Differences between hybrid query stages
The hybrid query pipeline stages are designed to combine lexical search based on keywords with vector search based on meaning or similarity. This combination gives more accurate and relevant results, especially for complex or natural language queries.
Solr vector hybrid search is available in Managed Fusion versions 5.9.5 and later. Since its introduction, improvements and changes have occurred. Please use this documentation to understand the distinctions between stages.
Which stage should I choose?
When deciding to add a hybrid query stage to your pipeline, here is some guidance on which stage you should choose.
-
Use Hybrid Query for basic hybrid setups if you’re on 5.9.5 through 5.9.9 and can’t upgrade.
-
Use Neural Hybrid Query as the default choice for general-purpose hybrid search.
-
Use Chunking Neural Hybrid Query for search across nested data, such as when working with parent-child or chunked data structures.

Technical details about the stages
Important information about implementing hybrid stages:
-
The Vectorize Stage (LWAI or Ray/Seldon) should always go as early as possible in the pipeline before any query changes.
-
It is recommended to use PULL/TLOG replicas because of the way HNSW graphs and replica types work.
-
Highlighting can conflict with the hybrid stages, causing query failures with errors
Index _ out of bounds for length _. To resolve, sethl.qto the lexical-only query parameter<request.params.q>before the hybrid stage, or<request.params.raw_lex_q>.
Hybrid Query stage
The Hybrid Query stage was introduced in 5.9.5 as the initial hybrid stage. It allows the choice between a KNN or a VecSim search. This stage surfaced a Lucene bug that breaks search capabilities if a Lucene segment is unable to find any vectors during a vector search. Because of this, it is recommended to have a vector on every document.
Stage details:
-
Vector Query type: VecSim XOR KNN
-
Scaling equation:
vector_weight*vector_score + lexical_weight*scaled(lexical_score) -
Stage ordering needs:
-
Any stages that add or modify eDisMax-specific request parameters (such as
uf,pf, orpf2) must happen before the hybrid stage. -
Apply Rules must be after the Hybrid Query stage.
-
All documents should have a vector to prevent the
no float vector value is indexed for fieldbug in Lucene.
-
Neural Hybrid Query stage
Advantages over the Hybrid Query stage include:
-
Prefiltering support (filtering prior to running vector search).
-
Improved faceting behavior.
-
A workaround for the Lucene bug is built in, so there is no need for a vector on every document.
The Neural Hybrid Query stage was introduced in 5.9.10, where initially it did not support prefiltering. As of 5.9.11, prefiltering is supported using a checkbox. The Lucene bug that enforces a vector on every segment is resolved when using this stage. Collapse is also properly supported by this stage.
In 5.9.12, facet counts are stable regardless of prefiltering or not. This is true in 5.9.10 and 5.9.11 only when prefiltering is blocked. When prefiltering is enabled in 5.9.10 and 5.9.11, all filter queries are included which causes inconsistent facet counts.
To smooth results scores and make sure any orphans are caught, turn on Compute Vector Similarity for Lexical-Only Matches. This impacts performance but prevents relevant documents from being lost.
Stage details:
-
Vector Query type: KNN
-
Scaling equation:
squash(lexical_score)*lexical_weight + vector_score*vector_weight-
In this equation,
squashistanh(alpha*lexical_score), wherealphais the Lexical Query Squash Factor in the stage andlexical_scoreis the lexical score. The squashing function makes the lexical scores smaller so the scores are more closely bounded to the vector scores and are not weighted significantly more than the vector scores in the scaling equation. Thesquashvalue should be decreased if Solr Explain in the JSON response or the query workbench’s debug mode displays0.9999for a lot of top lexical contributions. If thesquashvalue is smaller, then the lexical and semantic values can be more even.
-
-
Stage ordering needs:
-
Text Tagger stage needs to be before the Neural Hybrid Query stage.
-
Boosting Stages (for example Boost with Signals or Document Boosting) must be after the Neural Hybrid Query stage.
-
Apply Rules must be after the Neural Hybrid Query stage.
-
Security Trimming must be after the Neural Hybrid Query stage and pre-filtering should be enabled.
-
If you are using a JavaScript stage, the JavaScript stage must be after the Neural Hybrid Query stage.
-
This stage uses new query parsers.
If not setting up a new collection, the following must be added to solrconfig.xml:
<!-- Managed Fusion NOTES: These query parsers are used with Solr-based vector search -->
<queryParser name="xvecSim" class="org.apache.solr.lwbackported.XVecSimQParserPlugin"/>
<queryParser name="neuralHybrid" class="org.apache.solr.lw.NeuralHybridQParserPlugin"/>Chunking Neural Hybrid Query stage
The primary advantage of this stage is that it’s designed for cases where search is done across parent-child document relationships, such as product variants or nested documents.
The Chunking Neural Hybrid Query stage was introduced in 5.9.12. It supports prefiltering to enhance query speed. Chunking retrieves the parent documents for lexical search, then returns the parents of the highest child (chunk) score for vector search. The results are then combined.
To smooth results scores and make sure any orphans are caught, turn on Compute Vector Similarity for Lexical-Only Matches. This impacts performance but prevents relevant documents from being lost.
Use of the Chunking Neural Hybrid Query stage on the query side requires the use of specific chunking index stages on the index side (LWAI Chunker Stage).
It also requires the presence of field _lw_chunk_doctype_s with value of either _lw_chunk_root or the name of the vector field defined for the children.
Include one of these values in the chunking index stage.
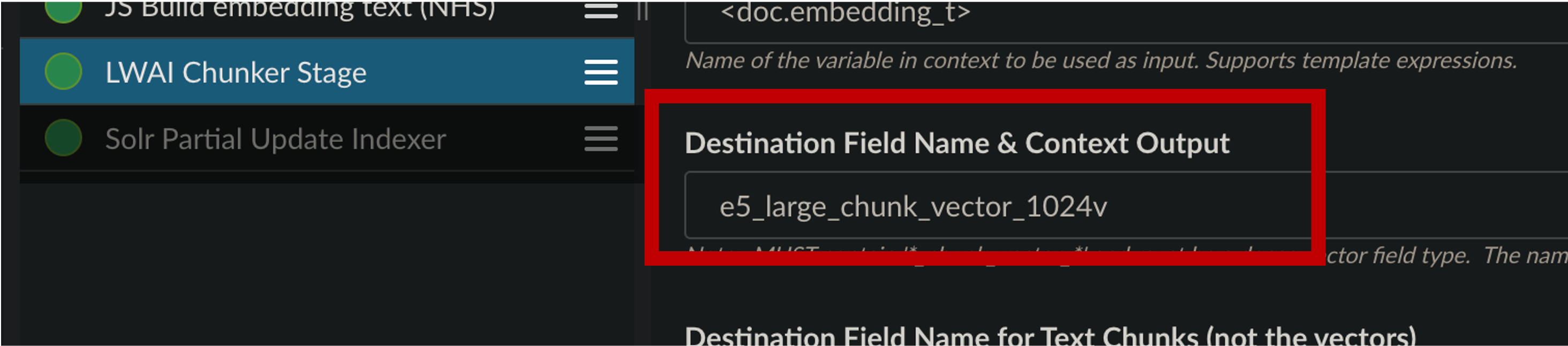
Then these values can be used with the Chunking Neural Hybrid Query stage.

Stage details:
-
Vector Query type: VecSim
-
Scaling equation:
squash(lexical_score)*lexical_weight + vector_score*vector_weight-
In this equation,
squashistanh(alpha*lexical_score), wherealphais the Lexical Query Squash Factor in the stage andlexical_scoreis the lexical score. The squashing function makes the lexical scores smaller so the scores are more closely bounded to the vector scores and are not weighted significantly more than the vector scores in the scaling equation. Thesquashvalue should be decreased if Solr Explain in the JSON response or the query workbench’s debug mode displays0.9999for a lot of top lexical contributions. If thesquashvalue is smaller, then the lexical and semantic values can be more even.
-
-
Stage ordering needs:
-
Text Tagger stage needs to be before the Chunking Neural Hybrid Query stage.
-
Boosting Stages (for example, Boost with Signals or Document Boosting) must be after the Chunking Neural Hybrid Query stage.
-
Apply Rules must be after the Chunking Neural Hybrid Query stage.
-
Security Trimming must be after the Chunking Neural Hybrid Query stage and pre-filtering should be enabled.
-
If you are using a JavaScript stage, the JavaScript stage must be after the Chunking Neural Hybrid Query stage.
-
This stage uses new query parsers.
If not setting up a new collection, the following must be added to solrconfig.xml:
<!-- Managed Fusion NOTES: These query parsers are used with Solr-based vector search -->
<queryParser name="xvecSim" class="org.apache.solr.lwbackported.XVecSimQParserPlugin"/>
<queryParser name="_lw_chunk_wrap" class="org.apache.solr.lw.ParentAndAllKidsWrapperQParserPlugin"/>
<queryParser name="neuralHybrid" class="org.apache.solr.lw.NeuralHybridQParserPlugin"/>