NLP AnnotatorQuery pipeline stage configuration specifications
Like the NLP Annotator index stage, the NLP Annotator query stage can be included in a query pipeline to perform Natural Language Processing tasks.
-
Add the NLP Annotator query stage to the query pipeline.
-
Supply the Model ID ("opennlp", "spacy", or the model ID given to the uploaded Spark NLP model).
-
Specify the input parameter, label pattern and target parameter fields:

-
input parameter field: the Managed Fusion query parameter text, normally
qsince we want to annotate the raw query string to understand the intent. -
label pattern: regex pattern that matches the NER/POS labels: for example,
PER.will match extracted name entities with labelPERSON, whileNN.will match tagged nouns. -
target parameter field: the outcome extraction/tagging, and.
For the query stage, the result is set to be put in a new query parameter field:
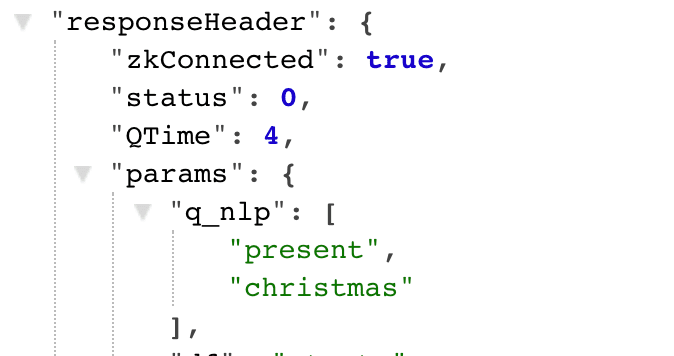
-
Query pipeline stage condition examples
Stages can be triggered conditionally when a script in the Condition field evaluates to true. Some examples are shown below.
Run this stage only for mobile clients:
params.deviceType === "mobile"Run this stage when debugging is enabled:
params.debug === "true"Run this stage when the query includes a specific term:
params.q && params.q.includes("sale")Run this stage when multiple conditions are met:
request.hasParam("fusion-user-name") && request.getFirstParam("fusion-user-name").equals("SuperUser");
!request.hasParam("isFusionPluginQuery")The first condition checks that the request parameter "fusion-user-name" is present and has the value "SuperUser". The second condition checks that the request parameter "isFusionPluginQuery" is not present.
Configuration
When entering configuration values in the UI, use unescaped characters, such as \t for the tab character. When entering configuration values in the API, use escaped characters, such as \\t for the tab character.
|