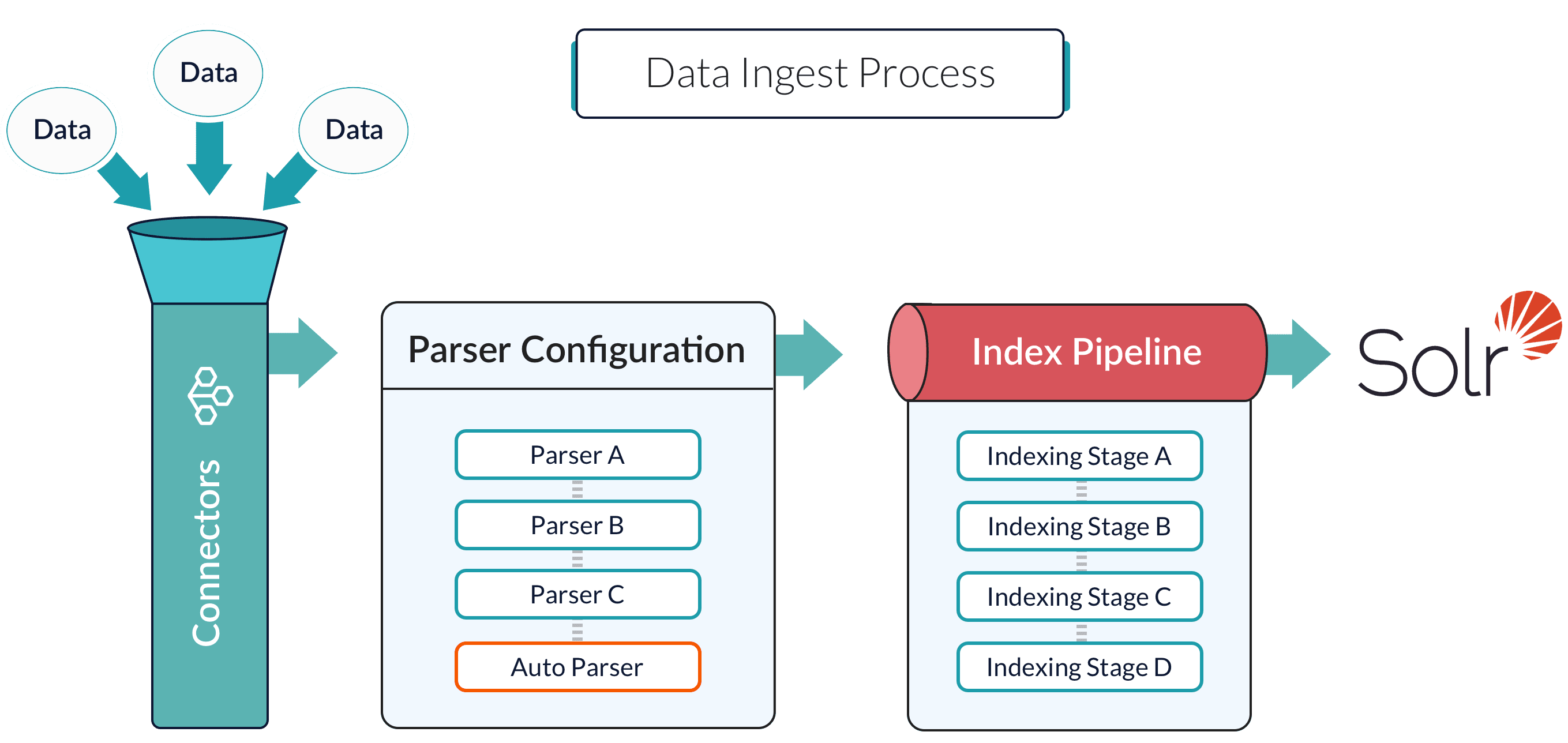
Index pipelines
Index pipelines transform incoming data into PipelineDocument objects for indexing by Managed Fusion-managed Solr service.
An index pipeline consists of a series of configurable
index pipeline stages,
each performing a different transformation on the data before passing the result to the next stage in the pipeline.
The final stage is the
Solr Indexer stage,
which transforms the PipelineDocument into a Solr document and submits it to Solr for indexing in a specific
Collection.
Each configured datasource has an associated index pipeline and uses a connector to fetch data to parse and then input into the index pipeline.
Alternatively, documents can be submitted directly to an index pipeline or profile with the REST API; see Importing Data with the REST API.
A pipeline can be reused across multiple collections. Managed Fusion provides a set of built-in pipelines. You can use the Index Workbench or the REST API to develop custom index pipelines to suit any datasource or application.
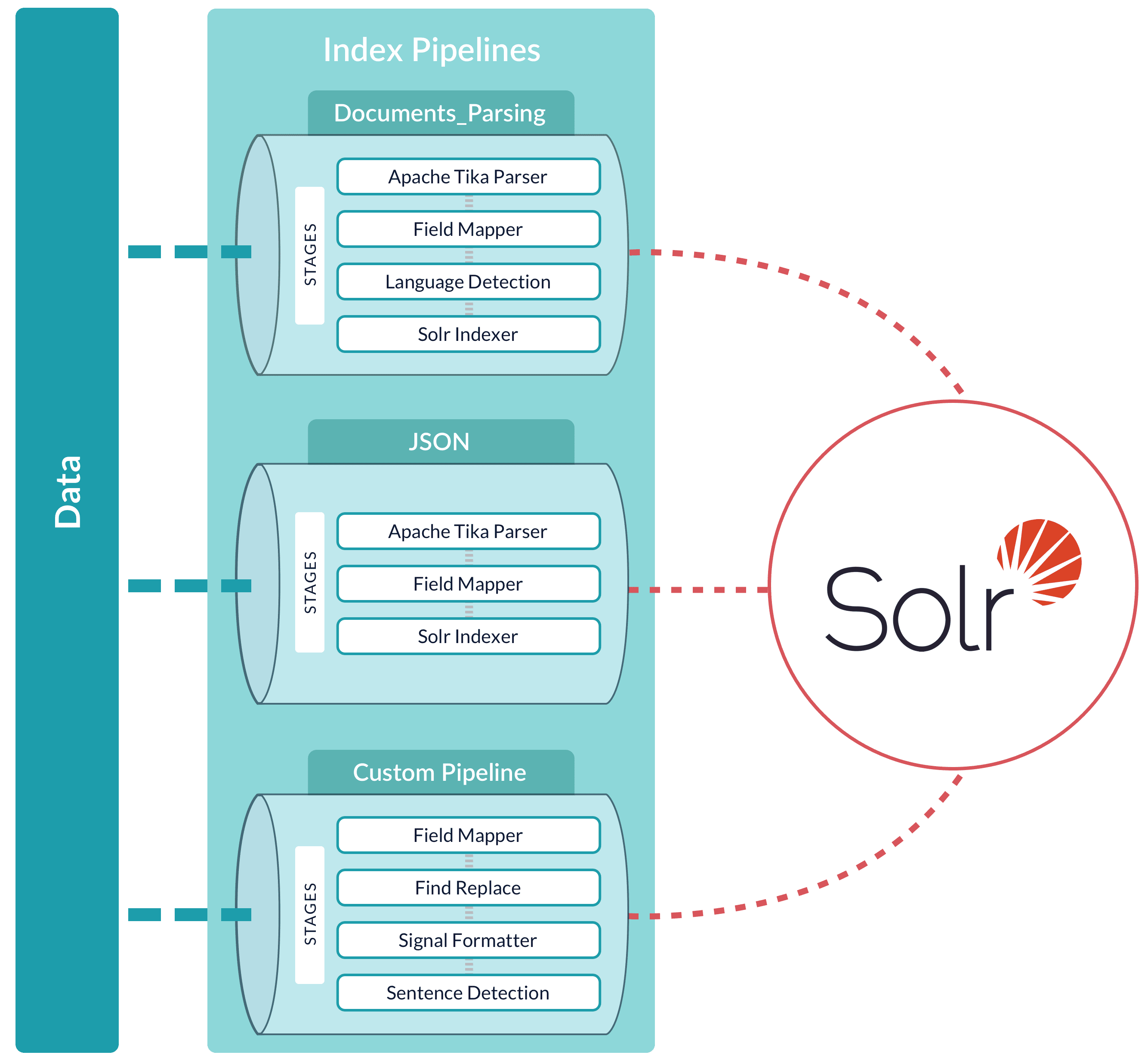
Managed Fusion creates a default index pipeline when you create an app. The index pipeline has the same name as the app. This pipeline consists of a Field Mapping index stage.