to import.
- Enter new synonym definitions one per line.
- To enter a string of terms that expand on the terms the user entered, enter the terms separated by commas, like
Television, TV. - To enter a term that should be mapped to another term, enter the terms separated by an equal sign then a right angle bracket,
=>, likei-pod=>ipod.
- To enter a string of terms that expand on the terms the user entered, enter the terms separated by commas, like
- Remove a line by clicking the x at the end of the line.
- Once you are finished with edits, click Save.
Profiles
Profiles allow you to create an alias for an index or query pipeline. This allows you to send documents or queries to a consistent endpoint and change the underlying pipeline or collection as needed.Read about profiles in Index Profiles and Query Profiles:- Fusion 5.x.
- Fusion 4.x.
Learn more
Collections Menu Tour
The quick learning for Collections Menu Tour focuses on the Collections Menu features and functionality along with a brief description of each screen available in the menu.
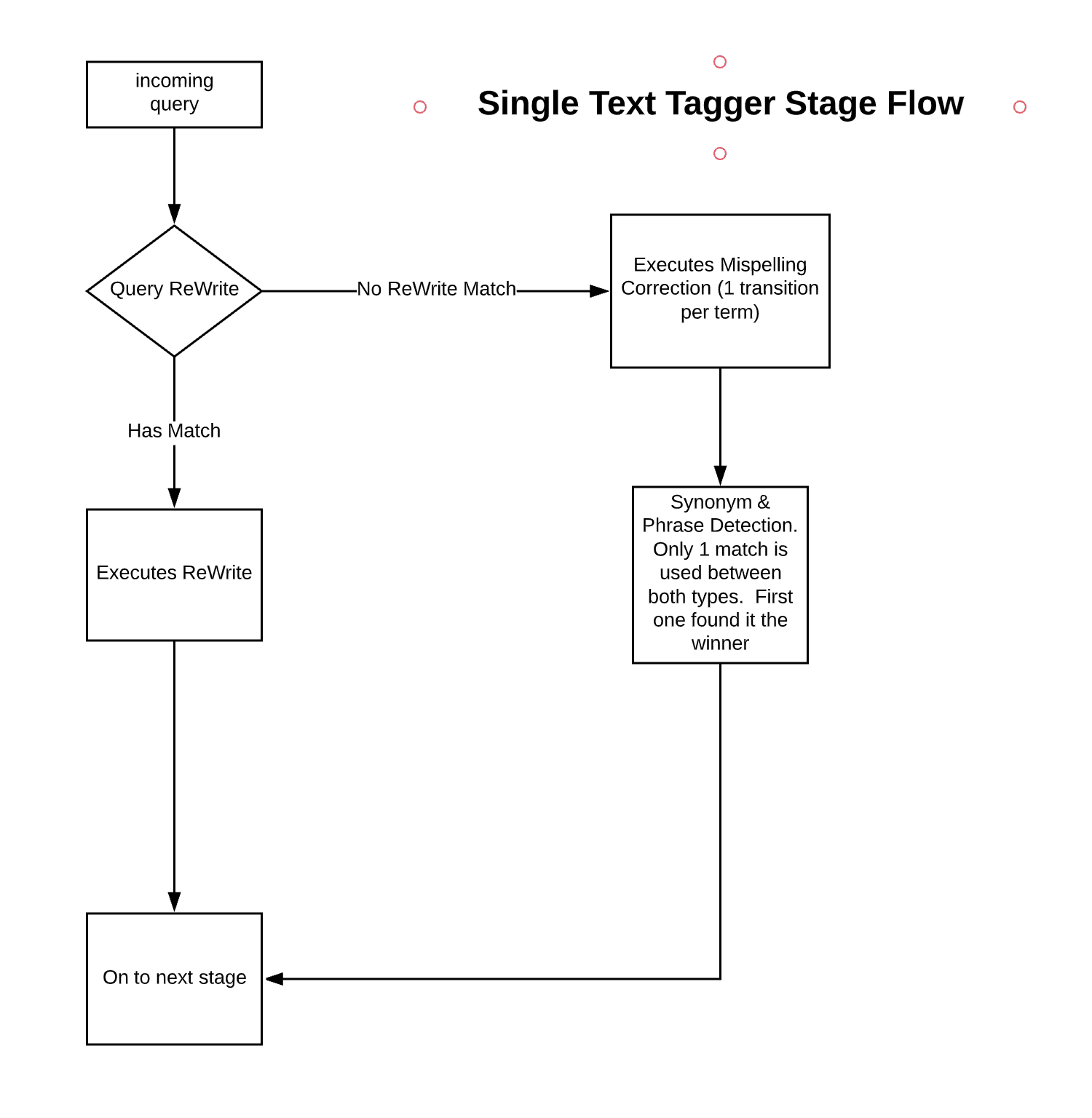
The underlying SolrTextTagger currently only supports single-shard collections. Fusion users should ensure their
_query_rewrite collection, or whatever collection the Text Tagger stage is configured to use, is single-sharded before enabling this stage.Although this stage is available without a Fusion AI license, it is only effective after running Fusion AI jobs or creating Fusion AI rules. See Query Rewriting for details.