Custom Spark jobs run Java ARchive (JAR) files uploaded to the blob store. To configure a custom Spark job, sign in to Lucidworks Search and click Collections > Jobs. Then click Add+ and in the Custom and Other Jobs section, select Custom Spark Job. You can enter basic and advanced parameters to configure the job. If the field has a default value, it is populated when you click to add the job.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
Basic parameters
To enter advanced parameters in the UI, click Advanced. Those parameters are described in the advanced parameters section.
- Spark job ID. The unique ID for the Spark job that references this job in the API. This is the
idfield in the configuration file. Required field. - Class name. The fully-qualified name of the Java/Scala class to invoke for this job. This is the
klassNamefield in the configuration file. Required field. - Script ARGs. The arguments (ARGs), which are additional options to pass to the application when running this job. This is the
submitArgsfield in the configuration file. Optional field.
Advanced parameters
If you click the Advanced toggle, the following optional fields are displayed in the UI.- Spark Settings. This section lets you enter
parameter name:parameter valueoptions to configure Spark settings. This is thesparkConfigfield in the configuration file. - Scala Script. The value in this text field overrides running
className.main(args)default behavior. This is thescriptfield in the configuration file.
Alternatives to custom Spark jobs are Custom Python job configuration specifications and Scala Script job configuration specifications.
Learn more
Configure Spark Job Resource Allocation
Configure Spark Job Resource Allocation
For related topics, see Spark Operations.
If
Number of instances and cores allocated
To set the number of cores allocated for a job, add the following parameter keys and values in the Spark Settings field. This is done within the “advanced” job properties in the Lucidworks Search UI or thesparkConfig object, if defining a job via the Lucidworks Search API.| Parameter Key | Example Value |
|---|---|
| spark.executor.instances | 3 |
| spark.kubernetes.executor.request.cores | 3 |
| spark.executor.cores | 6 |
| spark.driver.cores | 1 |
spark.kubernetes.executor.request.cores is unset, the default configuration, Spark sets the number of CPUs for the executor pod to be the same number as spark.executor.cores. For example, if spark.executor.cores is 3, Spark allocates 3 CPUs for the executor pod and runs 3 tasks in parallel. To under-allocate the CPU for the executor pod and still run multiple tasks in parallel, set spark.kubernetes.executor.request.cores to a lower value than spark.executor.cores.The ratio for spark.kubernetes.executor.request.cores to spark.executor.cores depends on the type of job: either CPU-bound or I/O-bound. Allocate more memory to the executor if more tasks are running in parallel on a single executor pod.If these settings not specified, the job launches with a driver using one core and 3GB of memory plus two executors, each using one core with 1GB of memory.Memory allocation
The amount of memory allocated to the driver and executors is controlled on a per-job basis using thespark.executor.memory and spark.driver.memory parameters in the Spark Settings section of the job definition. This is found in the Lucidworks Search UI or within the sparkConfig object in the JSON definition of the job.| Parameter Key | Example Value |
|---|---|
| spark.executor.memory | 6g |
| spark.driver.memory | 2g |
Use Spark Drivers
Use Spark Drivers
Using the Spark default driver
Navigate to Collections > Collections Manager and select thesystem_monitor collection.Then navigate to Collections > Jobs and select one of the built-in aggregation jobs, such as session_rollup. In the diagram above, the spark-master service in Fusion is the Cluster Manager.You must delete any existing driver applications before launching the job. Even if you have not started any jobs by hand, Fusion’s API service might have started one automatically, because Fusion ships with built-in jobs that run in the background which perform rollups of metrics in the system_monitorcollection. Therefore, before you try to launch a job, you should run the following command:Fusion-20161005224611) is running.In a terminal window or windows, set up a tail -f job (on Unix, or the equivalent on Windows) on the api and spark-driver-default logs:bin directory below the Fusion home directory, for example, /opt/fusion/latest.x* (on Unix) or C:\lucidworks\fusion\latest.*x (on Windows).Now, start any aggregation job from the UI. It does not matter whether or not this job performs any work; the goal of this exercise is to show what happens in Fusion and Spark when you run an aggregation job.
You should see activity in both logs related to starting the driver application and running the selected job.
The Spark UI will now show a Fusion-Spark app:
ps command to get more details on this process: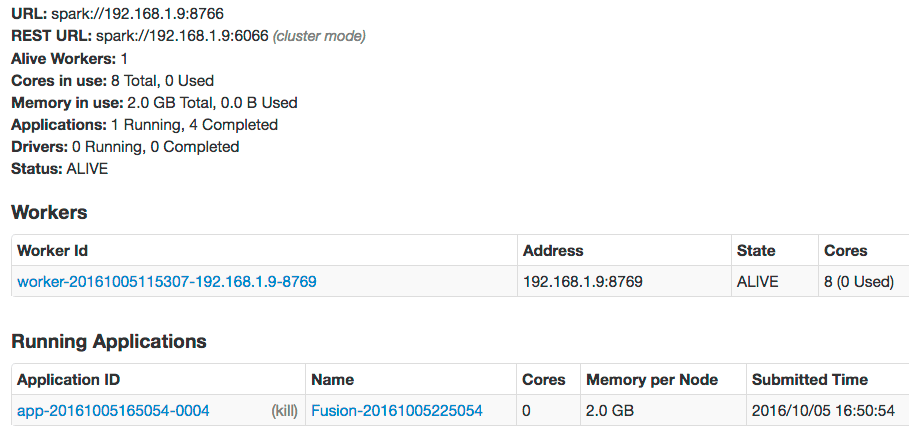
spark.dynamicAllocation.enabled=true. This setting allows the Spark master to reclaim CPU & memory from an application if it is not actively using the resources allocated to it.Both driver processes (default and scripted) manage a SparkContext. For the default driver, the SparkContext will be shut down after waiting a configurable (fusion.spark.idleTime: default 5 mins) idle time. The scripted driver shuts down the SparkContext after every scripted job is run to avoid classpath pollution between jobs.Using the Spark script-job driver
Fusion supports custom script jobs.Script jobs require a separate driver to isolate the classpath for custom Scala scripts, as well as to isolate the classpath between the jobs, so that classes compiled from scripts do not pollute the classpath for subsequent scripted jobs.For this reason, the SparkContext that each scripted job uses is immediately shut down after the job is finished and is recreated for new jobs. This adds some startup overhead for scripted jobs.Refer to the apachelogs lab in the Fusion Spark Bootcamp project for a complete example of a custom script job.To troubleshoot problems with a script job, start by looking for errors in the script-job driver logspark-driver-scripted.log in /opt/fusion/latest.x*/var/log/api/ (on Unix) or C:\lucidworks\var\fusion\latest.*x\var\log\api\ (on Windows).