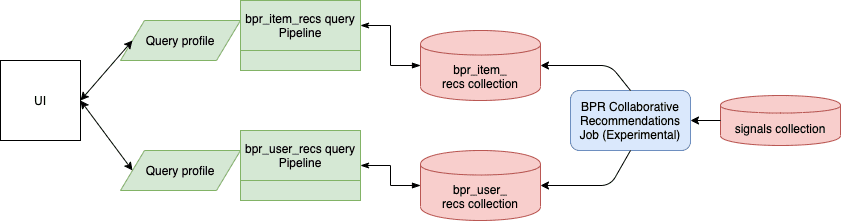
Use this job when you want to compute user recommendations or item similarities using a Bayesian Personalized Ranking recommender. You can also implement a user-to-item recommender in the advanced section of this job’s configuration UI.
id - stringrequired
The ID for this job. Used in the API to reference this job. Allowed characters: a-z, A-Z, dash (-) and underscore (_)
<= 63 characters
Match pattern: [a-zA-Z][_\-a-zA-Z0-9]*[a-zA-Z0-9]?
sparkConfig - array[object]
Provide additional key/value pairs to be injected into the training JSON map at runtime. Values will be inserted as-is, so use " to surround string values
object attributes:{key required : {
display name: Parameter Name
type: string
}value : {
display name: Parameter Value
type: string
}}
writeOptions - array[object]
Options used when writing output to Solr or other sources
object attributes:{key required : {
display name: Parameter Name
type: string
}value : {
display name: Parameter Value
type: string
}}
readOptions - array[object]
Options used when reading input from Solr or other sources.
object attributes:{key required : {
display name: Parameter Name
type: string
}value : {
display name: Parameter Value
type: string
}}
outputBatchSize - string
Batch size of documents when pushing results to solr
Default: 15000
jobRunName - string
Identifier for this job run. Use it to filter recommendations from particular runs.
trainingCollection - stringrequired
Solr collection or cloud storage path where training data is present.
>= 1 characters
trainingFormat - stringrequired
The format of the training data - solr, parquet etc.
>= 1 characters
Default: solr
secretName - string
Name of the secret used to access cloud storage as defined in the K8s namespace
>= 1 characters
outputUserRecsCollection - string
Solr collection or cloud storage path to store batch-predicted user/item recommendations (if absent, none computed). Specify at least one of Items-Users Output Collection or Items-Items Output Collection.
>= 1 characters
outputItemSimCollection - string
Solr collection or cloud storage path to store batch-computed item/item similarities (if absent, none computed). Specify at least one of Items-Users Output Collection or Items-Items Output Collection.
>= 1 characters
outputFormat - stringrequired
The format of the output data - solr, parquet etc.
>= 1 characters
Default: solr
partitionFields - string
If writing to non-Solr sources, this field will accept a comma-delimited list of column names for partitioning the dataframe before writing to the external output.
numRecsPerUser - integer
Number of recommendations that will be saved per user.
exclusiveMinimum: false
Default: 10
userTopkAnn - integer
Applies only when Filter Already Clicked Items is enabled. This is used to fetch additional recommendations so that the value specified for the Number of Recommendations Per User is most likely satisfied with filtering turned on.
exclusiveMinimum: false
numSimsPerItem - integer
Number of recommendations that will be saved per item.
exclusiveMinimum: false
Default: 10
deleteOldRecs - boolean
Should previous recommendations be deleted. If this box is unchecked, then old recommendations will not be deleted but new recommendations will be appended with a different Job ID. Both sets of recommendations will be contained within the same collection. Will only work when output path is solr.
Default: true
excludeFromDeleteFilter - string
If the 'Delete Old Recommendations' flag is enabled, then use this query filter to identify existing recommendation docs to exclude from delete. The filter should identify recommendation docs you want to keep.
filterClicked - boolean
Whether to filter out already clicked items in item recommendations for user. Takes more time but drastically improves quality.
Default: true
weightField - string
Solr field name containing stored counts/weights the user has for that item. This field is used as weight during training
Default: aggr_count_i
trainingDataFilterQuery - string
Solr or SQL query to filter training data. Use solr query when solr collection is specified in Training Path. Use SQL query when cloud storage location is specified. The table name for SQL is `spark_input`.
trainingSampleFraction - number
Choose a fraction of the data for training.
<= 1
exclusiveMaximum: false
Default: 1
userIdField - stringrequired
Solr field name in the training collection that contains stored User ID.
>= 1 characters
Default: user_id_s
itemIdField - stringrequired
Solr field name in the training collection that contains stored Item ID.
>= 1 characters
Default: item_id_s
randomSeed - integer
Pseudorandom determinism fixed by keeping this seed constant
Default: 12345
itemMetadataFields - array[string]
List of item metadata fields to include in the recommendation output documents. WARNING: Adding many fields can lead to huge output sizes or OOM issues.
itemMetadataCollection - string
Cloud storage path or Solr collection containing item metadata fields you want to add to the recommendation output documents. Leave blank and fill in the metadata fields if you want to fetch data from the training collection. Join field needs to be specified.
itemMetadataFormat - string
The format of the metadata - solr, parquet etc.
>= 1 characters
Default: solr
itemMetadataJoinField - string
Name of field in the item metadata collection to join on.
performANN - boolean
Whether to perform approximate nearest neighbor search (ANN). ANN will drastically reduce training time, but accuracy will drop a little. Disable only if training dataset is very small.
Default: true
maxNeighbors - integer
If perform ANN, size of the potential neighbors for the indexing phase. Higher value leads to better recall and shorter retrieval times (at the expense of longer indexing time).Reasonable range: 5~100
>= 100
<= 2000
exclusiveMinimum: false
exclusiveMaximum: false
searchNN - integer
If perform ANN, the depth of search used to find neighbors. Higher value improves recall at the expense of longer retrieval time.Reasonable range: 100~2000
>= 100
<= 2000
exclusiveMinimum: false
exclusiveMaximum: false
indexNN - integer
If perform ANN, the depth of constructed index. Higher value improves recall at the expense of longer indexing time.Reasonable range: 100~2000
>= 100
<= 2000
exclusiveMinimum: false
exclusiveMaximum: false
factors - integer
Latent factor dimension used for matrix decomposition. Bigger values require more time and memory but usually provide better results.
>= 1
exclusiveMinimum: false
Default: 100
epochs - integer
Number of model training iterations. Model will converge better with larger number at the expense of increased training time. For bigger datasets use smaller values.
>= 1
exclusiveMinimum: false
Default: 30
learningRate - number
Model learning rate.
Default: 0.05
metadataCategoryFields - array[string]
These fields will be used for item-item evaluation and for determining if the recommendation pair belong to the same category.
minNumItemUniqueClicks - integer
Items must have at least this no. of unique user interactions to be included for training and recommendations. The higher this value, the more popular items selected but the amount of training data will reduce.
>= 1
exclusiveMinimum: false
Default: 2
minNumUserUniqueClicks - integer
Users must have at least this no. of unique item interactions to be included for training and recommendations. The higher this value, the more active users are selected but the amount of training data will reduce.
>= 1
exclusiveMinimum: false
Default: 2
minNumClickedProducts - integer
Minimum number of clicked products the user should have to be a candidate for the test set.
>= 2
exclusiveMinimum: false
Default: 3
maxNumTestUsers - integer
Maximum number of test users to choose. If more users satisfying the Minimum Clicked Products criterion are present, the number will be capped to what is specified here.
exclusiveMinimum: false
Default: 10000
numTestUserClicks - integer
How many test user clicks to use for testing. Should be less than the value for Minimum Clicked Products.
>= 1
exclusiveMinimum: false
Default: 1
doEvaluation - boolean
Evaluate how well the trained model predicts user clicks. Test data will be sampled from original dataset.
type - stringrequired
Default: argo-item-recommender-user
Allowed values: argo-item-recommender-user