Workflow and Data Processing Module
A workflow processor is an atomic unit of business logic that can modify a query before it is submitted to a search platform, or transform a search response before rendering. This capability is used extensively for doing runtime data cleaning when, for example, it is not feasible to re-index a whole collection to fix issues in the source data.
The workflow module ships with a number of query and response processors for common tasks out of the box and it is easy to hook these or your own ones into the query/response lifecycle. These include, but are not restricted to:
-
Query pattern matching. Intercept queries for common terms that have no corresponding documents in the index (for example, postal codes, phone numbers, or email addresses).
-
Natural language processing (NLP). Analyse free-text input typed in by the end-user to provide a structured, more specific search command to the backend engine. For example, given the query "restaurants in new york" the NLP pre-processor might produce a structured query along the lines of
category:restaurant and city:nyc. Appkit has integration with a number of third-party NLP parsers, including Expert Systems, WolframAlpha and Smartlogic. More commonly, it is also easy to hook in custom natural language parsers, customized for a particular domain. -
Data augmentation. Transform and extend existing data on the fly with re-indexing, for example by fetching external linkages (look up latest stock ticker price, perform relational joins, etc.) or perform translation or lookups (replace ontology terms with common name).
-
Remove facet filters by pattern. The workflow module includes a comprehensive set of runtime data cleansing tools. When re-indexing is not feasible Appkit can remove irrelevant filters from dynamic navigation options based on for example, regular expression patterns.
The figure below illustrates the query-response lifecycle including a pipeline of workflow processing.
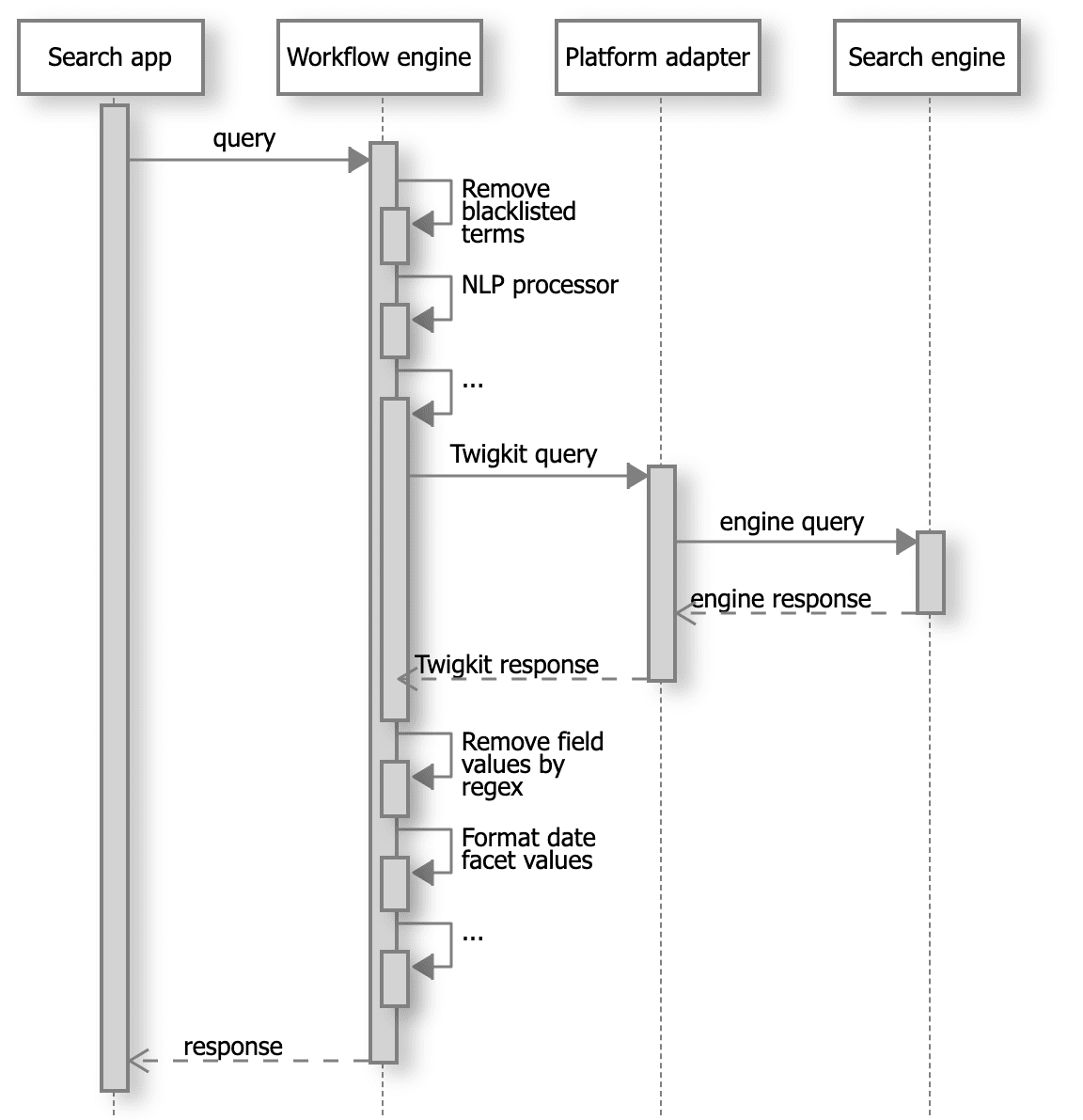
Figure 1. Sample query-response lifecycle involving the workflow engine.
In this example:
-
A search request is pre-processed before it is translated into an engine-specific command and sent to the search engine (for example, by removing specific forbidden or blacklisted words, applying natural language processing to the free-text portion of the query, etc.).
-
The data that comes back from the search engine is translated into a generic Appkit search response by the platform adapter, and then fed into a post-processing pipeline (which might, for example, apply regular expressions to remove specific terms from data fields, apply date formatting to facet aggregation values, etc.).
-
This produces finally a generic Appkit response that is returned to the search application, for rendering or further processing.
Workflow processors: building blocks of data transformation
An Appkit workflow processor is a Java class that is invoked and passed a reference to either a query or response object. A query pre-processor rewrites a query before it is submitted to the underlying search platform. Conversely, a response post-processor transforms a search response (both search results and facets) after it gets returned from a search engine (and before rendering). Workflow processors are typically declared in markup using JSP tags. Multiple processor tags can be specified for sequential processing of queries or responses.
Configuring a workflow pipeline
A workflow pipeline is configured at a platform level. This is useful for example for when you want to reuse processors in several places. This can be done using configuration files, chaining processors together along with a platform as a "workflow platform", which then can be referenced like any other platform.
Lucidworks has packaged up a selection of commonly used response post-processors for reuse.