When to use remote connectors
Use remote connectors for data sources behind firewalls, security policies restricting cloud access, or compliance requirements mandating on-premises data processing.
When to use standard Fusion connectors
Use standard connectors for publicly accessible or cloud-based data sources where Fusion can manage all infrastructure, scaling, and maintenance.
Connector compatibility
Only V2 connectors are able to run remotely on-premises. You also need the remote connector client JAR file that matches your Fusion version. You can download the latest files at V2 Connectors Downloads.Firewall configuration best practices
You can use a forward proxy server to allow HTTP/2 communication into the Fusion cloud. A forward proxy server acts as an intermediary between the firewalled connector and Fusion and will only allow specified communication traffic and block unauthorized traffic.Asynchronous parsing
Asynchronous parsing separates document crawling from document parsing, improving indexing performance and resource utilization. Unlike synchronous parsing where crawling waits for each document to be parsed, asynchronous parsing allows the connector to continue crawling while documents are parsed independently. This is particularly beneficial for remote V2 connectors processing large volumes of documents or complex file formats.This feature is available in Fusion 5.9 and later.
Learn more
Configure Remote V2 Connectors
Configure Remote V2 Connectors
If you need to index data from behind a firewall, you can configure a V2 connector to run remotely on-premises using TLS-enabled gRPC.The gRPC connector backend is not supported in Fusion environments deployed on AWS.The
Prerequisites
Before you can set up an on-prem V2 connector, you must configure the egress from your network to allow HTTP/2 communication into the Fusion cloud. You can use a forward proxy server to act as an intermediary between the connector and Fusion.The following is required to run V2 connectors remotely:- The plugin zip file and the connector-plugin-standalone JAR.
- A configured connector backend gRPC endpoint.
- Username and password of a user with a
remote-connectorsoradminrole. - If the host where the remote connector is running is not configured to trust the server’s TLS certificate, you must configure the file path of the trust certificate collection.
If your version of Fusion doesn’t have the
remote-connectors role by default, you can create one. No API or UI permissions are required for the role.Connector compatibility
Only V2 connectors are able to run remotely on-premises. You also need the remote connector client JAR file that matches your Fusion version. You can download the latest files at V2 Connectors Downloads.When you upgrade Fusion, you must also update your remote connectors to match the new version of Fusion.
System requirements
The following is required for the on-prem host of the remote connector:- (Fusion 5.9.0-5.9.10) JVM version 11
- (Fusion 5.9.11 and later) JVM version 17
- Minimum of 2 CPUs
- 4GB Memory
Enable backend ingress
In yourvalues.yaml file, configure this section as needed:-
Set
enabledtotrueto enable the backend ingress. -
Set
pathtypetoPrefixorExact. -
Set
pathto the path where the backend will be available. -
Set
hostto the host where the backend will be available. -
In Fusion 5.9.6 only, you can set
ingressClassNameto one of the following:nginxfor Nginx Ingress Controlleralbfor AWS Application Load Balancer (ALB)
-
Configure TLS and certificates according to your CA’s procedures and policies.
TLS must be enabled in order to use AWS ALB for ingress.
Connector configuration example
Minimal example
Logback XML configuration file example
Run the remote connector
logging.config property is optional. If not set, logging messages are sent to the console.Test communication
You can run the connector in communication testing mode. This mode tests the communication with the backend without running the plugin, reports the result, and exits.Encryption
In a deployment, communication to the connector’s backend server is encrypted using TLS. You should only run this configuration without TLS in a testing scenario. To disable TLS, setplain-text to true.Egress and proxy server configuration
One of the methods you can use to allow outbound communication from behind a firewall is a proxy server. You can configure a proxy server to allow certain communication traffic while blocking unauthorized communication. If you use a proxy server at the site where the connector is running, you must configure the following properties:- Host. The hosts where the proxy server is running.
- Port. The port the proxy server is listening to for communication requests.
- Credentials. Optional proxy server user and password.
Password encryption
If you use a login name and password in your configuration, run the following utility to encrypt the password:- Enter a user name and password in the connector configuration YAML.
-
Run the standalone JAR with this property:
- Retrieve the encrypted passwords from the log that is created.
- Replace the clear password in the configuration YAML with the encrypted password.
Connector restart (5.7 and earlier)
The connector will shut down automatically whenever the connection to the server is disrupted, to prevent it from getting into a bad state. Communication disruption can happen, for example, when the server running in theconnectors-backend pod shuts down and is replaced by a new pod. Once the connector shuts down, connector configuration and job execution are disabled. To prevent that from happening, you should restart the connector as soon as possible.You can use Linux scripts and utilities to restart the connector automatically, such as Monit.Recoverable bridge (5.8 and later)
If communication to the remote connector is disrupted, the connector will try to recover communication and gRPC calls. By default, six attempts will be made to recover each gRPC call. The number of attempts can be configured with themax-grpc-retries bridge parameters.Job expiration duration (5.9.5 only)
The timeout value for irresponsive backend jobs can be configured with thejob-expiration-duration-seconds parameter. The default value is 120 seconds.Use the remote connector
Once the connector is running, it is available in the Datasources dropdown. If the standalone connector terminates, it disappears from the list of available connectors. Once it is re-run, it is available again and configured connector instances will not get lost.Enable asynchronous parsing (5.9 and later)
To separate document crawling from document parsing, enable Tika Asynchronous Parsing on remote V2 connectors.Use Tika Asynchronous Parsing
Use Tika Asynchronous Parsing
This document describes how to set up your application to use Tika asynchronous parsing.Unlike synchronous Tika parsing, which uses a parser stage, asynchronous Tika parsing is configured in the datasource and index pipeline. For more information, see Asynchronous Tika Parsing.
Field names change with asynchronous Tika parsing.In contrast to synchronous parsing, asynchronous Tika parsing prepends
parser_ to fields added to a document. System fields, which start with \_lw_, are not prepended with parser_. If you are migrating to asynchronous Tika parsing, and your search application configuration relies on specific field names, update your search application to use the new fields.Configure the connectors datasource
- Navigate to your datasource.
- Enable the Advanced view.
-
Enable the Async Parsing option.
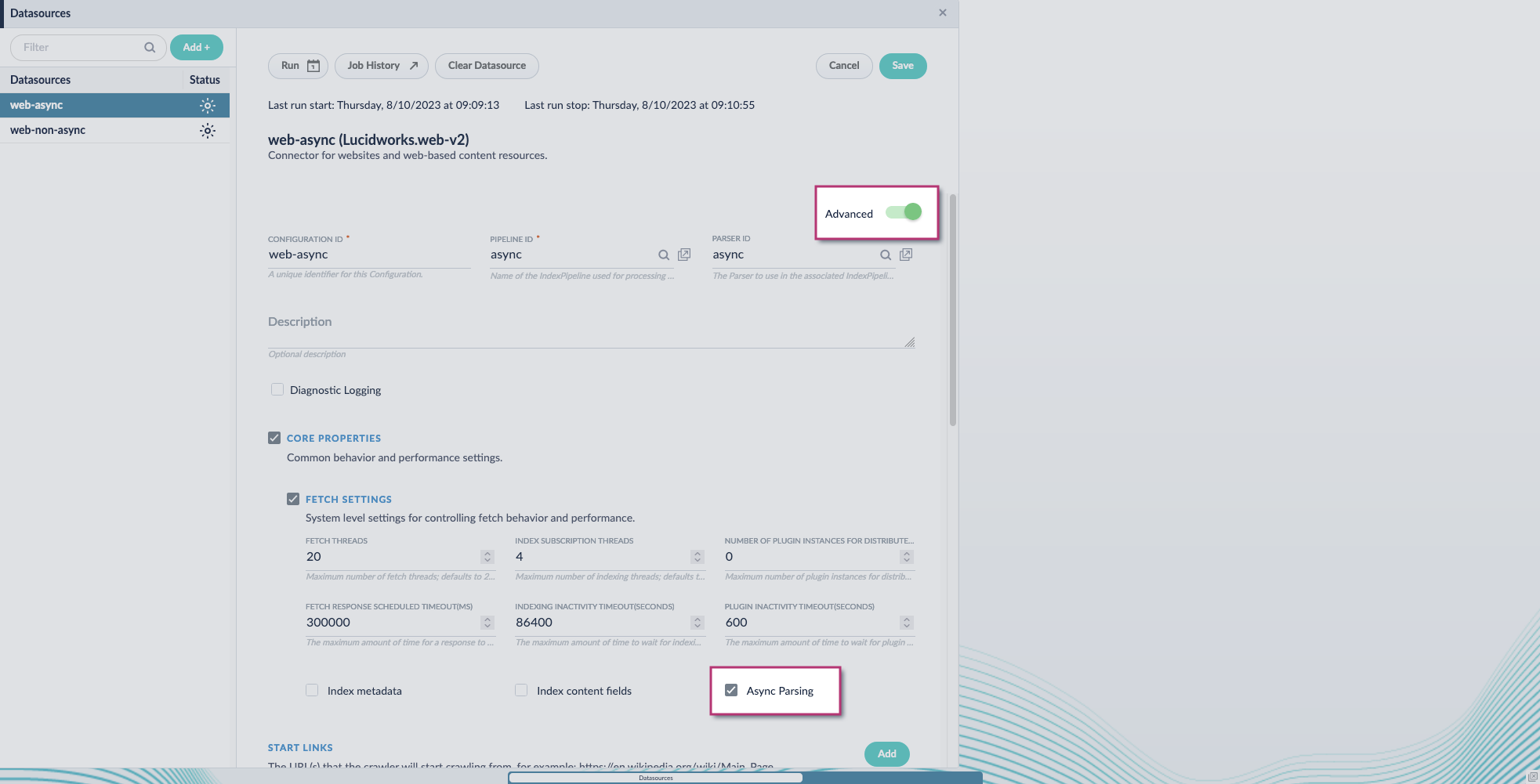 Fusion 5.9.11 and later uses your parser configuration when using asynchronous parsing.The asynchronous parsing service performs Tika parsing using Apache Tika Server. In Fusion 5.8 through 5.9.10, other parsers, such as HTML and JSON, are not supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is ignored. In Fusion 5.9.11 and later, other parsers, such as HTML and JSON, are supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is used.
Fusion 5.9.11 and later uses your parser configuration when using asynchronous parsing.The asynchronous parsing service performs Tika parsing using Apache Tika Server. In Fusion 5.8 through 5.9.10, other parsers, such as HTML and JSON, are not supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is ignored. In Fusion 5.9.11 and later, other parsers, such as HTML and JSON, are supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is used. - Save the datasource configuration.
Configure the parser stage
You must do this step in Fusion 5.9.11 and later.
- Navigate to Parsers.
- Select the parser, or create a new parser.
- From the Add a parser stage menu, select Apache Tika Container Parser.
- (Optional) Enter a label for this stage. This label changes the names from Apache Tika Container Parser to the value you enter in this field.
- If the Apache Tika Container Parser stage is not already the first stage, drag and drop the stage to the top of the stage list so it is the first stage that runs.
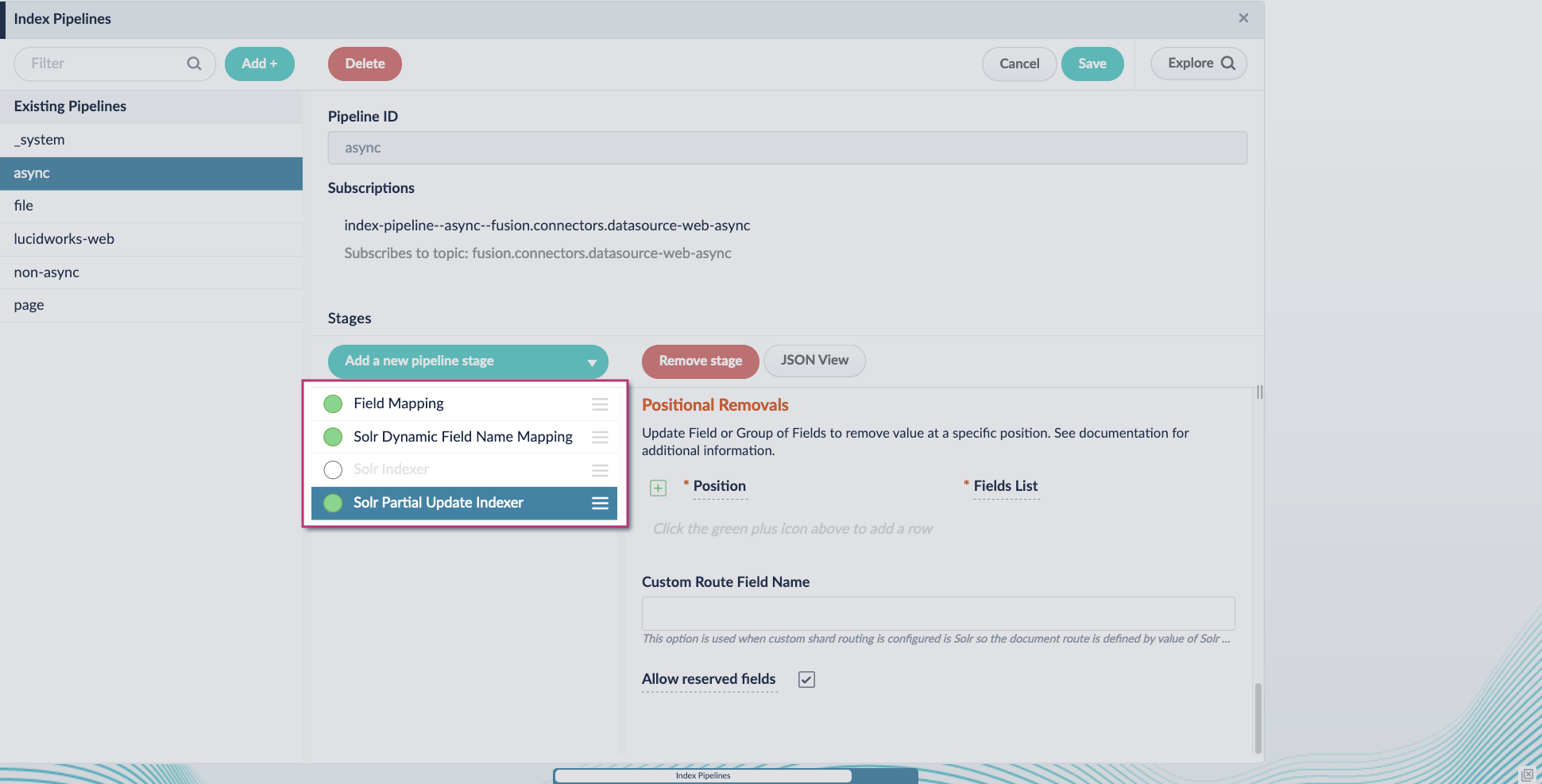
Configure the index pipeline
- Go to the Index Pipeline screen.
- Add the Solr Partial Update Indexer stage.
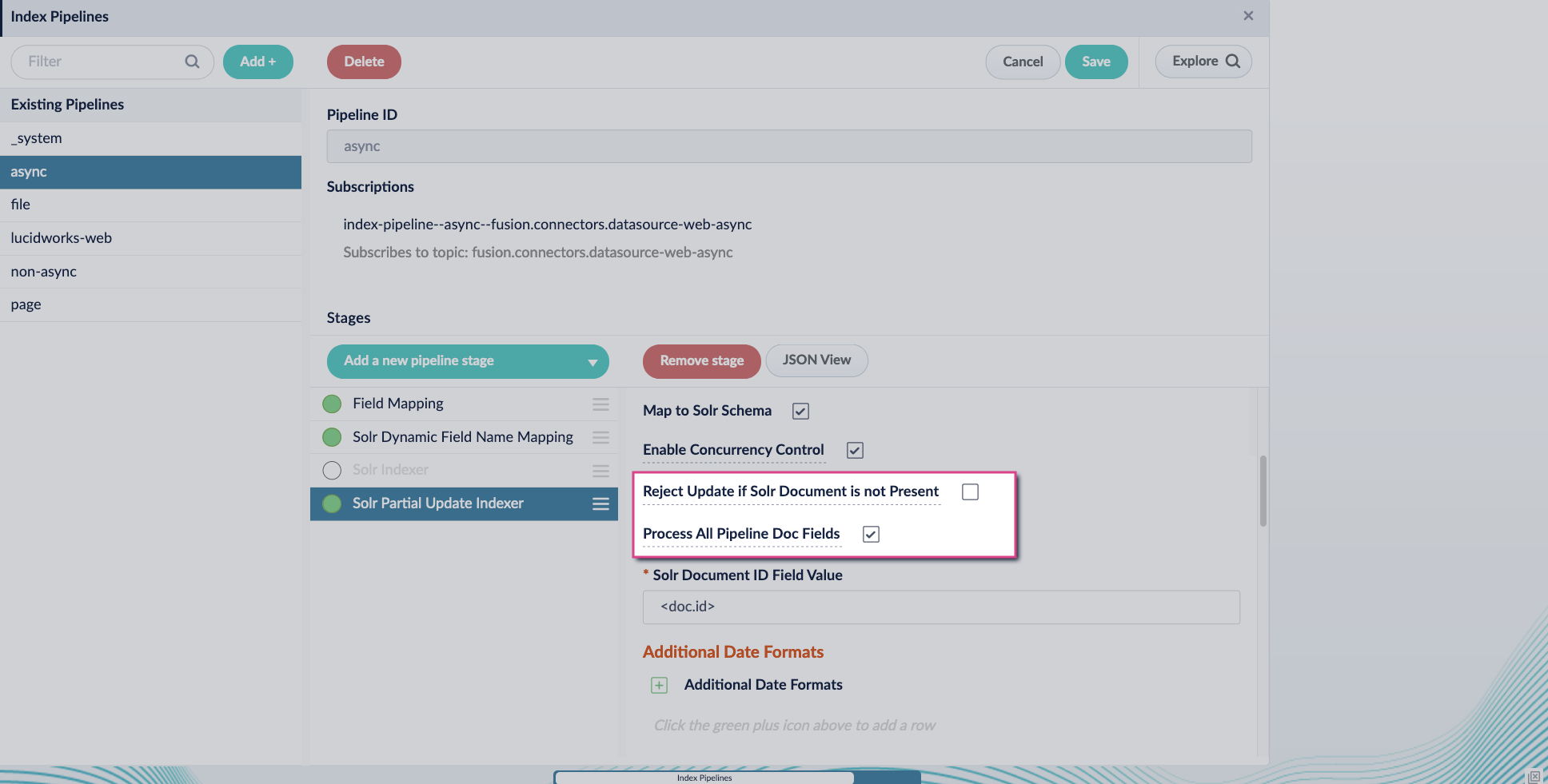
-
Turn off the Reject Update if Solr Document is not Present option and turn on the Process All Pipeline Doc Fields option:
-
Include an extra update field in the stage configuration using any update type and field name. In this example, an incremental field
docs_counter_iwith an increment value of1is added: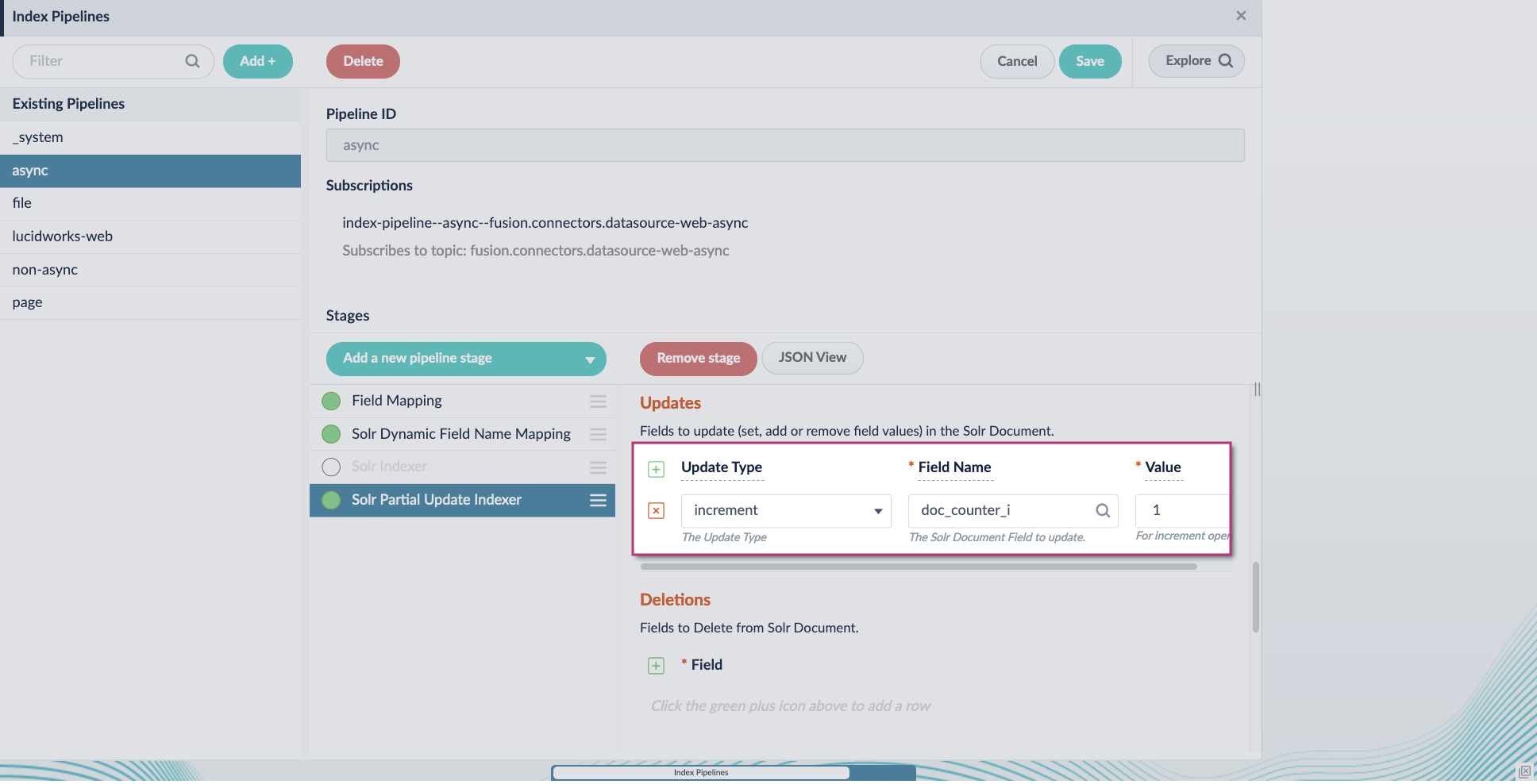
-
Enable the Allow reserved fields option:
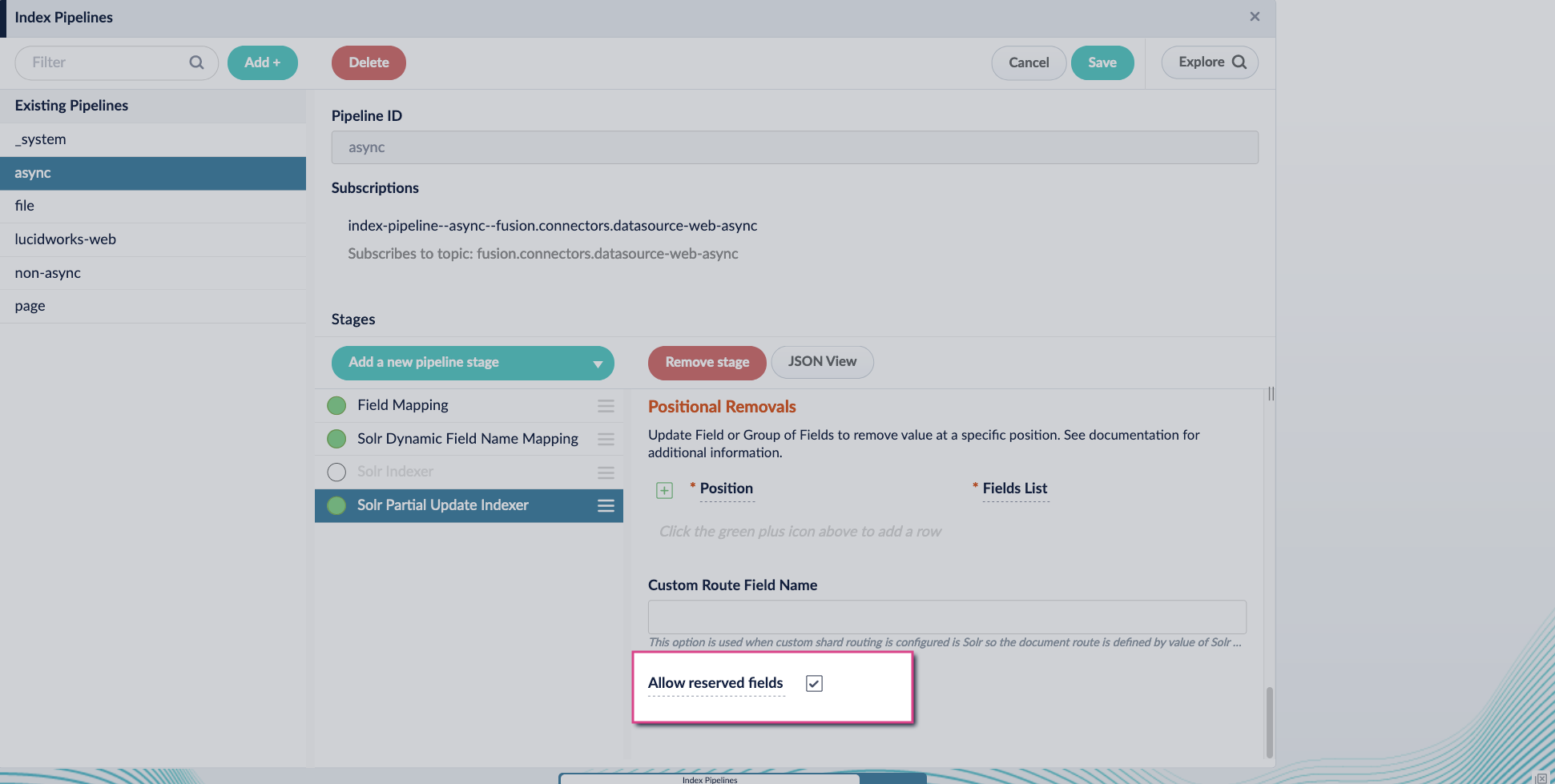
- Click Save.
-
Turn off or remove the Solr Indexer stage, and move the Solr Partial Update Indexer stage to be the last stage in the pipeline.