Deployment Types
The Fusion platform is designed to support enterprise search applications at any scale. You can deploy Fusion across multiple nodes in order to store large amounts of data or to achieve high processing throughput or both.
Fusion consists of a number of Java processes that run in JVMs, including the api, connectors-classic, connectors-rpc, and admin-ui processes, and possibly others such as spark-master and spark-worker. When you start Fusion, the processes that start are listed. You might also see zookeeper and solr processes, depending on the cluster arrangement.
For more information about Fusion components, see Fusion Components. For a complete list of Fusion services, see Start and stop Fusion.
Deployment goals
-
Demo, trial, and development deployments. The simplest possible architecture is the one you get out of the box, by unpacking the tar/zip file and running
https://FUSION_HOST:FUSION_PORT/bin/fusion start, so that all components (including the bundled Solr and ZooKeeper instances) run on a single host in their default configurations.You can quickly install and run Fusion on a computer (even on your laptop) to explore its features and work with sample data. See Quickstart for instructions. This diagram illustrates a single-node Fusion deployment:

-
Onsite late-stage development and test deployments. Ideally, an onsite deployment for late-stage development and testing should have the same architecture as the production deployment, though it does not need to be scaled to provide the same level of service.
-
Production deployments. Fusion is designed for flexible, distributed deployment. Any of its components can be distributed across your network, and some can be clustered. A production deployment requires multiple Fusion nodes, each of which runs some or all Fusion services (including Solr and ZooKeeper).
Cluster Arrangements
You can deploy Fusion across multiple nodes in a Fusion cluster and use a ZooKeeper cluster as the centralized, synchronized store for both application configurations and user data.
Regarding Solr, if you already have SolrCloud clusters managing your data, you can integrate them into a Fusion deployment.
To satisfy processing requirements, install Fusion, ZooKeeper, and Solr on specific nodes. These are the possibilities:
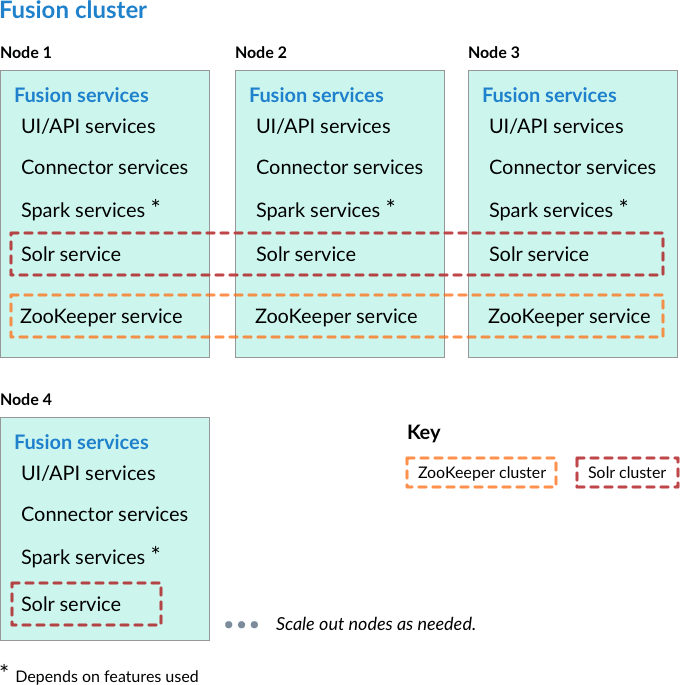
Nodes running core Fusion services and Solr also run ZooKeeper
In this cluster arrangement, a ZooKeeper cluster runs on the same nodes that run core Fusion services and Solr. This arrangement works well for a small cluster with low usage and can reduce cost when compared with placing ZooKeeper on separate nodes.
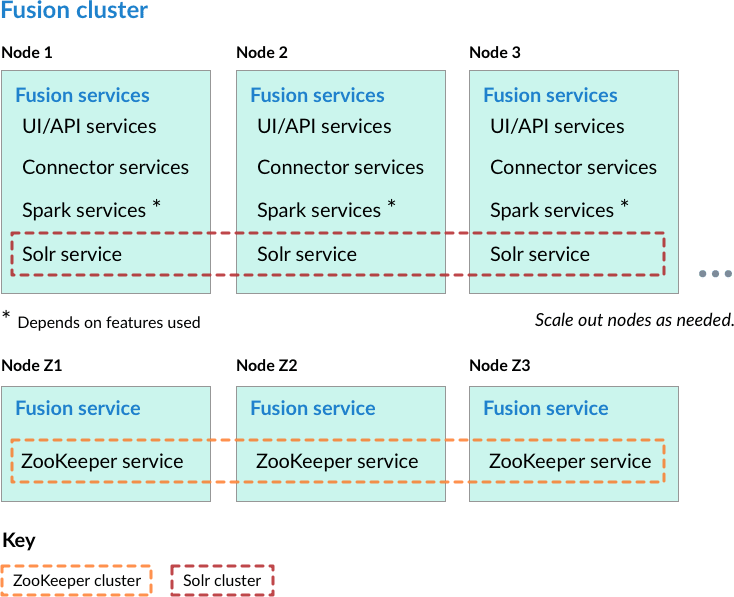
Nodes running ZooKeeper are not running core Fusion services or Solr
In this cluster arrangement, the ZooKeeper cluster runs on nodes in the Fusion cluster on which core Fusion services and Solr are not running. This arrangement is good for larger or more active clusters and can help reduce write latency. This also lets Fusion nodes scale horizontally without impacting the ZooKeeper nodes.