Classification Jobs
This job analyzes how your existing documents are categorized and produces a classification model that can be used to predict the categories of new documents at index time.
For detailed configuration instructions and examples, see Classify New Documents at Index Time or Classify New Queries.
This job takes raw text and an associated single class as input. Although it trains on single classes, there is an option to predict the top several classes with their scores.
At a minimum, you must configure these:
-
An ID for this job
-
A Method; Logistic Regression is the default
-
A Model Deployment Name
-
The Training Collection
-
The Training collection content field, the document field containing the raw text
-
The Training collection class field containing the classes, labels, or other category data for the text
|
Lucidworks offers free training to help you get started. The Course for Classification focuses on understanding the different classifier models in Fusion:
Visit the LucidAcademy to see the full training catalog. |

Classification at index time
Used at index time, a classification model can be applied to predict the categories of new, incoming documents. To train a model for this use case, use your main content collection as the training collection. The model requires at least 100 examples in the training data for each category predicted.
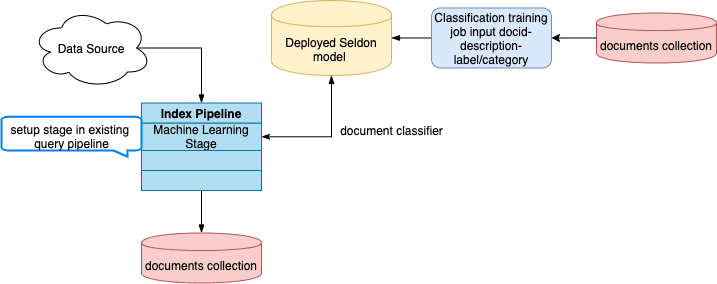
Once you have run the job, you can specify the model name in the Machine Learning Index Stage.
Job flow
The first part of the job is vectorization which is the same for all available classification algorithms. Mainly it supports two types of featurization:
-
Character-based - for queries or short texts, like document titles, sentences, and so on.
-
Word-based - for long texts like paragraphs, documents, and so on.
The second part is classification algorithms:
-
Logistic Regression. A classical algorithm with a good trade-off between training speed and results quality. It provides a robust baseline out of the box. Consider using it as a first choice.
-
StarSpace. A deep learning algorithm that jointly trains to maximize similarity between text and correct class and minimize similarity between text and incorrect classes. This usually requires more tuning and time for training, but with potentially more accurate results. Consider using it and then tuning it if better results are needed.
The third part of the job deploys the new classification model to Fusion using Seldon Core.
Best practices
These tips describe how to tune the options under Vectorization Parameters for best results with different use cases.
Query intent / short texts
If you want to train a model to predict query intents or to do short text classification, then enable Use Characters.
Another vectorization parameter that can improve model quality is Max Ngram size, with reasonable defaults between 3 and 5.
The more character ngrams are used the bigger the vocabulary, so it is worthwhile to tune the Maximum Vocab Size parameter that controls how many unique tokens will be used. Lower values will make training faster and will prevent overfitting but might provide lower quality too. It’s important to find a good balance.
Activating the advanced Sublinear TF option usually helps if characters are used.
Documents / long texts
If you want to train a model to predict classes for documents or long texts like one or more paragraphs, then uncheck Use Characters.
The reasonable values for word-based Max Ngram size are 2-3. Be sure to tune Maximum Vocab Size parameter too. Usually it’s better to leave the advanced Sublinear TF option deactivated.
Performance tuning
If the text is very long and Use Characters is checked, the job may take a lot of memory and possibly fail if the amount of memory requested by the job is not available. This may result in pods being evicted or failing with OOM errors. If you see this happening, try the following:
-
Uncheck Use Characters.
-
Reduce the vocabulary size and ngram range of the documents.
-
Allocate more memory to the pod.
Algorithm-specific
If you are going to train a model via LogisticRegression algorithm, dimensionality reduction usually doesn’t help so it makes sense to leave Reduce Dimensionality unchecked. But scaling seems to improve results, so it’s suggested to activate Scale Features.
For models trained by StarSpace algorithm it’s vice-versa. Dimensionality reduction usually helps to get better results as well as much faster model training. But scaling usually doesn’t help or might make results a little bit worse.
Index pipeline configuration
Model input transformation script
/*
Name of the document field to feed into the model.
*/
var documentFeatureField = "body_t"
/*
Model input construction.
*/
var modelInput = new java.util.HashMap()
modelInput.put("text", doc.getFirstFieldValue(documentFeatureField))
modelInputModel output transformation script
var top1ClassField = "top_1_class_s"
var top1ScoreField = "top_1_score_d"
doc.addField(top1ClassField, modelOutput.get("top_1_class")[0])
doc.addField(top1ScoreField, modelOutput.get("top_1_score")[0])// In case if top_k_predictions are needed
var top1ClassField = "top_1_class_s"
var top1ScoreField = "top_1_score_d"
var topKClassesField = "top_k_classes_ss"
var topKScoresField = "top_k_scores_ds"
var jsonOutput = JSON.parse(modelOutput.get("_rawJsonResponse"))
var parsedOutput = {};
for (var i=0; i<jsonOutput["names"].length;i++){
parsedOutput[jsonOutput["names"][i]] = jsonOutput["ndarray"][i]
}
doc.addField(top1ClassField, parsedOutput["top_1_class"][0])
doc.addField(top1ScoreField, parsedOutput["top_1_score"][0])
if ("top_k_classes" in parsedOutput) {
doc.addField(topKClassesField, new java.util.ArrayList(parsedOutput["top_k_classes"][0]))
doc.addField(topKScoresField, new java.util.ArrayList(parsedOutput["top_k_scores"][0]))
}Query pipeline configuration
Model input transformation script
var modelInput = new java.util.HashMap()
modelInput.put("text", request.getFirstParam("q"))
modelInputModel output transformation script
// To put into request
request.putSingleParam("class", modelOutput.get("top_1_class")[0])
request.putSingleParam("score", modelOutput.get("top_1_score")[0])
// Or for example to apply Filter Query
request.putSingleParam("fq", "class:" + modelOutput.get("top_1_class")[0])// To put into query context
context.put("class", modelOutput.get("top_1_class")[0])
context.put("score", modelOutput.get("top_1_score")[0])// To put into response documents (can be done only after Solr Query stage)
var docs = response.get().getInnerResponse().getDocuments();
var ndocs = new java.util.ArrayList();
for (var i=0; i<docs.length;i++){
var doc = docs[i];
doc.putField("query_class", modelOutput.get("top_1_class")[0])
doc.putField("query_score", modelOutput.get("top_1_score")[0])
ndocs.add(doc);
}
response.get().getInnerResponse().updateDocuments(ndocs);// In case if top_k_predictions are needed
// To put into response documents (can be done only after Solr Query stage)
var jsonOutput = JSON.parse(modelOutput.get("_rawJsonResponse"))
var parsedOutput = {};
for (var i=0; i<jsonOutput["names"].length;i++){
parsedOutput[jsonOutput["names"][i]] = jsonOutput["ndarray"][i]
}
var docs = response.get().getInnerResponse().getDocuments();
var ndocs = new java.util.ArrayList();
for (var i=0; i<docs.length;i++){
var doc = docs[i];
doc.putField("top_1_class", parsedOutput["top_1_class"][0])
doc.putField("top_1_score", parsedOutput["top_1_score"][0])
if ("top_k_classes" in parsedOutput) {
doc.putField("top_k_classes", new java.util.ArrayList(parsedOutput["top_k_classes"][0]))
doc.putField("top_k_scores", new java.util.ArrayList(parsedOutput["top_k_scores"][0]))
}
ndocs.add(doc);
}
response.get().getInnerResponse().updateDocuments(ndocs);